Enhydra的KXML是一個只占很小存儲空間的XML語法分析程序,對於J2ME利用程序非常合適。它有一個非常奇特的DOM把持方法和被稱為Pull的語法分析方法。
我最近一直在開發一個用於J2ME設備的多人游戲項目。在這個利用程序中,服務器和設備之間的通信本來被編碼成由"&"分隔的鍵值對,這樣從服務器檢索變量會很快,但是當我開端處理更復雜的數據結構和嵌套的數據結構時,我發明這種方法並不實用。在這種情況,它會變得很難寫數據並且輕易出錯。
為懂得決這標題,我決定應用XML重新編寫利用程序的數據傳輸部分。對於我來說,XML是一個自然而然的選擇,不僅僅由於我已經應用它在以前的一個項目中編寫了通過網絡向applet中傳送信息的程序,而且由於XML確實很輕易調試和編寫。當然,它還讓你應用一種很豐富的格局來結構化這些數據。然而,讓我意想不到的是我竟為我的編程工具箱找到一顆可貴的寶石。
KXML是一個被設計用於J2ME設備的簡化類庫,固然它也可以被用於其它需要小型XML語法分析程序的環境,比如Applet。KXML是一個Enhydra保護的項目,支撐下面的性能:
· 支撐XML名稱空間
· 用"疏松"模式分析Html或其它SGML格局
· 占用很少的存儲空間(21 kbps)
· 基於Pull的分析
· 支撐XML寫把持
· 可選的DOM支撐
· 可選的WAP支撐
在本文中,我將具體闡明其中的一些特點,尤其是Pull分析和DOM把持,而且我將告訴你如何檢查KXML在內存中把持的後果。
本文中的兩個MIDlet例程都有完整的源代碼,可以向你闡明如何應用KXML。在KToolBar 1.04工程中不包含KXML類庫--你必需從http://KXML.enhydra.org/取得類庫,然後把壓縮文件放在工程的"lib"目錄下。
應用XML工作
有兩個常見的應用XML工作的方法:把持DOM或者捕捉語法分析事件。把持DOM是一個與XML相互作用的簡略方法,通常這個XML是一棵完整的XML 樹,被解析成一個存放在存儲器中的節點結構,你可以遍歷這棵樹。它非常簡略易用,但是由於整棵樹存在於存儲器中造成存儲器的累贅。
第二種方法在捕捉語法分析事件中,每當語法分析程序碰到數據中的特定結構,它就會遍歷XML數據,然後把成果發回前面注冊的一個事件*********中。比如說,當語法分析程序碰到一個起始標記,如<Html>,那麼事件*********將接收一個事件,通知它這個情況,並且向它傳遞任何所需的信息。實現這種策略的語法分析程序被稱為push語法分析程序,由於這個語法分析程序把事件"推動"一個*********中。
KXML支撐DOM語法分析和把持,但是不支撐 push語法分析。取而代之,它應用一種稍微不同的稱為"Pull"的分析方法。與push語法分析相反,Pull語法分析讓程序員從語法分析程序中"拉 "出下一個事件。在push語法分析中,你必需保護你正在分析確當前數據的狀態,然後基於傳送到*********的事件,恢復任何以前的狀態,並且當你轉換到一個不同的狀態時保留新的狀態。Pull語法分析使處理狀態轉變更加輕易,由於你可以發送分析器到不同的函數,保護它們自己的狀態變量。Pull語法分析
讓我們來研究一個例子,看看KXML如何做一個Pull語法分析程序。演示程序名為KXMLDemo_Pull。它將應用一個Pull語法分析程序查看一個包含通信錄信息的文件。下面給出源代碼中比擬重要的幾行,我還給出了注釋。
1.XMLParser parser = null;
2......
3.parser = new XMLParser( new InputStreamReader( 1this.getClass().getResourceAsStream(resfile_name) ));
第三行創立了一個XMLParser,把它傳到一個InputStream中。這個語法分析程序重復調用,直到呈現END_DOCUMENT事件。
1.while ( (event = parser.read()).getType() != XML.END_DOCUMENT ) {
2. ...
3.if (name != null && name.equals("address")) {
4. ...
