簡介
高可用性是重要數據庫應用程序的關鍵需求。IBM DB2 9.5 提供了很多特性來滿足這一需求。如果您對分布式平台上的 DB2 還不是很了解,或者已經使用過一陣子,您可能會發現這組處理可用性的特性令人困惑。什麼時候使用哪個特性,當使用特性時,您希望完成什麼目標?
本文的目的就是總結這些特性,並指導您理解如何使用 DB2 技術構建高度可用的數據庫系統。此外,發現每種解決方案的成本和優點。
在開始之前,我們先來定義術語高可用性(HA)的意義。HA 是指要求在依賴性應用程序需要數據時能夠提供數據。其目的是消除或盡量避免停機。與 HA 相關的一個術語是災難恢復(Disaster Recovery,DR),DR 與 HA 的不同之處在於,它側重於保護數據,防止因災難性故障導致數據丟失。本文只關注 HA。
術語和客戶機/服務器數據庫架構
術語和客戶機/服務器數據庫架構
我們首先討論一些術語和概念,這對理解高可用性十分重要。
一個數據庫解決方案包括三個部分的軟件:
用戶應用程序
客戶機軟件
數據庫引擎
除了軟件,要得到一個有效的解決方案,還必須擁有一些其他資源:
服務器硬件
網絡連接
磁盤存儲
操作系統
當設計一個 HA 解決方案時,必須考慮所有這些方面。僅僅使數據庫引擎高度可用未必就能創建出一個 HA 解決方案。HA 解決方案的設計並不完全是一個技術問題,它還必須考慮其他一些因素,例如解決方案的成本、技能需求以及管理需求。
數據庫應用程序是基於客戶機/服務器的。應用程序能否產生一致的結果,取決於數據庫軟件的完整性。雖然這一點是顯而易見的,但是它在選擇和設計解決方案時十分重要。
SQL 事務可分為兩種類型:讀和寫。讀事務是不需要插入、更新或刪除活動的選擇語句。而寫事務則要更改至少一個數據庫。讀事務需要數據的一致視圖 —— 即當同時提交兩個讀事務時,如果它們選擇相同的數據范圍,那麼應該產生一致的結果集。寫事務要求提交的數據庫更改被持久化,即使出現故障時也是如此。業務需求會影響到什麼 HA 解決方案是可用的或者是最適合的。通常,HA 解決方案的設計由兩個因素驅動,正常運行時間(uptime)需求和事務一致性。如果業務要求更高的可用性,並且讀一致性不是很重要,那麼選擇異步可能是更經濟的方法。另一方面,如果事務一致性是關鍵需求,那麼則需要選擇更加同步的解決方案。如果事務一致性和可用性都是必需的,那麼將進一步縮小可選擇的范圍。
高可用性
有兩種類型的高可用性可供選擇:持續可用性(continuous availability)和故障轉移可用性(failover availability)。
持續可用性
持續可用性要求數據庫引擎隨時可用,沒有可覺察的停機時間。在這些場景中,停機時間以不存在、一秒或數秒來度量。傳統上,只會在最關鍵的應用程序中實現這種類型的可用性。為實現這個目標,需要有高度的冗余。
對於這些類型的系統,有三種基本的設計 —— 編程式(programmatic)可用性、共享(shared)可用性和多重副本(multiple copy)可用性。
編程式可用性
編程式的設計實際上是一個用戶編程解決方案,它不是在數據庫級實現的,而是在用戶應用程序級實現的。實際上,應用程序在多個系統上實現 SQL 事務。一個系統上出現故障不會導致其他系統上的事務被中斷。應用程序邏輯使應用程序即使在一個數據庫系統出現故障時仍可以繼續執行工作。
