在過去單 CPU 時代,單任務在一個時間點只能執行單一程序。之後發展到多任務階段,計算機能在同一時間點並行執行多任務或多進程。雖然並不是真正意義上的“同一時間點”,而是多個任務或進程共享一個 CPU,並交由操作系統來完成多任務間對 CPU 的運行切換,以使得每個任務都有機會獲得一定的時間片運行。
隨著多任務對軟件開發者帶來的新挑戰,程序不在能假設獨占所有的 CPU 時間、所有的內存和其他計算機資源。一個好的程序榜樣是在其不再使用這些資源時對其進行釋放,以使得其他程序能有機會使用這些資源。
再後來發展到多線程技術,使得在一個程序內部能擁有多個線程並行執行。一個線程的執行可以被認為是一個 CPU 在執行該程序。當一個程序運行在多線程下,就好像有多個 CPU 在同時執行該程序。
多線程比多任務更加有挑戰。多線程是在同一個程序內部並行執行,因此會對相同的內存空間進行並發讀寫操作。這可能是在單線程程序中從來不會遇到的問題。其中的一些錯誤也未必會在單 CPU 機器上出現,因為兩個線程從來不會得到真正的並行執行。然而,更現代的計算機伴隨著多核 CPU 的出現,也就意味著不同的線程能被不同的 CPU 核得到真正意義的並行執行。
如果一個線程在讀一個內存時,另一個線程正向該內存進行寫操作,那進行讀操作的那個線程將獲得什麼結果呢?是寫操作之前舊的值?還是寫操作成功之後的新值?或是一半新一半舊的值?或者,如果是兩個線程同時寫同一個內存,在操作完成後將會是什麼結果呢?是第一個線程寫入的值?還是第二個線程寫入的值?還是兩個線程寫入的一個混合值?因此如沒有合適的預防措施,任何結果都是可能的。而且這種行為的發生甚至不能預測,所以結果也是不確定性的。
Java 是最先支持多線程的開發的語言之一,Java 從一開始就支持了多線程能力,因此 Java 開發者能常遇到上面描述的問題場景。
該系列主要關注 Java 多線程,但有些在多線程中出現的問題會和多任務以及分布式系統中出現的存在類似,因此該系列會將多任務和分布式系統方面作為參考,所以叫法上稱為“並發性”,而不是“多線程”。
盡管面臨很多挑戰,多線程有一些優點使得它一直被使用。這些優點是:
想象一下,一個應用程序需要從本地文件系統中讀取和處理文件的情景。比方說,從磁盤讀取一個文件需要 5 秒,處理一個文件需要 2 秒。處理兩個文件則需要:
5秒讀取文件A 2秒處理文件A 5秒讀取文件B 2秒處理文件B --------------------- 總共需要14秒
從磁盤中讀取文件的時候,大部分的 CPU 時間用於等待磁盤去讀取數據。在這段時間裡,CPU 非常的空閒。它可以做一些別的事情。通過改變操作的順序,就能夠更好的使用 CPU 資源。看下面的順序:
5秒讀取文件A 5秒讀取文件B + 2秒處理文件A 2秒處理文件B --------------------- 總共需要12秒
CPU 等待第一個文件被讀取完。然後開始讀取第二個文件。當第二文件在被讀取的時候,CPU 會去處理第一個文件。記住,在等待磁盤讀取文件的時候,CPU大 部分時間是空閒的。
總的說來,CPU 能夠在等待 IO 的時候做一些其他的事情。這個不一定就是磁盤 IO。它也可以是網絡的 IO,或者用戶輸入。通常情況下,網絡和磁盤的 IO 比 CPU 和內存的 IO 慢的多。
在單線程應用程序中,如果你想編寫程序手動處理上面所提到的讀取和處理的順序,你必須記錄每個文件讀取和處理的狀態。相反,你可以啟動兩個線程,每個線程處理一個文件的讀取和操作。線程會在等待磁盤讀取文件的過程中被阻塞。在等待的時候,其他的線程能夠使用 CPU 去處理已經讀取完的文件。其結果就是,磁盤總是在繁忙地讀取不同的文件到內存中。這會帶來磁盤和 CPU 利用率的提升。而且每個線程只需要記錄一個文件,因此這種方式也很容易編程實現。
將一個單線程應用程序變成多線程應用程序的另一個常見的目的是實現一個響應更快的應用程序。設想一個服務器應用,它在某一個端口監聽進來的請求。當一個請求到來時,它去處理這個請求,然後再返回去監聽。
服務器的流程如下所述:
while(server is active){
listen for request
process request
}
如果一個請求需要占用大量的時間來處理,在這段時間內新的客戶端就無法發送請求給服務端。只有服務器在監聽的時候,請求才能被接收。另一種設計是,監聽線程把請求傳遞給工作者線程(worker thread),然後立刻返回去監聽。而工作者線程則能夠處理這個請求並發送一個回復給客戶端。這種設計如下所述:
while(server is active){
listen for request
hand request to worker thread
