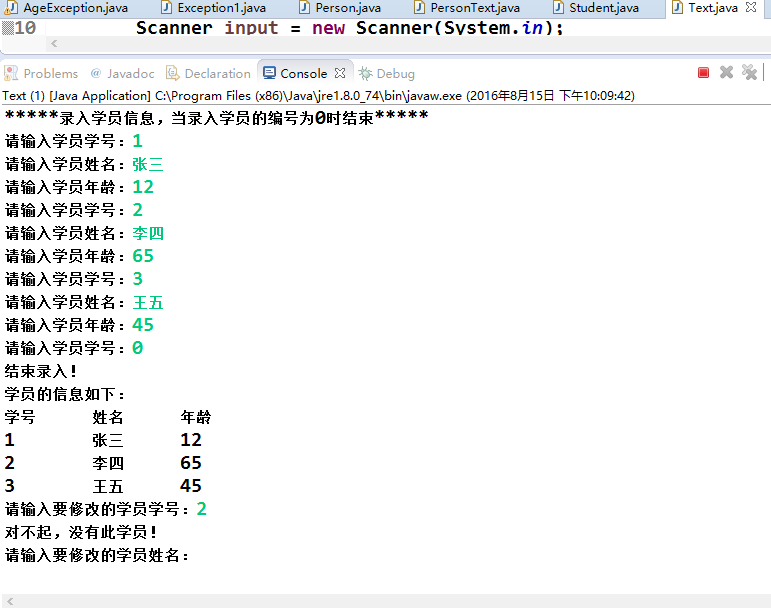
Java異常的機制有三種:
我們知道,一個對象的創建過程經過內存分配,靜態代碼初始化、構造函數執行等過程,對象生成的關鍵步驟是構造函數,那是不是也允許在構造函數中拋出異常呢?從Java語法上來說,完全可以在構造函數中拋出異常,三類異常都可以,但是從系統設計和開發的角度來分析,則盡量不要在構造函數中拋出異常,我們以三種不同類型的異常來說明之。
(1)、構造函數中拋出錯誤是程序員無法處理的
在構造函數執行時,若發生了VirtualMachineError虛擬機錯誤,那就沒招了,只能拋出,程序員不能預知此類錯誤的發生,也就不能捕捉處理。
(2)、構造函數不應該拋出非受檢異常
我們來看這樣一個例子,代碼如下:
class Person {
public Person(int _age) {
// 不滿18歲的用戶對象不能建立
if (_age < 18) {
throw new RuntimeException("年齡必須大於18歲.");
}
}
public void doSomething() {
System.out.println("doSomething......");
}
}
這段代碼的意圖很明顯,年齡不滿18歲的用戶不會生成一個Person實例對象,沒有對象,類行為doSomething方法就不可執行,想法很好,但這會導致不可預測的結果,比如我們這樣引用Person類:
public static void main(String[] args) {
Person p = new Person(17);
p.doSomething();
/*其它的業務邏輯*/
}
很顯然,p對象不能建立,因為是一個RunTimeException異常,開發人員可以捕捉也可以不捕捉,代碼看上去邏輯很正確,沒有任何瑕疵,但是事實上,這段程序會拋出異常,無法執行。這段代碼給了我們兩個警示:
(3)、構造函數盡可能不要拋出受檢異常
我們來看下面的例子,代碼如下:
//父類
class Base {
// 父類拋出IOException
public Base() throws IOException {
throw new IOException();
}
}
//子類
class Sub extends Base {
// 子類拋出Exception異常
public Sub() throws Exception {
}
}
就這麼一段簡單的代碼,展示了在構造函數中拋出受檢異常的三個不利方面:
public static void main(String[] args) {
try {
Base base = new Base();
} catch (Exception e) {
e.printStackTrace();
}
}
然後,我們期望把new Base()替換成new Sub(),而且代碼能夠正常編譯和運行。非常可惜,編譯不通過,原因是Sub的構造函數拋出了Exception異常,它比父類的構造函數拋出更多的異常范圍要寬,必須增加新的catch塊才能解決。
可能大家要問了,為什麼Java的構造函數允許子類的構造函數拋出更廣泛的異常類呢?這正好與類方法的異常機制相反,類方法的異常是這樣要求的:
// 父類
class Base {
// 父類方法拋出Exception
public void testMethod() throws Exception {
}
}
// 子類
class Sub extends Base {
// 父類方法拋出Exception
@Override
public void testMethod() throws IOException {
}
}
子類的方法可以拋出多個異常,但都必須是覆寫方法的子類型,對我們的例子來說,Sub類的testMethod方法拋出的異常必須是Exception的子類或Exception類,這是Java覆寫的要求。構造函數之所以於此相反,是因為構造函數沒有覆寫的概念,只是構造函數間的引用調用而已,所以在構造函數中拋出受檢異常會違背裡氏替換原則原則,使我們的程序缺乏靈活性。
3.子類構造函數擴展受限:子類存在的原因就是期望實現擴展父類的邏輯,但父類構造函數拋出異常卻會讓子類構造函數的靈活性大大降低,例如我們期望這樣的構造函數。
// 父類
class Base {
public Base() throws IOException{
}
}
// 子類
class Sub extends Base {
public Sub() throws Exception{
try{
super();
}catch(IOException e){
//異常處理後再拋出
throw e;
}finally{
//收尾處理
}
}
}
很不幸,這段代碼編譯不通過,原因是構造函數Sub沒有把super()放在第一句話中,想把父類的異常重新包裝再拋出是不可行的(當然,這裡有很多種 “曲線” 的實現手段,比如重新定義一個方法,然後父子類的構造函數都調用該方法,那麼子類構造函數就可以自由處理異常了),這是Java語法機制。
將以上三種異常類型匯總起來,對於構造函數,錯誤只能拋出,這是程序人員無能為力的事情;非受檢異常不要拋出,拋出了 " 對己對人 " 都是有害的;受檢異常盡量不拋出,能用曲線的方式實現就用曲線方式實現,總之一句話:在構造函數中盡可能不出現異常。
