數據倉庫一體機
什麼是一體機
一體機 (Applicance) 並沒有一個通用的定義 , 一體機應該具備以下的一些特征。它應該是為特定的應用領域專門設計的設備,針對特定的用途集中優化,在特定的領域內提供一套完整的解決方案,需要很低的維 護成本。對於最終用戶來說一體機應該是能夠快速簡易的安裝,通過標准的接口和非常簡單的操作來滿足用戶的需求。一體機是個黑盒子,用戶告訴它想要做什麼, 一體機快速的把結果或答案反饋給用戶。IPod 就是一個很好的一體機例子,它簡單化並且徹底改革了數字娛樂領域。
Netezza- 數據倉庫領域真正的一體機
值得驕傲的是 Netezza 的產品是真正的,是專門為數據倉庫設計的一體機。 在數據倉庫領域許多廠商都推出的自己的“一體機”產品。有些產品只提供軟件,用戶需要自行的集成軟件與硬件。有些產品雖然把軟件與硬件結合在一起,但並不 是專門的為數據倉庫而設計和優化。這些產品都需要非常復雜並漫長的人工調優過程,而且後續的維護成本也很高昂。 說 Netezza 是真正的一體機是因為它解決了以上問題。它是軟件與硬件不可分離的緊密結合體,無縫的整合數據庫管理系統(DBMS)、服務器(Server)和存儲設備 (Storage)。不需要復雜配置和調優就可以取得非常優異性能。“Netezza”是印度某種方言中的一個詞,在英語中的意思是“RESULT”。這 個名字也非常恰如其分的體現了 Netezza 一體機的特點。需要結果麼? 那麼只需要提出問題。
簡單性
Netezza 一體機與傳統數據倉庫的一個很大區別在於它的簡單性。這種簡單性體現在方方面面。
· 安裝與部署的簡單性 : 從外部來看 Netezza 一體機就是一個大盒子,給這個大盒子插上電配置好服務 IP 那它就可以對外提供服務了。而傳統的數據倉庫往往需要花很大的心思在物理規劃設計上。這包括規劃存儲、配置網絡以及安裝所需要的軟件等等。
· 管理和維護的簡單性 : 聽起來似乎有點不可思議,但事實確實如此 -Netezza 幾乎不需要執行任何傳統數據倉庫 DBA 所執行的任務
o 沒有索引(index)
o 不需要性能調優(tuning)
o 不需要存儲管理:沒有 dbspace/tablespace 規劃和配置,沒有 redo/physical long 規劃和配置,沒有表的 page/block/extent 規劃和配置,無需臨時表空間的分配與監控,無需 RAID 級別的選擇,無需邏輯卷的規劃與創建時間
o 無需配置操作系統內核參數以及維護建議的操作系統補丁級別
o 簡單的數據分區策略:哈希或者隨機
簡單性所帶來到好處是巨大的。這種簡單性可以節省出昂貴的 DBA 管理和維護成本,節省出的資源可以投入到更能夠創造出商業價值的任務上而不是乏味的 DBA 任務。是 一個非常簡單的創建數據庫例子。可以看出 Netezza 的語句十分簡單。當然其他的數據倉庫語句也可以簡單的和 Netezza 一樣,但是如果那樣的話創建出的數據庫是沒有經過優化會比清單 1 中創建出的數據庫性能差很多。Netezza 的優勢就在於用簡單的語句(更少的管理與維護)也可以創建出性能很好的數據庫。在一些實際的數據倉庫數遷移項目中,其它數據倉庫數千行的建表語句(包括分 區和索引部分)轉換到 Netezza 只用十幾行就能代替,並且還能取得更好的性能。由於篇幅的關系這裡就不列出建表語句的例子了
清單 1 在某數據倉庫上創建一個 database 的語句
CREATE DATABASE TEST
LOGFILE 'E:\OraData\TEST\LOG1TEST.ORA' SIZE 2M,
'E:\OraData\TEST\LOG2TEST.ORA' SIZE 2M,
'E:\OraData\TEST\LOG3TEST.ORA' SIZE 2M,
