前言
在信息整合的架構中,IBM 聯邦數據庫與若干異構數據源連接並提供整體一致的服務。從數據源到聯邦數據庫再到具體應用程序,數據的流動和轉換依賴於各個環節代碼頁的正確配置。由於數據源環境本身的異構性,聯邦數據庫在包裝器中采用了不同的策略和實現方式,客戶需要根據實際環境進行配置以實現聯邦數據庫和數據源之間的代碼頁轉換。另外,區別於傳統歐美用戶的使用習慣,東亞用戶更多采用 Unicode 或者其他多字節字符集,也增大了代碼頁配置過程中的復雜性。
本文首先總體介紹一下聯邦數據庫在多國語言環境下配置代碼頁轉換幾種情況;其次對於不同數據源的包裝器(如 DRDA、Oralce、ODBC 等),分別介紹如何根據用戶的需要進行配置;最後,對使用聯邦數據庫的代碼轉換常見問題進行了解答。
聯邦數據庫中代碼頁簡介
聯邦數據庫中涉及到的代碼頁包括操作系統級別區域設置選項默認的代碼頁,DB2 客戶端應用程序的代碼頁,DB2 數據庫代碼頁,遠程數據源的客戶端代碼頁和遠程數據庫的代碼頁。
操作系統 Locale:系統級別的代碼頁設置,決定應用程序或數據庫的默認代碼頁。
DB2CODEPAGE:實例級別的代碼頁設置,影響到所有的 DB2 客戶端應用程序的代碼頁。
數據庫的代碼頁:數據庫級別的代碼頁設置,在 DB2 V9.5 及之後的版本,數據庫代碼頁默認是 1208(UTF-8),但在創建數據庫時可以通過“USING CODESET”子句顯性指定代碼頁名稱。數據庫一旦創建成功,此代碼頁將不能改變。例如,您可以使用下面的 SQL 創建一個支持 GBK 中文編碼的數據庫。
CREATE DATABASE <database_name>USING CODESET GBK TERRITORY CN
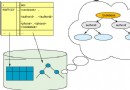
作為分布式異構數據庫集合的核心,聯邦數據庫提供更靈活的代碼頁轉換功能。圖 1 顯示了聯邦數據庫代碼頁轉換的總體框架。
圖 1. 聯邦數據庫代碼頁轉換的總體框架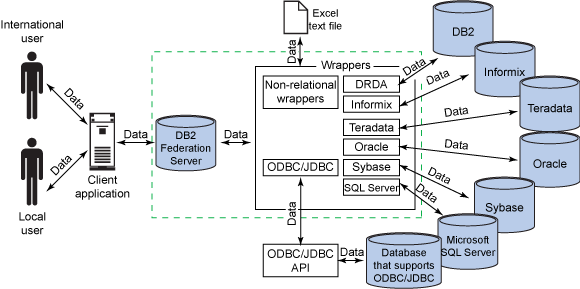
查看原圖(大圖)
從圖 1 中,您可以容易的看到從遠程數據庫到用戶應用程序中的數據流。每雙箭頭表示可能發生的代碼頁轉換過程,這些過程可能是受不同的參數影響。通常情況數據的接收端負責代碼頁的轉換。例如,如果 DB2 客戶端應用程序從聯邦服務器數據獲取數據,那麼 DB2 的客戶端進行轉換代碼頁,反之亦然。
代碼頁轉換依賴於遠端數據源客戶端 / 服務器
對於那些功能強大的數據源,例如 DB2 和 Oracle,由於它們的客戶端本身具有就擁有強大的代碼頁轉換能力,因此我們只需要了解如何將它們的代碼頁轉換配置設置到聯邦數據庫下。通常遵循以下准則:
對於遠端數據源,聯邦數據庫扮演了該數據源的客戶端應用程序的角色。包裝器通過客戶端 API 將聯邦數據庫和遠程數據源連接起來。
根據相應的包裝器,需要將遠端數據源代碼頁轉換的相關環境變量或系統參數設置到 db2dj.ini 文件中。
聯邦數據庫與遠端數據源連接建立時,db2dj.ini 中的代碼頁環境變量將被設置在當前會話中。
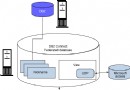
下面我們以 Oracle 包裝器為例,進行詳細的說明:
圖 2. Oracle 包裝器代碼頁轉換框架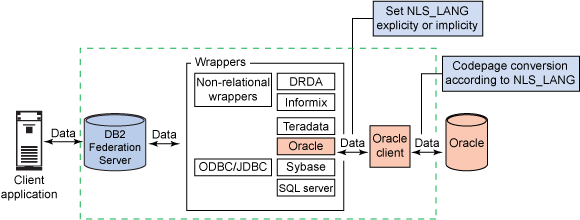
查看原圖(大圖)
Oracle 包裝器的代碼頁轉換依賴於 Oracle 數據源。為了更好的理解聯邦服務器 Oracle 包裝器如何處理代碼頁轉換,我們最好先了解下 Oracle 數據源處理代碼頁轉換的機制。
Oracle 使用 NLS 參數來指定其服務器和客戶端的行為約定。大約有 20 個 NLS 參數影響不同的 NLS 域,比如 NLS_LANG,NLS_DATE_FORMAT,NLS_TIMESTAMP_FORMAT,NLS_CURRENCY 等等。
共有四種設置 NLS 參數的方法,優先級依次增高
