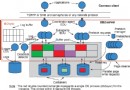
數據庫系統中恢復是指讓數據庫從發生某些“失敗”後的不一致的狀態恢復到正常的一致狀態的行為,恢復的基礎是冗余(物理上冗余,非邏輯上)
這些失敗包括了:
事務失敗:包括邏輯錯誤(事務不滿足某些條件不能執行)和系統錯誤(DBMS強制終止事務,如事務發生死鎖) 系統崩潰:斷電、物理硬件損壞、軟件系統(如OS)崩潰,本章假設系統崩潰不會改變非易失存儲器 磁盤失敗:磁盤存儲發生錯誤,本章假設可利用檢查和監測磁盤失敗大體上,恢復策略分成兩個步驟:
正常事務處理時,記錄足夠的額外信息以供失敗時恢復 失敗發生後,講數據庫返回一致性狀態的動作本小節假設討論恢復問題時的存儲結構和數據訪問模型
按系統奔潰時是否影響數據存儲,將存儲器分成易失存儲器(主存、cache等)和非易失存儲器(磁盤磁帶、閃存、非易失RAM等),然後我們假設一種理想的穩定存儲器(stable storage),發生任何失敗時都不會影響存儲數據內容
定義物理塊為存儲在非易失的磁盤上的塊,緩沖塊是為存儲在易失的主存中的塊,而私有空間是指為每個事務T分配的獨立於其他事務的虛擬存儲區域,那麼可以命名一下4種操作:
input(A):從磁盤中加載物理塊到主存 output(A):把主存中緩沖塊寫回磁盤 read(X):從主存中將緩沖塊讀取到私有空間 write(X):把私有空間中的本地副本寫回到主存假設在事務中,DBMS在第一次訪問塊X時調用一次read操作加載到私有緩沖區,事務執行完畢時write(X)寫回主存,而事務中間的操作時都只是修改其本地副本
注意,DBMS沒有必要在每次write時調用output,這取決於OS的寫回策略
日志是一組記錄在理想的穩定存儲器上的數據庫存儲記錄,約定:
事務Ti開始時,日志記錄<Ti, start> 事務Ti執行write操作時,日志記錄<Ti, X, old_value, new_value> 事務Ti結束時,日志記錄<Ti, commit> 任何時候最多只有一個事務活躍基於日志的恢復有兩種策略,推遲數據庫修改和立即數據庫修改
推遲數據庫修改模式下,數據庫的修改操作僅記錄在Log中而不真正的實施write操作,直到partial committed之後才write
定義在失敗發生時的redo和undo操作:
redo:按照Log中的<Ti, X, old_value, new_value>再一次寫入新值new_value undo:按照Log中的<Ti, X, old_value, new_value>撤銷新值寫入,即寫入old_value由推遲數據庫修改模式的定義知,未記錄<Ti, commit>的事務不執行任何恢復操作,已記錄<Ti, commit>的事務順序地執行redo操作(其實這種模式下old_value是沒有必要記錄的)
立即數據庫修改模式和推遲數據庫修改模式相反,事務未commit之前就允許修改數據庫,write-ahead logging rule(WAL規則)規定log記錄必須在數據庫寫入之前完成
立即數據庫修改下,未記錄<Ti, commit>的事務必須反序地執行undo操作讓數據庫返回到一致性狀態,而已記錄<Ti, commit>的事務順序地執行redo操作
每次redo和undo時都遍歷整個Log並完成所有事務的redo和undo的話,開銷十分巨大,並且對於已經commit後output寫入磁盤的redo是沒有任何意義的,因此在Log引入<checkpoint>語句
DBMS周期性地做檢查工作,把所有commit的事務(已write入主存)從主存中寫回到磁盤中,並在日志中記錄一條<checkpoint>;注意檢查時,可能某個事務還未commit
有了檢查點的數據庫恢復,每次錯誤時只需恢復最近的事務即可:
反向遍歷日志,直到找到第一個<checkpoint> 繼續反向遍歷,找到最近一個未commit的事務起點<Ti, start> 從該句開始執行響應的redo和undo操作那麼對於下面的時序圖,發生失敗時有(立即數據庫修改模式):

除了基於日志的恢復,還另一種恢復策略——影子數據庫(Shadow Database),它有以下設定
假設任何時候只有一個事務活躍 db_pointer指針總是指向數據庫當前的一致性副本 所有的update都是在數據庫的影子拷貝(shadow copy)上完成的,只有當事務partial committed之後才把影子拷貝中的副本寫入磁盤中,並且更新db_pointer 事務失敗時轉向db_pointer指向的一致性的數據庫,當前影子數據庫被直接刪除 假設磁盤不會失敗影子數據庫的拷貝策略運用在大型數據庫上十分低效
13.3中介紹的基於Log的恢復是針對單活躍事務而言的,下面進行更多的假設已完成對並發事務的恢復:
所有的事務共享一份存儲緩沖和一份日志記錄 一個緩沖塊中可以有多個事務修改後的數據 並發控制嚴格遵循兩階段鎖(下一章詳細描述),保證未commit的事務間不可見 並發事務的Log可以交織在一起 檢查點發生時,可能有多個事務正處在活躍狀態,記錄<checkpoint, L>,L是檢查點發生時活躍的事務列表 當失敗發生時執行一下動作:初始化undo_list和redo_list為空表,倒序找到第一個<checkpoint, L>,對於L中每一個事務的update按Log記錄反序加入undo_list、正序加入redo_list 執行undo_list和redo_list中的操作如果把Log緩存在主存中,那麼當緩存已滿或log force操作時才把Log記錄(全部)寫入磁盤(這樣多條log記錄可以一次output,減少I/O開銷),此外Log記錄緩存還必須遵從以下約定:
log記錄必須順序地output進磁盤 事務Ti只有當<Ti, commit>寫入磁盤後才能進入Committed狀態 log記錄必須比相應修改後的數據先寫入磁盤數據庫緩存和Log記錄緩存不一樣的是,它是分塊劃分緩存的,當緩存滿時是選擇緩存塊被新塊替換(若修改需要寫回磁盤),而不整個緩存寫回
上述對恢復的討論僅包含易失存儲器的部分,非易失存儲器的恢復也利用了相似的分層存儲器思想:增加一種dump操作,它下一級是理想的穩定存儲器(可以假想為磁帶等層次更低的存儲介質)