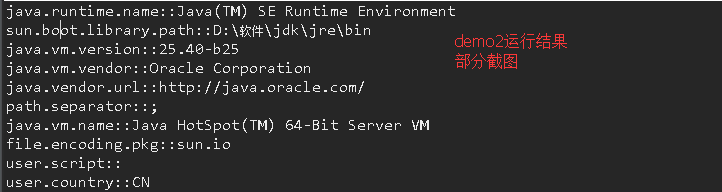
【實戰Java高並發程序設計 1】Java中的指針:Unsafe類
【實戰Java高並發程序設計 2】無鎖的對象引用:AtomicReference
【實戰Java高並發程序設計 3】帶有時間戳的對象引用:AtomicStampedReference
【實戰Java高並發程序設計 4】數組也能無鎖:AtomicIntegerArray
【實戰Java高並發程序設計 5】讓普通變量也享受原子操作
【實戰Java高並發程序設計6】挑戰無鎖算法:無鎖的Vector實現
在對線程池的介紹中,提到了一個非常特殊的等待隊列SynchronousQueue。SynchronousQueue的容量為0,任何一個對SynchronousQueue的寫需要等待一個對SynchronousQueue的讀,反之亦然。因此,SynchronousQueue與其說是一個隊列,不如說是一個數據交換通道。那SynchronousQueue的其妙功能是如何實現的呢?
既然我打算在這一節中介紹它,那麼SynchronousQueue比如和無鎖的操作脫離不了關系。實際上SynchronousQueue內部也正是大量使用了無鎖工具。
對SynchronousQueue來說,它將put()和take()兩個功能截然不同的操作抽象為一個共通的方法Transferer.transfer()。從字面上看,這就是數據傳遞的意思。它的完整簽名如下:
Object transfer(Object e, boolean timed, long nanos)
當參數e為非空時,表示當前操作傳遞給一個消費者,如果為空,則表示當前操作需要請求一個數據。timed參數決定是否存在timeout時間,nanos決定了timeout的時長。如果返回值非空,則表示數據以及接受或者正常提供,如果為空,則表示失敗(超時或者中斷)。
SynchronousQueue內部會維護一個線程等待隊列。等待隊列中會保存等待線程以及相關數據的信息。比如,生產者將數據放入SynchronousQueue時,如果沒有消費者接受,那麼數據本身和線程對象都會打包在隊列中等待(因為SynchronousQueue容積為0,沒有數據可以正常放入)。
Transferer.transfer()函數的實現是SynchronousQueue的核心,它大體上分為三個步驟:
1、如果等待隊列為空,或者隊列中節點的類型和本次操作是一致的,那麼將當前操作壓入隊列等待。比如,等待隊列中是讀線程等待,本次操作也是讀,因此這2個讀都需要等待。進入等待隊列的線程可能會被掛起,它們會等待一個“匹配”操作。
2、如果等待隊列中的元素和本次操作是互補的(比如等待操作是讀,而本次操作是寫),那麼就插入一個“完成”狀態的節點,並且讓他“匹配”到一個等待節點上。接著彈出這2個節點,並且使得對應的2個線程繼續執行。
3、如果線程發現等待隊列的節點就是“完成”節點。那麼幫助這個節點完成任務。其流程和步驟2是一致的。
步驟1的實現如下(代碼參考JDK 7u60):
SNode h = head;
if (h == null || h.mode == mode) { // 如果隊列為空,或者模式相同
if (timed && nanos <= 0) { // 不進行等待
if (h != null && h.isCancelled())
casHead(h, h.next); // 處理取消行為
else
return null;
} else if (casHead(h, s = snode(s, e, h, mode))) {
SNode m = awaitFulfill(s, timed, nanos); //等待,直到有匹配操作出現
if (m == s) { // 等待被取消
clean(s);
return null;
}
if ((h = head) != null && h.next == s)
casHead(h, s.next); // 幫助s的 fulfiller