服務器端設置初始化參數
客戶端設置服務器變量
使用 ALTER SESSION 語句指定
使用 SQL 函數指定
Oracle 客戶端的環境變量 NLS_LANG 是聯邦數據庫中所使用的最重要的 NLS 參數。NLS_LANG 通過下面的語法指定語言、區域和代碼字符集。
NLS_LANG = language_territory.charset
從 Oracle 的角度來看,聯邦數據庫更像 Oracle 的一個客戶端應用程序,因此設置 Oracle 客戶端環境變量 NLS_LANG 是利用 Oracle 進行聯邦數據庫和 Oracle 服務器之間的代碼頁轉換前提條件。
聯邦數據庫 Oracle 包裝器可以在配置文件 db2dj.ini 裡配置環境變量 NLS_LANG。定義的格式和上面一樣,但是所指定的參數要根據聯邦數據庫的字符集、語言和區域設置來指定對應 Oracle 的參數。如果 NLS_LANG 沒有在 db2dj.ini 裡顯性指定,Oracle 包裝器在發起和 Oracle 服務器連接時,會根據聯邦數據庫的代碼頁來自動設置該參數。
例如,當聯邦數據庫的代碼頁是 GBK(1386)、區域代碼是 CN,並且 Oracle 服務器數據庫代碼頁是 UTF8,NLS_LANG 應該設置如下參數:
NLS_LANG=SimplifIEd Chinese_China.ZHS16GBK.
NLS_LANG 語言和區域參數指定了其他的 NLS 參數的默認值,如日期時間的格式、數字格式的顯示等等。您也可以設置這些 NLS 環境變量來改變的 NLS_LANG 對應的默認值。
聯邦數據庫 Oracle 封裝器只使用一種日期 / 時間戳格式。在與遠程 Oracle 數據源建立連接的時候,以下 Oracle 變量將被設置在當前會話中,這樣 Oracle 服務器和客戶端之間的日期 / 時間戳格式將依照這樣的格式。因此,其他日期 / 時間戳格式的數據將不能被正確處理,比如'20-MAY-2009'。
NLS_TIMESTAMP_FORMAT=YYYY-MM-DD HH24:MI:SS.FF
NLS_DATE_FORMAT=YYYY-MM-DD HH24:MI:SS
代碼頁轉換依賴於聯邦數據庫包裝器
聯邦數據庫可以幫助那些自身不能提供或者只能部分提供代碼頁轉換的遠端數據源完成相應轉換。例如,對於有表結構特征的文本文件,顯然數據源沒有代碼頁轉換的能力,此時聯邦數據庫中的 File 包裝器可以通過設置昵稱選項 CODEPAGE,提供不同代碼頁的轉換。
復雜情況下的代碼頁轉換
聯邦數據庫某些包裝器如 ODBC 包裝器,可以提供更為靈活的代碼頁轉換配置。下面,我們以 ODBC 包裝器為例進行說明。
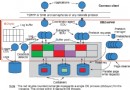
ODBC 包裝器可以聯邦所有支持 ODBC 3.0 標准的數據源,因此,ODBC 包裝器可以聯邦那些本身功能強大的數據源如 PostgreSQL,也可以聯邦一些非關系型數據源如文本文件。所以數據代碼頁轉換還依賴於 ODBC 驅動管理器、遠端數據源提供的 ODBC 驅動、遠端數據源客戶端以及服務器。例如,圖 4 展示了三種不同數據源 Classic Federation Server、Microsoft SQL Server 和 PostgreSQL 數據源。
圖 3. ODBC 包裝器的代碼頁轉換框架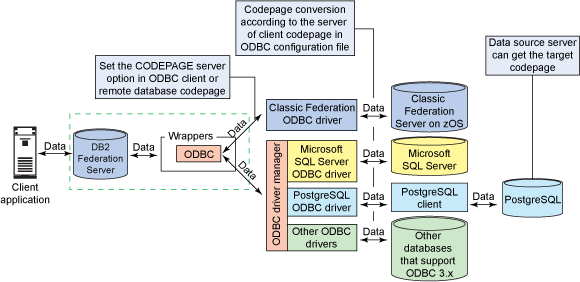
查看原圖(大圖)
假設 DB2 的客戶端應用程序通過昵稱從遠端數據源獲取數據。我們需要考慮以下四個部分:
遠端數據源服務器到其客戶端:例如對於 PostgreSQL,您可以在其服務器端設置參數來控制其客戶端和服務器的代碼頁轉換規則。
客戶端到數據源 ODBC 驅動:例如對於主機 Classic Federation Server,可以在客戶端 ODBC 配置文件中設置客戶機和服務器的代碼頁轉換規則。
數據源 ODBC 驅動到 ODBC 驅動管理器:例如對於 IBM Branded 的 DataDirect ODBC 驅動管理器,當使用 Unicode 應用程序和 ASCII 的 ODBC 驅動或者,使用 ASCII 應用程序和 Unicode 的 ODBC 驅動時,它可以提供與驅動之間的代碼頁轉換規則。如果使用 IBM Branded 的 DataDirect ODBC 驅動程序管理器,請到 DataDirect 網站上了解參數 IANAAppCodePage 更多細節。
ODBC 驅動管理器到 ODBC 包裝器:ODBC 包裝器來對於那些無法進行代碼頁轉換的 ODBC 驅動程序管理器或驅動器進行補償。
代碼頁轉換依賴於 DB2 應用程序客戶端
聯邦數據庫可以對異構數據源提供透明訪問,客戶端應用程序不用考慮在整個過程中進行了幾次代碼頁的轉換。通常 DB2 客戶端應用程序的代碼頁依賴於客戶端操作系統的 locale。但是,對於一些情況,在應用程序代碼頁和系統 locale 不兼容時,需要設置變量 DB2CODEPAGE。除此之外,對於 Java™ 應用程序,也需要一些特殊的配置。下面我們以 DB2 控制中心為例進行闡述。
在使用 DB2 的控制中心界面時,在數據源服務器、客戶端和聯邦數據庫包裝器的代碼頁都設置正確的前提下,仍然不能正確顯示 Unicode 字符如中文和日文。這些字符可以顯示在命令行窗口,但是卻不能在控制中心界面上顯示。為了深入了解此類問題,我們先介紹一些 Java 應用程序相關的編碼設置技術。
Java 虛擬機默認編碼格式
JVM 的每個實例都有一個默認的字符編碼格式,這個默認的編碼在虛擬機啟動的時候確定,並且一般會依賴於操作系統使用的 locale 和 encoding,我們可以通過下面這個命令查看 JVM 默認的編碼格式 encoding=System.getProperty(“file.encoding”)
Java 以系統默認編碼讀入源文件,然後按 Unicode 進行編碼。Java 運行時,也采用 Unicode 編碼,為了提高內存空間利用效率對 Unicode 字符編碼采用了 UTF-8 的方式編碼,並且默認輸入和輸出的都是操作系統的默認編碼。
當數據需要被以一種不同於 file.encoding 中的編碼格式讀入或者讀出 Java 程序的時候,可以使用 Java IO 類,比如 java.io.InputStreamReader, java.io.FileReader, java.io.OutputStreamReader, java.io.FileWriter,Java.lang.String. 它們支持在其中聲明一個編碼格式的值來替代現在 JVM 中使用的默認編碼格式的值。下面的代碼給出了一個簡單的例子:
清單 1. Java 類替代虛擬機默認編碼格式
System.out.println("File.encoding"=System.getProperty("file.encoding"));
stmt = conn.createStatement();
ResultSet resultSet = stmt.executeQuery("SELECT * FROM my_table");
while (resultSet.next()) {
String s = resultSet.getString(1);
System.out.println(s);
//the hex value of s
String hexs="";
byte[] bytes = s.getBytes();
for (int i = 0; i < bytes.length; i++) {
String hex = Integer.toHexString(bytes[i] & 0xFF);
if (hex.length() == 1) {
hex = '0' + hex;
}
hexs += hex.toUpperCase();
}//for
System.out.println(hexs);
} //while
Java 應用與數據庫
在下面的代碼段中,我們給出了一個用 Java 來訪問數據庫的例子:
清單 2. Java 類訪問數據庫時的代碼頁轉換
System.out.println(System.getProperty("file.encoding"));
stmt = conn.createStatement();
ResultSet resultSet = stmt.executeQuery("SELECT * FROM my_table");
while (resultSet.next()) {
String s = resultSet.getString(1);
System.out.println(s);
//the hex value of s
String hexs="";
byte[] bytes = s.getBytes();
for (int i = 0; i < bytes.length; i++) {
String hex = Integer.toHexString(bytes[i] & 0xFF);
if (hex.length() == 1) {
hex = '0' + hex;
}
hexs += hex.toUpperCase();
}//for
System.out.println(hexs);
} //while
在不同的編碼格式下,它的輸出顯示如下:
表 1. 同一程序在不同虛擬機上運行的不同結果
輸出 1 輸出 2 GB18030 ISO8859-1 北京 ?? B1B1BEA9(北京的 GBK 編碼) 3F3F2020 (亂碼) 中國 ?? D6D0B9FA(中國的 GBK 編碼) 3F3F2020(亂碼)
如果默認的虛擬機編碼是 GB18030,Java 程序會將從數據庫讀入的數據按 GBK 進行編碼。如果默認的虛擬機編碼是 ISO8859-1,數據將會被先轉換為 ISO8859-1 編碼,然後從 ISO8859-1 轉換到 Java 內部編碼 Unicode。但是編碼 ISO8859-1 不支持中文,因此會顯示亂碼。
如果操作系統編碼是 ISO8859-1,從數據庫中取出的中文字符就沒法轉換成操作系統編碼格式下的二進制,從而不能顯示出結果來,解決方法是通過 db2set 命令設置 DB2 客戶端的編碼格式為 GBK。
解決 Java 應用程序的中日文等 Unicode 字符集顯示的問題,一種方法是將 JVM 的默認編碼格式改為支持中文或者日文的編碼格式,如 GB18030,由於 JVM 的默認編碼依賴於操作系統,這就需要將操作系統改為中文或者日文的操作系統。
在不改變操作系統 locale 等設置的情況下,我們還可以在編譯和運行的時候加入編碼格式參數來覆蓋 JVM 默認編碼格式的值。例如對於上面的 JVM 默認編碼是 ISO8859-1,中文字符顯示為亂碼的程序,我們可以通過以下的方式編譯和運行:
javac -encoding GB18030 testEncoding3.Java
Java -Dfile.encoding=GB18030 testEncoding3.class
運行結果可以看到程序中的編碼格式已經被我們在運行時設置的參數覆蓋:
清單 3. JVM 編碼改變後的結果輸出
GB18030
北京
B1B1BEA9
中國
D6D0B9FA
Java 應用與聯邦數據庫
Java 應用直接訪問遠端數據源中的數據與從聯邦數據庫中通過別名訪問遠端數據有什麼區別呢?我們可以通過下面的代碼段來進行比較
清單 4. Java 類訪問聯邦數據庫時的代碼頁轉換
System.out.println(System.getProperty("file.encoding"));
stmt = conn.createStatement();
ResultSet resultSet = stmt.executeQuery("SELECT hex(col) FROM my_nick");
while (resultSet.next()) {
String s = resultSet.getString(1);
System.out.println(s);
}//for
System.out.println(hexs);
} //while
假設聯邦數據庫編碼為 GBK,遠端數據源編碼為 UTF8。聯邦數據庫建立一個基於遠端數據源表“my_table”的昵稱“my_nick”。用這個測試腳本,可以看到從昵稱讀到的字節編碼是 GBK,而從遠端數據表中讀到的字節編碼為 UTF8。所以當 Java 應用程序訪問通過聯邦數據庫訪問遠端表時,並不關心遠端數據源的代碼頁。在這種情況下,它會先將數據從 GBK 編碼轉換為 JVM 的編碼,然後 JVM 會轉換其編碼為 Unicode。
包裝器代碼頁配置匯總表
由於篇幅限制,我們不能對所有的包裝進行更詳細的介紹,表 2 提供一個代碼頁轉換參數匯總表便於讀者參考。
表 2. 配置匯總表
包裝器
配置選項
說明
ODBC
CODEPAGE
設置服務器選項 CODEPAGE,指定 ODBC 客戶端的代碼頁。另外,可以根據此數據源的文檔設置數據源特有的代碼頁轉換配置。
Microsoft SQL Server
CODEPAGE
設置服務器選項 CODEPAGE,指定 Microsoft SQL Server 客戶端的代碼頁。
Oracle
NLS_LANG
如果在 db2dj.ini 文件中設置 NLS_LANG 環境變量 , 包裝器會使用該代碼頁。如果沒有設置 NLS_LANG,包裝器會根據 DB2 的區域代碼和代碼頁選擇對應的 Oracle 地區代碼進行設置。若沒有對應的代碼頁,Oracle 包裝器會默認 NLS_LANG 的值為 American_America.US7ASCII。
Teradata
TERADATA_CHARSET
如果在 db2dj.ini 文件中設置 TERADARA_CHARSET 環境變量 , 包裝器會使用該代碼頁。若該值不是有效值,Teradata 包裝器會返回錯誤。如果沒有設置 TERADARA_CHARSET,包裝器會根據 Teradata 客戶端字符集設置代碼頁。
Sybase
Sybase_CHARSET
如果在 db2dj.ini 文件中設置 SYBASE_CHARSET 環境變量 , 包裝器會使用該代碼頁,你可以在 $SYBASE\charsets 目錄下查看所有 Sybase 支持的字符集。若該值不是有效值,Teradata 包裝器會返回錯誤。如果沒有設置 SYBASE_CHARSET,包裝器會根據 DB2 字符集相對應的 Sybase 字符集設置代碼頁。若沒有相對應的代碼頁,Sybase 包裝器會默認 iso_1 字符集。
Informix
CLIENT_LOCALE
DB_LOCALE
DBNLS
下列三個變量需要如果設置在聯邦數據庫 db2dj.ini 文件中,包裝器會使用該代碼頁:
CLIENT_LOCALE
指定 Informix 的 locale,如果沒有設置 CLIENT_LOCALE,包裝器會根據 DB2 的區域代碼和代碼頁選擇對應的 Informix 地區代碼進行設置。若沒有對應的代碼頁,Informix 包裝器在 UNIX®平台會默認 en_us.8859-1,而在 Windows®平台上默認為 en_us.CP1252。
DB_LOCALE
該環境變量用來指定 Informix 數據庫的代碼頁。使用後 Informix 將會按照 Infomix 數據庫和客戶端的代碼也進行轉換。
DBNLS
指定 Informix 是否需要驗證環境變量 DB_LOCALE 的值與 Informix 數據庫的實際區域代碼吻合。
Flat File
CODEPAGE
昵稱選項,用來設置文本文件和聯邦數據庫代碼頁轉換。
Control Center
Font.propertIEs
font.propertIEs 配置文件用來設置 Java 和操作系統字體映射
常見問題及解決辦法
為什麼在使用 DB2 命令行窗口連接 GBK 代碼頁的數據庫時遇到 SQL0332N 錯誤?