}
這種方式,服務端線程迅速地返回去監聽。因此,更多的客戶端能夠發送請求給服務端。這個服務也變得響應更快。
桌面應用也是同樣如此。如果你點擊一個按鈕開始運行一個耗時的任務,這個線程既要執行任務又要更新窗口和按鈕,那麼在任務執行的過程中,這個應用程序看起來好像沒有反應一樣。相反,任務可以傳遞給工作者線程(word thread)。當工作者線程在繁忙地處理任務的時候,窗口線程可以自由地響應其他用戶的請求。當工作者線程完成任務的時候,它發送信號給窗口線程。窗口線程便可以更新應用程序窗口,並顯示任務的結果。對用戶而言,這種具有工作者線程設計的程序顯得響應速度更快。
從一個單線程的應用到一個多線程的應用並不僅僅帶來好處,它也會有一些代價。不要僅僅為了使用多線程而使用多線程。而應該明確在使用多線程時能多來的好處比所付出的代價大的時候,才使用多線程。如果存在疑問,應該嘗試測量一下應用程序的性能和響應能力,而不只是猜測。
設計更復雜、上下文切換的開銷、增加資源消耗。
## 設計更復雜
雖然有一些多線程應用程序比單線程的應用程序要簡單,但其他的一般都更復雜。在多線程訪問共享數據的時候,這部分代碼需要特別的注意。線程之間的交互往往非常復雜。不正確的線程同步產生的錯誤非常難以被發現,並且重現以修復。
## 上下文切換的開銷
當 CPU 從執行一個線程切換到執行另外一個線程的時候,它需要先存儲當前線程的本地的數據,程序指針等,然後載入另一個線程的本地數據,程序指針等,最後才開始執行。這種切換稱為“上下文切換”(“context switch”)。CPU 會在一個上下文中執行一個線程,然後切換到另外一個上下文中執行另外一個線程。
上下文切換並不廉價。如果沒有必要,應該減少上下文切換的發生。
你可以通過維基百科閱讀更多的關於上下文切換相關的內容:
https://zh.wikipedia.org/wiki/%E4%B8%8A%E4%B8%8B%E6%96%87%E4%BA%A4%E6%8F%9B
## 增加資源消耗
線程在運行的時候需要從計算機裡面得到一些資源。除了CPU,線程還需要一些內存來維持它本地的堆棧。它也需要占用操作系統中一些資源來管理線程。我們可以嘗試編寫一個程序,讓它創建 100 個線程,這些線程什麼事情都不做,只是在等待,然後看看這個程序在運行的時候占用了多少內存。
Java 線程類也是一個 object 類,它的實例都繼承自 java.lang.Thread 或其子類。 可以用如下方式用 java 中創建一個線程:
Tread thread = new Thread();
執行該線程可以調用該線程的 start()方法:
thread.start();
在上面的例子中,我們並沒有為線程編寫運行代碼,因此調用該方法後線程就終止了。
編寫線程運行時執行的代碼有兩種方式:一種是創建 Thread 子類的一個實例並重寫 run 方法,第二種是創建類的時候實現 Runnable 接口。接下來我們會具體講解這兩種方法:
創建 Thread 子類的一個實例並重寫 run 方法,run 方法會在調用 start()方法之後被執行。例子如下:
public class MyThread extends Thread {
public void run(){
System.out.println("MyThread running");
}
}
可以用如下方式創建並運行上述 Thread 子類:
MyThread myThread = new MyThread(); myTread.start();
一旦線程啟動後 start 方法就會立即返回,而不會等待到 run 方法執行完畢才返回。就好像 run 方法是在另外一個 cpu 上執行一樣。當 run 方法執行後,將會打印出字符串 MyThread running。
你也可以如下創建一個 Thread 的匿名子類:
Thread thread = new Thread(){
public void run(){
System.out.println("Thread Running");
}
};
thread.start();
當新的線程的 run 方法執行以後,計算機將會打印出字符串”Thread Running”。
第二種編寫線程執行代碼的方式是新建一個實現了 java.lang.Runnable 接口的類的實例,實例中的方法可以被線程調用。下面給出例子:
public class MyRunnable implements Runnable {
public void run(){
System.out.println("MyRunnable running");
}
}
