Java和C++之間顯著的一個區別就是對內存的管理。和C++把內存管理的權利賦予給開發人員的方式不同,Java擁有一套自動的內存回收系統(Garbage Collection,GC)簡稱GC,可以無需開發人員干預而對不再使用的內存進行回收管理。
垃圾回收技術(以下簡稱GC)是一套自動的內存管理機制。當計算機系統中的內存不再使用的時候,把這些空閒的內存空間釋放出來重新投入使用,這種內存資源管理的機制就稱為垃圾回收。
其實GC並不是Java的專利,GC的的發展歷史遠比Java來得久遠的多。早在Lisp語言中,就有GC的功能,包括其他很多語言,如:Python(其實Python的歷史也比Java早)也具有垃圾回收功能。
使用GC的好處,可以把這種容易犯錯的行為讓給計算機系統自己去管理,可以防止人為的錯誤。同時也把開發人員從內存管理的泥沼中解放出來。
雖然使用GC雖然有很多方便之處,但是如果不了解GC機制是如何運作的,那麼當遇到問題的時候,我們將會很被動。所以有必要學習下Java虛擬機中的GC機制,這樣我們才可以更好的利用這項技術。當遇到問題,比如內存洩露或內存溢出的時候,或者垃圾回收操作影響系統性能的時候,我們可以快速的定位問題,解決問題。
接下來,我們來看下JVM中的GC機制是怎麼樣的。
首先,我們如果要進行垃圾回收,那麼我們必須先要識別出哪些是垃圾(被占用的無用內存資源)。
Java虛擬機將內存劃分為多個區域,分別做不同的用途。簡單的將,JVM對內存劃分為這幾個內存區域:程序計數器、虛擬機棧、本地方法棧、Java堆和方法區。其中程序計數器、虛擬機棧和本地方法棧是隨著線程的生命周期出生和死亡的,所以這三塊區域的內存在程序執行過程中是會有序的自動產生和回收的,我們可以不用關心它們的回收問題。剩下的Java堆和方法區,它們是JVM中所有線程共享的區域。由於程序執行路徑的不確定性,這部分的內存分配和回收是動態進行的,GC主要關注這部分的內存的回收。
對像實例是否是存活的,有兩種算法可以用於確定哪些實例是死亡的(它們占用的內存就是垃圾),那麼些實例是存活的。第一種是引用計數算法:
引用計數算法會對每個對象添加一個引用計數器,每當一個對象在別的地方被引用的時候,它的引用計數器就會加1;當引用失效的時候,它的引用計數器就會減1。如果一個對象的引用計數變成了0,那麼表示這個對象沒有被任何其他對象引用,那麼就可以認為這個對象是一個死亡的對象(它占用的內存就是垃圾),這個對象就可以被GC安全地回收而不會導致系統出現問題。
我們可以發現,這種計數算法挺簡單的。在C++中的智能指針,也是使用這種方式來跟蹤對象引用的,來達到內存自動管理的。引用計數算法實現簡單,而且判斷高效,在大部分情況下是一個很好的垃圾標記算法。在Python中,就是采用這種方式來進行內存管理的。但是,這個算法存在一個明顯的缺陷:如果兩個對象之間有循環引用,那麼這兩個對象的引用計數將永遠不會變成0,即使這兩個對象沒有被任何其他對象引用。