這種類型的系統具有最大的靈活性,但同時也要求實現大量的工作。當編寫這些類型的環境時,DB2 對分布式工作單元和事務監視器的支持可以提供一定的幫助,但是大部分工作仍有賴於應用程序開發小組。編寫的所有應用程序都必須支持您的設計。“開箱即用” 應用程序將不能理解您的環境。另外還需要解決其他問題:
保持數據庫系統的同步
非確定函數的使用
非原子存儲過程的使用
非確定函數是指根據不同的運行環境可能產生不同的輸出的函數。例如,由於系統時鐘不同步,或者語句不可能完全在同一時間到達系統,DB2 專用寄存器 CURRENT TIMESTAMP 在不同的系統上會產生不同的輸出。
非原子存儲過程是指不作為一個整體一起提交或回滾的存儲過程。根據運行的環境,存儲過程中的事務可能產生不同的結果。
表 1. 編程式可用性
優點
缺點
靈活性
應用程序開發時間和成本
缺乏對打包應用程序的支持
復雜性
共享可用性
共享設計在共享關鍵資源的同時使用冗余系統。這種共享設計是這樣工作的:如果有 2 個或更多的系統在工作,當其中一個系統出現故障時,其他的系統可以繼續工作。成員之間並非完全獨立,而必須通過共享機制或數據才能執行它們的工作。
最常見的共享資源是物理數據存儲。圖 1 演示了數據如何被存儲在一個中央存儲系統上,並被三個成員訪問。
圖 1. 共享可用性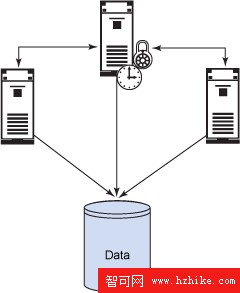
為了讓這種架構能夠正確地運行,需要共享的資源不僅僅是共享存儲。為了讓每個系統執行工作,它們必須共享一些類型的鎖和鎖機制。鎖機制使得每個系統可以在共享數據上執行工作,同時不會執行對其他成員正在執行的工作造成干擾。例如,如果一個成員正在更新一行數據,那麼另一個成員就不能以未提交讀(uncommitted read)以外的任何隔離級別讀取這一行。為了防止這樣的事情發生,成員之間必須共享鎖機制。為了確保一致的視圖時間,必須實現一個共享鎖機制。
這種架構的特點是高度復雜,並且要求硬件和軟件的高度集成。必須解決的問題有:鎖機制、系統計時器集成、數據緩沖區共享或非共享以及日志記錄機制。如何實現這些機制對於性能和可用性有很大的影響。如果成員不共享數據緩沖區,那麼每個成員就有可能緩沖相同的數據。如果數據的所有關系可以簡單地在成員之間劃分,那麼您將擁有更好的數據緩沖,但是有可能遇到事務路由問題。如果需要處理一個更新事務,而該事務由不擁有那部分數據的成員接收,那麼需要將它路由到另一個成員。顯然,這種路由會影響性能,您可能被迫通過在應用程序中實現代碼來將事務路由給正確的成員。如果一個成員出故障,那麼可用性可能受到影響,影響的大小取決於其他成員必須做什麼事情才能繼續工作。理想情況下,不需要做任何事情,其他成員可以繼續執行工作,並且可用性不受影響。然而,一些共享設計要求掛起或停止所有事務,並重新初始化緩存和鎖機制。這實際上造成了停機時間,直到這些任務被完成為止。
數據共享環境中的 DB2 for zOS 诠釋了共享架構的理想目標。這個環境的基礎是 z Parallel Sysplex,它提供了 sysplex 計時器和耦合設施(coupling facilitIEs)。耦合設施是高度集成的組件,通過它們可以創建鎖設施和緩沖池等共享資源。此外,成員之間的通信技術是非常高效的。一個成員出故障不會影響其他成員的事務工作負載。除了更好的可用性外,還可以得到更大的容量和更好的工作負載平衡。不需要對應用程序做出更改,就能有效地使用這個解決方案。
用於非 zOS 平台的 DB2 不支持這種類型的架構。
表 2. 共享可用性
優點
缺點
非常高的可用性
高成本
增加可伸縮性
需要專門化硬件
不需要更改應用程序
實現需要專門化技能
多重副本可用性
多重副本設計利用數據庫的多個副本,工作負載分布在這些副本上。當一個副本出現故障時,工作負載繼續在其他數據庫副本上運行。使用一個數據庫的多個副本時要解決的最大問題是,如何保持它們同步,以及如何跨多個副本創建一致的查詢結果。有些類型的復制解決方案是創建和同步這些副本的最簡單方法。但是,由於傳統復制解決方案固有的異步本性,我選擇了在故障轉移小節描述這個場景。
xkoto 中的 Gridscale 提供了另一種多重數據庫副本解決方案,這種解決方案具有高級的同步過程和負載平衡。圖 3 顯示了 Gridscale 解決方案的基本架構。
Gridscale 在數據庫解決方案中充當事務層。它可以根據可用性、系統利用率或同步狀態將事務性工作發送到任何數據庫副本。如果一個副本變得不可用,那麼只需將工作轉移到其他副本。它將根據系統負載將工作負載轉移給其他副本。
寫事務(插入、更新和刪除)被同時發送到所有副本。Gridscale 跟蹤在響應寫事務時被同步的副本。當對寫事務作出響應時,它們才有資格接收之後的讀事務(選擇)。這種機制確保事務性工作總是產生一致的結果。
可以集群化 Gridscale 系統來防止它成為故障點。Gridscale 實現了自己的可在幾種條件下使用的緩存和事務日志記錄。如果一個讀事務被發送到一個出現故障或者在合理時間內未能返回的副本,那麼可以將該事務路由到另一個副本。這個過程對應用程序是完全透明的。如果某種類型的故障或維護使一個副本不可用,那麼可以根據 Gridscale 事務日志對它進行同步,這個過程完成後,它便可以開始參與分布式工作負載。要增加更多的副本以取得更大的可伸縮性,只需從一個副本恢復一個備份,並允許 Gridscale 將新的系統與其他副本同步。
DB2 和 Gridscale 解決方案的實現和管理非常簡單。可以使用 Gridscale 管理工具來創建和同步副本。通過 Gridscale 工具,可以估計整個系統的工作負載,也可以估計每個副本的工作負載。您可以增加新的副本,並將工作從其他副本轉移到新副本,以減輕其他副本的負載。這種靈活性使您可以執行滾動式系統維護。這裡並不要求所有副本具有相同的修復包或發行版級別。您可以使副本下線,執行所需的軟件或硬件維護,然後讓 Gridscale 同步該系統,使之重新變得可用。
Gridscale 還解決了分布式副本遇到的很多其他問題。例如,非確定函數可以在 Gridscale 服務器中實現。在大多數場景中,Gridscale 不要求更改客戶機應用程序。在客戶端,DB2 驅動程序被一個 Gridscale 驅動程序替代,後者具有 Gridscale 特有的附加功能。對於 Java、DB2 CLI 和 .Net 應用程序,都有可用的 Gridscale 驅動程序。應用程序不知道 Gridscale 或事務層。
這種解決方案的總體效果是,不會因為單個或多個系統的故障而造成停機,具有更大的可伸縮性,而且成本更低。能降低成本的原因在於可以使用商用硬件,而不必購買大型的、更強大的機器或更高成本的存儲系統。
圖 2. 多重副本可用性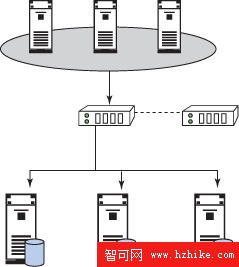
表 3. 多重副本可用性
優點
缺點
非常高的可用性
實現需要附加軟件
增加可伸縮性
附加硬件管理
不需要更改應用程序
適度增加成本
易於實現和管理
故障轉移可用性
故障轉移可用性與持續可用性的不同之處在於,總有那麼一段時間,不管這段時間有多麼短,數據庫引擎不能用於事務處理。這種解決方案的基本要素有:
主系統和輔助系統
故障檢測
數據源移動
兩個系統都有數據庫數據的副本,或者都可以訪問同一個副本,當檢測到故障時,就會進行故障轉移。在故障轉移過程中,數據源從主系統移動到輔助系統。
有兩種類型的故障轉移可用性:同步和異步。同步可用性保證主系統和輔助系統上的數據源是一致的,完整的數據連續性是在故障轉移之後維護的。而異步可用性則不保證主系統和輔助系統是完全同步的。將數據庫從主系統移動到輔助系統的方法因情況而異,但是這個過程總會產生一個時間窗,在這個時間窗內,數據還沒有完成從一個系統到另一個系統的遷移。這裡的數據量可能很小,時間窗可能很短,但是在決定使用何種解決方案時必須考慮這一點。
我們來看看同步或異步故障轉移可用性提供的一些選項。
同步故障轉移可用性有兩種類型:專門化的 HA 軟件和同步復制。
專門化的 HA 軟件
同步方法要求數據庫軟件與專門化的 HA 軟件緊密集成,以產生一個 HA 集群。HA 軟件支持因操作系統平台而異。常見的可用 HA 解決方案有:
Tivoli® System Automation(TSA) - Linux - AIX
Veritas Cluster Server - Windows®, AIX, and Linux
High Availability Cluster Multiprocessing(HACMP - AIX)
Microsoft Cluster Server(MSCS) - Windows
Sun Cluster - Sun
Steeleye Lifekeeper - Linux and Windows
這些是我所列出的平台上最常見的選項。還有其他一些 HA 軟件解決方案可供使用。
所有這些解決方案實際上都是以相同的方式工作。如果出現故障,數據庫服務器可以從一台機器轉移到一個備份系統。為完成這項任務,HA 軟件將所有需要的資源移動到輔助系統上。這些資源包括物理數據庫的磁盤資源、網絡資源和數據庫服務器資源。
在 HA 集群解決方案中,物理數據庫只有一個副本,這個副本存儲在一個共享存儲系統上。在 DB2 環境中,同一時間只有一個系統可以 “擁有” 存儲陣列。當檢測到故障時,存儲的所有關系從主系統轉移到輔助系統。同時網絡資源也發生轉移。最後,數據庫服務器資源在輔助系統上啟動,數據庫變得可用。
故障的檢測是由服務器之間的一個 “heartbeat” 連接來執行的。這個 “heartbeat” 是 HA 軟件的一個功能,它能識別硬件和軟件故障。
由於只有一個數據庫副本,所以它總是同步的。故障轉移和數據庫引擎重啟所需的時間取決於以下幾個因素:
檢測故障所需的時間
移動數據庫資源依賴項(存儲陣列、網絡資源等)所需的時間
DB2 引擎執行崩潰恢復所需的時間
當沒有適當地關數據庫閉時,DB2 會總是執行崩潰恢復。崩潰恢復是對日志文件進行處理,確保所有已提交的事務被寫到磁盤,所有未提交的事務被回滾。執行這項操作所需的時間取決於出現故障時數據庫日志中 “打開的” 工作量。如果需要從日志文件中處理較大的工作負載,那麼整個故障轉移需要數秒或更長的時間。