為了使線程能夠執行 run()方法,需要在 Thread 類的構造函數中傳入 MyRunnable 的實例對象。示例如下:
Thread thread = new Thread(new MyRunnable()); thread.start();
當線程運行時,它將會調用實現了 Runnable 接口的 run 方法。上例中將會打印出”MyRunnable running”。
同樣,也可以創建一個實現了 Runnable 接口的匿名類,如下所示:
Runnable myRunnable = new Runnable(){
public void run(){
System.out.println("Runnable running");
}
}
Thread thread = new Thread(myRunnable);
thread.start();
對於這兩種方式哪種好並沒有一個確定的答案,它們都能滿足要求。就我個人意見,我更傾向於實現 Runnable 接口這種方法。因為線程池可以有效的管理實現了 Runnable 接口的線程,如果線程池滿了,新的線程就會排隊等候執行,直到線程池空閒出來為止。而如果線程是通過實現 Thread 子類實現的,這將會復雜一些。
有時我們要同時融合實現 Runnable 接口和 Thread 子類兩種方式。例如,實現了 Thread 子類的實例可以執行多個實現了 Runnable 接口的線程。一個典型的應用就是線程池。
創建並運行一個線程所犯的常見錯誤是調用線程的 run()方法而非 start()方法,如下所示:
Thread newThread = new Thread(MyRunnable()); newThread.run(); //should be start();
起初你並不會感覺到有什麼不妥,因為 run()方法的確如你所願的被調用了。但是,事實上,run()方法並非是由剛創建的新線程所執行的,而是被創建新線程的當前線程所執行了。也就是被執行上面兩行代碼的線程所執行的。想要讓創建的新線程執行 run()方法,必須調用新線程的 start 方法。
當創建一個線程的時候,可以給線程起一個名字。它有助於我們區分不同的線程。例如:如果有多個線程寫入 System.out,我們就能夠通過線程名容易的找出是哪個線程正在輸出。例子如下:
MyRunnable runnable = new MyRunnable(); Thread thread = new Thread(runnable, "New Thread"); thread.start(); System.out.println(thread.getName());
需要注意的是,因為 MyRunnable 並非 Thread 的子類,所以 MyRunnable 類並沒有 getName()方法。可以通過以下方式得到當前線程的引用:
Thread.currentThread();
因此,通過如下代碼可以得到當前線程的名字:
String threadName = Thread.currentThread().getName();
這裡是一個小小的例子。首先輸出執行main()方法線程名字。這個線程 JVM 分配的。然後開啟 10 個線程,命名為 1~10。每個線程輸出自己的名字後就退出。
public class ThreadExample {
public static void main(String[] args){
System.out.println(Thread.currentThread().getName());
for(int i=0; i<10; i++){
new Thread("" + i){
public void run(){
System.out.println("Thread: " + getName() + "running");
}
}.start();
}
}
}
需要注意的是,盡管啟動線程的順序是有序的,但是執行的順序並非是有序的。也就是說,1 號線程並不一定是第一個將自己名字輸出到控制台的線程。這是因為線程是並行執行而非順序的。Jvm 和操作系統一起決定了線程的執行順序,他和線程的啟動順序並非一定是一致的。
在同一程序中運行多個線程本身不會導致問題,問題在於多個線程訪問了相同的資源。如,同一內存區(變量,數組,或對象)、系統(數據庫,web services 等)或文件。實際上,這些問題只有在一或多個線程向這些資源做了寫操作時才有可能發生,只要資源沒有發生變化,多個線程讀取相同的資源就是安全的。
多線程同時執行下面的代碼可能會出錯:
public class Counter {
protected long count = 0;