'E:\OraData\TEST\LOG4TEST.ORA' SIZE 2M,
'E:\OraData\TEST\LOG5TEST.ORA' SIZE 2M
EXTENT MANAGEMENT LOCAL MAXDATAFILES 100
DATAFILE 'E:\OraData\TEST\SYS1TEST.ORA' SIZE 50 M
DEFAULT TEMPORARY TABLESPACE temp TEMPFILE 'E:\OraData\TEST\TEMP.ORA' SIZE 50 M
UNDO TABLESPACE undo DATAFILE 'E:\OraData\TEST\UNDO.ORA' SIZE 50 M
NOARCHIVELOG
CHARACTER SET WE8ISO8859P1;
清單 2 在 Netezza 上創建一個 database 的語句
CREATE DATABASE TEST
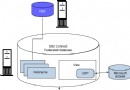
Netezza 一體機架構
之前的介紹中說用戶可以把 Netezza 一體機看作一個黑盒子。那這個黑盒子是如何在保持簡單性的同時又提供高性能的呢?這就需要我們打開黑盒子看一看 Netezza 一體機的獨特架構。
主要包括四大關鍵組件。SMP 主機、S-Blades、磁盤存儲櫃和網絡結構
Netezza 1000
Netezza 1000 是 Netezza 一體機很具代表性的一個型號。在 Netezza 被 IBM 收購之前這個型號的名稱是 Netezza TwinFin
· SMP 主機是兩台高性能的 Linux 服務器,兩台服務器一台是活動的,另外一體是備機。BI 應用程序的請求都會通過活動的 SMP 主機來提交。SMP 主機編譯並且生成最優的可執行代碼,分發生成的可執行代碼給 S-Blades 執行。最後收集並匯總 S-Blades 返回的結果返回給用戶。
· S-Blades 是智能的處理節點也是 Netezza 魔法發生的地方。每個 S-Blades 都是一台獨立的服務器它包含了個一台標准的刀片服務器和一塊 Netezza 特有的數據庫加速卡。刀片服務器和數據庫加速卡通過 IBM 的 sidercar 技術整合起來,使它們在邏輯上和物理上都成為一個整體。Netezza 1000 的每個 S-Blades 節點包括 2 個 4 核的 CPU、4 個 2 核的 FPGA 引擎以及 16GB 的內存。
· 磁盤存儲櫃包含了高密度高性能的磁盤。每塊磁盤包含表的一個數據片(data slice)。所有磁盤上的某個表的數據片合起來組成一個表完整的數據。每塊磁盤上還包含另外一塊磁盤上的數據鏡像。磁盤陣列櫃通過高速的通道 (3Gb/s SAS)和 S-Blades 連接在一起。
· 網絡結構並沒有在中標注出來。主要的網絡鏈接線路都在機櫃的背面。Netezza 1000 一體機的各個組件是通過高速網絡連接起來的。網絡有兩種一種是 IP 網絡另一種是 SAS 存儲網絡。IP 網絡是服務於 SMP 主機與 S-Blades 節點之間以及不同 S-Blades 節點之間的數據通訊。IP 網絡中的協議是經過深度定制的,專門為了 Netezza 的應用環境而優化,能夠支持上千節點之間同時的大數據量傳輸。SAS 網絡連接了 S-Blades 節點與磁盤存儲櫃,使 S-Blades 能夠高速的訪問磁盤上的數據。
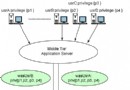
Netezza 一體機架構
