概述
就算是配置最仔細的系統也終究會發現它仍然需要一定的性能調優,並且這時我們已經搜集了的運行監控數據,將來非常便於搜集。
保持一種系統的方法來調優和進行故障診斷對我們非常重要。當發生了一個問題,為了解決這個問題,很容易隨意的進行調整。然而,當我們這麼做了,事實上定位到問題的可能性非常低,甚至讓問題更糟糕。性能調優的一些基本原則:
有備而來,去了解系統一切正常的情況下性能怎麼樣。搜集運行監視信息來跟蹤一段時間內系統行為的變化。
了解整個場景,不要局限於你從 DB2 上看到的 – 也要搜集並分析來自於操作系統、存儲、應用程序甚至來自用戶的數據。了解系統本身將有助於你解釋監控數據。
只調整能解釋你看到的症狀的參數,如果連發動機都無法啟動就不要更換輪胎。不要試圖通過降低 CPU 來解決磁盤的瓶頸。
一次只改一個參數,在更改其它參數之前先觀察效果。
你可能遇到的問題類型
性能問題往往分為兩大類:影響了整個系統的問題和只影響了部分系統的問題。比如某一特定應用或 SQL 語句,在研究的過程中-種類型的問題可能轉化為另外一種類型的問題,或者相反。例如造成整個系統性能降低可能是一個單獨的語句,或者是整個系統的問題只是在一個特定的區域被發現。
下面我們從整個系統的問題開始。
我們發現的所有導致性能降低的原因的方法就是從高層入手並逐漸提煉我們的診斷。這個“判斷樹”策略可以幫助我們盡可能早的排除那些不能解釋我們所看到症狀的因素,適用於整個系統或者更加局部的問題。我們將把瓶頸分成下面 4 種普通類型:
磁盤
CPU
內存
‘懶惰系統’
在開始一個對 DB2 調查之前,首先考慮一些准備問題常常是有幫助的,比如:
是否有性能降低,與什麼相關?我們的‘基准’是什麼?
一個系統的性能看起來在隨時間流逝下降了?與一個不同的系統或不同的應用比較下降了?這個問題可以對性能降低的原因展開不同的可能性。數據量增加了?所有的硬件都運行正常嗎?
性能下降是什麼時候發生的?在另一個任務運行之前、之中、之後,性能下降或許周會期性的發生。甚至如果這個任務沒有直接和數據庫相關,它也可能由於消耗網絡或者 CPU 資源影響數據庫性能。
性能下降的前後關系有什麼變化嗎?通常是,添加了新硬件、或應用程序被更改了、大量數據被加載、或者更多的用戶訪問這個系統。
在據庫專家和應用程序以及架構方面的專家一起工作的情況下,這些問題通常是一個綜合分析方法一個很重要的部分。 DB2 服務器幾乎總是硬件、其它中間件、和應用程序這樣一個復雜環境的一部分,所以解決問題可能需要有多領域的技能。
磁盤瓶頸
System Bottleneck > Disk Bottleneck?
磁盤瓶頸的基本症狀是:
在 vmstat 或 iOStat 結果中出現較高的 I/O 等待時間。這顯示系統會花費一小段時間等待磁盤 I/O 完成請求。等待時間達到 20% 或 25% 是很少見的。如果 CPU 時間非常低,那麼高 I/O 等待時間是一個很好的預示了瓶頸所在。
從 iOStat 或 perfmon 顯示磁盤高達 80% 的繁忙程度。
從 vmstat 輸出中看到較低的 CPU 利用率(25%-50%)
可能最終我們可能需要添加磁盤,但現在我們將檢查我們是否能通過調優 DB2 系統消除這個瓶頸。
如果存在一個磁盤瓶頸,系統管理員可以幫忙映射一個繁忙設備鏡像的文件系統路徑。從這裡你可以決定 DB2 如何使用這些受到影響的路徑 :
瓶頸是表空間容器?這取決於在 sysibmadm.snapcontainer 中查詢 TBSP_NAME,TBSP_ID 和 CONTAINER_NAME 的結果,查看造成瓶頸的路徑是否在 CONTAINER_NAME 結果中。
瓶頸是事務日志路徑?這取決於檢查數據庫配置參數的結果,查看造成瓶頸的路徑是否是“日志文件路徑”。
作為診斷日志路徑?這取決於檢查數據庫管理配置參數的結果,查看造成瓶頸的路徑是否是 DIAG_PATH 。
我們將分別考慮這幾種情況。
System Bottleneck > Container Disk Bottleneck > Hot Data Container > Hot Table?
為了判斷是什麼導致容器成為瓶頸的,我們需要判斷都有哪些表存儲在這那個表空間而且最活躍。
要判斷什麼表在這個表空間,需要查詢 syscat.tables,把 TBSPACEID 同上面的 snapcontainer.TBSP_ID 匹配
要找出哪些表最活躍,需要查詢 sysibmadm.snaptab,選擇在我們繁忙的容器上的表的 ROW_READ 和 ROW_WRITTEN 。查看那些水平活躍程度比其它要高很多的表。注意這需要打開實例級表監控開關 DFT_MON_TABLE
System Bottleneck > Container Disk Bottleneck > Hot Data Container > Hot Table > Dynamic SQL stmt?
進一步向下鑽取,我們需要找出什麼造成了這個表的高水平的活躍程度。是動態 SQL 語句造成的高度活躍?通過 sysibmadm.snapdyn_sql.TBSP_ID 查詢動態 SQL 快照,來找出我們感興趣的那些涉及這個表的語句:
select … from sysibmadm.snapdyn_sql where translate(cast(substr(stmt_text,1,32672)
as varchar(32672))) like ‘ %<tbname>% ’
order by …
列返回能包含行的讀和寫,緩沖池活躍程度,執行時間,CPU 時間,等等。我們能在列上使用 ORDER BY 子句,比如 ROWS_READ,ROWS_WRITTEN 和 NUM_EXECUTIONS 來集中那些對表有最大影響的語句。注意我們假設這裡的表名在 SQL 語句的頭 32672 個字符中。這個假設雖然不完美,卻在大多數情況下正確,也是需要使用 LIKE 。
select … from sysibmadm.snapdyn_sql where translate(cast(substr(stmt_text,1,32672)
as varchar(32672))) like ‘ %<tbname>% ’ order by …
System Bottleneck > Container Disk Bottleneck > Hot Data Container > Hot Table > Static SQL stmt?
是否是靜態 SQL 語句導致的高活躍程度?在這裡我們需要使用系統編目表和 db2pd 來找出哪寫語句最活躍。查詢 syscat.statements, 參考那些我們關注的表:
select PKGSCHEMA, PKGNAME, SECTNO, substr(TEXT,1,80)
from syscat.statements where translate(cast(substr(text,1,32672)
as varchar(32672))) like ‘ %<tbname>% ’
一旦我們有了涉及到我們感興趣的那些表的靜態 SQL 語句的包名和片段數字,我們就可以使用 db2pd – static 來找出它們中哪些是高度活躍的。 Db2pd – static 的輸出都有一條從實例啟動並執行過的每一個靜態 SQL 語句的記錄。 NumRef 計數器這條語句已經運行了多少次,並且 RefCount 計數器顯示了當前有多少 DB2 代理程序正在運行這條語句。監視 db2pd – static 結果中的每一條調用記錄。 NumRef 值的迅速攀升、 RefCount 的值經常超過 2 或 3,往往表明這是一個高度活躍的語句:
select PKGSCHEMA, PKGNAME, SECTNO, substr(TEXT,1,80)
from syscat.statements where translate(cast(substr(text,1,32672)
as varchar(32672))) like ‘ %<tbname>% ’
System Bottleneck > Container Disk Bottleneck > Hot Data Container > Hot Table > Hot SQL statement
如果我們能確定並得出一個或多個 SQL 語句導致了 I/O 瓶頸,下一步我們需要確這個語句是否可以被優化以降低 I/O 。這個語句是否發起了一個不期望的表掃描?這可以通過用 db2exfmt 檢查查詢計劃以及比較這個問題語句的 ROWS_READ 和 ROW_SELECTED 來驗證。由於在表掃描中使用了過時的統計信息或有索引問題,經常在臨時查詢的時候不可避免會發生表掃描,但是一個導致過多 I/O 並造成瓶頸的重復查詢還是應該被討論的。另一方面,如果受到的影響的表非常小,那麼增加緩沖池大小對減少 I/O 和消除瓶頸或許已經足夠了。詳情參考這裡對於查詢優化和物理設計的最佳實踐文章。
在我們討論索引容器之前,先介紹兩個數據容器磁盤瓶頸的情況:
我們希望一個產生大量磁盤讀取的表掃描通過預取器完成。如果在預取過程中有任何問題(見下面的懶惰系統),讀入緩沖池操作都將被代理程序自己完成,並且-每次只讀取一頁。在這種情況下,會產生導產生大量閒置的“懶惰系統”,或(如我們在此討論的)磁盤瓶頸。因此如果有磁盤瓶頸是由於表掃描造成的,但是在 iOStat 中卻顯示的讀入大小比那個表空間的預取大小要小很多的話,可能是預取不足導致的問題。
通常,為了保證表空間後續讀取時候有足夠的可用緩沖池頁面,頁清理會對這個表空間產生一個穩定的寫出流。然而如果在調整頁清除有問題(見懶惰系統的瓶頸),代理程序將停下來自己做清理。這常常會產生頁面清理的‘爆發’ - 周期性的高度活躍的寫入(可能造成磁盤瓶頸),並與良好性能交替出現。
在後面懶惰系統的瓶頸章節,有更多關於如何診斷和解決這兩個問題信息。
System Bottleneck > Container Disk Bottleneck > Hot Index Container > Hot Index?
