一、簡單回顧ConcurrentHashMap在jdk1.7中的設計
先簡單看下ConcurrentHashMap類在jdk1.7中的設計,其基本結構如圖所示:
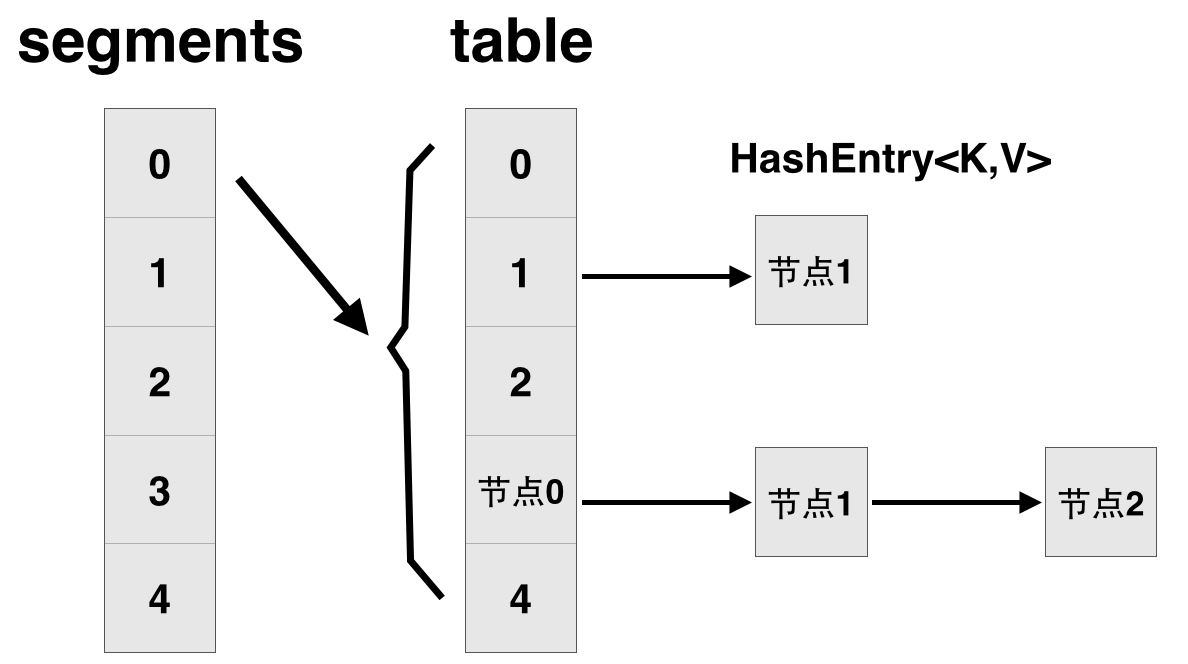
每一個segment都是一個HashEntry<K,V>[] table, table中的每一個元素本質上都是一個HashEntry的單向隊列。比如table[3]為首節點,table[3]->next為節點1,之後為節點2,依次類推。
public class ConcurrentHashMap<K, V> extends AbstractMap<K, V>
implements ConcurrentMap<K, V>, Serializable {
// 將整個hashmap分成幾個小的map,每個segment都是一個鎖;與hashtable相比,這麼設計的目的是對於put, remove等操作,可以減少並發沖突,對
// 不屬於同一個片段的節點可以並發操作,大大提高了性能
final Segment<K,V>[] segments;
// 本質上Segment類就是一個小的hashmap,裡面table數組存儲了各個節點的數據,繼承了ReentrantLock, 可以作為互拆鎖使用
static final class Segment<K,V> extends ReentrantLock implements Serializable {
transient volatile HashEntry<K,V>[] table;
transient int count;
}
// 基本節點,存儲Key, Value值
static final class HashEntry<K,V> {
final int hash;
final K key;
volatile V value;
volatile HashEntry<K,V> next;
}
}
二、在jdk1.8中主要做了2方面的改進
改進一:取消segments字段,直接采用transient volatile HashEntry<K,V>[] table保存數據,采用table數組元素作為鎖,從而實現了對每一行數據進行加鎖,進一步減少並發沖突的概率。
改進二:將原先table數組+單向鏈表的數據結構,變更為table數組+單向鏈表+紅黑樹的結構。對於hash表來說,最核心的能力在於將key hash之後能均勻的分布在數組中。如果hash之後散列的很均勻,那麼table數組中的每個隊列長度主要為0或者1。但實際情況並非總是如此理想,雖然ConcurrentHashMap類默認的加載因子為0.75,但是在數據量過大或者運氣不佳的情況下,還是會存在一些隊列長度過長的情況,如果還是采用單向列表方式,那麼查詢某個節點的時間復雜度為O(n);因此,對於個數超過8(默認值)的列表,jdk1.8中采用了紅黑樹的結構,那麼查詢的時間復雜度可以降低到O(logN),可以改進性能。
為了說明以上2個改動,看一下put操作是如何實現的。
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
// 如果table為空,初始化;否則,根據hash值計算得到數組索引i,如果tab[i]為空,直接新建節點Node即可。注:tab[i]實質為鏈表或者紅黑樹的首節點。
if (tab == null || (n = tab.length) == 0)
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
// 如果tab[i]不為空並且hash值為MOVED,說明該鏈表正在進行transfer操作,返回擴容完成後的table。
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else {
V oldVal = null;
// 針對首個節點進行加鎖操作,而不是segment,進一步減少線程沖突
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
// 如果在鏈表中找到值為key的節點e,直接設置e.val = value即可。
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
// 如果沒有找到值為key的節點,直接新建Node並加入鏈表即可。
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
// 如果首節點為TreeBin類型,說明為紅黑樹結構,執行putTreeVal操作。
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
// 如果節點數>=8,那麼轉換鏈表結構為紅黑樹結構。
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
// 計數增加1,有可能觸發transfer操作(擴容)。
addCount(1L, binCount);
return null;
}
另外,在其他方面也有一些小的改進,比如新增字段 transient volatile CounterCell[] counterCells; 可方便的計算hashmap中所有元素的個數,性能大大優於jdk1.7中的size()方法。
三、ConcurrentHashMap jdk1.7、jdk1.8性能比較
測試程序如下:
public class CompareConcurrentHashMap {
private static ConcurrentHashMap<String, Integer> map = new ConcurrentHashMap<String, Integer>(40000);
public static void putPerformance(int index, int num) {
for (int i = index; i < (num + index) ; i++)
map.put(String.valueOf(i), i);
}
public static void getPerformance2() {
long start = System.currentTimeMillis();
for (int i = 0; i < 400000; i++)
map.get(String.valueOf(i));
