如果兩個操作訪問同一個變量,且這兩個操作中有一個為寫操作,此時這兩個操作之間就存在數據依賴性。數據依賴分下列三種類型:
名稱 代碼示例 說明 寫後讀 a = 1;b = a; 寫一個變量之後,再讀這個位置。 寫後寫 a = 1;a = 2; 寫一個變量之後,再寫這個變量。 讀後寫 a = b;b = 1; 讀一個變量之後,再寫這個變量。上面三種情況,只要重排序兩個操作的執行順序,程序的執行結果將會被改變。
前面提到過,編譯器和處理器可能會對操作做重排序。編譯器和處理器在重排序時,會遵守數據依賴性,編譯器和處理器不會改變存在數據依賴關系的兩個操作的執行順序。
注意,這裡所說的數據依賴性僅針對單個處理器中執行的指令序列和單個線程中執行的操作,不同處理器之間和不同線程之間的數據依賴性不被編譯器和處理器考慮。
as-if-serial 語義的意思指:不管怎麼重排序(編譯器和處理器為了提高並行度),(單線程)程序的執行結果不能被改變。編譯器,runtime 和處理器都必須遵守 as-if-serial 語義。
為了遵守 as-if-serial 語義,編譯器和處理器不會對存在數據依賴關系的操作做重排序,因為這種重排序會改變執行結果。但是,如果操作之間不存在數據依賴關系,這些操作可能被編譯器和處理器重排序。為了具體說明,請看下面計算圓面積的代碼示例:
double pi = 3.14; //A double r = 1.0; //B double area = pi * r * r; //C
上面三個操作的數據依賴關系如下圖所示:
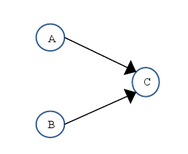
如上圖所示,A 和 C 之間存在數據依賴關系,同時 B 和 C 之間也存在數據依賴關系。因此在最終執行的指令序列中,C 不能被重排序到 A 和 B 的前面(C 排到 A 和 B 的前面,程序的結果將會被改變)。但 A 和 B 之間沒有數據依賴關系,編譯器和處理器可以重排序 A 和 B 之間的執行順序。下圖是該程序的兩種執行順序:
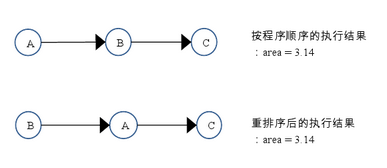
as-if-serial 語義把單線程程序保護了起來,遵守 as-if-serial 語義的編譯器,runtime 和處理器共同為編寫單線程程序的程序員創建了一個幻覺:單線程程序是按程序的順序來執行的。as-if-serial 語義使單線程程序員無需擔心重排序會干擾他們,也無需擔心內存可見性問題。
根據 happens- before 的程序順序規則,上面計算圓的面積的示例代碼存在三個 happens- before 關系:
這裡的第3個 happens- before 關系,是根據 happens- before 的傳遞性推導出來的。
這裡 A happens- before B,但實際執行時 B 卻可以排在 A 之前執行(看上面的重排序後的執行順序)。在第一章提到過,如果 A happens- before B,JMM 並不要求 A 一定要在 B 之前執行。JMM 僅僅要求前一個操作(執行的結果)對後一個操作可見,且前一個操作按順序排在第二個操作之前。這裡操作 A 的執行結果不需要對操作 B 可見;而且重排序操作 A 和操作 B 後的執行結果,與操作 A 和操作 B 按 happens- before 順序執行的結果一致。在這種情況下,JMM 會認為這種重排序並不非法(not illegal),JMM 允許這種重排序。
在計算機中,軟件技術和硬件技術有一個共同的目標:在不改變程序執行結果的前提下,盡可能的開發並行度。編譯器和處理器遵從這一目標,從 happens- before 的定義我們可以看出,JMM 同樣遵從這一目標。
現在讓我們來看看,重排序是否會改變多線程程序的執行結果。請看下面的示例代碼:
class ReorderExample {
int a = 0;
boolean flag = false;
public void writer() {
a = 1; //1
flag = true; //2
}
Public void reader() {
if (flag) { //3
int i = a * a; //4
……
}
}
}
flag 變量是個標記,用來標識變量 a 是否已被寫入。這裡假設有兩個線程 A 和 B,A 首先執行writer() 方法,隨後 B 線程接著執行 reader() 方法。線程B在執行操作4時,能否看到線程 A 在操作1對共享變量 a 的寫入?
答案是:不一定能看到。
由於操作1和操作2沒有數據依賴關系,編譯器和處理器可以對這兩個操作重排序;同樣,操作3和操作4沒有數據依賴關系,編譯器和處理器也可以對這兩個操作重排序。讓我們先來看看,當操作1和操作2重排序時,可能會產生什麼效果?請看下面的程序執行時序圖:
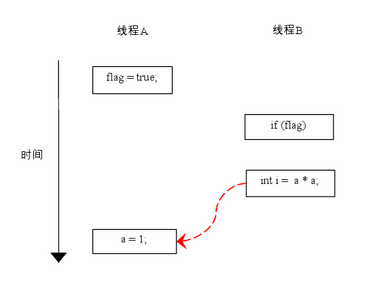
如上圖所示,操作1和操作2做了重排序。程序執行時,線程A首先寫標記變量 flag,隨後線程 B 讀這個變量。由於條件判斷為真,線程 B 將讀取變量a。此時,變量 a 還根本沒有被線程 A 寫入,在這裡多線程程序的語義被重排序破壞了!
※注:本文統一用紅色的虛箭線表示錯誤的讀操作,用綠色的虛箭線表示正確的讀操作。
下面再讓我們看看,當操作3和操作4重排序時會產生什麼效果(借助這個重排序,可以順便說明控制依賴性)。下面是操作3和操作4重排序後,程序的執行時序圖:
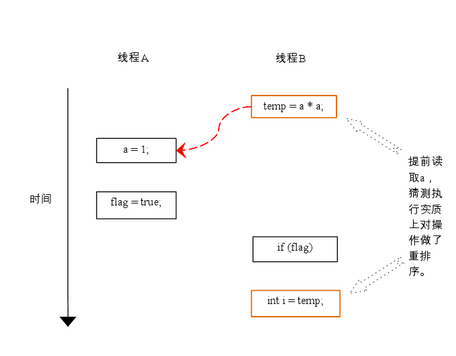
在程序中,操作3和操作4存在控制依賴關系。當代碼中存在控制依賴性時,會影響指令序列執行的並行度。為此,編譯器和處理器會采用猜測(Speculation)執行來克服控制相關性對並行度的影響。以處理器的猜測執行為例,執行線程 B 的處理器可以提前讀取並計算 a*a,然後把計算結果臨時保存到一個名為重排序緩沖(reorder buffer ROB)的硬件緩存中。當接下來操作3的條件判斷為真時,就把該計算結果寫入變量i中。
從圖中我們可以看出,猜測執行實質上對操作3和4做了重排序。重排序在這裡破壞了多線程程序的語義!
在單線程程序中,對存在控制依賴的操作重排序,不會改變執行結果(這也是 as-if-serial 語義允許對存在控制依賴的操作做重排序的原因);但在多線程程序中,對存在控制依賴的操作重排序,可能會改變程序的執行結果。