public void add(long value){
this.count = this.count + value;
}
}
想象下線程 A 和 B 同時執行同一個 Counter 對象的 add()方法,我們無法知道操作系統何時會在兩個線程之間切換。JVM 並不是將這段代碼視為單條指令來執行的,而是按照下面的順序:
從內存獲取 this.count 的值放到寄存器
將寄存器中的值增加 value
將寄存器中的值寫回內存
觀察線程 A 和 B 交錯執行會發生什麼:
this.count = 0;
A: 讀取 this.count 到一個寄存器 (0)
B: 讀取 this.count 到一個寄存器 (0)
B: 將寄存器的值加 2
B: 回寫寄存器值(2)到內存. this.count 現在等於 2
A: 將寄存器的值加 3
A: 回寫寄存器值(3)到內存. this.count 現在等於 3
兩個線程分別加了 2 和 3 到 count 變量上,兩個線程執行結束後 count 變量的值應該等於 5。然而由於兩個線程是交叉執行的,兩個線程從內存中讀出的初始值都是 0。然後各自加了 2 和 3,並分別寫回內存。最終的值並不是期望的 5,而是最後寫回內存的那個線程的值,上面例子中最後寫回內存的是線程 A,但實際中也可能是線程 B。如果沒有采用合適的同步機制,線程間的交叉執行情況就無法預料。
當兩個線程競爭同一資源時,如果對資源的訪問順序敏感,就稱存在競態條件。導致競態條件發生的代碼區稱作臨界區。上例中 add()方法就是一個臨界區,它會產生競態條件。在臨界區中使用適當的同步就可以避免競態條件。
允許被多個線程同時執行的代碼稱作線程安全的代碼。線程安全的代碼不包含競態條件。當多個線程同時更新共享資源時會引發競態條件。因此,了解 Java 線程執行時共享了什麼資源很重要。
## 局部變量
局部變量存儲在線程自己的棧中。也就是說,局部變量永遠也不會被多個線程共享。所以,基礎類型的局部變量是線程安全的。下面是基礎類型的局部變量的一個例子:
public void someMethod(){
long threadSafeInt = 0;
threadSafeInt++;
}
## 局部的對象引用
對象的局部引用和基礎類型的局部變量不太一樣。盡管引用本身沒有被共享,但引用所指的對象並沒有存儲在線程的棧內。所有的對象都存在共享堆中。如果在某個方法中創建的對象不會逃逸出(譯者注:即該對象不會被其它方法獲得,也不會被非局部變量引用到)該方法,那麼它就是線程安全的。實際上,哪怕將這個對象作為參數傳給其它方法,只要別的線程獲取不到這個對象,那它仍是線程安全的。下面是一個線程安全的局部引用樣例:
public void someMethod(){
LocalObject localObject = new LocalObject();
localObject.callMethod();
method2(localObject);
}
public void method2(LocalObject localObject){
localObject.setValue("value");
}
樣例中 LocalObject 對象沒有被方法返回,也沒有被傳遞給 someMethod()方法外的對象。每個執行 someMethod()的線程都會創建自己的 LocalObject 對象,並賦值給 localObject 引用。因此,這裡的 LocalObject 是線程安全的。事實上,整個 someMethod()都是線程安全的。即使將 LocalObject 作為參數傳給同一個類的其它方法或其它類的方法時,它仍然是線程安全的。當然,如果 LocalObject 通過某些方法被傳給了別的線程,那它就不再是線程安全的了。
## 對象成員
對象成員存儲在堆上。如果兩個線程同時更新同一個對象的同一個成員,那這個代碼就不是線程安全的。下面是一個樣例:
public class NotThreadSafe{
StringBuilder builder = new StringBuilder();
public add(String text){
this.builder.append(text);
}
}
如果兩個線程同時調用同一個 NotThreadSafe 實例上的 add()方法,就會有競態條件問題。例如:
NotThreadSafe sharedInstance = new NotThreadSafe();
new Thread(new MyRunnable(sharedInstance)).start();
new Thread(new MyRunnable(sharedInstance)).start();
public class MyRunnable implements Runnable{
NotThreadSafe instance = null;
public MyRunnable(NotThreadSafe instance){
this.instance = instance;
}
public void run(){
this.instance.add("some text");
}
}
注意兩個 MyRunnable 共享了同一個 NotThreadSafe 對象。因此,當它們調用 add()方法時會造成競態條件。
當然,如果這兩個線程在不同的 NotThreadSafe 實例上調用 call()方法,就不會導致競態條件。下面是稍微修改後的例子:
new Thread(new MyRunnable(new NotThreadSafe())).start(); new Thread(new MyRunnable(new NotThreadSafe())).start();
現在兩個線程都有自己單獨的 NotThreadSafe 對象,調用 add()方法時就會互不干擾,再也不會有競態條件問題了。所以非線程安全的對象仍可以通過某種方式來消除競態條件。
## 線程控制逃逸規則
線程控制逃逸規則可以幫助你判斷代碼中對某些資源的訪問是否是線程安全的。
如果一個資源的創建,使用,銷毀都在同一個線程內完成,
且永遠不會脫離該線程的控制,則該資源的使用就是線程安全的。
資源可以是對象,數組,文件,數據庫連接,套接字等等。Java 中你無需主動銷毀對象,所以“銷毀”指不再有引用指向對象。
即使對象本身線程安全,但如果該對象中包含其他資源(文件,數據庫連接),整個應用也許就不再是線程安全的了。比如 2 個線程都創建了各自的數據庫連接,每個連接自身是線程安全的,但它們所連接到的同一個數據庫也許不是線程安全的。比如,2 個線程執行如下代碼:
檢查記錄 X 是否存在,如果不存在,插入 X
如果兩個線程同時執行,而且碰巧檢查的是同一個記錄,那麼兩個線程最終可能都插入了記錄:
線程 1 檢查記錄 X 是否存在。檢查結果:不存在
線程 2 檢查記錄 X 是否存在。檢查結果:不存在
線程 1 插入記錄 X
線程 2 插入記錄 X
同樣的問題也會發生在文件或其他共享資源上。因此,區分某個線程控制的對象是資源本身,還是僅僅到某個資源的引用很重要。
當多個線程同時訪問同一個資源,並且其中的一個或者多個線程對這個資源進行了寫操作,才會產生競態條件。多個線程同時讀同一個資源不會產生競態條件。
我們可以通過創建不可變的共享對象來保證對象在線程間共享時不會被修改,從而實現線程安全。如下示例:
public class ImmutableValue{
private int value = 0;
public ImmutableValue(int value){
this.value = value;
}
public int getValue(){
return this.value;
}
}
請注意 ImmutableValue 類的成員變量 value 是通過構造函數賦值的,並且在類中沒有 set 方法。這意味著一旦 ImmutableValue 實例被創建,value 變量就不能再被修改,這就是不可變性。但你可以通過 getValue()方法讀取這個變量的值。
(譯者注:注意,“不變”(Immutable)和“只讀”(Read Only)是不同的。當一個變量是“只讀”時,變量的值不能直接改變,但是可以在其它變量發生改變的時候發生改變。比如,一個人的出生年月日是“不變”屬性,而一個人的年齡便是“只讀”屬性,但是不是“不變”屬性。隨著時間的變化,一個人的年齡會隨之發生變化,而一個人的出生年月日則不會變化。這就是“不變”和“只讀”的區別。(摘自《Java 與模式》第 34 章))
如果你需要對 ImmutableValue 類的實例進行操作,可以通過得到 value 變量後創建一個新的實例來實現,下面是一個對 value 變量進行加法操作的示例:
public class ImmutableValue{
private int value = 0;
public ImmutableValue(int value){
this.value = value;
}
public int getValue(){
return this.value;
}
public ImmutableValue add(int valueToAdd){
return new ImmutableValue(this.value + valueToAdd);
