淺析Java的Hibernate框架中的繼續關系設計。本站提示廣大學習愛好者:(淺析Java的Hibernate框架中的繼續關系設計)文章只能為提供參考,不一定能成為您想要的結果。以下是淺析Java的Hibernate框架中的繼續關系設計正文
此次我們來講一下hibernate的條理設計,條理設計也就是實體之間的繼續關系的設計。
或許如許比擬籠統,我們直接看例子。
1)我們先看一下通俗的做法
直接上代碼:三個實類以下:
public class TItem implements Serializable{
//省略Get/Set辦法
private int id;
private String manufacture;
private String name;
}
public class TBook extends TItem{
//省略Get/Set辦法
private int pageCount;
}
public class TDVD extends TItem{
//省略Get/Set辦法
private String regionCode;
}
這裡我們須要三個映照文件,內容以下:
<class name="TItem" table="ITEM">
<id name="id" column="id" type="java.lang.Integer">
<generator class="native" />
</id>
<property name="name" column="name" type="java.lang.String"/>
<property name="manufacture" column="manufacture" type="java.lang.String"/>
</class>
<class name="TBook" table="Book">
<id name="id" column="id" type="java.lang.Integer">
<generator class="native" />
</id>
<property name="name" column="name" type="java.lang.String"/>
<property name="manufacture" column="manufacture" type="java.lang.String"/>
<property name="pageCount" column="pageCount" type="java.lang.Integer"/>
</class>
<class name="TDVD" table="DVD">
<id name="id" column="id" type="java.lang.Integer">
<generator class="native" />
</id>
<property name="name" column="name" type="java.lang.String"/>
<property name="manufacture" column="manufacture" type="java.lang.String"/>
<property name="regionCode" column="regionCode" type="java.lang.String"/>
</class>
很通俗的映照文件,跟之前的沒甚麼差別。
上面我們直接寫一個測試辦法:
public void testSelect() {
Query query = session.createQuery("from TItem ");
List list = query.list();
Iterator iter = list.iterator();
while(iter.hasNext()) {
System.out.println("Name:"+(((TItem)iter.next()).getName()));
}
}
留意,這裡我們是用TItem類,而不是詳細的字類,這裡它會主動去查找繼續於TItem類的子類,查出一切成果。這裡觸及到一個多態形式,class標簽有屬性 polymorphism,它的默許值為implicit,這意味著不須要指命名稱便可以查詢出成果。假如為explicit則注解須要指定詳細的類名時,才可以查出此類的成果。
2)上個例子中我們用到了三個映照文件,當我們須要修正時,就須要修正三個映照文件,這關於年夜的項目是很弗成行的。並且每一個表都有對應的主類的對應字段,這是過剩的。所以我們有上面這類辦法。
實體類照樣跟1)中的一樣。我們把映照文件由三個改成一個,只保存TItem映照文件。但我們須要做響應的修正,如今內容以下:
<class name="TItem" table="ITEM" polymorphism="explicit">
<id name="id" column="id" type="java.lang.Integer">
<generator class="native" />
</id>
<property name="name" column="name" type="java.lang.String"/>
<property name="manufacture" column="manufacture" type="java.lang.String"/>
<joined-subclass name="TBook" table="TBOOK">
<key column="id" />
<property name="pageCount" column="pageCount" type="java.lang.Integer" />
</joined-subclass>
<joined-subclass name="TDVD" table="TDVD">
<key column="id"/>
<property name="regionCode" column="regionCode" type="java.lang.String"/>
</joined-subclass>
</class>
這裡,我們只要一個映照文件,但有一個joined-subclass標簽,它注解這個類繼續於以後類,<key>注解分表的主鍵,這裡分表是指TBOOK和TDVD這兩個由子類對應的表。分表中只要字段在property中指定。
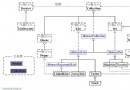
如許當我們運轉後生成的表就以下圖:
兩個子類對應的表只要我們經由過程property指定的字段。如許就防止了表內有多個字段,使字表只保護其零丁字段,當item類停止轉變時,也不消過量的停止修正。
3)再來懂得別的一種辦法完成條理設計,這就是經由過程在表內置入標記來完成。在hibernate的映照文件中我們經由過程descriminator標簽來停止完成。
空話不多說,我們直接看例子:
我們把昨天的TItem的映照文件修正為:
<class name="TItem" table="ITEM" polymorphism="explicit">
<id name="id" column="id" type="java.lang.Integer">
<generator class="native" />
</id>
<discriminator column="category" type="java.lang.String"/>
<property name="name" column="name" type="java.lang.String"/>
<property name="manufacture" column="manufacture" type="java.lang.String"/>
</class>
看到中央,我們參加了一個discriminator標簽,它注解我們以下的兩個subclass經由過程哪一個字段來停止差別。
<subclass name="TBook" discriminator-value="1">
<property name="pageCount" column="pageCount"/>
</subclass>
<subclass name="TDVD" discriminator-value="2" >
<property name="regionCode" column="regionCode"/>
</subclass>
我們看到這兩段,它指清楚明了當discriminator所指定的field的值為1時,注解它是TBook類,而且pageCount有值;當discriminator所指定的field值為2時,注解它是TDVD類,而且regionCode有值。
如許我們就只須要用到一個表,就注解了它們幾個類的關系了,留意,這類方法對有過量子類的情形下,其實不好,它會使主表的字段過量,會形成必定的設計上的未便。