本文是“使用腳本加速 DB2 存儲過程的開發”的升級篇。在前一篇文章中我們通過使用 Windows 下的 bat 批處理 (.bat) 腳本來幫助我們進行數據庫開發。本文中介紹的 mydbtool 腳本是對它們的重寫。mydbtool 是用 shell 腳本來編寫的。之所以使用 shell 而不是 bat,是因為 shell 提供了更多的功能,而且它可以在 Windows(Cygwin) 和 Linux/Unix 等系統下使用。所以 mydbtool 是一個功能更強大,而且跨平台的工具。本文不會重復介紹前一篇已經介紹過的命令,它們在 mydbtool 腳本中仍然適用。下面我們將主要討論 mydbtool 腳本提供的一些高級功能。
本文主要討論使用 Shell 腳本與 DB2 交互的一些技巧和方法。介紹了利用 Shell 腳本幫助我們進行存儲過程調優和部署。同時通過一個演示項目的開發過程的介紹來展示如何使用文中的腳本進行開發。
背景
我們遇到的問題
在項目中我們大量使用了存儲過程,並且每三個月發布一個新版本。在開發每個版本中,我們要經過:Unit Test,Function Verification Test (FVT) 和 User Acceptance Test (UAT) 階段,然後我們才會把代碼發布到 Production 環境。每個階段對應一個數據庫(fvtdb,uatdb 和 proddb 等 )。大家知道,存儲過程的部署不像 J2EE 應用程序的部署。J2EE 應用程序只需要把所有的 Java class, XML,JSP 等文件打成 ear 包,部署到 J2EE 服務器上就可以了。但是存儲過程的部署需要我們只更新修改過的存儲過程。因此,如何正確快速的把存儲過程部署到為數眾多的數據庫中,就是一個很大的問題。
我們的解決方案
敏捷開發要求我們能夠迅速應對變化,快速應對變化就要求我們盡量把一些耗時的工作自動化。出於這個目的,我們開發了 mydbtool 腳本來解決我們遇到的問題。它提供很多數據庫開發和部署的工具,可以大大提高開發工作的效率和准確性。其部署工具可以比較數據庫 (fvtdb, uatdb 和 proddb 等 ) 之間的不同,生成一個報告。通過該報告,我們可以很容易的把更新的存儲過程部署到正確的數據庫環境中。
在介紹 mydbtool 之前,讓我們先了解一下 Cygwin 和 Shell。
Cygwin 簡介
Cygwin 是一個用於在 Windows 上模擬 Linux/Unix 操作系統環境的軟件。運行 Cygwin 後,你會得到一個類似 Linux/Unix 的 Shell 環境,在其中你可以使用絕大部分 Linux/Unix 軟件和功能。如 sed, awk, 運行 Shell 腳本等等,總之如果你想使用某個 Linux/Unix 下 的功能,而 Windows 上又找不到好的軟件的話,你就可以采用 Cygwin。這樣就解決了我們的問題,我們開發好一套 Shell 腳本後,如果你用的工作站是 Linux/Unix,那麼可以直接運行腳本;如果你用的是 Windows 操作系統,那麼可以把腳本放到 Cygwin 環境下運行,效果是一樣的。
Cygwin 的下載及安裝:請參見 參考資料 中的 "Cygwin 中國鏡像"。你只需要安裝默認的軟件包就可以開始使用 mydbtool 腳本了。
Shell 編程簡介
Shell 也叫做命令行界面,它為我們和 Linux/Unix 系統之間提供了一個交互的接口。用戶既可以輸入命令來執行各種各樣的任務,也可以通過編寫 Shell 腳本完成更加自動化和復雜的操作。它的作用就是按照一定的語法規范將用戶指令加以轉化並傳給系統進行處理。
Linux/Unix 操作系統提供了幾種不同的 Shell, 如 Bourne Shell(/bin/sh)、Korn Shell(/bin/ksh)、Bourne Again Shell(/bin/bash)、 Tenex C Shell(tcsh)、C Shell(/bin/csh) 等,其中 Bourne Again Shell( 即 bash) 是自由軟件基金會 (GNU) 支持開發的一個 Shell 版本,它是很多 Linux 系統中一個默認的 Shell。Cygwin 中默認的 Shell 也是 Bash。
本文的 mydbtool 腳本就是采用 Bash 來編寫的,它充分利用了 DB2 的常用命令和 sed, awk 等 Linux/Cygwin 下的文本處理工具。
mydbtool 用法簡介
要使用 mydbtool 腳本,你需要把本文中的附件 mydbtool.zip 解壓到某個目錄,然後把該目錄放到 PATH 裡面。
清單 1. 使用 export 設置 PATH 變量
export PATH=mydbtool_dir;$PATH
