原創不易,未經允許,不得轉載~~~
總體來說CMS的執行過程可以分為以下幾個階段:
3.1 初始標記(STW)
3.2 並發標記
3.3 並發預清理
3.4 重標記(STW)
3.5 並發清理
3.6 重置
3.1 初始標記階段需要STW。
該階段進行可達性分析,標記GC ROOT能直接關聯到的對象。
注意是直接關聯間接關聯的對象在下一階段標記。
3.2 並發標記階段是和用戶線程並發執行的過程。
該階段進行GC ROOT TRACING,在第一個階段被暫停的線程重新開始運行。
由前階段標記過的對象出發,所有可到達的對象都在本階段中標記。
3.3 並發預處理階段做的工作還是標記,與3.4的重標記功能相似。
既然相似為什麼要有這一步?
前面我們講過,CMS是以獲取最短停頓時間為目的的GC。
重標記需要STW(Stop The World),因此重標記的工作盡可能多的在並發階段完成來減少STW的時間。
此階段標記從新生代晉升的對象、新分配到老年代的對象以及在並發階段被修改了的對象。
此階段比較復雜,從初學者容易忽略或者說不理解的地方拋出一個問題大家思考下:
如何確定老年代的對象是活著的?
答案很簡單,通過GC ROOT TRACING可到達的對象就是活著的。
繼續延伸,如果存在以下場景怎麼辦:
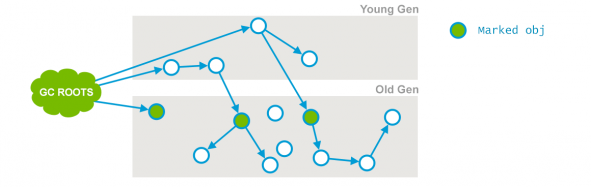
老年代進行GC時如何確保上圖中Current Obj標記為活著的?
(確認新生代的對象是活著的也存在相同問題,大家可以思考下,文章後面會給出答案)
答案是必須掃描新生代來確保。這也是為什麼CMS雖然是老年代的gc,但仍要掃描新生代的原因。(注意初始標記也會掃描新生代)
在CMS日志中我們可以清楚地看到掃描日志:
[GC[YG occupancy: 820 K (6528 K)]
[Rescan (parallel) , 0.0024157 secs]
[weak refs processing, 0.0000143 secs]
[scrub string table, 0.0000258 secs]
[1 CMS-remark: 479379K(515960K)] 480200K(522488K), 0.0025249 secs]
[Times: user=0.01 sys=0.00, real=0.00 secs]
Rescan階段(remark階段的一個子階段)會掃描新生代和老年代中的對象。在日志中可以看到此階段標識為Rescan (parallel),說明此階段是並行進行的。
(看到這裡,如果你心中仍有疑問說明已經入門了)
重點來了:全量的掃描新生代和老年代會不會很慢?肯定會。
CMS號稱是停頓時間最短的GC,如此長的停頓時間肯定是不能接受的。
如何解決呢?
你們先思考著。
必須要有一個能夠快速識別新生代和老年代活著的對象的機制。
先說新生代。
你應該已經知道,新生代垃圾回收完剩下的對象全是活著的,並且活著的對象很少。
如果在掃描新生代前進行一次Minor GC,情況是不是就變得好很多?
CMS 有兩個參數:CMSScheduleRemarkEdenSizeThreshold、CMSScheduleRemarkEdenPenetration,默認值分別是2M、50%。兩個參數組合起來的意思是預清理後,eden空間使用超過2M時啟動可中斷的並發預清理(CMS-concurrent-abortable-preclean),直到eden空間使用率達到50%時中斷,進入remark階段。
如果能在可中止的預清理階段發生一次Minor GC,那就萬事大吉、天下太平了。
這裡有一個小問題,可終止的預清理要執行多長時間來保證發生一次Minor GC?
答案是沒法保證。道理很簡單,因為垃圾回收是JVM自動調度的,什麼時候進行GC我們控制不了。
但此階段總有一個執行時間吧?是的。
CMS提供了一個參數CMSMaxAbortablePrecleanTime ,默認為5S。
只要到了5S,不管發沒發生Minor GC,有沒有到CMSScheduleRemardEdenPenetration都會中止此階段,進入remark。
如果在5S內還是沒有執行Minor GC怎麼辦?
CMS提供CMSScavengeBeforeRemark參數,使remark前強制進行一次Minor GC。
這樣做利弊都有。好的一面是減少了remark階段的停頓時間;壞的一面是Minor GC後緊跟著一個remark pause。如此一來,停頓時間也比較久。
CMS日志如下:
7688.150: [CMS-concurrent-preclean-start]
7688.186: [CMS-concurrent-preclean: 0.034/0.035 secs]
7688.186: [CMS-concurrent-abortable-preclean-start]
7688.465: [GC 7688.465: [ParNew: 1040940K->1464K(1044544K), 0.0165840 secs] 1343593K->304365K(2093120K),
0.0167509 secs]7690.093: [CMS-concurrent-abortable-preclean: 1.012/1.907 secs] 7690.095: [GC[YG occupancy: 522484 K (1044544 K)]
7690.095: [Rescan (parallel) , 0.3665541 secs]7690.462: [weak refs processing, 0.0003850 secs] [1 CMS-remark: 302901K(1048576K)] 825385K(2093120K), 0.3670690 secs]
7688.186啟動了可終止的預清理,在隨後的三秒內啟動了Minor GC,然後進入了Remark階段.