}
}
請注意 add()方法以加法操作的結果作為一個新的 ImmutableValue 類實例返回,而不是直接對它自己的 value 變量進行操作。
## 引用不是線程安全的!
重要的是要記住,即使一個對象是線程安全的不可變對象,指向這個對象的引用也可能不是線程安全的。看這個例子:
public void Calculator{
private ImmutableValue currentValue = null;
public ImmutableValue getValue(){
return currentValue;
}
public void setValue(ImmutableValue newValue){
this.currentValue = newValue;
}
public void add(int newValue){
this.currentValue = this.currentValue.add(newValue);
}
}
Calculator 類持有一個指向 ImmutableValue 實例的引用。注意,通過 setValue()方法和 add()方法可能會改變這個引用。因此,即使 Calculator 類內部使用了一個不可變對象,但 Calculator 類本身還是可變的,因此 Calculator 類不是線程安全的。換句話說:ImmutableValue 類是線程安全的,但使用它的類不是。當嘗試通過不可變性去獲得線程安全時,這點是需要牢記的。
要使 Calculator 類實現線程安全,將 getValue()、setValue()和 add()方法都聲明為同步方法即可。
Java 內存模型把 Java 虛擬機內部劃分為線程棧和堆。
堆和棧的知識補漏:
Java把內存分成兩種,一種叫做棧內存,一種叫做堆內存
在函數中定義的一些基本類型的變量和對象的引用變量都是在函數的棧內存中分配。當在一段代碼塊中定義一個變量時,java就在棧中為這個變量分配內存空間,當超過變量的作用域後,java會自動釋放掉為該變量分配的內存空間,該內存空間可以立刻被另作他用。
堆內存用於存放由new創建的對象和數組。在堆中分配的內存,由java虛擬機自動垃圾回收器來管理。在堆中產生了一個數組或者對象後,還可以在棧中定義一個特殊的變量,這個變量的取值等於數組或者對象在堆內存中的首地址,在棧中的這個特殊的變量就變成了數組或者對象的引用變量,以後就可以在程序中使用棧內存中的引用變量來訪問堆中的數組或者對象,引用變量相當於為數組或者對象起的一個別名,或者代號。
引用變量是普通變量,定義時在棧中分配內存,引用變量在程序運行到作用域外釋放。而數組&對象本身在堆中分配,即使程序運行到使用new產生數組和對象的語句所在地代碼塊之外,數組和對象本身占用的堆內存也不會被釋放,數組和對象在沒有引用變量指向它的時候,才變成垃圾,不能再被使用,但是仍然占著內存,在隨後的一個不確定的時間被垃圾回收器釋放掉。這個也是java比較占內存的主要原因,實際上,棧中的變量指向堆內存中的變量,這就是 Java 中的指針!
具體文章參見:Java中的堆和棧的區別
這張圖演示了 Java 內存模型的邏輯視圖。
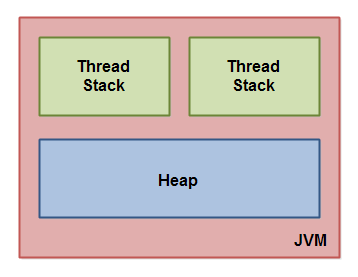
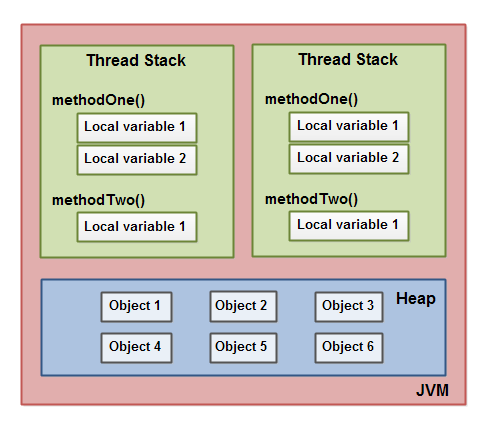
每一個運行在 Java 虛擬機裡的線程都擁有自己的線程棧。這個線程棧包含了這個線程調用的方法當前執行點相關的信息。一個線程僅能訪問自己的線程棧。一個線程創建的本地變量對其它線程不可見,僅自己可見。即使兩個線程執行同樣的代碼,這兩個線程任然在在自己的線程棧中的代碼來創建本地變量。因此,每個線程擁有每個本地變量的獨有版本。
所有原始類型的本地變量都存放在線程棧上,因此對其它線程不可見。一個線程可能向另一個線程傳遞一個原始類型變量的拷貝,但是它不能共享這個原始類型變量自身。
堆上包含在 Java 程序中創建的所有對象,無論是哪一個對象創建的。這包括原始類型的對象版本。如果一個對象被創建然後賦值給一個局部變量,或者用來作為另一個對象的成員變量,這個對象任然是存放在堆上。
下面這張圖演示了調用棧和本地變量存放在線程棧上,對象存放在堆上。
具體分析可詳見文章:http://wiki.jikexueyuan.com/project/java-concurrent/java-memory-model.html
Java 同步塊(synchronized block)用來標記方法或者代碼塊是同步的。Java 同步塊用來避免競爭。本文介紹以下內容:
Java 中的同步塊用 synchronized 標記。同步塊在 Java 中是同步在某個對象上。所有同步在一個對象上的同步塊在同時只能被一個線程進入並執行操作。所有其他等待進入該同步塊的線程將被阻塞,直到執行該同步塊中的線程退出。
有四種不同的同步塊:
上述同步塊都同步在不同對象上。實際需要那種同步塊視具體情況而定。
### 實例方法同步
下面是一個同步的實例方法:
public synchronized void add(int value){
this.count += value;
}
注意在方法聲明中同步(synchronized )關鍵字。這告訴 Java 該方法是同步的。
Java 實例方法同步是同步在擁有該方法的對象上。這樣,每個實例其方法同步都同步在不同的對象上,即該方法所屬的實例。只有一個線程能夠在實例方法同步塊中運行。如果有多個實例存在,那麼一個線程一次可以在一個實例同步塊中執行操作。一個實例一個線程。
### 靜態方法同步
靜態方法同步和實例方法同步方法一樣,也使用 synchronized 關鍵字。Java 靜態方法同步如下示例:
public static synchronized void add(int value){
count += value;
}
同樣,這裡 synchronized 關鍵字告訴 Java 這個方法是同步的。
靜態方法的同步是指同步在該方法所在的類對象上。因為在 Java 虛擬機中一個類只能對應一個類對象,所以同時只允許一個線程執行同一個類中的靜態同步方法。
對於不同類中的靜態同步方法,一個線程可以執行每個類中的靜態同步方法而無需等待。不管類中的那個靜態同步方法被調用,一個類只能由一個線程同時執行。
### 實例方法中的同步塊
有時你不需要同步整個方法,而是同步方法中的一部分。Java 可以對方法的一部分進行同步。
在非同步的 Java 方法中的同步塊的例子如下所示:
public void add(int value){
synchronized(this){
this.count += value;
}
}
示例使用 Java 同步塊構造器來標記一塊代碼是同步的。該代碼在執行時和同步方法一樣。
注意 Java 同步塊構造器用括號將對象括起來。在上例中,使用了“this”,即為調用 add 方法的實例本身。在同步構造器中用括號括起來的對象叫做監視器對象。上述代碼使用監視器對象同步,同步實例方法使用調用方法本身的實例作為監視器對象。
一次只有一個線程能夠在同步於同一個監視器對象的 Java 方法內執行。
下面兩個例子都同步他們所調用的實例對象上,因此他們在同步的執行效果上是等效的。
public class MyClass {
public synchronized void log1(String msg1, String msg2){
log.writeln(msg1);
log.writeln(msg2);
}
public void log2(String msg1, String msg2){
synchronized(this){
log.writeln(msg1);
log.writeln(msg2);
}
}
}
在上例中,每次只有一個線程能夠在兩個同步塊中任意一個方法內執行。
如果第二個同步塊不是同步在 this 實例對象上,那麼兩個方法可以被線程同時執行。
### 靜態方法中的同步塊
和上面類似,下面是兩個靜態方法同步的例子。這些方法同步在該方法所屬的類對象上。
public class MyClass {
public static synchronized void log1(String msg1, String msg2){
log.writeln(msg1);
log.writeln(msg2);
}
public static void log2(String msg1, String msg2){
synchronized(MyClass.class){
log.writeln(msg1);
log.writeln(msg2);
}
}
}
這兩個方法不允許同時被線程訪問。
如果第二個同步塊不是同步在 MyClass.class 這個對象上。那麼這兩個方法可以同時被線程訪問。
在下面例子中,啟動了兩個線程,都調用 Counter 類同一個實例的 add 方法。因為同步在該方法所屬的實例上,所以同時只能有一個線程訪問該方法。
public class Counter{
long count = 0;
public synchronized void add(long value){
this.count += value;
}
}
public class CounterThread extends Thread{
protected Counter counter = null;
public CounterThread(Counter counter){