注意 :在構造函數中不要拋出異常,盡量曲線實現。
AOP編程可以很輕松的控制一個方法調用哪些類,也能夠控制哪些方法允許被調用,一般來說切面編程(比如AspectJ),只能控制到方法級別,不能實現代碼級別的植入(Weave),比如一個方法被類A的m1方法調用時返回1,在類B的m2方法調用時返回0(同參數情況下),這就要求被調用者具有識別調用者的能力。在這種情況下,可以使用Throwable獲得棧信息,然後鑒別調用者並分別輸出,代碼如下:
class Foo {
public static boolean method() {
// 取得當前棧信息
StackTraceElement[] sts = new Throwable().getStackTrace();
// 檢查是否是methodA方法調用
for (StackTraceElement st : sts) {
if (st.getMethodName().equals("methodA")) {
return true;
}
}
return false;
}
}
//調用者
class Invoker{
//該方法打印出true
public static void methodA(){
System.out.println(Foo.method());
}
//該方法打印出false
public static void methodB(){
System.out.println(Foo.method());
}
}
注意看Invoker類,兩個方法methodA和methodB都調用了Foo的method方法,都是無參調用,返回值卻不同,這是我們的Throwable類發揮效能了。JVM在創建一本Throwable類及其子類時會把當前線程的棧信息記錄下來,以便在輸出異常時准確定位異常原因,我們來看Throwable源代碼。
public class Throwable implements Serializable {
private static final StackTraceElement[] UNASSIGNED_STACK = new StackTraceElement[0];
//出現異常記錄的棧幀
private StackTraceElement[] stackTrace = UNASSIGNED_STACK;
//默認構造函數
public Throwable() {
//記錄棧幀
fillInStackTrace();
}
//本地方法,抓取執行時的棧信息
private native Throwable fillInStackTrace(int dummy);
public synchronized Throwable fillInStackTrace() {
if (stackTrace != null || backtrace != null /* Out of protocol state */) {
fillInStackTrace(0);
stackTrace = UNASSIGNED_STACK;
}
return this;
}
}
在出現異常時(或主動聲明一個Throwable對象時),JVM會通過fillInStackTrace方法記錄下棧幀信息,然後生成一個Throwable對象,這樣我們就可以知道類間的調用順序,方法名稱及當前行號等了。
獲得棧信息可以對調用者進行判斷,然後決定不同的輸出,比如我們的methodA和methodB方法,同樣地輸入參數,同樣的調用方法,但是輸出卻不同,這看起來很想是一個bug:方法methodA調用method方法正常顯示,而方法methodB調用卻會返回錯誤數據,因此我們雖然可以根據調用者的不同產生不同的邏輯,但這僅局限在對此方法的廣泛認知上,更多的時候我們使用method方法的變形體,代碼如下:
class Foo {
public static boolean method() {
// 取得當前棧信息
StackTraceElement[] sts = new Throwable().getStackTrace();
// 檢查是否是methodA方法調用
for (StackTraceElement st : sts) {
if (st.getMethodName().equals("methodA")) {
return true;
}
}
throw new RuntimeException("除了methodA方法外,該方法不允許其它方法調用");
}
}
只是把“return false” 替換成了一個運行期異常,除了methodA方法外,其它方法調用都會產生異常,該方法常用作離線注冊碼校驗,讓破解者視圖暴力破解時,由於執行者不是期望的值,因此會返回一個經過包裝和混淆的異常信息,大大增加了破解難度。
異常只為異常服務,這是何解?難道異常還能為其它服務不成?確實能,異常原本是正常邏輯的一個補充,但是有時候會被當做主邏輯使用,看如下代碼:
//判斷一個枚舉是否包含String枚舉項
public static <T extends Enum<T>> boolean Contain(Class<T> clz,String name){
boolean result = false;
try{
Enum.valueOf(clz, name);
result = true;