Netezza 的 AMPP(Asymmetric Massively Parallel Processing)是一個兩層結構,專門為了處理多用戶的大數據量查詢而設計。AMPP 結構是 SMP 前端和 shared nothing 的 MPP 後端的完美結合。前端是 SMP 的高性能 Linux 主機。其主要功能是通過標准的接口(SQL、ODBC、JDBC、OLE DB)對外提供服務。SMP 主機負責編譯從應用程序發出的查詢請求,生成優化過的可執行代碼片段,稱之為 snippet,然後分發這些代碼片段到所有的 S-Blades 上並行執行。當所有的 S-Blades 都執行完畢 SMP 主機匯總結果後把最終的結果返回給應用程序。後端是由大量的 S-Blades 組成,主要的數據操作過程都是在 S-Blades 上完成的。S-Blades 之間是相互獨立的,每個 S-Blades 都會占有自己磁盤和數據片(data slice)在並行處理的時候並不會相互影響。這種結構的好處是可以通過增加 S-Blades 節點和其所使用的磁盤來使性能得到近似線性的提升。Netezza 1000 的 S-Blades 數量可以擴展到 120 個。在面對超大量數據的時候,這種分而治之的方法能收到立竿見影的效果。 這種結構也提供了極大的靈活性通過改變磁盤、S-Blades 和內存的配比來創建出不同型號的 Netezza 一體機。比如增加磁盤數量減少 S-Blades 數量,這樣的一體機查詢性能有所減弱,但數據容量有所增大。可以用來存放歷史數據。
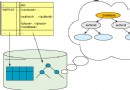
FPGA 與數據流處理
在架構層面上,靈活的 AMPP 架構是 Netezza 一體機具有高性能的一個重要因素,另外一個起到決定性作用的因素就是 Netezza 一體機引入的數據庫加速卡和數據流處理概念。這些都發生在 S-Blades 裡面,它們極大的增強了一體機數據處理能力。下面將更深入的進入到魔法發生的地方 -S-Blades 裡面看看它的獨特之處。 S-Blades 包括一個刀片服務器 (8 個 CPU 核 ) 和一塊數據加速卡(8 個 FPGA 核)。正常情況下在 Netezza 1000 一體機中一個 S-Blades 管理 8 個數據片(data slices)。一個 CPU 核與一個 FPGA 核再加上一個數據片組成了一個邏輯的處理單元,稱之為 Snippet Processor。每個 Snippet Processor 都獨立的負責一個數據片的處理,這樣當運行查詢的時候一個 S-Blades 中就有個 8 個這樣的邏輯處理單元並行的處理 8 個數據片。
CPU和 FPGA 各自都有明確的分工對任務的不同階段進行處理,形成了流水線作業大大提高了性能。展示了一個邏輯處理單元(1 CPU 核 + 1 FPGA 核 + 1 數據片)各個組件的分工以及它們是如何協同工作的。 SMP 主機編譯生成可執行的代碼片段並且把它們分發到 S-Blades 上去執行。這個代碼片段實際上包含兩部分內容一部分是用來配置 FPGA 的參數另一部分是 CPU 可執行的程序。FPGA 配置好了參數之後便開始根據配置的參數來執行,這時將建立一個數據流。下面將結合一條 SQL 語句來解釋一下數據是如何在流中被操作的。
SQL:select c1, c2, sum(c3) from t1 where c2=999 假設表 t1 包含 10 列分別是 c1 到 c10
1 FPGA 從數據片中讀取所查詢表 t1 的所有數據塊到內存中 . 這裡讀取的知識表 t1 的一部分數據,其他的數據存儲在其它的數據片上。
2 磁盤上所有的數據都是經過壓縮的,壓縮的好處是可以有效的減少磁盤的 IO。FPGA 對數據進行解壓