這種類型的可用性解決方案的一個優點是:不需要對應用程序或客戶機配置目錄進行任何更改。HA 軟件為數據庫連接提供一個虛擬 IP 地址資源。當檢測到故障時,這個 IP 地址將在故障轉移過程中發生轉移,相同的連接語句仍可以被之前使用它的應用程序使用。當發生故障轉移時,所有應用程序被斷開連接,客戶機將一個通信錯誤條件返回給應用程序。一旦數據庫服務器在輔助系統上運行,應用程序只需重新發出連接語句,就能像之前一樣繼續處理工作。自動化客戶機重路由的互補技術將在後面的一個小節中討論。
輔助系統在等待故障轉移時可以執行其他任務。可以將兩個系統配置為相互接管的配置,使兩個服務器都處於活動狀態,分別容納不同的數據庫。每個機器都准備在出現故障時接管其伙伴的工作負載。圖 3 是 HA 軟件解決方案的一個例子。
圖 3. HA 軟件可用性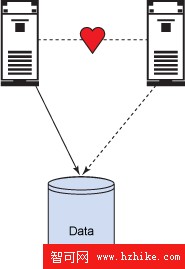
表 3. HA 軟件可用性
優點
缺點
數據庫總是同步
需要額外軟件創建和配置解決方案
不需要更改應用程序或客戶機
需要額外技能來設置和管理 HA 軟件
不需要用戶交互就能檢測和初始化故障轉移
不復制數據,減少了冗余
不會因為 HA 解決方案的設計降低性能
需要能滿足某些 HA 標准的外部存儲
數據庫總是同步
存儲需求會帶來距離限制
同步復制有兩種可用的實現方法:磁盤存儲復制和 DB2 High Availability Disaster Recover(HADR)。
磁盤存儲復制
磁盤存儲復制利用專門的存儲硬件和/或軟件在輔助位置上執行主 DB2 服務器的同步磁盤寫。當在主站點出現故障時,數據庫資源在輔助位置上啟動。輔助硬件/軟件必須在兩個位置上都執行同步磁盤塊寫,否則輔助位置可能與主位置不同步。圖 4 演示了利用 IBM Peer to Peer Remote Copy(PPRC)的這種設計的一個例子。由於所有數據存儲寫必須在兩個位置上同步地執行,這種解決方案的設計必須考慮主站點與輔助站點之間所需的 IO 帶寬。
圖 4. 磁盤存儲復制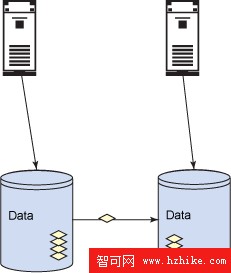
表 4. 磁盤存儲復制
優點
缺點
數據庫總是同步
需要滿足解決方案標准的外部存儲
不需要更改應用程序或客戶機
存儲復制需求會帶來距離限制
輔助系統不能用於數據庫工作負載
所有寫活動必須在輔助站點上以正確的順序回放
DB2 HADR 和 DB2 HA 特性
DB2 High Availability Disaster Recovery(HADR)是基於 DB2 日志記錄機制的一種高性能數據庫復制系統。一個 DB2 HADR 場景由兩個 DB2 系統組成,一個是主系統,一個是備用系統。主系統執行所有事務性工作,並將任何數據庫更改復制到備用系統。當出現故障時,通過一個命令將備用系統的角色切換為主系統的角色。
HADR 提供所有被日志記錄的 DB2 操作的同步復制。要使兩個 DB2 系統參與 DB2 HADR 對的基本要求是,它們具有 TCP/IP 連接。HADR 的設置和管理非常簡單,DB2 提供向導幫助完成這些任務。
HADR 復制數據的基本方法是將 DB2 日志寫同時發送到本地磁盤和備用系統。備用系統收到日志寫後,將確認通知發送到主系統。當從備用系統收到本地寫 IO 和接收確認通知後,主系統可以考慮提交的事務。客戶機或應用程序並不知道這項操作。必須在兩個系統之間發送的數據量只受到日志記錄的操作的限制。數據存儲頁的實際更改是在兩個系統上獨立地執行的 —— 這樣大大減少了實際所需的帶寬。