一個發生在容器中的瓶頸,更多的可能是表活躍而不是索引活躍,但是一旦我們排除了表活躍的原因,我們就應該調查是否是索引活躍造成的問題。應為我們沒有索引快照可以一用,就不得不通過間接的發現問題。
在表空間中索引讀寫是否很活躍?對表空間查詢 sysibmadm.snaptbsp 的 TBSP_ID 對應上面 snapcontainer 的 TBSP_ID. select dbpartitionnum, tbsp_id, tbsp_name,
pool_index_p_reads, pool_index_writes from
sysibmadm.snaptbsp T
where T.tbsp_id =
<tablespace ID of hot container>
一個很大並不斷增長的 POOL_INDEX_P_READS 或 POOL_INDEX_WRITES 值表明這個表空間有一個或多個‘忙碌的索引’。
這個表空間中有什麼索引?
查詢 syscat.tables 和上面的 snapcontainer.TBSP_NAME 匹配 INDEX_TBSPACE 。
select t.tabname, i.indname
from syscat.tables t, syscat.indexes i
where t.tabname = i.tabname and
coalesce(t.index_tbspace, t.tbspace) =
<name of table space with hot container>
這其中哪些索引是高度活躍的?如果在我們檢查的表空間上有不止一個索引,我們就需要查看索引層面的活躍程度。反復搜集 db2pd – tcbstats index – db <dbname> 。在‘ TCB index Stats ’部分列出了所有活動的索引,以及每一個的統計信息。‘ Scans ’列顯示了在每個索引上已經執行了多少次索引掃描。在繁忙的表空間使用索引列表來查看一個索引上的掃描總數,雖然增長非常迅速 KeyUpdates 或 InclUpdats(包括列值的更新)卻很穩定。
System Bottleneck > Container Disk Bottleneck > Hot Index Container > Hot Index > Buffer pool too small?
索引掃描通常很劃算,所以基於這一點研究是否能在緩沖池中放入更多的索引而非直接從硬盤讀取是很合理的。增加緩沖池的大小,或為索引指定專門的緩沖池,可能足以降低 I/O 來消除平均。注意,在數據倉庫環境中的索引通常非常大,分配足夠的緩沖池來消除 I/O 不大可能。在那種情況下,通過增加額外的容器以提高磁盤 I/O 帶寬來消除瓶頸或許更加有效。
System Bottleneck > Container Disk Bottleneck > Hot Index Container > Hot Index > Hot SQL Statement?
在我們找到了一個‘ hot table ’後,如果我們不能通過調優消除索引 I/O 瓶頸,或許我們需要更進一步的向下鑽取,以找到導致索引 I/O 的 SQL 語句。不幸的是,我們並不能再一次像之前我們所做的那樣只挖掘 SQL 語句文本,至少 I/O 瓶頸和具體的索引沒有直接連系。
利用索引名稱確定相應的表,然後用表名和上面描述的方法從活躍的表上找到可能使用這些索引的動態或靜態的 SQL 語句。(這並不保證和表相關就一定會被使用。)那麼我們需要使用 db2exfmt 來確定是否這些語句使用了索引。
System Bottleneck > Container Disk Bottleneck > Hot Temporary Table Space Container
從另一方面,如果這個繁忙的容器屬於一個臨時表空間,那麼我們就需要考慮兩個可能的原因。
是否這個臨時表空間的 I/O 繁忙是由於排序溢出?這是一種情況,排序從設計的內存緩沖溢出必須使用一個臨時表空間來代替。如果排序時間和溢出快照監控元素很高而且不斷增長,或許這就是原因。 select dbpartitionnum, total_sorts,
total_sort_time, sort_overflows
from sysibmadm.snapdb
STMM 會盡全力避免這種情況;然而如果你沒有使用 STMM 來控制 sheapthres_shr 和 sortheap,你可能需要手動來增加這些值。
是 I/O 由於龐大的中間結果導致的嗎?如果是,這表明通過大量的臨時數據的物理讀寫。我們應該在最初的時候就在表空間級的快照信息中檢查這些,如果有臨時數據 I/O 高的證據,那麼我們就能從動態 SQL 語句的快照或者靜態 SQL 事件監控數據中向下鑽取。查找造成臨時緩沖池中活躍的某個語句。 select dbpartitionnum, tbsp_name,
pool_temp_data_p_reads, pool_data_writes
from sysibmadm.snaptbsp
where tbsp_id = <tablespace ID of hot container>
System Bottleneck > Container Disk Bottleneck > Poor Configuration?
假設現在我們已經確定了一個發生以上類型瓶頸的容器 - 但是有時卻會出現這種能情況,我們看不到任何明顯的原因。沒有繁忙的表,沒有繁忙的索引,沒有繁忙的 SQL 語句。可以調查幾種可能的原因。
在這個表空間中有太多‘ fairly active ’的表或索引嗎?雖然它們中沒有一個能自己活躍到足以導致瓶頸的程度,它們聚集起來仍有可能相對於底層磁盤太過活躍了。一個解決方法是把這些表和索引分布到不同的表空間。另外一個可能性是向這個表空間添加更多的容器(提供的這些容器位於不同於現有容器所在的磁盤上,因此 I/O 能力得到了提升。)
太多的表空間共享了同樣的磁盤嗎?這一不小心就可能發生,表面上表空間占用了不同的邏輯卷,但是最終在最底層還是使用的同樣的磁盤。像上面提到的,整體活躍 - 這個時候越過表,表空間或許要承擔全部責任。合理的反反應是把一些表空間挪到別的磁盤上。
如果在這點上我們沒有找到發生容器磁盤瓶頸具體的原因,至少我們已經排除了大多數‘可調整問題’,而且應該考慮增加而外的磁盤吞吐能力來提高這個‘問題’表空的性能。
System Bottleneck > Log Disk Bottleneck?