}catch(RuntimeException e){
//只要是拋出異常,則認為不包含
}
return result;
}
判斷一個枚舉是否包含指定的枚舉項,這裡會根據valueOf方法是否拋出異常來進行判斷,如果拋出異常(一般是IllegalArgumentException異常),則認為是不包含,若不拋出異常則可以認為包含該枚舉項,看上去這段代碼很正常,但是其中有是哪個錯誤:
我們這段代碼是用一段異常實現了一個正常的業務邏輯,這導致代碼產生了壞味道。要解決從問題也很容易,即不在主邏輯中實使用異常,代碼如下:
// 判斷一個枚舉是否包含String枚舉項
public static <T extends Enum<T>> boolean Contain(Class<T> clz, String name) {
// 遍歷枚舉項
for (T t : clz.getEnumConstants()) {
// 枚舉項名稱是否相等
if (t.name().equals(name)) {
return true;
}
}
return false;
}
異常只能用在非正常的情況下,不能成為正常情況下的主邏輯,也就是說,異常是是主邏輯的輔助場景,不能喧賓奪主。
而且,異常雖然是描述例外事件的,但能避免則避免之,除非是確實無法避免的異常,例如:
public static void main(String[] args) {
File file = new File("a.txt");
try {
FileInputStream fis = new FileInputStream(file);
// 其它業務處理
} catch (FileNotFoundException e) {
e.printStackTrace();
// 異常處理
}
}
這樣一段代碼經常在我們的項目中出現,但經常寫並不代表不可優化,這裡的異常類FileNotFoundException完全可以在它誕生前就消除掉:先判斷文件是否存在,然後再生成FileInputStream對象,這也是項目中常見的代碼:
public static void main(String[] args) {
File file = new File("a.txt");
// 經常出現的異常,可以先做判斷
if (file.exists() && !file.isDirectory()) {
try {
FileInputStream fis = new FileInputStream(file);
// 其它業務處理
} catch (FileNotFoundException e) {
e.printStackTrace();
// 異常處理
}
}
}
雖然增加了if判斷語句,增加了代碼量,但是卻減少了FileNotFoundException異常出現的幾率,提高了程序的性能和穩定性。
我們知道異常是主邏輯的例外邏輯,舉個簡單的例子來說,比如我在馬路上走(這是主邏輯),突然開過一輛車,我要避讓(這是受檢異常,必須處理),繼續走著,突然一架飛機從我頭頂飛過(非受檢異常),我們可以選在繼續行走(不捕捉),也可以選擇指責其噪音污染(捕捉,主邏輯的補充處理),再繼續走著,突然一顆流星砸下來,這沒有選擇,屬於錯誤,不能做任何處理。這樣具備完整例外場景的邏輯就具備了OO的味道,任何一個事務的處理都可能產生非預期的效果,問題是需要以何種手段來處理,如果不使用異常就需要依靠返回值的不同來進行處理了,這嚴重失去了面向對象的風格。
我們在編寫用例文檔(User case Specification)時,其中有一項叫做 " 例外事件 ",是用來描述主場景外的例外場景的,例如用戶登錄的用例,就會在" 例外事件 "中說明" 連續3此登錄失敗即鎖定用戶賬號 ",這就是登錄事件的一個異常處理,具體到我們的程序中就是:
public void login(){
try{
//正常登陸
}catch(InvalidLoginException lie){
// 用戶名無效
}catch(InvalidPasswordException pe){
//密碼錯誤的異常
}catch(TooMuchLoginException){
//多次登陸失敗的異常
}
}
如此設計則可以讓我們的login方法更符合實際的處理邏輯,同時使主邏輯(正常登錄,try代碼塊)更加清晰。當然了,使用異常還有很多優點,可以讓正常代碼和異常代碼分離、能快速查找問題(棧信息快照)等,但是異常有一個缺點:性能比較慢。
Java的異常機制確實比較慢,這個"比較慢"是相對於諸如String、Integer等對象來說的,單單從對象的創建上來說,new一個IOException會比String慢5倍,這從異常的處理機制上也可以解釋:因為它要執行fillInStackTrace方法,要記錄當前棧的快照,而String類則是直接申請一個內存創建對象,異常類慢一籌也就在所難免了。
而且,異常類是不能緩存的,期望先建立大量的異常對象以提高異常性能也是不現實的。
難道異常的性能問題就沒有任何可以提高的辦法了?確實沒有,但是我們不能因為性能問題而放棄使用異常,而且經過測試,在JDK1.6下,一個異常對象的創建時間只需1.4毫秒左右(注意是毫秒,通常一個交易是在100毫秒左右),難道我們的系統連如此微小的性能消耗都不予許嗎?
注意:性能問題不是拒絕異常的借口。