運行 HADR 的開銷非常小。默認的復制方法(也有其他可用的方法)只要求在將確認通知返回給主系統之前,備用系統的內存中收到一個日志寫。通常,執行本地寫 IO 的同步操作大於通過 TCP/IP 傳輸到備用系統的數據量。由於只需復制被更改的數據,所以讀事務不受 HADR 實現的影響。在這些環境中,運行 HADR 時受到的影響很小。當執行大量的被日志記錄的事務時,HADR 受到的影響由系統之間的網絡帶寬和延遲決定。如果網絡帶寬大於期望的日志記錄活動,性能應該不會受到明顯的影響。
如果這對系統之間的連接丟失,那麼可以設置一個超時值,以便自動關閉 HADR。HADR 關閉後,主系統可以繼續正常地處理事務。等到連接恢復時,就可以重新打開 HADR,而備用系統將與主系統通信,並執行 “catch-up” 操作,直到它返回到同步狀態。圖 5 演示了同步主系統和備用系統的 HADR 過程。
圖 5. HADR 過程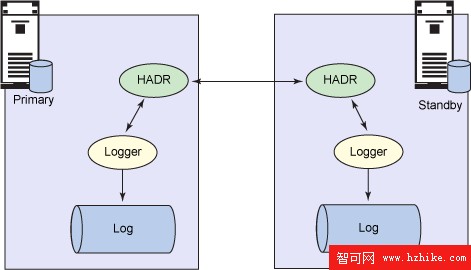
HADR 的故障轉移操作可以通過 HA 軟件實現自動化。DB2 9.5 for AIX and Linux 包括了 DB2 High Availability(HA)特性。
DB2 HA 特性是通過高度集成 TSA 和 DB2 集群管理器應用程序編程接口(API)來實現的。當在 AIX 或 Linux 上安裝 DB2 時,可以選擇安裝這個特性,這樣就會自動安裝 TSA。TSA 和 DB2 的配置是通過 DB2 High Availability Configuration Utility(db2haicu)實現的,db2haicu 大大簡化了 HA 集群的配置。HA 特性的另一個非常重要的優點是,它實現了集群管理器 API。集群管理器 API 使 DB2 可以感知集群。由於能感知集群,將會自動處理影響到 HA 集群的 DB2 系統更改。一個例子就是停止 DB2 引擎。DB2 會讓 HA 集群知道管理員停止了引擎,不需要因為停止事件而采取行動來重新啟動或傳輸資源。
DB2 HADR 還允許執行滾動升級,從而增加了可用性。只要主系統和備用系統保持同步狀態,它們之間的角色可以隨意切換。當需要執行某種類型的系統維護任務、升級或安裝 DB2 修復包時,可以關閉 HADR。在備用系統上執行維護時,主系統繼續正常運行。一旦維護任務完成,便可以打開 HADR,系統自動重新同步,必要時可以切換角色,以便在原先的主系統上執行維護。
表 5. HADR
優點
缺點
數據庫總是同步
附加的服務器和存儲需求
不需要更改應用程序或客戶機
備用系統不能同時用於數據庫工作負載
易於安裝和維護
不復制無日志記錄的操作
對於 AIX 和 Linux,自動化故障轉移是 “開箱即用” 的
對性能的影響非常小
可執行滾動升級
DB2 復制
DB2 復制可分為兩種風格,傳統的復制和基於隊列的復制。這兩種復制在本質上是類似的,但用於產生每個解決方案的復制方法有所不同,並且各有優點。
復制是一個異步的過程,不能保證故障轉移期間兩個副本之間所有數據都是一致的。復制是高度可配置的,但必須是將數據庫表的更改從一個位置復制到另一個位置。復制這種可配置的特性為我們提供了很多選項,包括選擇只復制一部分表和/或數據庫范圍、復制期間進行數據轉換以及有多個復制目的地。只要有足夠的網絡帶寬滿足客戶需要,距離不是問題。