雖然容器磁盤瓶頸很普遍,日志磁盤瓶頸卻能對系統更大的影響。這是因為日志速度降低能影響系統中所有的 INSERT/UPDATE/DELETE 語句,不僅是某些表或索引。像其它類型的磁盤瓶頸最主要的症狀就是 iOStat/perfmon(90% 或者更高)。日志瓶頸也會造成事件監控器中的更長的提交時間,在應用程序快照中更多的代理程序處於‘ commit active ’狀態。
如在這個章節提到過的對於日志配置,強烈建議在數據運行中,日志不和任何‘ active ’對像共享磁盤,比如容器,等等 。這是在發生日志瓶頸的時候需要首先反復確認的事情之一。
如果日志有它自己的磁盤,那麼我們需要了解瓶頸的性質。
如果 iOStat 顯示日志設備每秒執行 80-100 個操作,並且平均的 I/O 大小是 4k 字節,這表明日志飽和更多的發生在 I/O 操作上而非完全是數據量導致的。
這種情況有兩種可能。
首先,系統中的一些應用程序可能提交得過於頻繁 - 或比需要的要頻繁。高提交率的應用程序可以通過應用程序快照來確定(比較 select/insert/update/delete 語句提交率,並查看每分鐘提交的數目)。在極端情況下(例如,自動提交開啟,並且 SQL 語句都很短),是可能造成日志設備飽和的。在應用程序中減少提交頻率對於減少日志瓶頸有直接的好處。
造成頻繁日志寫的另外一種可能是日志緩沖區太小。當日志緩沖滿了,DB2 必須把它寫入磁盤,而不管其是否提交。對於日志緩沖被迅速填滿的情況(如 sysibmadm.snapdb 的監視元素 num_log_buffer_full 所報告的)很可能導致這個問題。
System Bottleneck > Log Disk Bottleneck > Large Number of Log Writes
過多的數據寫入同樣可以造成日志瓶頸。如果隨著設備利用率越來越高,iOStat 也會顯示寫入日志設備的數據超過 4k 字節很多,這表明比起高事務率,數據量對產生這個問題負有更多的責任。
或許根據你的具體環境可以降低記日志記錄數據的量 :
當 DB2 更新表中的一行的時候,它會記錄從第一個被更改的列到最後個被更改的列之間的所有列 - 包括那些沒有被更改的列。在定義表的時候,將那些經常修改的列放在一起能減少更新時日志記錄的量。
大對像(CLOB,BLOB,DBCLOB)列默認是要記日志的,但是如過這些數據可以從數據庫之外恢復,從減少 INSERT/UPDATE/DELETE 操作的時候日志記錄的數據量,它們可以適當的標記為NOT LOGDED 。
如果大量日志數據跟大批 SQL 操作(比如,有子查詢的 INSERT,有時用於數據維護和數據裝載過程)有關,目標表或許能設置為 NOT LOGGED INITIALLY(NLI)。這會在當前工作單元不記日志。需要顧及到對 NLI 表的可恢復過程;然而,如果適合你的系統,NLI 可以非常明顯的降低日志數據量和相應的提高性能。當然,如果這批操作是直接 INSERT,可以用 load 使用工具替代,它也能同樣地避免記錄日志。
System Bottleneck > Log Disk Bottleneck > High Volume of Data Logged
無論哪種情況 - 不管是日志的高寫入頻率還是數據寫入量高造成的日志瓶頸 - 要消除問題的原因往往是不可能或者不切實際的。一旦我們確認日志配置遵循了上面描述的最佳實踐,或許就需要通過提高日志系統的能力來解決問題。要麼通過添加額外的磁盤到日志 RAID 隊列中,要麼提供一個專門的或者升級了的磁盤緩沖控制器。
System Bottleneck > Diagnostic PathBottleneck?
DB2 診斷日志路徑― db2diag.log 存放的地方 - 繁重的磁盤寫入能造成整個系統的性能下降,這很難分離,因為普通的 DB2 監控元素並不跟蹤它。在多分區環境中所有分區都寫入同樣的診斷日志路徑,它一般是通過網絡共享 NFS 文件系統。類似於分區間同步,從許多分區對 db2diag.log 的並發寫入可能會導致很高的網絡通訊和 I/O 負載,並因此降低系統性能。正如在前面配置章節提到的,解決這個問題最簡單的辦法就是為每個分區指定一個單獨的診斷日志路徑(並指定一個專門的診斷日志文件)。
設置 DB2 的 diaglevel 數據管理配置參數為 4 會增加診斷信息的數據量,這會導致明顯的性能影響 - 尤其在一個大型的多分區(DPF)環境。性能急劇下降甚至可能造成 DIAGPATH 文件系統滿並最終使系統停止。為了避免這種情況,你應該確認診斷日志文件系統有足夠的可用空間,通過歸檔診斷信息或者分配一個專門的文件系統給 DB2 存放診斷信息。
圖 1. 磁盤瓶頸 - 總圖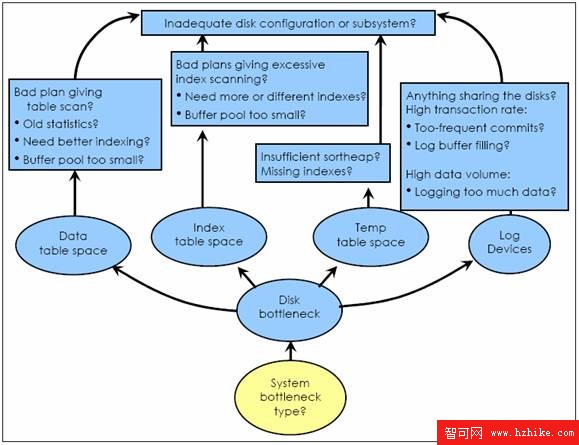
圖片看不清楚?請點擊這裡查看原圖(大圖)。
CPU 瓶頸
System Bottleneck > CPU Bottleneck?
CPU 瓶頸表現在兩個方面:
所有 CPU 都飽和 - 意味著這個系統上的所有處理器都繁忙。根據 vmstat 和 perfmon 的報告,一般的標准是計算用戶 CPU 時間和系統 CPU 時間。 CPU 利用率超過 95% 就被認為是飽和的
單個 CPU 飽和 - 意味著系統上的在一個處理器上的負載達到了飽和,但是其它處理器卻部分或完全空閒。這通常發生在系統中只有一個很忙的應用程序在運行。雖然還有可用的 CPU 能力,系統卻無法消費,因此,應用程序或語句的速度取決於這一個處理器內核的繁忙程度。
同樣我們也應該考慮到用戶模式和系統模式上不同的 CPU 消耗。一種是處理器正在運行操作系統內核以外的軟件比如 DB2 應用程序或者中間件,導致用戶 CPU 時間增多。一種是在運行操作系統內核的時候系統內存增多。這兩個在數量上是分開顯示的,並且根據它們之間的分布情況,可以幫助我們找到 CPU 瓶頸的原因。用戶和系統 CPU 時間比率在 3:1 到 4:1 之間是正常的。如果在有瓶頸的系統中,用戶和系統時間比率高於這個區間,我們應該收件調查用戶 CPU 時間增加的原因。
System Bottleneck > CPU Bottleneck > User CPU Bottleneck
在 DB2 服務器上造成用戶 CPU 瓶頸的許多原因可以通過抓取快照和語句事件監控器來診斷。我們可以使用應用程序快照或查詢 sysibmadm.snapappl 管理視圖來向下鑽取,以找出是什麼用戶消耗了大多數 CPU 時間:
select appl.dbpartitionnum, appl_name,
agent_usr_cpu_time_s + agent_usr_cpu_time_ms / 1000000.0 as user_cpu
from sysibmadm.snapappl appl,
sysibmadm.snapappl_info appl_info
where appl.agent_id = appl_info.agent_id and
appl.dbpartitionnum = appl_info.dbpartitionnum order by user_cpu desc
同樣(並且更又有用),通過動態語句快照,或查詢 sysibmadm.snapdyn_sql 管理視圖,我們也能確定什麼 SQL 語句正在使用絕大多數 CPU 時間:
select substr(stmt_text,1,200),
total_usr_cpu_time +
total_usr_cpu_time_ms / 1000000.0 as user_cpu
from sysibmadm.snapdyn_sql
order by user_cpu desc
通常情況下,我們查找一個或多個語句,它們消耗‘比它們平均份額更多’的 CPU 。這轉化並增加 TOTAL_USR_CPU_TIME 和 TOTAL_USR_CPU_TIME_MS 的值
同時,我們應該考慮靜態 SQL 語句。如上面所提到的,快照監控器並沒有包含這類信息。所以我們需要使用語句事件監控器,或者 WLM 活動事件監控器,來收集它們的 CPU 使用信息。有一些推薦的步驟可以用來把語句事件監控器的開銷減少到最小:
事件監控器的默認 BUFFERSIZE 是 4 頁,這需要增加到 512 頁以獲得更好的性能。
在一個單獨的表空間創建語句事件監控表。這避免了事件監控數據和其它表的 I/O 沖突。這樣也讓我們有機會選擇更大的表空間,這樣能最小化 SQL 語句被截斷。
在 CREATE EVENT MONITOR 命令的時候使用 TRUNC 選項。和存入另外的大對像列相比,這會強制把 SQL 語句文本保存在同一行,如花費的時間,CPU 時間等等…注意這可能會導致在事件監控結果中 SQL 語句被截斷。根據語句事件監控表的頁大小(比如,一個 4K 頁能存 3500 字節),一部分 SQL 語句可以以這種方式存儲。
使用 WHERE 子句把監視范圍集中在一部分連接或應用程序上。雖然監視連接會有額外的開銷,但是使用 WHERE 子句將減少事件監控導致的總的系統開銷。
把所有這些放在一起,並且從 LIST APPLICATIONS 得到我們關注的連接對應的應用程序 ID,我們將得到跟下面一樣的結果:
create event monitor stmt_evt for statements
where appl_id = '*LOCAL.DB2.075D83033106'
write to table
connheader(table stmt_evt_ch, in tbs_evmon),
stmt(table stmt_evt_stmt, in tbs_evmon, trunc),
control(table stmt_evt_ctrl, in tbs_evmon)
buffersize 512
對 WLM 活動監視器也有類似的原則。一個大的 BUFFERSIZE,單獨的表空間和 TRUNC 選項都是減少開銷的好思路。 WLM 活動監視器不支持 WHERE 子句,不過在活動監視器被定義的時候,在工作量或者服務類型裡已經隱含了一個范圍。和 WHERE 子句相同,這也能非常有效的降低性能開銷和收集的數據量。注意如果在活動監視器使用了 WITHOUT DETAILS 字句 , 將提供我們所需要的 CPU 消耗的基本信息。提高到 WITH DETAILS 或者 WITH DETAILS AND VALUES 會提供其它的有用信息,但是如果監視開銷堆你的環境是一個問題,那最好還是從 WITHOUT DETAILS 開始,然後在需要的情況下啟用 DETAILS 或 VALUES 。
System Bottleneck > CPU Bottleneck > User CPU Bottleneck > High CPU SQL
我們並不總是能夠減少一個 SQL 語句請求的 CPU 量,但是在某些情況下我們可以影響它。
一個頻繁運行的對緩沖池中的表掃描能消耗令人吃驚的 CPU 時間。這可以發生在一個很小的表上,它沒有合適的索引而它卻會在一個連接中被查詢到。我們能看到的症狀包括
(i)相關地語句運行很短地時間
(ii)用戶 CPU 消耗大致等於執行時間
(iii)在查詢計劃中又一個關系查詢
(iv)db2pd – tcbstats 中查詢數目不在增加
(v)對於這個語句只發生非常少地物理讀。
雖然這類語句不屬於我們通常考慮的瓶頸,頻繁執行和 CPU 的高消耗卻能讓它成為問題。通常我們的響應是創建一個索引給優化器在表查詢的時候多一個選項。一個正確的索引定義可以在查詢計劃中明顯的被看到,如果沒有,在這裡設計顧問程序可以提供協助。
如果應用程序執行一個 SQL 語句卻只會用到一小部分產生的數據,使用 OPTIMIZE FOR n ROWS(OFnR)和 FETCH FIRST n ROWS ONLY(FFnRO)子句能幫助減少所有類型的資源消耗,也包括 CPU 。詳細說來,比起優化返回結果集中所有的行給應用程序,OFnR 和 FFnRO 能幫助優化 SQL 查詢計劃來返回結果集的初始行更加有效。如果只用了 OFnR,n 可以在運行時被超過;然而 FFnRO 將阻止超過 n 的行數被返回,即使應用程序也嘗試這麼做。
正如之前配置章節我們提到的,使用了文化正確性校驗序列的 Unicode 代碼頁會產生大量的開銷,尤其在 CPU 消耗上。因為開銷的總量和 SQL 語句產生的字符串數據比較量直接相關(在謂詞中,或者在 ORDER BY 子句引起的排序,等等),如果我們能減少一個語句產生的數據比較量,我們將減少 CPU 消耗。這常常能通過鼓勵在預先評估和結果集排序時都使用索引來實現。設計顧問程序會設計正確的索引來將表掃描和排序減到最少。
鎖的問題通常只存在於沖突和等待時間這兩個方面。然而就算有很少或者根本沒有沖突,獲取和釋放鎖的過程也會消耗大量的 CPU 時間。考慮一個要檢查表裡很多行的應用程序或語句,由於只有它自己在運行就只產生了少量的鎖沖突,因為對它涉及的表的訪問是排他訪問,或是因為所有並發的應用程序都使用的是只讀模式。在這樣的情況下為了降低 CPU,可以使用表級別的鎖定來達到被要求的隔離級別
如果沒有 SQL 語句看起來消耗了大量的 CPU,也有很多潛在問題會導致整體 CPU 消耗增加。
System Bottleneck > CPU Bottleneck > User CPU Bottleneck > Dynamic SQL without Parameter Markers?
比起使和用參數標記,許多應用程序通過連接語句片段和字符串值來構建它們的 SQL 語句。(注意,使用分發統計信息的復雜的 SQL 語句、以及嵌入的文字信息可以幫助 SQL 優化器選擇一個更好的查詢計劃。作為替代,我們專注於嵌入文字信息沒有任何好處的輕量級語句) String procNameVariable = "foo";
String query =
"SELECT language FROM "
+ "syscat.procedures "
+ "WHERE procname ="
+ " ‘ "
+ procNameVariable// inject literal value
+ " ‘ ";
System Bottleneck > CPU Bottleneck > User CPU Bottleneck > UtilitIEs Running?
為了盡快完成工作,DB2 實用工具被設計成擴展良好並充分利用系統資源。那就是說在一個實用工具正在運行時,可能 CPU 使用會有顯著的增加。 Load 和 runstats 是一個實用程序的很好的例子,它們經常導致高 CPU 使用,但是在正常情況下,其它的實用程序也能這樣。正在運行的實用程序可以通過 LIST UTILITYES SHOW DETAIL 命令看到。
如果實用程序正在執行,我們可以向下鑽取來判斷它的 CPU 使用情況。在 Unix 和 Linux,在 DB2 9.5 引入線程引擎之前只需通過一個簡單的ps命令,就可以看見實用程序許多的工作進程(伴隨這 CPU 的使用,等)到 DB2 9.5 db2pd – edus 命令顯示了 DB2 引擎中的所有線程,包括用戶和系統的 CPU 使用。這對決定是否某個線程是 CPU 瓶頸的時候非常有用。
設置 UTL_IMPACT_PRIORITY 可以有助於限制 BACKUP 和 RUNSTATS 對系統的影響。另外 RUNSTATS 的開銷和運行時間可以通過兩個方法降低(1)收集統計信息時僅對那些會作為謂詞的列(因此它需要統計信息)如果知道的話。(2)使用樣本統計信息,也是很好的建議,在後面的“寫和調優查詢以優化性能”提到。
默認情況下,在 LOAD 命令將對每個 CPU 都創建一個格式化程序線程(db2lfrm),但是通過使用 CPU PARALLELISM n 選項,我們可以把格式化程序減少到 n,來為剩下的系統留出更多的 CPU 能力。注意,通常情況下,通過 UTL_IMPACT_PRIORITY 或 CPU PARALLELISM 等來限制一個實用程序會成比例的延長使用程序的運行時間。
System Bottleneck > CPU Bottleneck > User CPU Bottleneck > Temporary Object Cleanup Overhead
當一個系統臨時表不再需要然後可以刪除了的時候,DB2 必須從緩沖池中移除它不在需要的頁面。如果這經常發生,而且如果臨時表和普通用戶數據共享緩沖池,會導致耗費額外的 CPU 時鐘周期來解決沖突和處理頁面。比起復雜查詢系統,這個問題在事務處理系統更常見。如果表快照顯示有很多臨時表被創建和銷毀,最佳實踐是把臨時表放到它們自己的的緩沖池裡面。這會消除多於的沖突和處理開銷,並對降低 CPU 實用有好處。
System Bottleneck > CPU Bottleneck > System CPU Bottleneck?