實際上為了減少remark階段的STW時間,預清理階段會盡可能多做一些事情來減少remark停頓時間。
remark的rescan階段是多線程的,為了便於多線程掃描新生代,預清理階段會將新生代分塊。
每個塊中存放著多個對象,這樣remark階段就不需要從頭開始識別每個對象的起始位置。
多個線程的職責就很明確了,把分塊分配給多個線程,很快就掃描完。
遺憾的是,這種辦法仍然是建立在發生了Minor GC的條件下。
如果沒有發生Minor GC,top(下一個可以分配的地址空間)以下的所有空間被認為是一個塊(這個塊包含了新生代大部分內容)。
這種塊對於remark階段並不會起到多少作用,因此並行效率也會降低。
ok,新生代的機制講完了,下面講講老年代。
老年代的機制與一個叫CARD TABLE的東西(這個東西其實就是個數組,數組中每個位置存的是一個byte)密不可分。
CMS將老年代的空間分成大小為512bytes的塊,card table中的每個元素對應著一個塊。
並發標記時,如果某個對象的引用發生了變化,就標記該對象所在的塊為 dirty card。
並發預清理階段就會重新掃描該塊,將該對象引用的對象標識為可達。
舉個例子:
並發標記時對象的狀態:
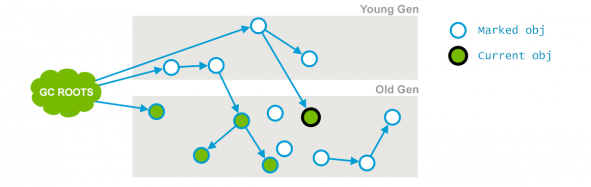
但隨後current obj的引用發生了變化:
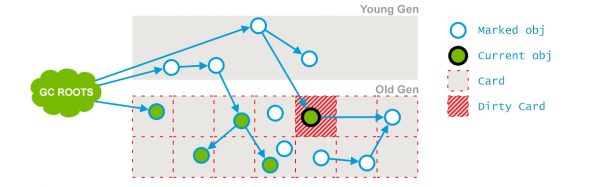
current obj所在的塊被標記為了dirty card。
隨後到了pre-cleaning階段,還記得該階段的任務之一就是標記這些在並發標記階段被修改了的對象麼?之後那些通過current obj變得可達的對象也被標記了,變成下面這樣:
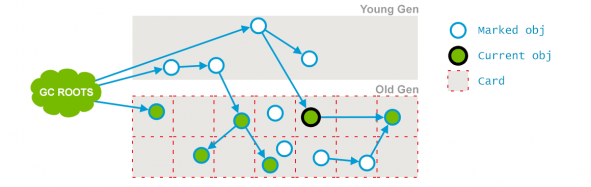
同時dirty card標志也被清除。
老年代的機制就是這樣。
不過card table還有其他作用。
還記得前面提到的那個問題麼?進行Minor GC時,如果有老年代引用新生代,怎麼識別?
(有研究表明,在所有的引用中,老年代引用新生代這種場景不足1%.原因大家可以自己分析下)
當有老年代引用新生代,對應的card table被標識為相應的值(card table中是一個byte,有八位,約定好每一位的含義就可區分哪個是引用新生代,哪個是並發標記階段修改過的)。
所以,Minor GC通過掃描card table就可以很快的識別老年代引用新生代。
這裡點一下,hotspot 虛擬機使用字節碼解釋器、JIT編譯器、 write barrier維護 card table。
當字節碼解釋器或者JIT編譯器更新了引用,就會觸發write barrier操作card table.
再點一下,由於card table的存在,當老年代空間很大時會發生什麼?(這裡大家可以自由發揮想象)
至此,預清理階段的工作講完。
3.4 重標記(STW) 暫停所有用戶線程,重新掃描堆中的對象,進行可達性分析,標記活著的對象。
有了前面的基礎,這個階段的工作量被大大減輕,停頓時間因此也會減少。
注意這個階段是多線程的。
3.5 並發清理。用戶線程被重新激活,同時清理那些無效的對象。
3.6 重置。 CMS清除內部狀態,為下次回收做准備。
CMS執行過程講完了,重點講解了並發預清理時的操作及CMS幾個關鍵參數。你們可以消化一下,消化完了可以休息一下,因為事情還沒結束。
4. CMS有什麼問題?
every coin has two sides ------高中英語作文我經常用的一句話。
在我看來,CMS這三個字母就隱含了問題所在。並發+標記-清除算法 是問題的來源。
先說並發
4.1並發意味著多線程搶占CPU資源,即GC線程與用戶線程搶占CPU。這可能會造成用戶線程執行效率下降。
CMS默認的回收線程數是(CPU個數+3)/4。這個公式的意思是當CPU大於4個時,保證回收線程占用至少25%的CPU資源,這樣用戶線程占用75%的CPU,這是可以接受的。
但是,如果CPU資源很少,比如只有兩個的時候怎麼辦?按照上面的公式,CMS會啟動1個GC線程。相當於GC線程占用了50%的CPU資源,這就可能導致用戶程序的執行速度忽然降低了50%,50%已經是很明顯的降低了。
這種場景怎麼處理呢?