public class ReferenceCountTest {
public Object ref = null;
public static void main(String ...args) {
ReferenceCountTest objA = new ReferenceCountTest();
ReferenceCountTest objB = new ReferenceCountTest();
// 循環引用 objA <--> objB
objA.ref = objB;
objB.ref = objA;
// 去除外部對這兩個對象引用
objA = null;
objB = null;
System.gc();
}
}
上面的代碼就演示了兩個對象之間出現循環引用的情況。這個時候objA和objB的引用計數都是1,由於兩個對象之間是循環引用的,所以它們的引用計數將一直是1,而即使這兩個對象已經不再被系統所使用到。

由於引用計數這種算法存在這種缺陷,所以就有了一種稱為“可達性分析算法”的算法來標記垃圾對象。
通過可達性分析算法來判斷對象存活,可以克服上面提到的循環引用的問題。在很多編程語言中都采用這種算法來判斷對象是否存活。
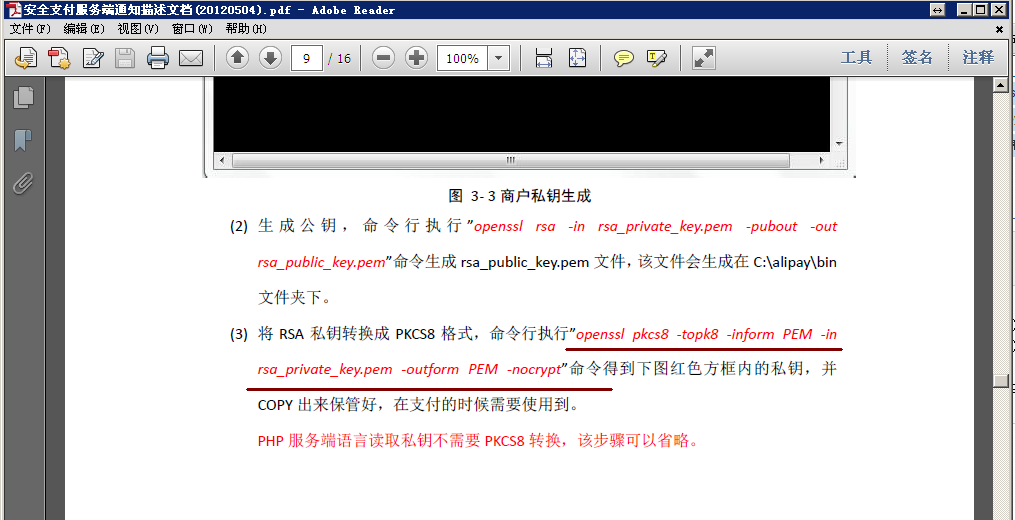
這種算法的基本思路是,確定出一系列的稱為“GC Roots”的對象,以這些對象作為起始點,向下搜索所有可達的對象。搜索過程中所走過的路徑稱為“引用鏈”。當一個對象沒有被任何到“GC Roots”對象的“引用鏈”連接的時候,那麼這個對象就是不可達的,這個對象就被認為是垃圾對象。

從上面的圖中可以看出,object1~4這4個對象,對於GC Roots這個對象來說都是可達的。而object5~7這三個對象,由於沒有連接GC Roots的引用鏈,所以這三個對象時不可達的,被判定為垃圾對象,可以被GC回收。
在Java中,可以作為GC Roots的對象有以下幾種:
當通過可達性分析算法判定為不可達的對象,我們也不能斷定這個對象就是需要被回收的。當我們需要真正回收一個對象的時候,這個對象必須經歷至少兩次標記過程:
當通過可達性分析算法處理以後,這個對象沒有和GC Roots相連的引用鏈,那麼這個對象就會被第一次標記,並判斷對象的finalize()方法(在Java的Object對象中,有一個finalize()方法,我們創建的對象可以選擇是否重寫這個方法的實現)是否需要執行,如果對象的類沒有覆蓋這個finalize()方法或者finalize()已經被執行過了,那麼就不需要再執行一次該方法了。
如果這個對象的finalize()方法需要被執行,那麼這個對象會被放到一個稱為F-Queue的隊列中,這個隊列會被由Java虛擬機自動創建的一個低優先級Finalizer線程去消費,去執行(虛擬機只是觸發這個方法,但是不會等待方法調用返回。這麼做是為了保證:如果方法執行過程中出現阻塞,性能問題或者發生了死循環,Finalizer線程仍舊可以不受影響地消費隊列,不影響垃圾回收的過程)隊列中的對象的finalize()方法。