在大多數 CPU 受限的環境中用戶 CPU 往往是決定因素,不過系統 CPU 有時也能成為決定因素。雖然我們能診斷出很多原因,但是能最終解決的只有極少數。
系統 CPU 時間高的一個原因是與之相關的 DB2 在操作系統(OS)中上下文切換率過高。一個上下文切換是 OS 用來切換它需要處理的不同任務。上下文開關被系統中不同的規則觸發。然而當上下文切換得太頻繁,它們自己最終可能導致消耗大量 CPU 時間。在 Unix,上下文切換在 vmstat 中在‘ CS ’列有記錄。每秒超過 75,000 到 100,000 次的上下文切速度被認為是非常高了。
System Bottleneck > CPU Bottleneck > High System CPU > High Context Switches
在 DB2 系統中導致上下文切換率高的原因是大量的數據庫連接。每個連接都有一個或多個的數據庫代理進程為它工作,所以如果連很活躍-尤其對於很短的事務-會導致高上下文切換率何高 CPU 消耗的結果。避免這種情況的一種方法是開啟 DB2 連接集中器。它允許多個連接共享一個代理程序,因此降低了代理數目(節約了內存占用),並降低了上下文切換率。
設備中斷也會導致 CPU 時間高。一個設備(如網卡)發生一個中斷就需要操作系統的‘注意’。一次中斷的成本並不高,然而如果中斷的頻率太高,系統的總的負載會非常高。幸運的是,現在的網卡何磁盤轉適配器已經從 OS 中高度獨立出來了,比起前幾年的產品,現在只產生了非常少的中斷。來自磁盤的顯著中斷開銷很少,不過在網絡密集的客戶端 / 服務器系統(像許多 SAP R/3)網絡中斷造成的開銷可能會非常高。有些步驟可以用來降低網絡在服務器上造成的開銷,不過這類調試超過了本文討論的范圍。在這樣的場合你最好還是讓你的網絡管理員來定位並解決問題。
如果應用邏輯(尤其是較長的事務)能被寫入一個 SQL 存儲過程,這會有助於減少上下文切換和網絡通信量。這麼做不僅是把應用程序邏輯存入服務器,在上下文切換問題范疇,它也直接把邏輯推入 DB2 代理程序。這就消除了代理程序和客戶應用程序之間的 SQL 調用和結果的進出流 - 從而減少了上下文切換。
System Bottleneck > CPU Bottleneck > High System CPU > High Device Interrupts
在一個 DB2 系統中,我們通常盡可能的讓系統有很少的空閒內存並努力開發系統內存。不幸的是,如果我們過多的分配了內存 - 就像錯誤配置 DB2 或者其它軟件一樣,使用了超過系統物理內存的總量 - 頁清除操作將造成系統 CPU 開銷(磁盤開銷也有可能)。這種情況在 UNIX 上通過低空閒內存和 vmstat 動態輸出眾較高的頁面換入 / 換出,來確定。修正的辦法就是把內存分配降到觸發頁清除操作起點之下。
文件緩存消耗了內存是稍微有點棘手的情況。為了避免 I/O,OS 通常使用空閒內存來緩存磁盤數據。雖然文件緩存使用的內存在需要的時候 DB2 可以使用,我們總是希望避免 DB2 和文件系統在內存上發生‘拔河’的情況。由於文件系統緩存處理它自己是發生在用戶模式(它不消耗系統 CPU)而虛擬內存管理又能增加系統 CPU 使用,在這篇文章前面的‘ DB2 配置’章節中建議了要避免系統緩存影響 DB2 。在 AIX 上,使用 vmo 參數 LRU_FILE_REPAGE=0(同樣在上面討論過)能有助於確保 DB2 外的系統緩存開銷在可控的范圍。
System Bottleneck > CPU Bottleneck > High System CPU > Over-allocation of Memory
擁有龐大內存總量的系統 - 100G 或者更多 - 如果系統沒有配置使用大內存頁就會產生額外的 CPU 開銷。操作系統是以頁為最小粒度來管理內存的(注意這和 DB2 的頁有所不同)。一個典型的頁大小是 4KB -這意味著操作系統必須管理 100G 內存的 250,000,000 個頁表項。大多數操作系統都支持更大的頁大小,這有助於減少虛擬內存管理的開銷。以 AIX 為例,支持的最大頁大小達到了 16G 。這雖然在實際中幾乎用不到,不過有其它的頁大小可供手動選擇。在大多數擁有龐大內存的系統的最佳實踐是確保在啟用了 64-KB 頁,在 AIX 中 DB2 可以使用它們。這是在良好性能和最小化使用大頁面帶來的副作用之間的折衷。在 Linux 中,DB2 必須通過DB2_LARGE_PAGE_MEM來手動啟用對大數據頁的支持。
在 AIX 上,vmstat -P ALL 顯示了系統提供並使用了的頁大小是多少。如果系統使用了 64KB 的頁面並且數據庫正在運行,通過 vmstat – P ALL 你可以看到非常多的 64KB 頁被分配。如果系統有很大的物理內存卻沒有使用 64KB 頁,這會導致高於正常水平的系統內存消耗。
System Bottleneck > CPU Bottleneck > High System CPU > Small Memory Pages
系統 CPU 瓶頸 – 總圖
圖 2. 系統 CPU 瓶頸 – 總圖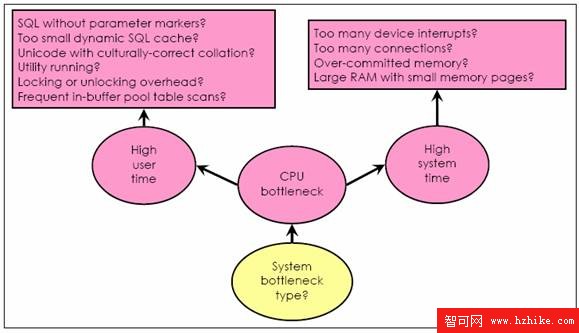
圖片看不清楚?請點擊這裡查看原圖(大圖)。
內存瓶頸
System Bottleneck > MemoryBottleneck?
系統有充足的內存並得到正確的配置是良好性能的關鍵。否則,如果沒有恰當的內存訪問,數據在填滿緩沖後就將轉向 I/O - 在這個過程中常常會造成磁盤瓶頸。同樣,雖然總量小一些卻很重要的內存也被用來存儲元數據以及運算結果,比如 SQL 查詢計劃和鎖。如果它們缺少內存,系統不得不取消或銷毀那些重要信息,並重新運算要不就以額外的處理來補償-增加了 CPU 的開銷。因此,一個內存瓶頸經常能把自己偽裝成磁盤或 CPU 問題。
下表把我們在前面討論過的可能由於底層內存的原因造成的磁盤和 CPU 瓶頸再回顧一下。
瓶頸類型 主要症狀 內存問題潛在的造成 / 影響瓶頸 磁盤 數據或索引表空間瓶頸 緩沖池太小
整個系統的內存太小
磁盤 臨時表空間瓶頸 Sortheap / sheapthres_shr 太小系統總內存太小
磁盤 日志磁盤瓶頸 日志緩沖太小 CPU 重復保緩存插入造成的 CPU 瓶頸 包高速緩存太小系統總內存太小
CPU 過多的系統 CPU 時間花費再 VMM 上 系統總內存過度分配較小系統內存頁大小管理很大的系統內存
這是最常見的有 CPU 或磁盤瓶頸症狀的內存瓶頸,並且是在分析這種問題時內存問題的主要可能性。然而在內存短缺的時候也是經常發生的(像 vmstat 報告的)-伴隨著低性能讓我們把這放到第一的位置-是明顯的症狀。如果進一步調查數據(vmstat)顯示持續活躍的頁面調度(有可能伴隨系統 CPU 使用的升高),這表示系統內存壓力過大。
DB2 的內存分配分成兩大類:
數據庫和實例級分配,分配了像共享數據庫內存,從緩沖池、排序堆、鎖列表到包緩存等等。對於定位內存過度分配的原因,共享內存非常容易處理,因為分配是和數據庫連接數沒有關系。這些分配都受到 DATABASE_MEMORY 配置參數的限制。
連接層面或應用程序分配,像應用程序堆和語句堆。連接層總的內存消耗明顯依賴與連接數,這可能會使得在系統初始化配置時候更難預估。在 DB2 9.5 每個應用程序內存都在 INSTANCE_MEMORY 保護傘下,所以由於突然連接導致的逃逸分配變得不大可能。
無論是直接指定堆大小還是啟用 STMM,判斷 DB2 內存實際用量的最好辦法就是查看 database,database manager 和應用程序快照的內存使用部分(或 sysibmadm.snapdb_memory_pool snapdbm_memory_pool, 和 snapagent_memory_pool 管理視圖),它們提供了數據庫,實例和應用層面各自的配置堆大小和當前堆大小。這些讓你檢查配置的和當前堆和應用程序的分配,以及檢查當前總的分配。
DB2 9.5 內存使用的最高限制是通過 INSTANCE_MEMORY 數據庫管理配置參數,和 DATABASE_MEMORY 數據庫配置參數。在大多數系統中,它們默認為 AUTOMATIC, 這意味著實例和數據庫的內存的使用可以上下浮動。(它們的當前值通過 get database manager configuration 和 get database configuration 命令的 SHOW DETIAL 選項)因此,DB2 的內存管理系統是設計來避免我們在這裡討論的內存瓶頸問題。為什麼仍然發生內存瓶頸?