我給的答案是可以不用考慮這種場景。現在的PC機中都至少有雙核處理器,更別說大型的服務器了。
CMS的解決方案是提供了一個 incremental mode(增量模式)。
在這種模式下,進行並發標記、清理時讓GC線程、用戶線程交替運行,盡量減少GC線程獨占CPU資源的時間。
這會造成GC時間更長,但對用戶線程造成的影響就會少一些。
但實踐證明,這種模式下CMS的表現很一般,並沒有什麼大的優化。
i-CMS已經被聲明為“deprecated”,不再提倡使用。
(https://docs.oracle.com/javase/8/docs/technotes/guides/vm/gctuning/cms.html#concurrent_mark_sweep_cms_collector)
4.2 並發清理階段用戶線程還在運行,這段時間就可能產生新的垃圾,新的垃圾在此次GC無法清除,只能等到下次清理。這些垃圾有個專業名詞:浮動垃圾。
由於垃圾回收階段用戶線程仍在執行,必需預留出內存空間給用戶線程使用。因此不能像其他回收器那樣,等到老年代滿了再進行GC。
CMS 提供了CMSInitiatingOccupancyFraction參數來設置老年代空間使用百分比,達到百分比就進行垃圾回收。
這個參數默認是92%,參數選擇需要看具體的應用場景。
設置的太小會導致頻繁的CMS GC,產生大量的停頓;反過來想,設置的太高會發生什麼?
假設現在設置為99%,還剩1%的空間可以使用。
在並發清理階段,若用戶線程需要使用的空間大於1%,就會產生Concurrent Mode Failure錯誤,意思就是說並發模式失敗。
這時,虛擬機就會啟動備案:使用Serial Old收集器重新對老年代進行垃圾回收.如此一來,停頓時間變得更長。
所以CMSInitiatingOccupancyFraction的設置要具體問題具體分析。
網上有一些設置此參數的公式,個人認為不是很嚴謹(原因就是CMS另外一個問題導致的),因此不寫出來以免大家疑惑。
其實CMS有動態檢查機制。
CMS會根據歷史記錄,預測老年代還需要多久填滿及進行一次回收所需要的時間。
在老年代空間用完之前,CMS可以根據自己的預測自動執行垃圾回收。
這個特性可以使用參數UseCMSInitiatingOccupancyOnly來關閉。
這裡提個問題給讀者思考,如果讓你設計,如何預測什麼時候開始自動執行?
4.3 前兩個問題是由並發引起的,接下來要說的問題就是由標記-清除算法引起的。
使用標記-清除算法可能造成大量的空間碎片。空間碎片過多,就會給大對象分配帶來麻煩。
往往老年代還有很大剩余空間,但無法找到足夠大的連續空間來分配當前對象,不得不觸發一次Full GC。
CMS的解決方案是使用UseCMSCompactAtFullCollection參數(默認開啟),在頂不住要進行Full GC時開啟內存碎片整理。
這個過程需要STW,碎片問題解決了,但停頓時間又變長了。
虛擬機還提供了另外一個參數CMSFullGCsBeforeCompaction,用於設置執行多少次不壓縮的Full GC後,跟著來一次帶壓縮的(默認為0,每次進入Full GC時都進行碎片整理)。
延伸一個“foreground collector”的東西給大家,這個玩意在Java8中也聲明為deprecated。(https://bugs.openjdk.java.net/browse/JDK-8027132)
CMS存在的問題已經講清楚,大家消化下。
至此,CMS相關內容已經講完。
總結一下:
CMS采用了多種方式盡可能降低GC的暫停時間,減少用戶程序停頓。
停頓時間降低的同時犧牲了CPU吞吐量 。
這是在停頓時間和性能間做出的取捨,可以簡單理解為"空間(性能)"換時間。
文中提到的幾個問題大家可以把自己當成設計者來思考。
再次聲明,未經允許,不得轉載!
歡迎關注微信訂閱號:

參考資料:
https://docs.oracle.com/javase/8/docs/technotes/guides/vm/gctuning/cms.html#concurrent_mark_sweep_cms_collector
https://blogs.oracle.com/jonthecollector/entry/did_you_know
http://dept.cs.williams.edu/~freund/cs434/hotspot-gc.pdf
https://plumbr.eu/handbook/garbage-collection-algorithms-implementations
https://blogs.msdn.microsoft.com/abhinaba/2009/03/02/back-to-basics-generational-garbage-collection/
https://bugs.openjdk.java.net/browse/JDK-8027132
《深入理解Java虛擬機 JVM高級特性與最佳實踐》