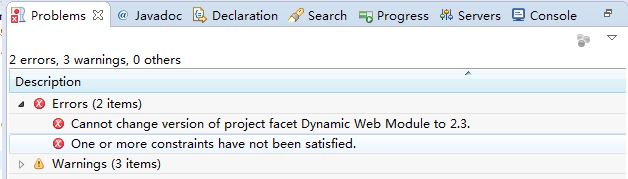
是Apache軟件基金會的一個項目,是一個開發源碼的全文檢索引擎工具包,是一個全文檢索引擎的一個架構。提供了完成的查詢引擎和檢索引擎,部分文本分析引擎。
全文檢索程序庫,雖然與搜索引擎相關,但是不能混淆。
官方網址:https://lucene.apache.org/
幫助文檔:https://lucene.apache.org/core/4_9_1/index.html
官方解釋:
Lucene is a Java full-text search engine. Lucene is not a complete application, but rather a code library and API that can easily be used to add search capabilities to applications.
了解Luence要知道倒排索引;
通俗解釋,我們通常都是通過查找文件位置及文件名,再查找文件的內容。倒排索引可以理解為通過文件內容來查找文件位置及文件名的。
倒排索引是一種索引方法,被用來存儲在全文搜索下某個單詞在一個文檔或者一組文檔中的存儲位置的映射。它是文檔檢索系統中最常用的數據結構。通過倒排索引,可以根據單詞快速獲取包含這個單詞的文檔列表。
倒排索引也是lucence的索引核心。
文件內容可以表示一個field,文件名稱可以表示一個field,將整個field進行分詞,然後根據分詞創建索引,建立一個個term;
如:文件的內容作為一個field,命名為"contents",將文件內容進行分詞,假設文件內容為"A B",分詞結果為"A","B",這樣term的信息就為兩條,field的內容為"contents",term對應的文本內容分別為"A"和"B"。
當查找指定分詞的時候就可以獲取這個分詞所在的doc,並獲取doc相關的信息。
例子參考官方demo; package位置:org.apache.lucene.demo
自己寫了一個demo
依賴的jar包:
commons-io-2.4.jar
lucene-analyzers-common-4.9.1.jar
lucene-core-4.9.1.jar
lucene-queries-4.9.1.jar
lucene-queryparser-4.9.1.jar
MyIndexFiles.java
1 import org.apache.commons.io.FileUtils;
2 import org.apache.lucene.analysis.Analyzer;
3 import org.apache.lucene.analysis.standard.StandardAnalyzer;
4 import org.apache.lucene.document.*;
5 import org.apache.lucene.index.*;
6 import org.apache.lucene.queryparser.classic.ParseException;
7 import org.apache.lucene.queryparser.classic.QueryParser;
8 import org.apache.lucene.search.IndexSearcher;
9 import org.apache.lucene.search.Query;
10 import org.apache.lucene.search.ScoreDoc;
11 import org.apache.lucene.search.TopDocs;
12 import org.apache.lucene.store.Directory;
13 import org.apache.lucene.store.FSDirectory;
14 import org.apache.lucene.util.Version;
15 import org.junit.Test;
16
17 import java.io.File;
18 import java.io.IOException;
19
20 /**
21 * Created by Edward on 2016/7/25.
22 */
23 public class MyIndexFiles {
24
25
26 public static void main(String[] args) throws IOException {
27
28 //文件方式存儲索引文件
29 FSDirectory directory = FSDirectory.open(new File("D:\\documents\\Lucene\\MyDemo\\index"));
30
31 //文本解析器,分詞器
32 Analyzer analyzer= new StandardAnalyzer(Version.LUCENE_4_9);
33
34 //索引寫配置,要指定解析器及版本信息
35 IndexWriterConfig indexWriterConfig = new IndexWriterConfig(Version.LUCENE_4_9, analyzer);
36
37 //創建寫索引
38 IndexWriter indexWriter = new IndexWriter(directory, indexWriterConfig );
39
40 //路徑
41 File path = new File("D:\\documents\\Lucene\\MyDemo\\docs");
42 //文件列表
43 File[] listFile = path.listFiles();
44 for(File file: listFile){
45 //創建doc
46 Document doc = new Document();
47
48 //獲取文件屬性信息
49 String filename = file.getName();
50 long lastModified = file.lastModified();
51
52 //通過commons-io-2.4.jar包中的FileUtils方法,讀文件內容轉化為String
53 String readFile2Sting = FileUtils.readFileToString(file);
54
55 //將field添加到doc
56 //StringField不進行分詞,當做一個分詞
57 //Field的有索引和存儲屬性,
58 //Field.Store.NO代表數據不進行存儲,僅能索引到,多用來處理文本內容,可獲取文件名然後通過文件位置打開文件獲取內容
59 //Field.Store.YES代表存儲數據,通常用來直接獲取文件路徑
60 doc.add(new StringField("filename", filename, Field.Store.YES));
61 doc.add(new LongField("modify", lastModified, Field.Store.YES));
62 doc.add(new TextField("contents",readFile2Sting, Field.Store.NO));
63
64 //新增的方式
65 //indexWriter.addDocument(doc);
66
67 //更新的方式, 更新與term匹配的docs
68 indexWriter.updateDocument(new Term("filename", file.getName()), doc);
69 }
70 indexWriter.close();
71 }
72
73
74 @Test
75 public void serach() throws IOException, ParseException {
76
77 //本地索引文件
78 Directory directory = FSDirectory.open(new File("D:\\documents\\Lucene\\MyDemo\\index"));
79
80 //讀索引目錄
81 IndexReader indexReader = DirectoryReader.open(directory);
82
83 //創建索引搜索對象
84 IndexSearcher indexSearcher = new IndexSearcher(indexReader);
85
86 Analyzer analyzer= new StandardAnalyzer(Version.LUCENE_4_9);
87
88 //查詢解析 指定查詢的item,解析器,版本
89 QueryParser queryParse = new QueryParser(Version.LUCENE_4_9, "contents", analyzer);
90
91 //查詢內容
92 Query query = queryParse.parse("111");
93
94 //查詢指定條數
95 int num = 6;
96 TopDocs topDocs= indexSearcher.search(query, num);
97
98 //采集數
99 ScoreDoc[] docs = topDocs.scoreDocs;
100
101 for(ScoreDoc doc:docs){
102
103 //獲取doc編號
104 int i = doc.doc;
105
106 //通過文檔編號獲取文檔信息
107 Document d = indexSearcher.doc(i);
108
109 //打印文檔信息
110 System.out.println(d.get("filename"));
111 System.out.println(d.get("modify"));
112 System.out.println(d.get("contents"));
113 }
114 indexReader.close();
115 }
116
117 }