return (mode == REQUEST) ? m.item : s.item;
}
}
上述代碼中,第1行SNode表示等待隊列中的節點。內部封裝了當前線程、next節點、匹配節點、數據內容等信息。第2行,判斷當前等待隊列為空,或者隊列中元素的模式與本次操作相同(比如,都是讀操作,那麼都必須要等待)。第8行,生成一個新的節點並置於隊列頭部,這個節點就代表當前線程。如果入隊成功,則執行第9行awaitFulfill()函數。該函數會進行自旋等待,並最終掛起當前線程。直到一個與之對應的操作產生,將其喚醒。線程被喚醒後(表示已經讀取到數據或者自己產生的數據已經被別的線程讀取),在14~15行嘗試幫助對應的線程完成兩個頭部節點的出隊操作(這僅僅是友情幫助)。並在最後,返回讀取或者寫入的數據(第16行)。
步驟2的實現如下:
} else if (!isFulfilling(h.mode)) { //是否處於fulfill狀態
if (h.isCancelled()) // 如果以前取消了
casHead(h, h.next); // 彈出並重試
else if (casHead(h, s=snode(s, e, h, FULFILLING|mode))) {
for (;;) { // 一直循環直到匹配(match)或者沒有等待者了
SNode m = s.next; // m 是 s的匹配者(match)
if (m == null) { // 已經沒有等待者了
casHead(s, null); // 彈出fulfill節點
s = null; // 下一次使用新的節點
break; // 重新開始主循環
}
SNode mn = m.next;
if (m.tryMatch(s)) {
casHead(s, mn); // 彈出s 和 m
return (mode == REQUEST) ? m.item : s.item;
} else // match 失敗
s.casNext(m, mn); // 幫助刪除節點
}
}
}
上述代碼中,首先判斷頭部節點是否處於fulfill模式。如果是,則需要進入步驟3。否則,將試自己為對應的fulfill線程。第4行,生成一個SNode元素,設置為fulfill模式並將其壓入隊列頭部。接著,設置m(原始的隊列頭部)為s的匹配節點(第13行),這個tryMatch()操作將會激活一個等待線程,並將m傳遞給那個線程。如果設置成功,則表示數據投遞完成,將s和m兩個節點彈出即可(第14行)。如果tryMatch()失敗,則表示已經有其他線程幫我完成了操作,那麼簡單得刪除m節點即可(第17行),因為這個節點的數據已經被投遞,不需要再次處理,然後,再次跳轉到第5行的循環體,進行下一個等待線程的匹配和數據投遞,直到隊列中沒有等待線程為止。
步驟3:如果線程在執行時,發現頭部元素恰好是fulfill模式,它就會幫助這個fulfill節點盡快被執行:
} else { // 幫助一個 fulfiller
SNode m =h.next; // m 是 h的 match
if (m ==null) // 沒有等待者
casHead(h,null); // 彈出fulfill節點
else {
SNode mn =m.next;
if(m.tryMatch(h)) // 嘗試 match
casHead(h, mn); // 彈出 h 和 m
else // match失敗
h.casNext(m,mn); // 幫助刪除節點
}
}
上述代碼的執行原理和步驟2是完全一致的。唯一的不同是步驟3不會返回,因為步驟3所進行的工作是幫助其他線程盡快投遞它們的數據。而自己並沒有完成對應的操作,因此,線程進入步驟3後,再次進入大循環體(代碼中沒有給出),從步驟1開始重新判斷條件和投遞數據。
從整個數據投遞的過程中可以看到,在SynchronousQueue中,參與工作的所有線程不僅僅是競爭資源的關系。更重要的是,它們彼此之間還會相互幫助。在一個線程內部,可能會幫助其他線程完成它們的工作。這種模式可以更大程度上減少饑餓的可能,提高系統整體的並行度。
摘自《實戰Java高並發程序設計》