long end = System.currentTimeMillis();
System.out.println("get: it costs " + (end - start) + " ms");
}
public static void main(String[] args) throws InterruptedException {
long start = System.currentTimeMillis();
final CountDownLatch cdLatch = new CountDownLatch(4);
for (int i = 0; i < 4; i++) {
final int finalI = i;
new Thread(new Runnable() {
public void run() {
CompareConcurrentHashMap.putPerformance(100000 * finalI, 100000);
cdLatch.countDown();
}
}).start();
}
cdLatch.await();
long end = System.currentTimeMillis();
System.out.println("put: it costs " + (end - start) + " ms");
CompareConcurrentHashMap.getPerformance2();
}
}
程序運行多次後取平均值,結果如下:

四、Collections.synchronizedList和CopyOnWriteArrayList性能分析
CopyOnWriteArrayList在線程對其進行變更操作的時候,會拷貝一個新的數組以存放新的字段,因此寫操作性能很差;而Collections.synchronizedList讀操作采用了synchronized,因此讀性能較差。以下為測試程序:
public class App {
private static List<String> arrayList = Collections.synchronizedList(new ArrayList<String>());
private static List<String> copyOnWriteArrayList = new CopyOnWriteArrayList<String>();
private static CountDownLatch cdl1 = new CountDownLatch(2);
private static CountDownLatch cdl2 = new CountDownLatch(2);
private static CountDownLatch cdl3 = new CountDownLatch(2);
private static CountDownLatch cdl4 = new CountDownLatch(2);
static class Thread1 extends Thread {
@Override
public void run() {
for (int i = 0; i < 10000; i++)
arrayList.add(String.valueOf(i));
cdl1.countDown();
}
}
static class Thread2 extends Thread {
@Override
public void run() {
for (int i = 0; i < 10000; i++)
copyOnWriteArrayList.add(String.valueOf(i));
cdl2.countDown();
}
}
static class Thread3 extends Thread1 {
@Override
public void run() {
int size = arrayList.size();
for (int i = 0; i < size; i++)
arrayList.get(i);
cdl3.countDown();
}
}
static class Thread4 extends Thread1 {
@Override
public void run() {
int size = copyOnWriteArrayList.size();
for (int i = 0; i < size; i++)
copyOnWriteArrayList.get(i);
cdl4.countDown();
}
}
public static void main(String[] args) throws InterruptedException {
long start1 = System.currentTimeMillis();
new Thread1().start();
new Thread1().start();
cdl1.await();
System.out.println("arrayList add: " + (System.currentTimeMillis() - start1));
long start2 = System.currentTimeMillis();
new Thread2().start();
new Thread2().start();
cdl2.await();
System.out.println("copyOnWriteArrayList add: " + (System.currentTimeMillis() - start2));
long start3 = System.currentTimeMillis();
new Thread3().start();
new Thread3().start();
cdl3.await();
System.out.println("arrayList get: " + (System.currentTimeMillis() - start3));
long start4 = System.currentTimeMillis();
new Thread4().start();
new Thread4().start();
cdl4.await();
System.out.println("copyOnWriteArrayList get: " + (System.currentTimeMillis() - start4));
}
}
結果如下: