我們編寫一個實現了Serializable接口(序列化標志接口)的類,Eclipse馬上就會給一個黃色警告:需要添加一個Serial Version ID。為什麼要增加?他是怎麼計算出來的?有什麼用?下面就來解釋該問題。
類實現Serializable接口的目的是為了可持久化,比如網絡傳輸或本地存儲,為系統的分布和異構部署提供先決條件支持。若沒有序列化,現在我們熟悉的遠程調用、對象數據庫都不可能存在,我們來看一個簡單的序列化類:
1 import java.io.Serializable;
2 public class Person implements Serializable {
3 private String name;
4
5 public String getName() {
6 return name;
7 }
8
9 public void setName(String name) {
10 this.name = name;
11 }
12
13 }
這是一個簡單的JavaBean,實現了Serializable接口,可以在網絡上傳輸,也可以在本地存儲然後讀取。這裡我們以java消息服務(Java Message Service)方式傳遞對象(即通過網絡傳遞一個對象),定義在消息隊列中的數據類型為ObjectMessage,首先定義一個消息的生產者(Producer),代碼如下:
1 public class Producer {
2 public static void main(String[] args) {
3 Person p = new Person();
4 p.setName("混世魔王");
5 // 序列化,保存到磁盤上
6 SerializationUtils.writeObject(p);
7 }
8 }
這裡引入了一個工具類SerializationUtils,其作用是對一個類進行序列化和反序列化,並存儲到硬盤上(模擬網絡傳輸),其代碼如下:
1 import java.io.FileInputStream;
2 import java.io.FileNotFoundException;
3 import java.io.FileOutputStream;
4 import java.io.IOException;
5 import java.io.ObjectInputStream;
6 import java.io.ObjectOutputStream;
7 import java.io.Serializable;
8
9 public class SerializationUtils {
10 private static String FILE_NAME = "c:/obj.bin";
11 //序列化
12 public static void writeObject(Serializable s) {
13 try {
14 ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream(FILE_NAME));
15 oos.writeObject(s);
16 oos.close();
17 } catch (FileNotFoundException e) {
18 e.printStackTrace();
19 } catch (IOException e) {
20 e.printStackTrace();
21 }
22 }
23 //反序列化
24 public static Object readObject() {
25 Object obj = null;
26 try {
27 ObjectInputStream input = new ObjectInputStream(new FileInputStream(FILE_NAME));
28 obj=input.readObject();
29 input.close();
30 } catch (FileNotFoundException e) {
31 e.printStackTrace();
32 } catch (IOException e) {
33 e.printStackTrace();
34 } catch (ClassNotFoundException e) {
35 e.printStackTrace();
36 }
37 return obj;
38 }
39 }
通過對象序列化過程,把一個內存塊轉化為可傳輸的數據流,然後通過網絡發送到消息消費者(Customer)哪裡,進行反序列化,生成實驗對象,代碼如下:
1 public class Customer {
2 public static void main(String[] args) {
3 //反序列化
4 Person p=(Person) SerializationUtils.readObject();
5 System.out.println(p.getName());
6 }
7 }
這是一個反序列化的過程,也就是對象數據流轉換為一個實例的過程,其運行後的輸出結果為“混世魔王”。這太easy了,是的,這就是序列化和反序列化的典型Demo。但此處藏著一個問題:如果消息的生產者和消息的消費者(Person類)有差異,會出現何種神奇事件呢?比如:消息生產者中的Person類添加一個年齡屬性,而消費者沒有增加該屬性。為啥沒有增加?因為這個是分布式部署的應用,你甚至不知道這個應用部署在何處,特別是通過廣播方式發消息的情況,漏掉一兩個訂閱者也是很正常的。
這中序列化和反序列化的類在不一致的情況下,反序列化時會報一個InalidClassException異常,原因是序列化和反序列化所對應的類版本發生了變化,JVM不能把數據流轉換為實例對象。刨根問底:JVM是根據什麼來判斷一個類的版本呢?
好問題,通過SerializableUID,也叫做流標識符(Stream Unique Identifier),即類的版本定義的,它可以顯示聲明也可以隱式聲明。顯示聲明格式如下:
private static final long serialVersionUID = 1867341609628930239L;
而隱式聲明則是我不聲明,你編譯器在編譯的時候幫我生成。生成的依據是通過包名、類名、繼承關系、非私有的方法和屬性,以及參數、返回值等諸多因子算出來的,極度復雜,基本上計算出來的這個值是唯一的。
serialVersionUID如何生成已經說明了,我們再來看看serialVersionUID的作用。JVM在反序列化時,會比較數據流中的serialVersionUID與類的serialVersionUID是否相同,如果相同,則認為類沒有改變,可以把數據load為實例相同;如果不相同,對不起,我JVM不干了,拋個異常InviladClassException給你瞧瞧。這是一個非常好的校驗機制,可以保證一個對象即使在網絡或磁盤中“滾過”一次,仍能做到“出淤泥而不染”,完美的實現了類的一致性。
但是,有時候我們需要一點特例場景,例如我的類改變不大,JVM是否可以把我以前的對象反序列化回來?就是依據顯示聲明的serialVersionUID,向JVM撒謊說"我的類版本沒有變化",如此我買你編寫的類就實現了向上兼容,我們修改Person類,裡面添加private static final long serialVersionUID = 1867341609628930239L;
剛開始生產者和消費者持有的Person類一致,都是V1.0,某天生產者的Person類變更了,增加了一個“年齡”屬性,升級為V2.0,由於種種原因(比如程序員疏忽,升級時間窗口不同等)消費端的Person類還是V1.0版本,添加的代碼為 priavte int age;以及對應的setter和getter方法。
此時雖然生產這和消費者對應的類版本不同,但是顯示聲明的serialVersionUID相同,序列化也是可以運行的,所帶來的業務問題就是消費端不能讀取到新增的業務屬性(age屬性而已)。通過此例,我們反序列化也實現了版本向上兼容的功能,使用V1.0版本的應用訪問了一個V2.0的對象,這無疑提高了代碼的健壯性。我們在編寫序列化類代碼時隨手添加一個serialVersionUID字段,也不會帶來太多的工作量,但它卻可以在關鍵時候發揮異乎尋常的作用。
顯示聲明serialVersionUID可以避免對象的不一致,但盡量不要以這種方式向JVM撒謊。
我們知道帶有final標識的屬性是不變量,也就是只能賦值一次,不能重復賦值,但是在序列化類中就有點復雜了,比如這個類:
1 public class Person implements Serializable {
2 private static final long serialVersionUID = 1867341609628930239L;
3 public final String perName="程咬金";
4 }
這個Peson類(此時V1.0版本)被序列化,然後存儲在磁盤上,在反序列化時perName屬性會重新計算其值(這與static變量不同,static變量壓根就沒有保存到數據流中)比如perName屬性修改成了"秦叔寶"(版本升級為V2.0),那麼反序列化的perName值就是"秦叔寶"。保持新舊對象的final變量相同,有利於代碼業務邏輯統一,這是序列化的基本原則之一,也就是說,如果final屬性是一個直接量,在反序列化時就會重新計算。對於基本原則不多說,現在說一下final變量的另一種賦值方式:通過構造函數賦值。代碼如下:
public class Person implements Serializable {
private static final long serialVersionUID = 1867341609628930239L;
public final String perName;
public Person() {
perName = "程咬金";
}
}
這也是我們常用的一種賦值方式,可以把Person類定義為版本V1.0,然後進行序列化,看看序列化後有什麼問題,序列化代碼如下:
public class Serialize {
public static void main(String[] args) {
//序列化以持久保持
SerializationUtils.writeObject(new Person());
}
}
Person的實習對象保存到了磁盤上,它時一個貧血對象(承載業務屬性定義,但不包含其行為定義),我們做一個簡單的模擬,修改一下PerName值代表變更,要注意的是serialVersionUID不變,修改後的代碼如下:
public class Person implements Serializable {
private static final long serialVersionUID = 1867341609628930239L;
public final String perName;
public Person() {
perName = "秦叔寶";
}
}
此時Person類的版本時V2.0但serialVersionUID沒有改變,仍然可以反序列化,代碼如下:
public class Deserialize {
public static void main(String[] args) {
Person p = (Person) SerializationUtils.readObject();
System.out.println(p.perName);
}
}
現在問題出來了,打印出來的結果是"程咬金" 還是"秦叔寶"?答案是:"程咬金"。final類型的變量不是會重新計算嘛,打印出來的應該是秦叔寶才對呀。為什麼會是程咬金?這是因為這裡觸及到了反序列化的兩一個原則:反序列化時構造函數不會執行.
反序列化的執行過程是這樣的:JVM從數據流中獲取一個Object對象,然後根據數據流中的類文件描述信息(在序列化時,保存到磁盤的對象文件中包含了類描述信息,注意是描述信息,不是類)查看,發現是final變量,需要重新計算,於是引用Person類中的perName值,而此時JVM又發現perName竟沒有賦值,不能引用,於是它很聰明的不再初始化,保持原值狀態,所以結果就是"程咬金"了。
注意:在序列化類中不使用構造函數為final變量賦值.
為final變量賦值還有另外一種方式:通過方法賦值,及直接在聲明時通過方法的返回值賦值,還是以Person類為例來說明,代碼如下:
public class Person implements Serializable {
private static final long serialVersionUID = 1867341609628930239L;
//通過方法返回值為final變量賦值
public final String pName = initName();
public String initName() {
return "程咬金";
}
}
pName屬性是通過initName方法的返回值賦值的,這在復雜的類中經常用到,這比使用構造函數賦值更簡潔,易修改,那麼如此用法在序列化時會不會有問題呢?我們一起看看。Person類寫好了(定義為V1.0版本),先把它序列化,存儲到本地文件,其代碼與之前相同,不在贅述。現在Person類的代碼需要修改,initName的返回值改為"秦叔寶".那麼我們之前存儲在磁盤上的的實例加載上來,pName的會是什麼呢?
現在,Person類的代碼需要修改,initName的返回值也改變了,代碼如下:
public class Person implements Serializable {
private static final long serialVersionUID = 1867341609628930239L;
//通過方法返回值為final變量賦值
public final String pName = initName();
public String initName() {
return "秦叔寶";
}
}
上段代碼僅僅修改了initName的返回值(Person類為V2.0版本)也就是通過new生成的對象的final變量的值都是"秦叔寶",那麼我們把之前存儲在磁盤上的實例加載上來,pName的值會是什麼呢?
結果是"程咬金",很詫異,上一建議說過final變量會被重新賦值,但是這個例子又沒有重新賦值,為什麼?