mydbtool 有兩種使用模式,一種是交互式,一種是命令式。交互式方式方便用戶執行 DB2 命令。命令式則可以在其他腳本中調用 mydbtool。在控制台輸入 mydbtool 然後回車就會進入交互模式。在交互模式中你可以使用 mydbtool 的很多命令。 mydbtool 的命令模式需要在調用的時候加一個參數 -d [database name]。下面,我們會依次介紹 mydbtool 中各個命令的使用方法。
在命令行中輸入: mydbtool help。我們就可以看到一個簡單的幫助。
清單 2. mydbtool 的幫助
will@will-laptop:~$ mydbtool help
mydbtool --- An easy way to use DB2
list of commands:
conn [dbname] -- Connect to a database
listconn -- List all connections
view [spname] -- VIEw the source code of Stord Procedure or UDF
table [table name] -- VIEw the definition of table
dep [table name] -- VIEw the dependence
column [schemaname.tablename.columnname]
-- Determine dependencIEs for a column name
check [spname] -- Call the sample call in the source code
e [SQL file or SQL statment] -- Execute the SQL file.
rebindall -- Rebind all invalid Stored Procedure
rebindsp [spname] -- Rebind a Stored Procedure
exp [file path] -- Get Access plan for a given SQL in the file
expsp [spname] -- Get Access plan for Stored Procedure
diffsp [db_A] [db_B] [file path] -- Compare Stord Procedures between two databases
diffgrant [db_A] [db_B] [file path] -- Compare grant statment between two databases
difftab [db_A] [db_B] [file path] -- Compare tables/vIEws between two databases
diffdata [db_A] [db_B or file] [file path]
-- Compare data for a given sql file
diffdb [db_A ] [db_B] [project path] (date)
-- Compare database objects between two databases
editor -- Set text editor to open file generated by mydbtool
quit -- Exit
will@will-laptop:~$
建立連接
在我們項目組有很多數據庫,而且如果在連接數據庫時密碼輸錯三次,用戶就會被鎖住,需要讓經理去解鎖。所以為了減少錄入密碼錯誤, mydbtool 會記錄下數據庫的用戶名和密碼。下次你連接相同數據庫時就不需要再次輸入密碼。
在命令行中輸入: conn [ 數據庫名稱 ]。如果你曾經連接過該數據庫, mydbtool 會使用你上次的用戶名和密碼連接數據庫。如果你以前沒有連接該數據庫,或者數據庫的密碼被修改了。mydbtool 會提示你重新輸入相關連接信息。請看下面的程序流程圖。
圖 1. 連接數據庫函數的流程圖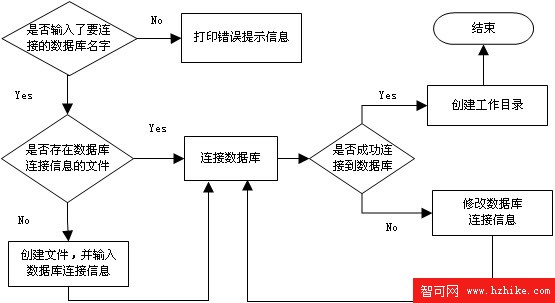
查看原圖(大圖)
如果您想知道 mydbtool 記錄了哪些連接信息, 輸入 listconn 命令 :
清單 3. 顯示連接信息
will@will-laptop:~$ mydbtool listconn
duke webduke db2user passWord
rod webrod db2user passWord
roll webroll db2user passWord
rail webrail db2user passWord
plug webplug db2user passWord
EDITOR:eMacsclIEnt
will@will-laptop:~$
所有連接信息都記錄在 ${HOME}/mydbtool.profile 文件中,其中 EDITOR 屬性是用來設置你希望用什麼工具打開文本文件。你可以改成你喜歡的文本編輯器,也可以刪除該屬性,讓 mydbtool 使用系統默認的文本編輯器。
獲得數據庫對象信息
mydbtool 提供了一些命令用於方便獲取數據庫對象的信息。運行這些命令前,你需要先使用 conn 命令連接上一個數據庫。
vIEw 命令用於獲得數據庫中用 SQL 編寫的存儲過程或者 UDF 的源代碼。
清單 4. vIEw 命令示例
# 交互模式
db2==>conn duke
webduke==>vIEw ebiz1.i_qt_quote
# 命令模式
mydbtool -d duke vIEw ebiz1.i_qt_quote
table 命令用於獲得表的相關信息,包括列的信息,外鍵,主鍵和索引。
清單 5. table 命令示例
# 交互模式
db2==>conn duke
webduke==>table ebiz1.web_quote
# 命令模式
mydbtool -d duke table ebiz1.web_quote
dep 命令用於獲得依賴於某個表的所有數據庫對象。
清單 6. dep 命令示例
# 交互模式
db2==>conn duke
webduke==>dep ebiz1.web_quote
# 命令模式
mydbtool -d duke dep ebiz1.web_quote
column 命令是用於獲得依賴與表中某一列的數據庫對象。在數據庫開發中,有時候我們確實需要知道,哪些存儲過程用到了表中的某一列。例如,我們需要把某列刪除或者改名時,可以使用 column 命令分析列修改後的影響。 column 命令的參數格式是: schema.tablename.columnname。
清單 7. column 命令示例
# 交互模式
db2==>conn duke
webduke==>column ebiz1.web_quote.web_quote_num
# 命令模式
mydbtool -d duke column ebiz1.web_quote.web_quote_num
check 命令用於快速測試某個存儲過程。我們在編寫存儲過程時,會把一些存儲過程調用的例子放在注釋裡面。 check 命令會提取這些例子,並調用他們,這樣我們就很容易的看出,該存儲過程在數據庫中工作是否正常。
清單 8. check 命令示例
# SQL 文件裡的 Sample Call
-- Sample Calls:
-- call EBIZ1.I_QT_QUOTE (?, ?, 'changwei@cn.ibm.com' , 'USA', 'USD', '', '', '', NULL)
# 交互模式
db2==>conn duke
webduke==>check ebiz1.i_qt_quote
# 命令模式
mydbtool -d duke check ebiz1.i_qt_quote
監控數據庫
本節我們將介紹一些用於執行,監控和調優的命令。運行這些命令前,你需要先使用 conn 命令連接上一個數據庫。
e 命令用於執行一個 SQL 文件或者一個 SQL 語句。e 命令會檢查傳入的參數是否是一個文件,如果是就會執行該文件 ; 如果不是, e 命令會把參數當做 SQL 語句執行。
清單 9. e 命令示例
# 交互模式
db2==>conn duke
# 執行一條 SQL 語句
webduke==>e select count(1) from ebiz1.web_quote
loading on [webduke] and logged in [logs/122809/webduke/run_webduke.log]
1
-----------
56764
1 record(s) selected.
# 執行一個文件
webduke==>e demo.sql
[demo.sql] is loading on [webduke] and logged in [logs/122809/webduke/run_webduke.log]
1
-----------
56764
1 record(s) selected.
webduke==>
# 命令模式
mydbtool -d duke e demo.sql
[demo.sql] is loading on [webduke] and logged in [logs/122809/webduke/run_webduke.log]
1
-----------
56764
1 record(s) selected.
rebindall 命令用於把非法的存儲過程重新編譯一遍。存儲過程經常會因為其依賴的表的修改而變成非法的。如果把那些非法的存儲過程重新再裝載一遍,那就太麻煩了。rebindall 命令幫我們解決了這個問題,它會把所有的非法的存儲過程編譯一遍,使得它們再次可用。rebindall 命令沒有參數。
清單 10. rebindall 命令示例
# 交互模式
db2==>conn duke
webduke==>rebindall
# 命令模式
mydbtool -d duke rebindall
rebindsp 命令用於重新編譯某一個存儲過程,當我們建立一個索引以後,通常需要編譯其相關的存儲過程使得執行計劃使用新建的索引。這個命令就是幫助我們做這件事情的。
清單 11. rebindsp 命令示例
# 交互模式
db2==>conn duke
webduke==>rebindsp ebiz1.i_qt_quote
# 命令模式
mydbtool -d duke rebindsp ebiz1.i_qt_quote
exp 和 expsp 命令用於生成文本格式的數據庫執行計劃。在大型的應用系統中,性能是一個不可回避的問題。一般我們可以通過創建索引來提高數據庫的性能。為了確定需要創建哪些索引,我們一般會查看數據庫的執行計劃,看其中有沒有進行表掃描,如果掃描的表是一個數據量很大的表,我們就需要建立相應的索引。 exp 命令的參數是需要解析的 SQL 文件,expsp 命令的參數是需要解析的存儲過程名稱。
清單 12. exp 和 expsp 命令示例
# 交互模式
db2==>conn duke
webduke==>exp demo.sql
webduke==>expsp ebiz1.i_qt_quote
# 命令模式
mydbtool -d duke exp demo.sql
mydbtool -d duke expsp ebiz1.i_qt_quote
比較數據庫對象
本節我們將介紹 mydbtool 中最重要的一些命令。這些命令用於比較數據庫。
diffsp 命令是用於比較存儲過程或者 UDF 在兩個數據庫之間的不同。此命令有三個參數: 源數據庫,目標數據庫和一個文件路徑,該文件裡面列出了需要比較的存儲過程的名稱。
清單 13. diffsp 命令示例
# 交互模式
webduke==>diffsp duke rod sp_change_list.txt
# 命令模式
mydbtool diffsp duke rod sp_change_list.txt
difftab 命令是用於比較表在兩個數據庫之間的不同,包括表相關的索引和訪問權限。此命令有三個參數: 源數據庫,目標數據庫和一個文件路徑,該文件裡面列出了需要比較的表的名稱。
清單 14. difftab 命令示例
# 交互模式
webduke==>difftab duke rod table_change_list.txt
# 命令模式
mydbtool difftab duke rod table_change_list.txt
diffdb 命令是前面兩個命令的組合,它會比較存儲過程,UDF,表,索引和訪問權限。此命令有四個參數: 源數據庫,目標數據庫,存儲存儲過程源程序的項目目錄和日期。這裡,我們解釋一下後兩個參數。diffsp 和 difftab 命令中需要一個包含要比較對象的列表 (Change List),有時候准備這個列表也是比較麻煩的,所以在 diffdb 中, mydbtool 幫助我們准備這個列表文件。我們告訴存儲過程和表的源文件的存放目錄和一個時間,mydbtool 會找到所有在該時間後修改過的文件,然後從這些文件中取出表或者存儲過程的名稱,這樣一個列表文件就有了。然後 diffdb 再使用這個列表文件調用 diffsp 和 difftab 命令來得到比較結果。
清單 15. diffdb 命令示例
# 交互模式
webduke==>diffdb duke rod ~/v1_0/quoteSQL 200905010000
# 命令模式
mydbtool diffdb duke rod ~/v1_0/quoteSQL 200905010000
項目開發實例
我們已經發布了該系統的 v1.0 版。現在在 v2.0 版開發中,我們項目中有如下數據庫,
webduke: 開發數據庫,用於開發調試存儲過程和進行 Unit Test。
webrod: FVT 數據庫,用於集成測試和功能驗證。
webroll: UAT 數據庫,用於全面的測試,為發布作准備。
webplug: 生產數據庫,我們的項目會發布到該數據庫供最終用戶使用。
webrail: 該數據庫環境和生產環境是一致的。用於重現和修復最終用戶發現的系統 bug。
表 1. 開發環境信息
版本 SQL 文件存儲路徑 開發起始時間 v1.0 ~/v1_0/orderSQL 2009 年 7 月 1 日 v2.0 ~/v2_0/orderSQL 2009 年 10 月 8 日