3 FPGA 對數據進行投影操作,只保留操作中能用到的列。這樣做可以減少數據的大小,使數據傳輸和處理起來都更加高效。效果對寬表尤其明顯。SQL 語句中選擇了 c1,c2 和 c3 三列其余的列都沒有用到,這樣只保存這三列其余列全部丟棄掉。
4 FPGA 對數據進行過濾,只保留用戶應該得到的數據。這裡有兩層過濾一層是由於查詢條件限制需要過濾掉的數據,SQL 語句中的 c2=999 會在這個階段產生作用。還有一層過濾是要過濾掉還實物還沒有提交的數據。
5 CPU 對過濾好的數據進行聚合、鏈接和匯總等操作。然後返回出這個邏輯處理單元的結果。SQL 語句中的 sum(c3) 在這個階段被執行。
6 SMP 主機收到所有的邏輯處理單元的結果後再匯總得到最終結果,返回給用戶。
這整個過程就像是一個工廠裡面的裝配線一樣,當數據流過這條裝配線就會得到結果。當工廠裡面有成百上千條流線同時工作的時候,得到結果自然就是很快的事情。
關鍵技術特性
分區數據庫與分區鍵
Netezza 是一個分區的數據庫,一個表的數據是分布所有的數據片上的。一條記錄存儲在那個數據片上是由分區鍵來決定的。有兩種方式來制定分區鍵,一是定義表的時候可以指定一個或多個列來作為表的分區鍵,另一個是用隨機的方式(round-robin)來給記錄分區。清單 3列出了其基本語法 . 如果指定了列作為分區鍵,Netezza 會根據所指定用哈希算法算出一條記錄數據屬於那個分區。如果沒有指定分區鍵則自動用第一個列作為分區鍵
清單 3 指定分區鍵
Create table table_name(
Column_name1 data_type1
Column_name2 data_type2
Column_name3 data_type3)
[distribute on (column_name1, column_name2, … ] |
[distribute on random]
分區鍵的選擇對性能的影響是至關重要的,這也是 Netezza 中為數不多的可以管理和調優的地方。應該盡可能的使數據均勻的分布在所有的數據片上。下面有一些基本的原則
· 選擇有大量唯一值的列做分區鍵,列的唯一值的數量越多數據的分布就越均勻。不要使用 bool 類型的列作為分區鍵,那將會導致所有的數據只會分布在兩個數據片上。
· 對於表關聯的情況,應該選擇關聯條件裡面的所有列作為兩個表的分區鍵,這樣關聯操作只會在數據片自己的分區內發生。每個數據片都不會廣播自己的數據到其它分區。
壓縮
與傳統的數據倉庫不同的,在 Netezza 一體機中所有的用戶數據都是經過壓縮存儲的,而並不像傳統數據倉庫那樣可以選擇不壓縮進行存儲,這也體現了 Netezza 的簡單性。數據倉庫中性能的瓶頸往往出現在磁盤上,數據壓縮存儲的好處是可以減少磁盤的 IO 壓力,FPGA 引擎負責將數據解壓縮成可讀的內容。 Netezza 的壓縮對用戶來說是完全透明的,它支持所有的數據類型,不要任何的調優和管理。壓縮算法把記錄根據列分成不同的數據列流,對每個列流獨立的進行壓縮,但在 存儲的時候保持行結構,這種具有專利的壓縮算法保證了 4 到 32 倍的壓縮率,極大的減少了磁盤 IO 的壓力。
Zone Maps
Zone Maps 是 Netezza 很獨特的技術,它可以使數據塊在還沒有被從磁盤上讀出來之前就知道這塊數據是否包含查詢中所包含的數據,如果不包含則直接跳過該數據塊。這種方式極大的減 少的磁盤的 IO,大大提高了查詢的性能。傳統的數據倉庫則需要讀出數據塊然後再判斷是否需要裡面的數據。 Zone Maps 是什麼呢?在 Netezza 中數據是以數據塊的方式存儲的磁盤上的,對數據的讀寫操作的最小單位是數據塊,每個數據塊的大小是 3MB。Zone Maps 保存了每張表的每個數據塊上表的各個列的最大值和最小值。默認情況下整數、日期和時間類型的列會生成 Zone Maps 統計信息。表 TradeTable 使用了 3 個數據塊來存放數據。Zone Maps 收集了其中兩列 Data 和 Cust_ID 的在每個數據塊上的最大值和最小值。當語句“select * from TradeTable where data=02”執行的時候數據庫系統首先檢查 Zone Maps,根據 Zone Maps 的指示,只有第二個數據塊中的數據有滿足條件的記錄,所以第一個和第三個數據塊的數據不會被讀入。