如果 INSTANCE_MEMORY 被設置為一個確定的數值,並且 STMM 啟動了,那麼 STMM 將調整 DB2 內存消耗只達到 INSTANCE_MEMORY 的值。在這種情況下,STMM 不會對系統釋放內存的壓力做出反應(因為 INSTANCE_MEMORY 沒有設置成 AUTOMATIC)因此,可能 DB2 和其它像應用程序服務器這樣的內存使用大戶等一起,會把系統范圍的總的內存用量推到過高位置。 Unix 的 ps 命令或者 Windows 的任務管理器將顯示進程的內存使用,是一個無價的工具用來跟蹤數據庫外的“memory hogs ”。
如前面提到的,當文件系統緩存對於 DB2 這樣的消費者是技術上存在的,DB2 也能成為大量文件緩存的原因(尤其對於在內存能釋放給其它內存用戶之前,修改的數據必須存到磁盤)如果產生了額外的內存需求,這可能導致發生頁清除。
如果在這個服務器上存在很強的非 DB2 的內存需求,INSTANCE_MEMORY 參數應該被設置成 AUTOMATIC,或降低到 DB2 在系統中能使用的內存范圍。
一個確定的 INSTANCE_MEMORY 值對系統而言太高的話可在另外的數據庫啟動之前可能不會出現問題,把 DB2 的整個分配高於系統可以調整不過仍然在 INSTANCE_MEMORY 之內。
因為 STMM 被設計來處理內存壓力,在需要的時候釋放內存給操作系統,如果沒有啟動 STMM 這種情況會經常發生,或者涉及的系統(如 Solaris)不支持內存釋放回操作系統,或當數據庫內存需求非常動態(如,很快的創建 / 銷毀數據庫連接,或者數據庫活躍很短周期,等。)
如果數據庫有非常大的連接需求,這可能導致實例的很大一部分內存被代理程序消耗。如果總量過多 - 留給數據庫全局內存太少,無論有沒有啟動 STMM- 它都可以通過使用連接集中器來減少內存消耗。
‘懶惰系統’瓶頸
System Bottleneck > Lazy System
第四,也是最有意思的一類瓶頸,我們接下來一起來看一下‘懶惰系統’瓶頸。這表現為在前面幾個瓶頸可能都不存在。沒有(明顯的)CPU,磁盤或者內存(或者網絡,或…)瓶頸,系統也不忙。
在 ‘懶惰系統中’一個最常見的原因是鎖爭搶。幸運的是,鎖爭搶是很容易在快照數據中被檢查到的。快照元素 lock_wait_time 和 locks_waiting 通過 sysibmadm.snapdb 分別顯示總的鎖等待時間和當前在等待鎖的代理進程數,活動代理等待鎖的百分比很高(如,20% 或者更高)與 / 或鎖等待的時間增加是發生瓶頸的明顯跡象。
System Bottleneck > Lazy System > Lock Wait
雖然不能判斷每個語句的鎖等待時間,但是通過動態 SQL 語句快照和語句事件監控器中被延長的執行時間、相關的 CPU 消耗以及 IO 活動,通常還是可以合理的判斷出語句收到鎖等待影響的時間。也就是說,應用程序快照同樣報告了應用程序的鎖等待時間,這對縮小在系統范圍內引起鎖等待的可能性的范圍來說非常有用。我們可以從 sysibmadm.snaplockwait 視圖中得到更多的鎖等待信息。它顯示:
鎖類型 - 共享鎖或排它鎖
對像類型 – 行,表,等。
持有者和請求者的代理進程 ID
注意,不像其它許多 DB2 快照監控數據 , 鎖的信息的存在周期是非常短暫的。除了 lock_wait_time 是總共的,其它大多數鎖的信息在鎖釋放後也釋放了。因此,在一段時間內周期性搜集鎖和鎖等待快照非常很重要,連續的場景也更容易被理解。像前面所介紹的,分析大量快照數據的最佳實踐是通過管理視圖並把它存入 DB2 。這尤其對於來自 snaplockwait 的數據是這樣,它由應用程序數據,數據庫和鎖快照組成,並且不能通過快照命令得到。
雖然不像其它快照類型,與僅通過鎖監控開關啟用快照功能相比,鎖快照的總開銷是抓取快照本身。所以,雖然抓取快照並存入 DB2 很平常,但是過於頻繁的快照會對它自己造成瓶頸。
有很多方法有助於降低鎖爭搶和鎖等待時間
如果可能,盡可能的避免運行時間過長的事務和 WITH HOLD 游標。持有鎖的時間越長,與其它應用程序發生鎖爭搶的可能性就越大。
要避免取得比實際需要更大的結果集,尤其是 REPEATABLE READ 隔離級別。簡單的說,涉及的行數越多意味著持有更多的鎖,而且有更多的機會運行到別人持有的鎖。在實際情況下,這常常意味著降低 SELECT 的 WHERE 子句對行的選擇標准,而不是返回更多的行卻在應用程序裡過濾它。
圖 3. 例子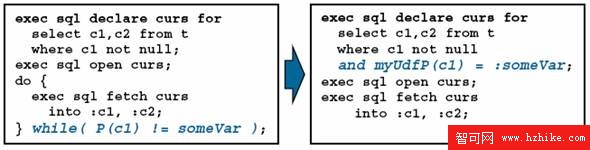
圖片看不清楚?請點擊這裡查看原圖(大圖)。
避免使用比實際需要更高的隔離級別。可重復讀或許在應用程序中保護結果集完整性時是必需的,然而它也會在持有鎖以及潛在的鎖沖突方面造成額外的開銷。
如果應用程序的商業邏輯合理,考慮到通過db2_evaluncommitted,db2_skipdeleted, anddb2_skipinserted來更改鎖的行為。這些設置讓 DB2 可以推遲或避免在某些情況下產生鎖,因而降低爭搶並潛在的提高吞吐量。
鎖升級也會成為發生爭搶的主要原因。反之,經過良好設計的應用程序持有的個別行鎖或許不會發生沖突,鎖升級導致的塊或表級別的鎖常常會導致對象串行化以及嚴重的性能問題。數據庫快照報告了一個全局的鎖升級的總和(sysibmadm.snapdb.lock_escals)。通過檢查寫入 db2diag.log 中的消息(DIAGLEVEL 3),當鎖升級發生的時候這很容易確定是哪個表上的升級 。
當一個應用程序消耗了他被允許的那一部分鎖列表(取決於數據庫配置參數 MAXLOCKS,它表現為鎖列表大小的百分比),鎖升級就被觸發。因此增加 MAXLOCKS 和 / 或鎖列表可以降低鎖升級的頻率。同樣,如上面提到的,降低應用程序持有的鎖數目(通過增加提交頻率,降低隔離級別,等)將有助於減少鎖升級。
System Bottleneck > Lazy System > Deadlocks and Lock Timeout
當鎖等待的時間成為十分微妙的瓶頸的時候,死鎖和鎖超問題時就很難被忽略了,因為它們倆都對應用程序返回負的 SQL 碼。雖然許多應用程序會簡單的重試失敗事務沒有報出死鎖並最終取得成功。在這種情況下能夠最直接反映潛在死鎖問題的是在 sysibmadm.snapdb 管理視圖中的死鎖監控元素。如上面提到的,我們建議把這作為搜集日常操作監控數據的一部分。
死鎖的成本有所不同,它的成本直接和回滾的事務成正比。同樣,每 1000 筆事務發生死鎖次數超過一次通常意味著有問題。
死鎖的頻率有時可以很容易降低,通過保證所有應用程序以相同的順序訪問它們的數據 - 例如,訪問(並且也鎖定)行在表 Table A 中 , 接著是 Table B,接著是 Table C,等。如果兩個應用程序以不同的順序在相同對像上持有互斥的鎖,它們發生死鎖的風險會很大。
默認的死鎖事件監控器db2detaildeadlock 將記錄所有死鎖信息並存在 deftdbpath(數據庫管理器默認數據庫路徑),例如在 <dftdbpath>/NODE0000/SQL00001/db2event/db2detaildeadlock.
像所有事件監控器一樣,它會帶來少量的額外開銷,但是能跟蹤死鎖帶來的好處超過了這小小的性能降低。
鎖超時對系統而言具有同死鎖相同的破壞力。因為普通的死鎖事件監控器不會跟蹤鎖超時,我們需要另外一個機制。 DB2 9.5 提供了一個技術用來產生一個基於文本關於鎖超時的報告,它基於死鎖事件監控器,在引擎中增加了其它基礎構造。比起之前的版本,這極大的簡化了鎖超時的診斷。產生鎖超時報告的流程在 developerworks:“New options for analyzing lock timeouts in DB2 9.5 ”中有描述。
System Bottleneck > Lazy System > InsufficIEnt Prefetching ?
