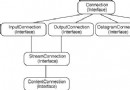
使用XML之前,你必須考慮好是不是必須用它來傳輸數據,因為解析XML是比較耗費資源的,尤其是在CPU和內存的資源都很寶貴的條件下。如果我們能使用DataInputStream和DataOutputStream傳輸的話就盡量不要使用XML。XML的解析器有兩種,一種是確認性的,他在解析之前會對XML的文檔進行有效性的驗證,確保這是應用程序需要的。另一種則是非確認性的,他不做驗證工作直接進行解析,無疑這樣的速度會快。kxml和nanoxml都是這樣的解析器。它們也存在差別,kXML是增量解析器他會一點一點的解析,這樣在解析大的文檔的時候會效率比較高。nanoxml是一步解析器,一次就把文檔解析完,如果文檔很大的話,這無疑會耗費很大的內存。要使用kXML你可以從http://www.kXML.org 下載得到,在http://nanoXML.sourceforge.Net 你可以下載nanoXML。
要使用kxml,你必須首先得到一個XMLParser實例,它用Reader作為構造器的參數:
try {
Reader r = .....;
XmlParser parser = new XMLParser( r );
}
catch( Java.io.IOException e ){
// handle exception....
}
如果你的XML文檔存儲在String內的話你可以使用ByteArrayInputStream和InputStreamReader:
String xml = "<a>some XML</a>";
ByteArrayInputStream bin = new ByteArrayInputStream( XML.getBytes() );
XmlParser parser = new XMLParser( new InputStreamReader( bin ) );
當從網上接收數據的時候可以這樣:
HttpConnection conn = .....;
InputStreamReader doc = new InputStreamReader( conn.openInputStream() );
XmlParser parser = new XMLParser( doc );
得到parser實例後我們就可以調用read方法進行解析了,read方法會返回一個ParseEvent,通過判斷他的類型我們就可以解析XML了。
try {
boolean keepParsing = true;
while( keepParsing ){
ParseEvent event = parser.read();
switch( event.getType() ){
case XML.START_TAG:
..... // handle start of an XML tag
break;
case XML.END_TAG:
..... // handle end of an XML tag
break;
case XML.TEXT:
..... // handle text within a tag
break;
case XML.WHITESPACE:
..... // handle whitespace
break;
case XML.COMMENT:
..... // handle comment
break;
case XML.PROCESSING_INSTRUCTION:
..... // handle XML PI
break;
case XML.DOCTYPE:
..... // handle XML doctype
break;
case XML.END_DOCUMENT:
..... // end of document;
keepParsing = false;
break;
}
}
}
catch( Java.io.IOException e ){
}
如果想使用nanoXML,那麼你首先要創建一個kXMLElement實例,然後調用parseFromReader、parseString或者parseCharArray。由於他是一步解析器,那麼它會把整個文檔解析完後生成一個Object tree。每個節點都是一個kXMLElement的實例,通過調用getChildren等方法可以在這棵樹上導航。
HttpConnection conn = .....;
InputStreamReader doc =
new InputStreamReader( conn.openInputStream() );
kXMLElement root = new kXMLElement();
try {
root.parseFromReader( doc );
}
catch( kXMLParseException pe ){
}
catch( IOException IE ){
}
下面是一個J2ME的應用程序簡單演示了如何解析xml。如果有時間可以寫寫復雜的測試程序。你可以從如下地址下載源代碼:XMLTest. 裡面包括了kxml和nanoXML的源代碼,如果想得到最新的源代碼請參考他們的官方網站,在本站提供了kXML的在線API
package com.eriCGIguere.techtips;
import Java.io.*;
import Java.util.*;
import Javax.microedition.lcdui.*;
import Javax.microedition.midlet.*;
import nanoXML.*;
import org.kXML.*;
import org.kXML.parser.*;
/**
* Simple MIDlet that demonstrates how an XML document can be
* parsed using kXML or NanoXML.
*/
public class XMLTest extends MIDlet {
// Our XML document -- normally this would be something you
// download.
private static String XMLDocument =
"<list><item>apple</item>" +
"<item>orange</item>" +
"<item>pear</item></list>";
private Display display;
private Command exitCommand = new Command( "Exit",
Command.EXIT, 1 );
public XMLTest(){
}
protected void destroyApp( boolean unconditional )
throws MIDletStateChangeException {
exitMIDlet();
}
protected void pauseApp(){
}
protected void startApp() throws MIDletStateChangeException {
if( display == null ){ // first time called...
initMIDlet();
}
}
private void initMIDlet(){
display = Display.getDisplay( this );
String [] items;
//items = parseUsingNanoXML( XMLDocument );
items = parseUsingkXML( XMLDocument );
display.setCurrent( new ItemList( items ) );
}
public void exitMIDlet(){
notifyDestroyed();
}
// Parses a document using NanoXML, looking for
// "item" nodes and returning their content as an
// array of strings.
private String[] parseUsingNanoXML( String XML ){
kXMLElement root = new kXMLElement();
try {
root.parseString( XML );
Vector list = root.getChildren();
Vector items = new Vector();
for( int i = 0; i < list.size(); ++i ){
kXMLElement node =
(kXMLElement) list.elementAt( i );
String tag = node.getTagName();
if( tag == null ) continue;
if( !tag.equals( "item" ) ) continue;
items.addElement( node.getContents() );
}
String[] tmp = new String[ items.size() ];
items.copyInto( tmp );
return tmp;
}
catch( kXMLParseException ke ){
return new String[]{ ke.toString() };
}
}
// Parses a document using kXML, looking for "item"
// nodes and returning their content as an
// array of strings.
private String[] parseUsingkXML( String XML ){
try {
ByteArrayInputStream bin =
new ByteArrayInputStream(
XML.getBytes() );
InputStreamReader in = new InputStreamReader( bin );
XmlParser parser = new XMLParser( in );
Vector items = new Vector();
parsekXMLItems( parser, items );
String[] tmp = new String[ items.size() ];
items.copyInto( tmp );
return tmp;
}
catch( IOException e ){
return new String[]{ e.toString() };
}
}
private void parsekXMLItems( XMLParser parser, Vector items )
throws IOException {
boolean inItem = false;
while( true ){
ParseEvent event = parser.read();
switch( event.getType() ){
case XML.START_TAG:
if( event.getName().equals( "item" ) ){
inItem = true;
}
break;
case XML.END_TAG:
if( event.getName().equals( "item" ) ){
inItem = false;
}
break;
case XML.TEXT:
if( inItem ){
items.addElement( event.getText() );
}
break;
case XML.END_DOCUMENT:
return;
}
}
}
// Simple List UI component for displaying the list of
// items parsed from the XML document.
class ItemList extends List implements CommandListener {
ItemList( String[] list ){
super( "Items", IMPLICIT, list, null );
addCommand( exitCommand );
setCommandListener( this );
}
public void commandAction( Command c, Displayable d ){
if( c == exitCommand ){
exitMIDlet();
}
}
}
}