Zone Maps 也是自動維護的並不需要用戶來進行干預。Zone Maps 會在以下的條件下自動進行更新:
· 運行 GENERATE STATISTICS 命令收集統計信息時
· 用 nzload 進行數據裝載時
· 插入和更新數據時
· 運行 GROOM TABLE 重新整理數據塊時
工作負載管理
現今的數據倉庫大多是多用戶同運行混合任務類型的系統。工作負載管理是這樣的系統上不可取少的一項功能。Netezza 提供了一套簡單又靈活的工作負載管理方案,包括以下一些策略:
· 資源保障分配(GRA):通過定義資源組,給每個資源組分配可使用資源的范圍來控制不同用戶對系統資源的使用比例。
· 分優先級的執行查詢(PQE):可以給每個查詢賦予低中高的優先級,當系統資源緊張的時候高優先級的查詢會優先執行。PQE 和 GRA 可以結合起來使用,即在相同的資源組裡面的查詢也可以通過指定不同的優先級來進行區分。
· 短查詢優先(SQB):保證短查詢不受大數據量查詢的影響,即使在系統資源很緊張的時候短查詢也能很快的返回結果而不必等到大數據量查 詢結束。這個是通過系統預留出一定數量的資源來實現的。Netezza 會根據生成的執行計劃來判斷一個查詢是否是短查詢,默認情況下認為一個查詢如果少於 2 秒就是一個短查詢。
高可用性
Netezza 一體機的各個部件都存在冗余的備份,不存在單點失敗的情況。其高可用性主要體現在以下三個層次。
· SMP 主機:一體機包含兩台 SMP 主機,這兩天主機是主備關系,其上面運行的 Linux HA 軟件可以保證在主機出現宕機的情況下,所有的服務都可以轉移到備機上。兩台主機之間並沒有采用共享磁盤的方式來保持共享的關鍵數據,而是采用了 DRBD 來同步需要共享的關鍵數據。
· S-Blades:每個刀片服務器底座包含了 6 個 S-Blades。當其中有的一台 S-Blades 出現問題的時候,Netezza 會自動的把失敗的的 S-Blades 所管理的磁盤分配給同一個底座上其他的 S-Blades 進行管理。對於只讀的查詢用戶是感覺不到這種切換的存在。
· 磁盤:每塊磁盤上都保存有一個數據片的數據,同時也保存著另外一個數據片數據的鏡像備份。例如磁盤 1 上有數據片 1 上的數據以及數據片 2 上數據的鏡像,磁盤 2 上有數據片 2 的數據以及數據片 1 的鏡像。當磁盤 1 失敗的時候,S-Blades 會自動的去訪問磁盤 2 上的鏡像數據,系統仍能維持正常的運行。此外磁盤存儲櫃裡的還有一些空閒磁盤他們不屬於任何的數據片,當有磁盤失敗空閒的磁盤會重新的生成數據,例如磁盤 1 失敗,那麼空閒磁盤 X 會從磁盤 2 復制數據片 1 的鏡像和數據片 2 的數據重新生成失敗的磁盤 1,這個過程需要一些時間,在這個過程中 S-Blades 還是通過磁盤 2 來訪問數據片 1 的數據。一旦這個過程完成 S-Blades 會通過新生成的磁盤來訪問數據片 1 的數據。整個過程對於用戶來說也都是透明的
結束語
一體機技術是今後數據倉庫發展的趨勢,各大廠商也都加大了在這個方向的投入。通過本文,您應該對 Netezza 一體機技術有所了解,理解了它為什麼外表看起來了如此簡單卻又有著非凡的性能表現。希望您能有機會親自體驗一下它給你帶來的驚喜。
作者 jaminwm