比起代理程序自己讀取數據,DB2 預取程序讀取數據查詢大量的數據對磁盤進行連續讀執行的效率要高很多。這有多種原因 ,
比如預取程序每次讀取多個頁面,讀取的大小是數據庫或表空間預取值,而代理程序一次只讀取一個數據頁。
代理程序可以在預取程序工作時執行一部分查詢,減少了計算和 I/O 的串行化。
多個預取程序可以每個都分配讀取一部分頁面,達到 I/O 並行性。
當代理程序將需要一個頁面范圍的數據的時候,它會排隊提出預取的請求。當代理程序需要要使用一個頁面的時候,如果預取程序還沒有開始它的 I/O(就是說,如果他還沒有最終被預取程序取到,或如果這個請求還在預取隊列),代理程序將自己讀取那個頁面。這會減少代理程序等待預取程序的頻率(它將之等待實際進行中的 I/O)。然而,如果我們像這樣回到使用代理程序 I/O,預取的所有好處都不復存在。
這種問題的症狀包括:
一個大的查詢語句低於 100% 的‘預取率’。(根據在數據庫或者緩沖池層面,目標值會降低,基於它的那些活動不是基於掃描的。)我們設置這個值的度量類似於緩沖池命中率,不過在這裡是以預取完成的物理讀和總的物理讀想比來計算的。 100% * (pool_data_p_reads – async_data_reads) / pool_data_p_reads
這樣可以在數據庫層面通過對 sysibmadm.snapdb、或者通過緩沖池層面的 sysibmadm.snapbp、在動態 SQL 語句層面的 namic SQL statement level with 計算
在 sysibmadm.snapdb 和 sysibmadm.snapappl 中的 prefetch_wait_time 顯示較高並且不斷攀升的‘花費在預取等待的時間’。如在上面所提到的,代理進程只等待實際上‘正在運行’的預取 I/O 。
類似於其它的“懶惰系統”問題,我們通常總會從 vmstat&perfmon 看見很高的空閒。不過 I/O 等待時間可能增加,因為代理進程讀取單個頁面的效率要遠遠少於預取進行大塊的讀取。但是即使如此,I/O 等待也不大可能爬升到足以造成瓶頸。
這個問題的最大可能性是預取器的數目(數據庫配置參數 NUM_iOSERVERS)太少。在 DB2 v9 及以後可以有 AUTOMATIC 設置,而且後來使用像表空間並行這樣的元素等,來計算預取器的個數,一般情況下不再需要調整。不過,在低預取率的時候調整顯得還是必要的,流程如下:
判斷是否所有的預取器花費大致等於 CPU 時間。這在 DB2 v9 或之前的版本上可以通過的 ps 命令,或者在 db2 v9.5 及以後版本使用 db2pd – edu 來實現。如果有一些預取器消耗了比其它預取器少很多的 CPU,那麼說明已經有足夠多(可能過多)的預取器。(如果有超過一對‘空閒’預取器,你可以慢慢減少 NUM_iOSERVERS,不過有多余的預取器並不是問題。)
通過 10% 增加 NUM_IOSERVERS 。讓系統在有大量預取器的情況下可以正常運行。如果不能提高繁重查詢的預取率,那麼我對我這個問題的判斷不正確,而且 NUM_iOSERVERS 應該被設回原始設置。
重復這個流程直到你找到預取器在這個系統上合適的級別。
如果預取仍然低於同等操作水平,就非常需要驗證 prefetchsize 是否被正確設置。DB2 Information Center對 於對這個驗證流程已經進行了詳細的討論,我們就不再這裡重復了。
System Bottleneck > Lazy System > InsufficIEnt Page Cleaning?
類似於預取的另一個關於緩沖池頁面清除的問題,如果強制代理進程終止它們的正常處理來執行 I/O,則通常應該有一個 DB2 的‘工作線程’來處理。然而在這種情況下,代理進程不得不進行寫操作(更改頁面)而非讀取。這常常會涉及到類似‘頁清除操作’。
應該說這個症狀和上面老套的‘預取缺乏’不大一樣。在一個有很多並發 DB2 代理進程的線事務處理(OLTP)環境中,缺少頁面清除會導致更多的問題。如果它們不能找到干淨的緩沖頁就不得不自己進行頁清除,這可能潛在的造成很多額外的單個頁面寫入容器。這意味著在這種情況下,我們可能看到一個 I/O 瓶頸,而不是一個通常意義上的‘懶惰系統’。發生的次數取決於連接的數目,頁面清除程序的性能,等等。
一個相關症狀是 ‘爆炸性的’系統活躍,如在 vmstat 中看到的。系統可能在短時間內運行很好,代理進程工作正常,在接下來的一段時間大多數代理進程會被阻塞,並自己刷新一個髒頁面到磁盤。這將在 vmstat 中顯示為高 I/O 等待和代理進程運行隊列段時間空閒。等代理進程完成了頁清除,性能又恢復如常 - 這將周期性重復。
在 DB2 ’ s 監控數據中,頁清除的次數(在 sysibmadm.snapdb 中 pool_drty_pg_steal_clns)是是否出現問題最佳指示器。我們通常希望在一個流暢運行的系統中很少發生頁清除操作,因此頁面清除次數的任何異常的增長都由於某些原因導致的。
如果頁清除下降並且發生換頁操作,要檢查的第一件事就是頁面清除程序的數目(數據庫配置參數 NUM_IOCLEANERS.)DB2 9 和之後的版本支持 AUTOMATIC 設置,這是遵循當前分區中每顆處理器一個頁面清除程序的最佳實踐。注意,在 DB2 9.5 中超過推薦值得多余的頁面清楚程序會最終有損於性能。
在 DB2 8.2 中 DB2 支持兩類頁清除程序 - ‘典型’被動頁清除程序(默認),和主動頁清除程序。
典型的頁面清除程序是受到兩個 DB2 配置參數控制的
CHAGPGS_THRESH – 判斷用於激活頁面清除程序的已更改緩沖池頁面的百分比。
SOFTMAX – 限制在緩沖池中最新更改頁面與最老的已更改頁面的 LSN 差距,以控制恢復時間。
減少它們中的任意一個通常都會使頁面清除更有侵略性,不過要影響在緩沖池中干淨頁面的數目,CHNGPGS_THRESH 是首選的方法。降低 CHNGPGS_THRESH 或許可以幫助減少換頁的次數,並且穩定起伏的頁面清除。注意,這個參數設置過低會導致過多的磁盤寫入,因此應該被設置為剛好能避免換頁的程度。
主動頁面清除(也就是熟知的輪流換頁,或 APC)通過使用注冊表變量 DB2_USE_ALTERNATE_PAGE_CLEANING 來啟用。這不同於‘典型’的頁面清除程序,在典型頁清除中它調整它的清除比例來維持期望的 LSN 差距。比起清除被‘開’或‘關’、觸發或不觸發,APC 可以阻止它被激活以避免典型頁面清除在某些時候的‘爆炸性’行為。和典型頁面清除類似,減少 SOFTMAX 也有效的增加了頁面清除的頻率,並減少了換頁。注意,如果系統之前是基於命中 CHNGPGS_THRESH 來清除頁面的話,APC 則只受 SOFTMAX 控制。(例如,髒頁閥值觸發器。)
System Bottleneck > Lazy System > Application side problem?