上個建議說的重新賦值,其中的"值"指的是簡單對象。簡單對象包括:8個基本類型,以及數組、字符串(字符串情況復雜,不通過new關鍵字生成的String對象的情況下,final變量的賦值與基本類型相同),但是不能方法賦值。
其中的原理是這樣的,保存到磁盤上(或網絡傳輸)的對象文件包括兩部分:
(1).類描述信息:包括類路徑、繼承關系、訪問權限、變量描述、變量訪問權限、方法簽名、返回值、以及變量的關聯類信息。要注意一點是,它並不是class文件的翻版,它不記錄方法、構造函數、static變量等的具體實現。之所以類描述會被保存,很簡單,是因為能去也能回嘛,這保證反序列化的健壯運行。
(2).非瞬態(transient關鍵字)和非靜態(static關鍵字)的實體變量值
注意,這裡的值如果是一個基本類型,好說,就是一個簡單值保存下來;如果是復雜對象,也簡單,連該對象和關聯類信息一起保存,並且持續遞歸下去(關聯類也必須實現Serializable接口,否則會出現序列化異常),也就是遞歸到最後,還是基本數據類型的保存。
正是因為這兩個原因,一個持久化的對象文件會比一個class類文件大很多,有興趣的讀者可以自己測試一下,體積確實膨脹了不少。
總結一下:反序列化時final變量在以下情況下不會被重新賦值:
部分屬性持久化問題看似很簡單,只要把不需要持久化的屬性加上瞬態關鍵字(transient關鍵字)即可。這是一種解決方案,但有時候行不通。例如一個計稅系統和一個HR系統,通過RMI(Remote Method Invocation,遠程方法調用)對接,計稅系統需要從HR系統獲得人員的姓名和基本工資,以作為納稅的依據,而HR系統的工資分為兩部分:基本工資和績效工資,基本工資沒什麼秘密,績效工資是保密的,不能洩露到外系統,這明顯是連個相互關聯的類,先看看薪水類Salary的代碼:
1 public class Salary implements Serializable {
2 private static final long serialVersionUID = 2706085398747859680L;
3 // 基本工資
4 private int basePay;
5 // 績效工資
6 private int bonus;
7
8 public Salary(int _basepay, int _bonus) {
9 this.basePay = _basepay;
10 this.bonus = _bonus;
11 }
12 //Setter和Getter方法略
13
14 }
Person類和Salary類是關聯關系,代碼如下:
1 public class Person implements Serializable {
2
3 private static final long serialVersionUID = 9146176880143026279L;
4
5 private String name;
6
7 private Salary salary;
8
9 public Person(String _name, Salary _salary) {
10 this.name = _name;
11 this.salary = _salary;
12 }
13
14 //Setter和Getter方法略
15
16 }
這是兩個簡單的JavaBean,都實現了Serializable接口,具備了序列化的條件。首先計稅系統請求HR系統對一個Person對象進行序列化,把人員信息和工資信息傳遞到計稅系統中,代碼如下:
1 public class Serialize {
2 public static void main(String[] args) {
3 // 基本工資1000元,績效工資2500元
4 Salary salary = new Salary(1000, 2500);
5 // 記錄人員信息
6 Person person = new Person("張三", salary);
7 // HR系統持久化,並傳遞到計稅系統
8 SerializationUtils.writeObject(person);
9 }
10 }
在通過網絡傳輸到計稅系統後,進行反序列化,代碼如下:
1 public class Deserialize {
2 public static void main(String[] args) {
3 Person p = (Person) SerializationUtils.readObject();
4 StringBuffer buf = new StringBuffer();
5 buf.append("姓名: "+p.getName());
6 buf.append("\t基本工資: "+p.getSalary().getBasePay());
7 buf.append("\t績效工資: "+p.getSalary().getBonus());
8 System.out.println(buf);
9 }
10 }
打印出的結果為:姓名: 張三 基本工資: 1000 績效工資: 2500
但是這不符合需求,因為計稅系統只能從HR系統中獲取人員姓名和基本工資,而績效工資是不能獲得的,這是個保密數據,不允許發生洩漏。怎麼解決這個問題呢?你可能會想到以下四種方案:
下面展示一個優秀的方案,其中實現了Serializable接口的類可以實現兩個私有方法:writeObject和readObject,以影響和控制序列化和反序列化的過程。我們把Person類稍作修改,看看如何控制序列化和反序列化,代碼如下:
1 public class Person implements Serializable {
2
3 private static final long serialVersionUID = 9146176880143026279L;
4
5 private String name;
6
7 private transient Salary salary;
8
9 public Person(String _name, Salary _salary) {
10 this.name = _name;
11 this.salary = _salary;
12 }
13 //序列化委托方法
14 private void writeObject(ObjectOutputStream oos) throws IOException {
15 oos.defaultWriteObject();
16 oos.writeInt(salary.getBasePay());
17 }
18 //反序列化委托方法
19 private void readObject(ObjectInputStream input)throws ClassNotFoundException, IOException {
20 input.defaultReadObject();
21 salary = new Salary(input.readInt(), 0);
22 }
23 }
其它代碼不做任何改動,運行之後結果為:姓名: 張三 基本工資: 1000 績效工資: 0
在Person類中增加了writeObject和readObject兩個方法,並且訪問權限都是私有級別,為什麼會改變程序的運行結果呢?其實這裡用了序列化的獨有機制:序列化回調。Java調用ObjectOutputStream類把一個對象轉換成數據流時,會通過反射(Refection)檢查被序列化的類是否有writeObject方法,並且檢查其是否符合私有,無返回值的特性,若有,則會委托該方法進行對象序列化,若沒有,則由ObjectOutputStream按照默認規則繼續序列化。同樣,在從流數據恢復成實例對象時,也會檢查是否有一個私有的readObject方法,如果有,則會通過該方法讀取屬性值,此處有幾個關鍵點需要說明:
分別是寫入和讀出相應的值,類似一個隊列,先進先出,如果此處有復雜的數據邏輯,建議按封裝Collection對象處理。大家可能注意到上面的方式也是Person失去了分布式部署的能了,確實是,但是HR系統的難點和重點是薪水的計算,特別是績效工資,它所依賴的參數很復雜(僅從數量上說就有上百甚至上千種),計算公式也不簡單(一般是引入腳本語言,個性化公式定制)而相對來說Person類基本上都是靜態屬性,計算的可能性不大,所以即使為性能考慮,Person類為分布式部署的意義也不大。
我們經常會寫一些轉換類,比如貨幣轉換,日期轉換,編碼轉換等,在金融領域裡用到的最多的要數中文數字轉換了,比如把"1"轉換為"壹" ,不過開源工具是不會提供此工具類的,因為它太貼近中國文化了,需要自己編寫:
1 public class Client15 {
2 public static void main(String[] args) {
3 System.out.println(toChineseNuberCase(0));
4 }
5
6 public static String toChineseNuberCase(int n) {
7 String chineseNumber = "";
8 switch (n) {
9 case 0:
10 chineseNumber = "零";
11 case 1:
12 chineseNumber = "壹";
13 case 2:
14 chineseNumber = "貳";
15 case 3:
16 chineseNumber = "三";
17 case 4:
18 chineseNumber = "肆";
19 case 5:
20 chineseNumber = "伍";
21 case 6:
22 chineseNumber = "陸";
23 case 7:
24 chineseNumber = "柒";
25 case 8:
26 chineseNumber = "捌";
27 case 9:
28 chineseNumber = "玖";
29 }
30 return chineseNumber;
31 }
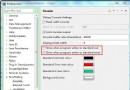
32 }
這是一個簡單的代碼,但運行結果卻是"玖",這個很簡單,可能大家在剛接觸語法時都學過,但雖簡單,如果程序員漏寫了,簡單的問題會造成很大的後果,甚至經濟上的損失。所以在用switch語句上記得加上break,養成良好的習慣。對於此類問題,除了平常小心之外,可以使用單元測試來避免,但大家都曉得,項目緊的時候,可能但單元測試都覆蓋不了。所以對於此類問題,一個最簡單的辦法就是:修改IDE的警告級別,例如在Eclipse中,可以依次點擊PerFormaces-->Java-->Compiler-->Errors/Warings-->Potential Programming problems,然後修改'switch' case fall-through為Errors級別,如果你膽敢不在case語句中加入break,那Eclipse直接就報個紅叉給你看,這樣可以避免該問題的發生了。但還是啰嗦一句,養成良好習慣更重要!