復制還允許系統在不同的 OS 平台或不同的數據庫管理系統上。復制的源和目標是 “活動的”,所以工作可以在每個系統上同時完成。例如,可以用一個系統來處理事務,而用另一個系統創建報告或運行備份。復制只限於用戶定義的表。系統目錄的更改不能復制。例如,對表權限的更改必須在所有系統上執行,因為這種更改是不能復制的。
DB2 傳統復制,也稱 SQL 復制,是一個集成的 DB2 特性。它由兩部分組成:捕獲和應用。復制管理員指定作為復制源的表,然後在目標數據庫(即輔助系統)上使用前一步中的復制源作為源創建復制子描述。一個捕獲進程監視事務日志,以發現對復制源表的任何更改,並將對這些表的更改放入到 staging 表中。一個應用(apply)程序則每隔一段時間讀取 staging 表,並將更改移動到子描述目標上。
運行傳統復制會導致一些開銷。額外工作的量取決於源表上的插入、更新和刪除活動的量。基表上不需要額外的鎖,因為復制只分析日志文件,而不是分析基表。但是填充 staging 表(更改表)和在日志中記錄這些事務則需要數據庫資源。圖 6 表示了傳統復制場景的基礎。
圖 6. 傳統復制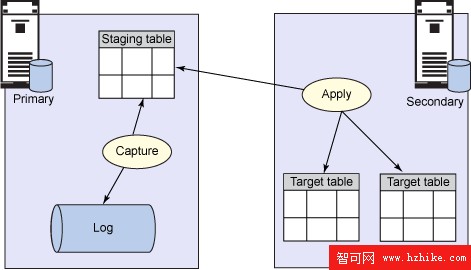
DB2 隊列復制類似於傳統復制;但是,這種復制沒有使用 staging 表。相反,更改被直接放在消息隊列中。這些隊列由 Websphere® Replication Server 提供,可以在一個單獨的服務器上創建隊列,也可以在主數據庫服務器或輔助數據庫服務器上創建隊列。隊列為將更改傳送到目標提供了一個快速的、有保證的傳送機制。DB2 隊列復制沒有傳統復制的那些開銷,並且提供更大的吞吐率,此外,隊列的實現也增加了冗余。
圖 7. 隊列復制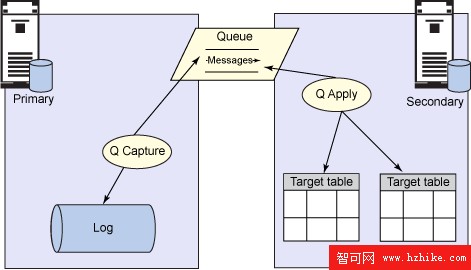
表 6. 復制
優點
缺點
極度靈活
固有的異步性
多個活動副本
附加的性能開銷(傳統復制)
沒有距離限制
附加設置和管理
不是所有的數據庫更改都被復制
自動客戶機重路由
當數據庫服務器上發生故障時,將停止客戶機連接。自動客戶機重路由(Automatic clIEnt reroute,ACR)使 DB2 客戶機可以自動重新連接到原始的或備用的服務器上,從而減少客戶機停機時間。用於 ACR 的備用服務器信息是在數據庫服務器上指定的一個參數。在客戶機第一次連接到數據庫服務器並從服務器端參數中提取信息之後,備用服務器信息被緩存在客戶機上。當檢測到通信錯誤時,ACR 輪流嘗試到原始服務器和備用服務器的連接。ACR 不會重放正在運行的事務,建立客戶機連接後,所有未提交的工作必須重新執行。ACR 為使用 ACR 的所有應用程序生成一條警告消息,以允許應用程序采取其他必要的行動。圖 8 顯示了在包含多個客戶機和應用服務器的環境下工作的 ACR。
圖 8. ACR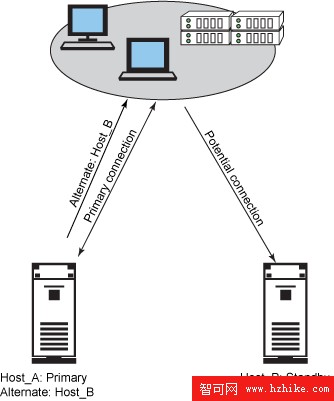
有些產品,例如 WebSphere 中間件,是 ACR 感知的(ACR-aware)。這進一步降低了復雜性,並提高了應用程序的可用性。
結束語
有很多選項可用於創建運行良好、高度可用的 DB2 解決方案。本文為您選擇最適合自己的環境的解決方案提供了指南。
-