本章目的:
RDBMS的查詢處理步驟
查詢優化的概念
基本方法和技術
查詢優化分類 :
代數優化
物理優化
RDBMS查詢處理階段 :
1. 查詢分析
2. 查詢檢查
3. 查詢優化
4. 查詢執行 對查詢語句進行掃描、詞法分析和語法分析
從查詢語句中識別出語言符號
進行語法檢查和語法分析
根據數據字典對合法的查詢語句進行語義檢查
根據數據字典中的用戶權限和完整性約束定義對用戶的存取權限進行檢查
檢查通過後把SQL查詢語句轉換成等價的關系代數表達式
RDBMS一般都用查詢樹(語法分析樹)來表示擴展的關系代數表達式
把數據庫對象的外部名稱轉換為內部表示
查詢優化:選擇一個高效執行的查詢處理策略
查詢優化分類 :
代數優化:指關系代數表達式的優化
物理優化:指存取路徑和底層操作算法的選擇
查詢優化方法選擇的依據:
基於規則(rule based)
基於代價(cost based)
依據優化器得到的執行策略生成查詢計劃
代碼生成器(code generator)生成執行查詢計劃的代碼
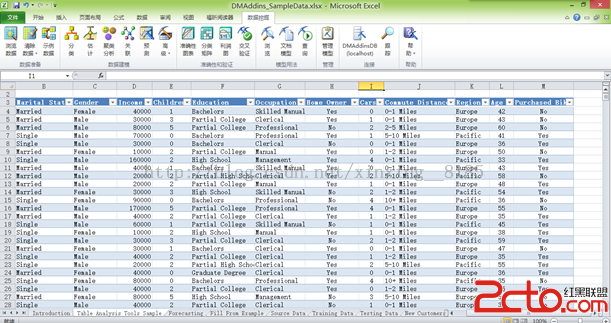
[例1]Select * from student where <條件表達式> ;
考慮<條件表達式>的幾種情況:
C1:無條件;
C2:Sno='200215121';
C3:Sage>20;
C4:Sdept='CS' AND Sage>20;
選擇操作典型實現方法:
1. 簡單的全表掃描方法
對查詢的基本表順序掃描,逐一檢查每個元組是否滿足選擇條件,把滿足條件的元組作為結果輸出
適合小表,不適合大表
2. 索引(或散列)掃描方法
適合選擇條件中的屬性上有索引(例如B+樹索引或Hash索引)
通過索引先找到滿足條件的元組主碼或元組指針,再通過元組指針直接在查詢的基本表中找到元組
[例1-C2] 以C2為例,Sno=‘200215121’,並且Sno上有索引(或Sno是散列碼)
使用索引(或散列)得到Sno為‘200215121’ 元組的指針
通過元組指針在student表中檢索到該學生
[例1-C3] 以C3為例,Sage>20,並且Sage 上有B+樹索引
使用B+樹索引找到Sage=20的索引項,以此為入口點在B+樹的順序集上得到Sage>20的所有元組指針
通過這些元組指針到student表中檢索到所有年齡大於20的學生。
[例1-C4] 以C4為例,Sdept=‘CS’ AND Sage>20,如果Sdept和Sage上都有索引:
算法一:分別用上面兩種方法分別找到Sdept=‘CS’的一組元組指針和Sage>20的另一組元組指針
求這2組指針的交集
到student表中檢索
得到計算機系年齡大於20的學生
算法二:找到Sdept=‘CS’的一組元組指針,
通過這些元組指針到student表中檢索
對得到的元組檢查另一些選擇條件(如Sage>20)是否滿足
把滿足條件的元組作為結果輸出。
連接操作是查詢處理中最耗時的操作之一
本節只討論等值連接(或自然連接)最常用的實現算法
[例2] SELECT * FROM Student,SC
WHERE Student.Sno=SC.Sno;對外層循環(Student)的每一個元組(s),檢索內層循環(SC)中的每一個元組(sc)
檢查這兩個元組在連接屬性(sno)上是否相等
如果滿足連接條件,則串接後作為結果輸出,直到外層循環表中的元組處理完為止
適合連接的諸表已經排好序的情況
排序-合並連接方法的步驟:
如果連接的表沒有排好序,先對Student表和SC表按連接屬性Sno排序
取Student表中第一個Sno,依次掃描SC表中具有相同Sno的元組
步驟:
① 在SC表上建立屬性Sno的索引,如果原來沒有該索引
② 對Student中每一個元組,由Sno值通過SC的索引查找相應的SC元組
③ 把這些SC元組和Student元組連接起來
循環執行②③,直到Student表中的元組處理完為止
把連接屬性作為hash碼,用同一個hash函數把R和S中的元組散列到同一個hash文件中
步驟:
劃分階段(partitioning phase):
對包含較少元組的表(比如R)進行一遍處理
把它的元組按hash函數分散到hash表的桶中
試探階段(probing phase):也稱為連接階段(join phase)
對另一個表(S)進行一遍處理
把S的元組散列到適當的hash桶中
把元組與桶中所有來自R並與之相匹配的元組連接起來
排序-合並連接方法的步驟(續):
當掃描到Sno不相同的第一個SC元組時,返回Student表掃描它的下一個元組,再掃描SC表中具有相同Sno的元組,把它們連接起來
重復上述步驟直到Student 表掃描完
Student表和SC表都只要掃描一遍
如果2個表原來無序,執行時間要加上對兩個表的排序時間
對於2個大表,先排序後使用sort-merge join方法執行連接,總的時間一般仍會大大減少
上面hash join算法前提:假設兩個表中較小的表在第一階段後可以完全放入內存的hash桶中