this.counter = counter;
}
public void run() {
for(int i=0; i<10; i++){
counter.add(i);
}
}
}
public class Example {
public static void main(String[] args){
Counter counter = new Counter();
Thread threadA = new CounterThread(counter);
Thread threadB = new CounterThread(counter);
threadA.start();
threadB.start();
}
}
創建了兩個線程。他們的構造器引用同一個 Counter 實例。Counter.add 方法是同步在實例上,是因為 add 方法是實例方法並且被標記上 synchronized 關鍵字。因此每次只允許一個線程調用該方法。另外一個線程必須要等到第一個線程退出 add()方法時,才能繼續執行方法。
如果兩個線程引用了兩個不同的 Counter 實例,那麼他們可以同時調用 add()方法。這些方法調用了不同的對象,因此這些方法也就同步在不同的對象上。這些方法調用將不會被阻塞。如下面這個例子所示:
public class Example {
public static void main(String[] args){
Counter counterA = new Counter();
Counter counterB = new Counter();
Thread threadA = new CounterThread(counterA);
Thread threadB = new CounterThread(counterB);
threadA.start();
threadB.start();
}
}
注意這兩個線程,threadA 和 threadB,不再引用同一個 counter 實例。CounterA 和 counterB 的 add 方法同步在他們所屬的對象上。調用 counterA 的 add 方法將不會阻塞調用 counterB 的 add 方法。
線程通信的目標是使線程間能夠互相發送信號。另一方面,線程通信使線程能夠等待其他線程的信號。
例如,線程 B 可以等待線程 A 的一個信號,這個信號會通知線程 B 數據已經准備好了。本文將講解以下幾個 JAVA 線程間通信的主題:
文章地址:http://wiki.jikexueyuan.com/project/java-concurrent/thread-communication.html
死鎖是兩個或更多線程阻塞著等待其它處於死鎖狀態的線程所持有的鎖。死鎖通常發生在多個線程同時但以不同的順序請求同一組鎖的時候。
例如,如果線程 1 鎖住了 A,然後嘗試對 B 進行加鎖,同時線程 2 已經鎖住了 B,接著嘗試對 A 進行加鎖,這時死鎖就發生了。線程 1 永遠得不到 B,線程 2 也永遠得不到 A,並且它們永遠也不會知道發生了這樣的事情。為了得到彼此的對象(A 和 B),它們將永遠阻塞下去。這種情況就是一個死鎖。
文章地址:http://wiki.jikexueyuan.com/project/java-concurrent/deadlock.html
在有些情況下死鎖是可以避免的。本文將展示三種用於避免死鎖的技術:
當多個線程需要相同的一些鎖,但是按照不同的順序加鎖,死鎖就很容易發生。
如果能確保所有的線程都是按照相同的順序獲得鎖,那麼死鎖就不會發生。看下面這個例子:
Thread 1: lock A lock B Thread 2: wait for A lock C (when A locked) Thread 3: wait for A wait for B wait for C
如果一個線程(比如線程 3)需要一些鎖,那麼它必須按照確定的順序獲取鎖。它只有獲得了從順序上排在前面的鎖之後,才能獲取後面的鎖。
例如,線程 2 和線程 3 只有在獲取了鎖 A 之後才能嘗試獲取鎖 C(譯者注:獲取鎖 A 是獲取鎖 C 的必要條件)。因為線程 1 已經擁有了鎖 A,所以線程 2 和 3 需要一直等到鎖 A 被釋放。然後在它們嘗試對 B 或 C 加鎖之前,必須成功地對 A 加了鎖。
按照順序加鎖是一種有效的死鎖預防機制。但是,這種方式需要你事先知道所有可能會用到的鎖(譯者注:並對這些鎖做適當的排序),但總有些時候是無法預知的。
文章地址:http://wiki.jikexueyuan.com/project/java-concurrent/deadlock-prevention.html