稍後,GC會對F-Queue隊列中的對象進行第二次標記,如果在這次標記發生的時候,隊列中的對象確實沒有存活(沒有和GC Roots之間有引用鏈),那麼這個對象就確定會被系統回收了。當然,如果在隊列中的對象,在進行第二次標記的時候,突然和GC Roots之間創建了引用鏈,那麼這個對象就"救活"了自己,那麼在第二次標記的時候,這個存活的對象就被移除出待回收的集合了。所以,通過這種兩次標記的機制,我們可以通過在finalize()方法中想辦法讓對象重新和GC Roots對象建立鏈接,那麼這個對象就可以被救活了。
下面的代碼,通過在finalize()方法中將this指針賦值給類的靜態屬性來"拯救"自己:
public class FinalizerTest {
private static Object HOOK_REF;
public static void main(String ...args) throws Exception {
HOOK_REF = new FinalizerTest();
// 將null賦值給HOOK_REF,使得原先創建的對象變成可回收的對象
HOOK_REF = null;
System.gc();
Thread.sleep(1000);
if (HOOK_REF != null) {
System.out.println("first gc, object is alive");
} else {
System.out.println("first gc, object is dead");
}
// 如果對象存活了,再次執行一次上面的代碼
HOOK_REF = null;
System.gc();
if (HOOK_REF != null) {
System.out.println("second gc, object is alive");
} else {
System.out.println("second gc, object is dead");
}
}
@Override
protected void finalize() throws Throwable {
super.finalize();
// 在這裡將this賦值給靜態變量,使對象可以重新和GC Roots對象創建引用鏈
HOOK_REF = this;
System.out.println("execute in finalize()");
}
}
#output:
execute in finalize()
first gc, object is alive
second gc, object is dead
