java完成PPT轉PDF湧現中文亂碼成績的處理辦法。本站提示廣大學習愛好者:(java完成PPT轉PDF湧現中文亂碼成績的處理辦法)文章只能為提供參考,不一定能成為您想要的結果。以下是java完成PPT轉PDF湧現中文亂碼成績的處理辦法正文
ppt轉成pdf,道理是ppt轉成圖片,再用圖片臨盆pdf,進程有個成績,不論是ppt照樣pptx,都碰到中文亂碼,編程方框的成績,個中ppt後綴網上隨意找就有處理計劃,就是設置字體為同一字體,pptx假如頁面是一種中文字體不會有成績,假如一個頁面有微軟雅黑和宋體,就會招致部門中文方框,疑惑是poi處置的時刻,只讀取第一種字體,所以招致多個中文字體亂碼。
百度和谷歌都找了良久,有看到說apache官網有人說是bug,但他們答復說是字體成績,這個成績其實我認為poi能夠可以本身做,讀取本來字體設置成以後字體,不外機能應當會有許多消費,橫豎我估量許多人跟我一樣消費年夜量時光找處理計劃,網上簡直沒有現成的計劃。本身也是一步步測驗考試,終究找到處理方法,ppt格局的就不說了網上找獲得,pptx後綴的網上我是沒找到。
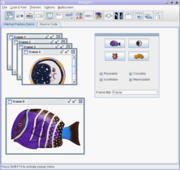
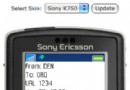
成績前的pptx轉成圖片:
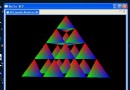
處理後的pptx轉成圖片:
處理辦法:
讀取每一個shape,將文字轉成同一的字體,網上找到的那段代碼弗成行,我本身改的計劃以下:
for( XSLFShape shape : slide[i].getShapes() ){
if ( shape instanceof XSLFTextShape ){
XSLFTextShape txtshape = (XSLFTextShape)shape ;
System.out.println("txtshape" + (i+1) + ":" + txtshape.getShapeName());
System.out.println("text:" +txtshape.getText());
for ( XSLFTextParagraph textPara : txtshape.getTextParagraphs() ){
List<XSLFTextRun> textRunList = textPara.getTextRuns();
for(XSLFTextRun textRun: textRunList) {
textRun.setFontFamily("宋體");
}
}
}
}
完全代碼以下(除以上本身的處理計劃,年夜部門是stackoverflow上的代碼):
public static void convertPPTToPDF(String sourcepath, String destinationPath, String fileType) throws Exception {
FileInputStream inputStream = new FileInputStream(sourcepath);
double zoom = 2;
AffineTransform at = new AffineTransform();
at.setToScale(zoom, zoom);
Document pdfDocument = new Document();
PdfWriter pdfWriter = PdfWriter.getInstance(pdfDocument, new FileOutputStream(destinationPath));
PdfPTable table = new PdfPTable(1);
pdfWriter.open();
pdfDocument.open();
Dimension pgsize = null;
Image slideImage = null;
BufferedImage img = null;
if (fileType.equalsIgnoreCase(".ppt")) {
SlideShow ppt = new SlideShow(inputStream);
inputStream.close();
pgsize = ppt.getPageSize();
Slide slide[] = ppt.getSlides();
pdfDocument.setPageSize(new Rectangle((float) pgsize.getWidth(), (float) pgsize.getHeight()));
pdfWriter.open();
pdfDocument.open();
for (int i = 0; i < slide.length; i++) {
TextRun[] truns = slide[i].getTextRuns();
for ( int k=0;k<truns.length;k++){
RichTextRun[] rtruns = truns[k].getRichTextRuns();
for(int l=0;l<rtruns.length;l++){
// int index = rtruns[l].getFontIndex();
// String name = rtruns[l].getFontName();
rtruns[l].setFontIndex(1);
rtruns[l].setFontName("宋體");
}
}
img = new BufferedImage((int) Math.ceil(pgsize.width * zoom), (int) Math.ceil(pgsize.height * zoom), BufferedImage.TYPE_INT_RGB);
Graphics2D graphics = img.createGraphics();
graphics.setTransform(at);
graphics.setPaint(Color.white);
graphics.fill(new Rectangle2D.Float(0, 0, pgsize.width, pgsize.height));
slide[i].draw(graphics);
graphics.getPaint();
slideImage = Image.getInstance(img, null);
table.addCell(new PdfPCell(slideImage, true));
}
}
if (fileType.equalsIgnoreCase(".pptx")) {
XMLSlideShow ppt = new XMLSlideShow(inputStream);
pgsize = ppt.getPageSize();
XSLFSlide slide[] = ppt.getSlides();
pdfDocument.setPageSize(new Rectangle((float) pgsize.getWidth(), (float) pgsize.getHeight()));
pdfWriter.open();
pdfDocument.open();
for (int i = 0; i < slide.length; i++) {
for( XSLFShape shape : slide[i].getShapes() ){
if ( shape instanceof XSLFTextShape ){
XSLFTextShape txtshape = (XSLFTextShape)shape ;
// System.out.println("txtshape" + (i+1) + ":" + txtshape.getShapeName());
//System.out.println("text:" +txtshape.getText());
for ( XSLFTextParagraph textPara : txtshape.getTextParagraphs() ){
List<XSLFTextRun> textRunList = textPara.getTextRuns();
for(XSLFTextRun textRun: textRunList) {
textRun.setFontFamily("宋體");
}
}
}
}
img = new BufferedImage((int) Math.ceil(pgsize.width * zoom), (int) Math.ceil(pgsize.height * zoom), BufferedImage.TYPE_INT_RGB);
Graphics2D graphics = img.createGraphics();
graphics.setTransform(at);
graphics.setPaint(Color.white);
graphics.fill(new Rectangle2D.Float(0, 0, pgsize.width, pgsize.height));
slide[i].draw(graphics);
// FileOutputStream out = new FileOutputStream("src/main/resources/test"+i+".jpg");
// javax.imageio.ImageIO.write(img, "jpg", out);
graphics.getPaint();
slideImage = Image.getInstance(img, null);
table.addCell(new PdfPCell(slideImage, true));
}
}
pdfDocument.add(table);
pdfDocument.close();
pdfWriter.close();
System.out.println("Powerpoint file converted to PDF successfully");
}
maven設置裝備擺設:
<dependency> <groupId>org.apache.poi</groupId> <artifactId>poi</artifactId> <!-- <version>3.13</version> --> <version>3.9</version> </dependency> <dependency> <groupId>org.apache.poi</groupId> <artifactId>poi-ooxml</artifactId> <!-- <version>3.10-FINAL</version> --> <version>3.9</version> </dependency> <dependency> <groupId>com.itextpdf</groupId> <artifactId>itextpdf</artifactId> <version>5.5.7</version> </dependency> <dependency> <groupId>com.itextpdf.tool</groupId> <artifactId>xmlworker</artifactId> <version>5.5.7</version> </dependency> <dependency> <groupId>org.apache.poi</groupId> <artifactId>poi-scratchpad</artifactId> <!-- <version>3.12</version> --> <version>3.9</version> </dependency>
下面就是為年夜家分享的java完成PPT轉PDF湧現中文亂碼成績的處理辦法,願望對年夜家的進修有所贊助。