客戶端應用程序和 DB2 服務器之間的請求以及前端與後端的響應和同步流,都意味著它們都是整個系統性能的角色之一。例如,在一批應用程序的運行時中的增加請求數,可能會導致系統緩慢,不過這也可能是由於應用程序對 DB2 的請求成功率下降的原故。這類問題的症狀和 ‘懶惰系統’非常接近的模式。
對 DB2 的請求成功率減少的症狀包括:
在應用程序中‘ UOW wait ’狀態的代理進程數目增加(在 sysibmadm.snapappl_info 中的 appl_status )- 意味著它們等待的時間多於工作時間。
請求到達代理進程的時間增加(sysibmadm.snapappl_info 中的 status_change_time)
客戶端發起請求的時間間隔增加,比如在語句事件監控器中,或 CLI 以及 JDBC trace 中看到的。 CLI 和 JDBC 跟蹤抓取客戶端的 API 請求,以及記錄請求發起的時間戳。雖然客戶端 trace 的開銷很大,不過它們有對包括網絡響應時間計時的好處,以及搜集其它 DB2 引擎外部的因素。
如果有應用程序端度量標准,比如商業層事務吞吐量或響應時間可能表現為變慢。
如果應用程序端變慢則顯示有問題,可能的原因包括
部署了一個新版的應用程序
一個在客戶端和服務器之間的網絡瓶頸
客戶端系統負載過大– 例如太多用戶或太多應用程序的副本在運行。
對 DB2 的請求成功率減少的症狀包括:
在應用程序中‘ UOW wait ’狀態的代理進程數目增加(在 sysibmadm.snapappl_info 中的 appl_status )- 意味著它們等待的時間多於工作時間。
請求到達代理進程的時間增加(sysibmadm.snapappl_info 中的 status_change_time)
客戶端發起請求的時間間隔增加,比如在語句事件監控器中,或 CLI 以及 JDBC trace 中看到的。 CLI 和 JDBC 跟蹤抓取客戶端的 API 請求,以及記錄請求發起的時間戳。雖然客戶端 trace 的開銷很大,不過它們有對包括網絡響應時間計時的好處,以及搜集其它 DB2 引擎外部的因素。
如果有應用程序端度量標准,比如商業層事務吞吐量或響應時間可能表現為變慢。
如果應用程序端變慢則顯示有問題,可能的原因包括
部署了一個新版的應用程序
一個在客戶端和服務器之間的網絡瓶頸
客戶端系統負載過大– 例如太多用戶或太多應用程序的副本在運行。
圖 4. 系統瓶頸 - 總圖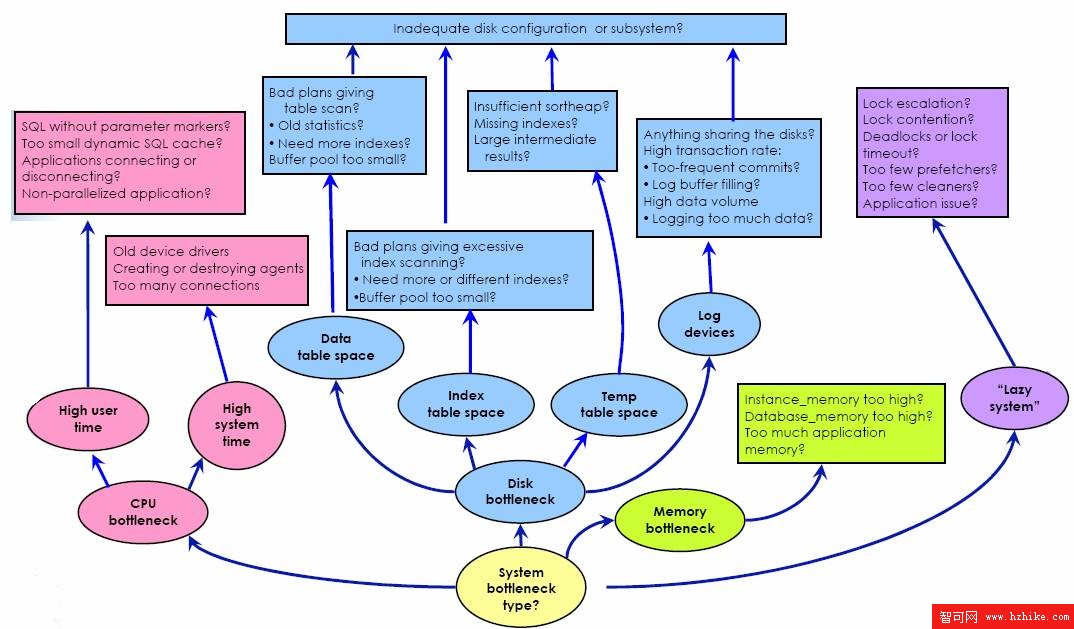
圖片看不清楚?請點擊這裡查看原圖(大圖)。
局部 vs. 系統范圍的問題診斷
到現在為止,我們已經處理了系統中的整體性能問題 – 高層磁盤、CPU、內存和懶惰系統問題。但是性能問題並不總是以這樣的形式出現。通常,整個系統運行正常,不過有一個用戶或應用程序,或存儲過程,或一個 SQL 語句 – 出現了問題。處理小范圍的問題和系統范圍的性能問題有什麼不同?
一旦我們確定了一個或多個問題 SQL 語句,以及我們了解它們所面對的瓶頸,我們就可以應用多種在前面章節討論的方法。尤其是涉及挖掘‘ hot SQL statements ’、hot table 的技術 – 我們關注在定位問題中涉及的因素。最佳實踐:
配置:
在物理磁盤的數目方面確保充足的磁盤能力
在專門的磁盤上存放本地事務日志
為了數據倉庫中部署超過 300GB 的數據使用 DB2 數據分區功能
對於 Unicode 的最佳性能考慮語言感知
對就像 SAP 一樣的 ISV 應用程序,遵循廠商的配置建議
使用 DB2 自動配置以獲得良好的初始配置設置
STMM 和其它自動維護提供了穩定而強大的性能
對 DPF 環境,使用一個本地文件系統要比 NFS-mounted 文件系統作為 DIAGPATH 更好。
監控:
搜集普通的基本操作監控數據,因此在出現問題的情況下可以使用背景信息
使用管理視圖來訪問並使用 SQL 操作監控數據
也監控非 DB2 的度量,比如 CPU 使用和應用程序端的響應時間
對配置和環境設置中的更改保持跟蹤
問題診斷:
系統的 - 一次只做一次更改,並仔細觀察結果
從最高級別症狀開始 – 比如 CPU、磁盤或內存瓶頸 – 以求在早期救排除不可能的原因。
利用每一步來提煉挖掘可能的原因 – 例如 I/O 瓶頸可能是由於容器 C 導致的,這可能是 T 表導致的,而 T 表可能是由於語句 S 效率極差。
不要僅根據‘直覺’對系統進行更改 - 要確定理解你准備解決的問題是如何產生你看到的症狀的。
對系統范圍的問題和更小范圍的問題都同樣從頭到尾使用系統方法。
幸運的是,在本文中提出的診斷性能問題方法論用在應用程序上也一樣,不管是普遍的還是特定問題。我們所需要做的就是抽取系統可以提供的監控數據的相關部分。
假設我們有一個應用程序,它運行在我們期望的級別之下。在我們可以開始診斷問題之前,需要在系統上定位這個應用程序的范圍
1 .了解應用程序名字和應用程序使用的授權 ID,LIST APPLICATIONS 命令告訴我們‘ appl ID ’(例如,LOCAL.srees.0804250311139),這是定位這個應用程序詳細監控數據的關鍵。
2 .對於特定應用程序監控數據,應用程序快照是一個極好的資源,而且通過指定剛才得到的 appl ID,我們可以專注於 我們感興趣的連接上。
db2 get snapshot for application applid '*LOCAL.srees.080425031139'
在這裡(或從 sysibmadm.snapappl 和 sysibmadm.snapapplinfo),我們可以判斷很多關於應用程序的重要信息,比如在抓取快照時的正在執行的語句、緩沖池命中率、排序總時間、選擇的行和讀取的行的比例,以及 CPU 和花費的時間。在排序中,我們可以得到了很多和我們用在診斷系統級別問題相同的信息,然而在這種情況下只側重我們關注的信息。
3 .為了深入研究,我們也可以使用在語句事件監控器中的應用程序 ID 作為一個 WHERE 子句的子句,只專注於我們工作的這個應用程序搜集的事件監控信息。這將向我們提供應用程序的每條語句執行時間、緩沖池和 CUP 消耗信息。
雖然我們對改變全局 CPU 消耗或磁盤活動(不要忘記,整體很好)並不關注,但是理解狀況是否發生在運行中的哪個應用程序卻仍然十分重要。如果系統是 CPU 受限,而且我們的應用程序是 CPU 饑餓狀態,則它的性能將會受到影響。類似,磁盤活躍情況也一樣。
在收集了很多應用程序快照、事件監控的跟蹤後,我們現在幾乎擁有和系統范圍問題一樣的監控數據。我們的基本目標就是判斷我們應該把時間花費在應用程序的什麼地方 – 這也是瓶頸所在。應用程序中的哪些 SQL 語句運行時間最長?哪些語句消耗了絕大多數 CPU,或導致了絕大部分的磁盤 I/O ?模仿我們在系統范圍的判斷樹來回答這些問題。
總結和結論
本文考慮了 3 個關鍵范圍,它們對於在理解嘗試避免你的系統性能降低時候非常重要:配置、監控和性能診斷。
我們的建議包括硬件和軟件配置,它們可以幫助你確保良好的系統性能。我們討論了很多監控技術這將幫助你在操作方面和問題診斷方面理解系統性能。同樣為了有步驟的,有條不紊的處理問題,我們展示了一批 DB2 性能診斷的最佳實踐。
如果你的系統配置恰當而且監控良好,你就可以有效的解決可能出現的性能問題,因此減少總的擁有成本並提高你的業務的投資回報。