5. parseAddressTag( parser );
第三行判定事件是否以一個<address>標記開端,第五行傳送語法分析器到把持語法分析程序的"parseAddressTag"。
9 7 3 1 2 3 4 8 :
1.while ((event = parser.peek()).getType() != XML.END_DOCUMENT) {
2....
3. if (type == XML.END_TAG && name.equals("address")) {
4. return;
5. }
6....
7. ParseEvent next = parser.read();
8.
9. // if it's not a text event then skip it
10. if (next.getType() != XML.TEXT) {
11. continue;
12. }
13....
14. System.err.println(name + ": " + text);
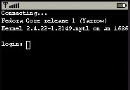
上面的這段代碼在"parseAddressTag"中循環,直到找到與<address>對應的終止標記。假如它碰到其它任何標記,那麼標記名和標記內容就會被打印到把持台上。因此,假如找到標記<name>Robert Cadena</name>,你將看到下面的把持台輸出:
name: Robert Cadena
一旦找到<address>的終止標記(8- 10行),控件被返回調用函數,然後又開端查找<address>。
如你所見,應用Pull語法分析程序非常輕易,並且能夠傳送語法分析程序到另一個函數,然後在文檔中查找元素。你並不局限於分析資源文件;你還可以應用 HttpConnection把這個函數傳遞到http InputStream。這把你從讀取InputStream、保留內容、分析內容等把持中解放了出來,一切都由KXML為你完成。
DOM處理
Pull語法分析特別實用於當你需要保護非常小的存儲空間的時候,由於發失事件的文檔只有一部分存在於內存中。換句話說,假如你感愛好的特定數據段是文檔中部的幾百個字節,那麼前面的幾百個字節就不必保留在內存中了。
但是假如你能夠節儉一些內存,你可以應用另一個版本的KXML語法分析程序,它包含對DOM的支撐。 DOM是保留在內存中的全部文檔樹,每個標記都被分別成節點(Node)對象。 你可以遍歷這個文檔樹,然後根據需要取得數據。
工程中的另一個MIDlet,KXMLDemo_dom,做了同樣的事情。它讀取一個通信錄,然後把內容打印到把持台,但是這次它應用了DOM。下面給出源代碼中比擬重要的幾行.
1.Document doc = new Document();
2....
3.parser = new XMLParser( isr );
4.doc.parse( parser );
第一行創立了一個文檔,保留XML樹。第三行從一個名為isr的InputStreamReader中創立一個KXML語法分析程序。第四行傳送這個語法分析程序到文檔,然後讓文檔開端分析。XML被遞回分析,直到達到文檔的結尾。當分析調用退出時,全部文檔被裝進內存,這時你就可以把持它了。
1.Element root = doc.getRootElement();
2.int child_count = root.getChildCount();
3....
4.for (int i = 0; i < child_count ; i++ ) {
5....
6. Element kid = root.getElement(i);
7.
8. if (!kid.getName().equals("address")) {
9. continue;
10. }
由於我們知道<address>元素是根元素的直接子元素,我們可以遍歷根元素的子元素,尋找address標記,假如子元素不是一個address 標記,則返回。
1.int address_item_count = kid.getChildCount();
2.
3. for (int j = 0; j < address_item_count ; j++) {
4....
假如我們找到了address子元素,我們開端遍歷它的子元素,並把這些子元素的內容打印出來。不幸的是,你不能只是應用kid.getElement ("name"),由於假如這個元素不存在的話,那麼你將得到一個RuntimeException。所以我建議只有當你知道XML文檔中存在你所有需要的所有字段時才應用這個方法。
檢查你的內存
根據經驗,當你不能確保你的利用程序的結構,並且你需要保持內存被占用情況較低時,你應當應用Pull語法分析程序。當你有足夠內存並且可能需要通過添加或移動標記的方法把持文檔時,可以應用DOM。
假如你想看看這兩種方法應用內存的情況,在KtoolBar中打開工程,應用內存監督器(Edit-->Preferences:Monitoring Tag)。 當你運行MIDlet,你將看到內存監控窗口彈出,有圖形和數字表現內存的應用情況。運行每一個利用程序,然後觀察綠線上升,這表現你的利用程序耗費的內存量。你將看到Pull利用程序比DOM利用程序應用內存少一些。固然本例中的兩個MIDlet之間的差別不是非常大,但是假如一個MIDlet用DOM方法遍歷一個更大的文件,那麼它將耗費更多內存。