可以看到,第一次執行System.gc()的時候,通過在方法finalize()中將this指針指向HOOK_REF來重建引用鏈接,使得本應該被回收的對象重新復活了。而對比同樣的第二段代碼,沒有成功拯救的原因是:finalize()方法只會被執行一次,所以當第二次將HOOK_REF賦值為null,釋放對對象的引用的時候,由於finalize()方法已經被執行過一次了,所以沒法再通過finalize()方法中的代碼來拯救對象了,導致對象被回收。
上面我們已經知道了怎麼識別出可以回收的垃圾對象。現在,我們需要考慮如何對這些垃圾進行有效的回收。垃圾收集的算法大致可以分為三類:
這三種算法,適用於不同的回收需求和場景。下面,我們來一一介紹下每個回收算法的思想。
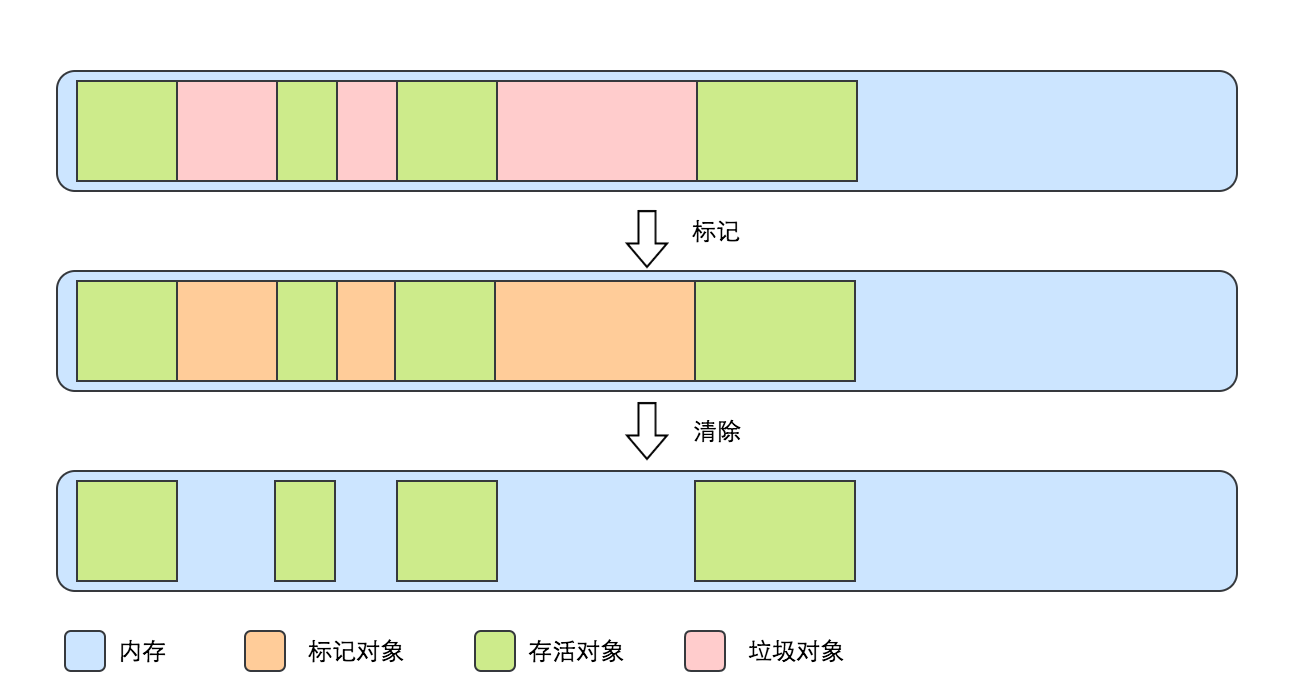
"標記-清除"算法是最基礎的垃圾收集算法。標記-清除算法在執行的時候,分為兩個階段:分別是"標記"階段和"清除"階段。
在標記階段,它會根據上面提到的可達性分析算法標記出哪些對象是可以被回收的,然後在清除階段將這些垃圾對象清理掉。
算法思路很簡單,但是這個算法存在一些缺陷:首先標記和清除這兩個過程的效率不高,其次是,直接將標記的對象清除以後,會導致產生很多不連續的內存碎片,而太多不連續的碎片會導致後續分配大塊內存的時候,沒有連續的空間可以分配,這會導致不得不再次觸發垃圾回收操作,影響性能。
復制算法,顧名思義,和復制操作有關。該算法將內存區域劃分為大小相等的兩塊內存區域,每次只是用其中的一塊區域,另一塊區域閒置備用。當進行垃圾回收的時候,會將當前是用的那塊內存上的存活的對象直接復制到另外一塊閒置的空閒內存上,然後將之前使用的那塊內存上的對象全部清理干淨。
這種處理方式的好處是,可以有效的處理在標記-清除算法中碰到的內存碎片的問題,實現簡單,效率高。但是也有一個問題,由於每次只使用其中的一半內存,所以在運行時會浪費掉一半的內存空間用於復制,內存空間的使用率不高。
標記-整理算法,思路就是先進行垃圾內存的標記,這個和標記-清除算法中的標記階段一樣。當將標記出來的垃圾對象清除以後,為了避免和標記-清除算法中碰到的內存碎片問題,標記-整理算法會對內存區域進行整理。將當前的所有存活的對象移動到內存的一端,將一端的空閒內存整理出來,這樣就可以得到一塊連續的空閒內存空間了。
這樣做,可以很方便地申請新的內存,只要移動內存指針就可以劃出需要的內存區域以存放新的對象,可以在不浪費內存的情況下高效的分配內存,避免了在復制算法中浪費一部分內存的問題。
在現代虛擬機實現中,會將整塊內存劃分為多個區域。用"年齡"的概念來描述內存中的對象的存活時間,並將不同年齡段的對象分類存放在不同的內存區域。這樣,就有了我們平時聽說的"年輕代"、"老年代"等術語。顧名思義,"年輕代"中的對象一般都是剛出生的對象,而"老年代"中的對象,一般都是在程序運行階段長時間存活的對象。
將內存中的對象分代管理的好處是,可以按照不同年齡代的對象的特點,使用合適的垃圾收集算法。
對於"年輕代"中的對象,由於其中的大部分對象的存活時間較短,很多對象都撐不過下一次垃圾收集,所以在年輕代中,一般都使用"復制算法"來實現垃圾收集器。