隨著需求的不斷增長, 我們的《訂單管理系統》的功能越來越豐富,同時為了支持數據挖掘,我們系統裡的表還被其他系統的存儲過程訪問。我們有一個新的需求: 把字段 MIS.ORDER.ORDER_TYPE 的類型從 Int 改為 String。
首先,讓我們來分析一下這個改動對系統的影響:需要修改哪些存儲過程或者 UDF ; 對其他應用系統有沒有影響等等。如何確定改動所引起的影響呢?可能有人會說,使用 dep 命令就可以得到依賴表 MIS.ORDER 的存儲過程和 UDF。對,我們可以使用 dep 命令。但是,現在我們系統已有上百個存儲過程,引用 MIS.ORDER 表的存儲過程也有幾十個,而且其他應用系統的存儲過程也依賴 MIS.ORDER 表。我們去檢查這幾十個存儲過程,不但費時,而且也容易出錯。這裡,我們使用 column 命令。
清單 16. 獲得 ORDER_TYPE 的引用
mydbtool -d duke column mis.order.order_type
mydbtool 列出了十個引用該列的存儲過程。現在我們只需要研究一下這十個存儲過程如何修改就可以了。
確定了需要修改的存儲過程,我們就可以使用 mydbtool 提供的命令來開發存儲過程了。這裡不再多說。感興趣的讀者可以參考“使用腳本加速 DB2 存儲過程的開發”。這裡我們主要介紹一下如何使用 mydbtool 進行存儲過程性能調試和部署。
我們發現,MIS.S_QT_Access_USER 這個存儲過程的性能特別差,我們需要對它進行性能調優。我們使用 expsp 獲得該存儲過程的執行計劃。
清單 17. 獲得存儲過程 MIS.S_QT_Access_USER 的執行計劃
mydbtool -d duke expsp mis.s_qt_Access_user
根據 mydbtool 生成的執行計劃,我們發現存儲過程中的第二個游標的 cost 很大,而且有表掃描( table scan )。於是我們建立了一些索引來避免表掃描。然後,我們需要重新編譯綁定這個存儲過程和獲得新的執行計劃。
清單 18. 編譯和獲得存儲過程 MIS.S_QT_Access_USER 的執行計劃
mydbtool -d duke rebindsp mis.s_qt_Access_user
mydbtool -d duke expsp mis.s_qt_Access_user
根據新的執行計劃,我們看到這個存儲過程的 cost 降低了很多。通過 check 命令,我們測試可以看到執行速度從 10 秒降到了 2 秒。我們在開發數據庫 webduke 修改完了所有的存儲過程,現在我們需要把它們部署到 FVT 數據庫 webrod 上。如何確定哪些存儲過程需要部署到 webrod 上呢? 解決這個問題,有兩種方法。方法一,我們記錄下所有修改的存儲過程名稱,然後使用 mydbtool 的 e 命令把它們部署到 webrod 上。這種方法對於小項目或者說小的修改是可行的。但是對於像我們有幾十個人的跨國開發團隊,把所有修改過得存儲過程記錄在文檔中,顯然有些困難,而且也不高效。我們使用方法二, webduke 是我們的開發數據庫,所有修改的存儲過程都部署在那裡,並且被開發人員測試過了。 webrod 上的存儲過程是上個版本 v1.0 的。我們只需要比較 webduke 和 webrod 上的存儲過程的異同,就可以知道在這個版本 v2.0 中我們修改了哪些存儲過程,這些修改了的存儲過程需要部署到 webrod 上去。
清單 19. 獲得 v2.0 中修改的存儲過程
mydbtool diffdb duke rod ~/v1.0/orderSQL 200907010000
mydbtool 的 diffdb 命令給我們生成了一個報告,報告中有需要部署到 webrod 上的存儲過程名稱列表 cr_list.txt 和一個部署它們的 Shell 腳本 cr_report.txt 。我們把 cr_report.txt 文件重命名為 cr_rod.sh,並且在文件開頭加上連接數據庫的命令。然後我們就可以使用 cr_rod.sh 部署存儲過程了。
清單 20. 部署修改的存儲過程
bash cr_rod.sh
現在讓我們簡單的測試一下 webrod 上的存儲過程。
清單 21. 簡單驗證部署情況
mydbtool -d rod check ebiz1.i_qt_quote
我們在控制台上可以看到 mydbtool 調用存儲過程中的 Sample Call 的情況。
當然,在我們從 FVT 到 UAT 再到 Production 的過程中,都是使用 diffdb 來進行部署的。可以看到, diffdb 為我們減少了很多工作量,同時避免了錯誤。
結束語
腳本文件是我們開發 DB2 數據庫應用的一大利器。我們充分利用腳本文件,可以提高開發效率。畢竟,每次在需要的時候,都去重新編寫同一個命令是一件很麻煩的工作。而腳本文件的最大好處,就是可以提高語句的重用性,節省我們編寫語句、調試測試的時間。
本文示例源代碼或素材下載