該錯誤的原因是,用戶所在客戶端的代碼頁為 ISO8859-1。解決辦法可以有兩種:設置 DB2CODEPAGE 為 GBK 或者不設置 DB2CODEPAGE 的前提下改變操作系統的 locale 為支持中文。
為什麼在使用 DB2 控制中心時,中文顯示的是亂碼?
原因是用戶沒有正確設置從 Java 邏輯字體到物理字體的映射,或者該物理字體沒有被安裝。
為什麼在使用代碼頁為 GBK 的聯邦數據庫去聯邦遠端代碼頁為 UTF8 的 Oracle 數據庫時,顯示亂碼?
聯邦數據庫的代碼頁為 GBK,Oracle 數據庫的代碼頁為 UTF8。在 Oracle 數據庫中定義 Table T1(C1 varchar(10)) 並插入 “中國”“北京”兩行記錄。清單 5 展示了表 T1 的內容和其 UTF8 編碼。
清單 5. Oracle 服務器中表 T1 的數據和 UTF8 編碼
SQL> select * from t1;
C1
----------
中國
北京
SQL> select dump(C1,16) from t1;
DUMP (C1,16)
---------------------------------------
Typ=1 Len=6: e4,b8,ad,e5,9b,bd
Typ=1 Len=6: e5,8c,97,e4,ba,ac
設置 NLS_LANG=SimplifIEd Chinese_China.UTF8。通“select userenv('language') from dual”語句獲取 Oracle NLS 參數的值, 並將該值設置到 db2dj.ini 文件中,NLS_LANG=SimplifIEd Chinese_China.UTF8。
清單 6. Oracle 的 NLS 參數值
SQL> select userenv('language') from dual;
USERENV('LANGUAGE')
----------------------------------------------
SIMPLIFIED CHINESE_CHINA.UTF8
在聯邦數據庫端查詢後,結果顯示為亂碼
從聯邦數據庫中查詢昵稱,得了錯誤編碼的數據。因為 NLS_LANG 在配置文件 db2dj.ini 中設置成 UTF8 編碼,並且 Oracle 的客戶端 和服務器之間並無代碼頁轉換,所以聯邦數據庫獲得的中文字符並沒有做代碼頁轉換,從而不能顯示期望的結果。
清單 7. 設置 NLS_LANG= SimplifIEd Chinese_China.UTF8 時,聯邦數據庫昵稱的查詢結果
=> db2 "select * from N1"
C1
----------
涓 浗
鍖椾含
2 record(s) selected.
=> db2 "select hex(C1) from N1"
1
--------------------
E4B8ADE59BBD
E58C97E4BAAC
2 record(s) selected.
改變 db2dj.ini 中參數 NLS_LANG 的設置為 GBK,並重新啟動 DB2,Oracle 服務器的 UTF8 字符將會被正確的轉換成 GBK 字符編碼。
清單 8. 設置 NLS_LANG= SimplifIEd Chinese_China.ZHS16GBK 時,聯邦數據庫昵稱的查詢結果
=> db2 "select * from N1"
C1
----------
中國
北京
2 record(s) selected.
=> db2 "select hex(C1) from N1"
1
--------------------
D6D0B9FA
B1B1BEA9
2 record(s) selected.
綜述所說,在 db2dj.ini 應該設置正確的 NLS_LANG 參數,因為該參數是 Oracle 的必要參數,並且其值應該遵循 Oracle 的 NLS_LANG 的格式。
結論
本文主要解釋了聯邦數據庫如何很好的支持多國語言和代碼頁。基於一些實際用戶應用時遇到的問題,我們根據用戶不同的環境和場景提供了多種靈活的解決方法。根據本文,用戶可以更為容易的使用聯邦數據庫和異構數據源。