下面是解析RESP的所有函數,其中對外函數是RedisProtocol::Decode:
https://github.com/XJM2013/GameEngine/blob/master/lib/src/redis/redisprotocol.cpp
static unsigned int EndLine(const char *buf, unsigned int len);
static int ReadNumber(const char *buf, unsigned int len);
static char _ReadString(const char *buf, unsigned int left_len, int &read_len, RedisData **data);
static int ReadMessage(char type, const char *buf, unsigned int len, RedisBulkData **bulk_data);
static int ReadInteger(const char *buf, unsigned int len, RedisBulkData **bulk_data);
static int ReadString(const char *buf, unsigned int len, RedisBulkData **bulk_data);
static int ReadArray(const char *buf, unsigned int left_len, RedisBulkData **bulk_data);
/*
:1\r\n 前綴 + 結果 + 結束 最少也要有4個字節
*/
int RedisProtocol::Decode(const char *buf, unsigned int len, RedisBulkData **bulk_data)
{
if (len < 4)
{
return OPR_MORE_DATA;
}
switch (buf[0])
{
case '+':
return ReadMessage(REPLY_TYPE_OK, buf + 1, len - 1, bulk_data);
case '-':
return ReadMessage(REPLY_TYPE_ERROR, buf + 1, len - 1, bulk_data);
case ':':
return ReadInteger(buf + 1, len - 1, bulk_data);
case '$':
return ReadString(buf + 1, len - 1, bulk_data);
case '*':
return ReadArray(buf + 1, len - 1, bulk_data);
default:
return OPR_DATA_INVALID;
}
return OPR_DATA_INVALID;
}
從上面的代碼來看,可以看出,代碼的結構相當清晰、簡潔;而且這代碼的功能只是對協議的處理,不包含網絡模塊和其它更復雜的封裝等處理,不需要做額外的辨別閱讀。對於學習協議者,個人覺得還是一個不錯的選擇。代碼中我有做一些內存池的功能,不想使用的,可以用new/delete 或者 malloc/free代替。https://github.com/XJM2013/GameEngine/blob/master/Test/testredis.h
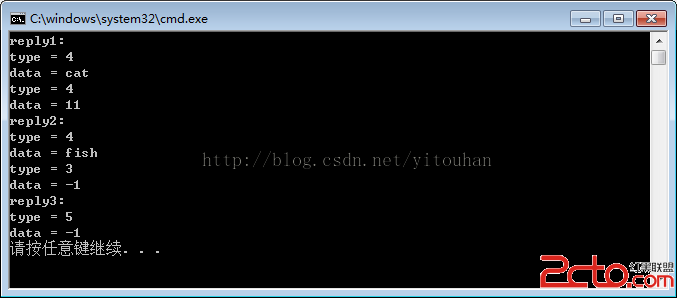
#ifndef TEST_REDIS_H #define TEST_REDIS_H #include下面輸出一下Test5()的結果:#include "lib/include/redis/redisprotocol.h" namespace TestRedis { void ShowBulkData(RedisBulkData *data) { std::list ::iterator itr = data->data_list.begin(); for (; itr != data->data_list.end(); ++itr) { printf("type = %d\n", (*itr)->type); switch ((*itr)->type) { case RedisProtocol::REPLY_TYPE_INTEGER: case RedisProtocol::REPLY_TYPE_STRING_ERROR: case RedisProtocol::REPLY_TYPE_ARRAY_ERROR: printf("data = %d\n", *(int *)(*itr)->data); break; default: printf("data = %.*s\n", (*itr)->len, (*itr)->data); break; } } } void Decode(char *reply) { RedisBulkData *data = NULL; if (RedisProtocol::Decode(reply, strlen(reply), &data) <= RedisProtocol::OPR_MORE_DATA) { return; } ShowBulkData(data); delete data; } // 短字符串 void Test1() { char *reply = "+OK\r\n"; Decode(reply); } // 錯誤 void Test2() { char *reply = "-ERR unknown command 'seet'\r\n"; Decode(reply); } // 整數 void Test3() { char *reply = ":11\r\n"; Decode(reply); } // 長字符串 void Test4() { char *reply1 = "$3\r\ncat\r\n"; printf("reply1:\n"); Decode(reply1); char *reply2 = "$-1\r\n"; printf("reply2:\n"); Decode(reply2); } // 數組 void Test5() { char *reply1 = "*2\r\n$3\r\ncat\r\n$2\r\n11\r\n"; printf("reply1:\n"); Decode(reply1); char *reply2 = "*2\r\n$4\r\nfish\r\n$-1\r\n"; printf("reply2:\n"); Decode(reply2); char *reply3 = "*-1\r\n"; printf("reply3:\n"); Decode(reply3); } } #endif
協議解析總結:
1、從C/C++的角度來看,序列化保存數據,解析更快。
例如將1000條數據序列化成1條數據:
從分配空間的角度來看,1000條數據需要分配1000次空間,1條數據需要分配1次空間。
從解析的角度來看,RESP的結構是LV結構,也就是長度-值(length-value)結構,其不需要標志類型(T,type),因為它的類型都是字符串類型。而序列化實現可以是TV和TLV結構的結合。因此C/C++裡面類型與長度是一一對應的,整型就是4個字節等等;對於字符串則使用TLV結構。這裡大致只需要將RESP的L與序列化的T做一個對比。一個需要匹配"\r\n",並將字符串轉化成數字,一個則只需要讀取第一字節則可以判斷數據長度。
2、set key val\r\n,當val很長,例如10k字節長,server 要匹配10k次才能匹配到\r\n,而且val中不允許出現\r\n否則會出錯。