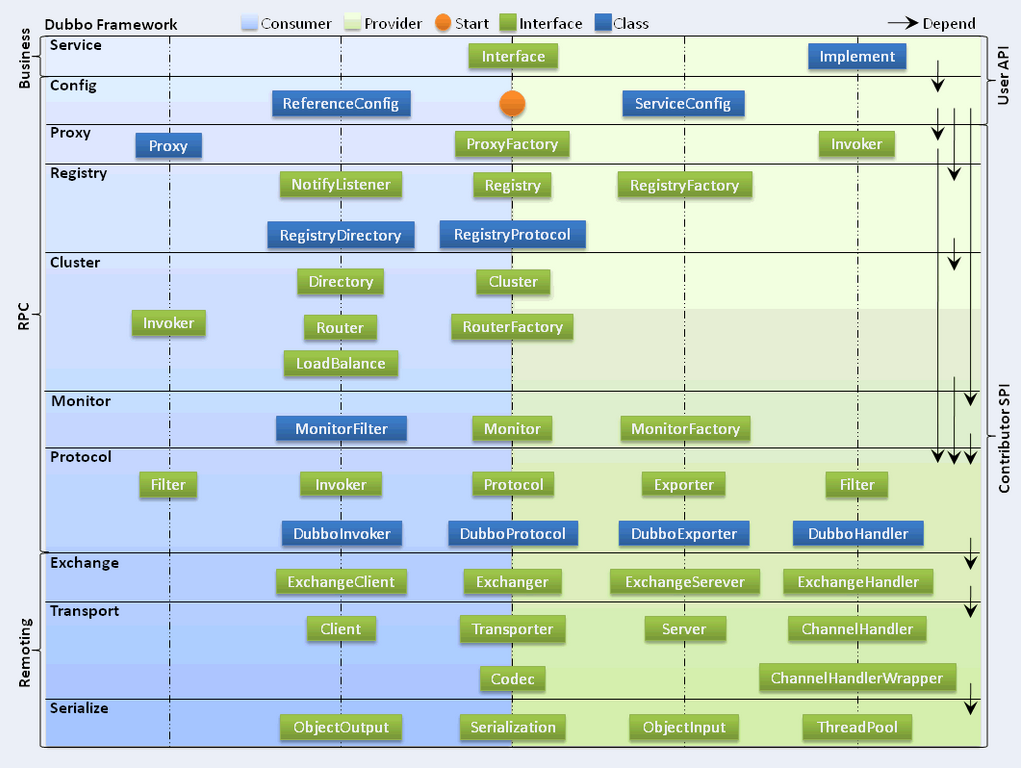
在上圖中,我們可以看到"Young Generation"標記的這塊區域就是"年輕代"。在年輕代中,還細分了三塊區域,分別是:"eden"、"S0"和"S1",其中"eden"是新對象出生的地方,而"S0"和"S1"就是我們在復制算法中說到了那兩塊相等的內存區域,稱為存活區(Survivor Space)。
這裡用於復制的區域只是占用了整個年輕代的一部分,由於在新生代中的對象大部分的存活時間都很短,所以如果按照復制算法中的以1:1的方式來平分年輕代的話,會浪費很多內存空間。所以將年輕代劃分為上圖中所示的,一塊較大的eden區和兩塊同等大小的survivor區,每次只使用eden區和其中的一塊survivor區,當進行內存回收的時候,會將當前存活的對象一次性復制到另一塊空閒的survivor區上,然後將之前使用的eden區和survivor區清理干淨,現在,年輕代可以使用的內存就變成eden區和之前存放存活對象的那個survivor區了,S0和S1這兩塊區域是輪替使用的。
HotSpot虛擬機默認Eden區和其中一塊Survivor區的占比是8:1,通過JVM參數"-XX:SurvivorRatio"控制這個比值。SurvivorRatio的值是一個整數,表示Eden區域是一塊Survivor區域的大小的幾倍,所以,如果SurvivorRatio的值是8,那麼Eden區和其中Survivor區的占比就是8:1,那麼總的年輕代的大小就是(Eden + S0 + S1) = (8 + 1 + 1) = 10,所以年輕代每次可以使用的內存空間就是(Eden + S0) = (8 + 1) = 9,占了整個年輕代的 9 / 10 = 90%,而每次只浪費了10%的內存空間用於復制。
並不是留出越少的空間用於復制操作越好,如果在進行垃圾收集的時候,出現大部分對象都存活的情況,那麼空閒的那塊很小的Survivor區域將不能存放這些存活的對象。當Survivor空間不夠用的時候,如果滿足條件,可以通過分配擔保機制,向老年代申請內存以存放這些存活的對象。
對於老年代的對象,由於在這塊區域中的對象和年輕代的對象相比較而言存活時間都很長,在這塊區域中,一般通過"標記-清理算法"和"標記-整理算法"來實現垃圾收集機制。上圖中的Tenured區域就是老年代所在的區域。而最後那塊Permanent區域,稱之為永久代,在這塊區域中,主要是存放類對象的信息、常量等信息,這個區域也稱為方法區。在Java 8中,移除了永久區,使用元空間(metaspace)代替了。
在這篇文章中,我們首先介紹了采用最簡單的引用計數法來跟蹤垃圾對象和通過可達性分析算法來跟蹤垃圾對象。然後,介紹了垃圾回收中用到的三種回收算法:標記-清除、復制、標記-整理,以及它們各自的優缺點。最後,我們結合上面介紹的三種回收算法,介紹了現代JVM中采用的分代回收機制,以及不同分代采用的回收算法。