簡介
分區索引(partitioned index)是 DB2 V9.7 中的新特性,在本文中將介紹什麼是分區索引,如何創建和管理分區索引,分區索引如何改進大型數據庫性能,讀者將獲得對分區索引的第一手體驗。每個分區索引由多個索引分區(index partition)組成,每個索引分區只對相應的數據分區(data partition)的數據作索引。
開始之前
在開始討論分區索引之前我們有必要復習一下 DB2 的表分區特性,這一特性是在 DB2 V9 引入的,developerworks 上的這篇文章 “ DB2 9 表分區 - 改進大型數據庫的管理” 是一個很好的參考。
表分區是一種數據組織模式,在這種模式中,數據將以一個或多個表列的值為依據,分割到多個稱為數據分區(或范圍)的存儲對象中。每一個數據分區被分別存儲。這些存儲對象可以位於不同的表空間中,可以位於相同的表空間中,也可能是這兩種情況的組合。
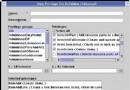
表分區特性改進了大型數據庫的管理,用戶可以靈活的放置索引,在圖 1 中,在分區表上建立了兩個索引,每個索引分別放置在一個表空間中。但是我們同時也看到,每一個索引中的鍵值指向了所有數據分區的數據庫,在表數據量很大的情況索引也會變得很大。
圖 1. DB2 v9 中表分區特性及其索引
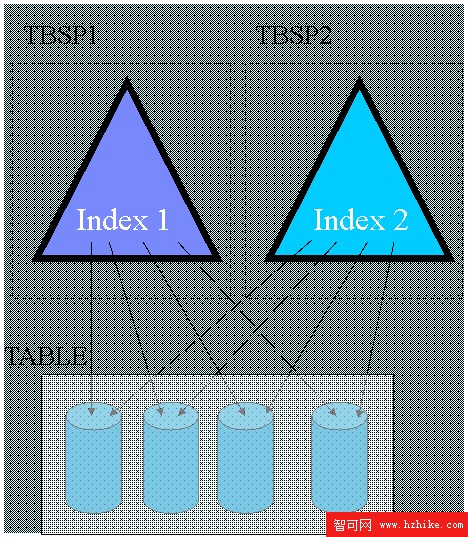
另外,表分區特性使得用戶可以使用 ALTER TABLE … ATTACH PARTITION 命令和 DETACH PARTITION 命令輕易的實現表數據的轉入( roll-in )和轉出( roll-out) ,這兩個操作都不需要有任何數據的移動,從而很大的提高性能。同時我們也看到,這兩個操作之後需要對索引進行維護,例如 ATTACH 一個新的分區之後需要為這個分區的新數據進行索引, DETACH 一個分區之後需要將索引中相應的鍵值清除。
分區索引簡介
在 DB2 V9.7 之前,分區表上的索引是不能分區的。由於分區表很多情況都是應用在數據倉庫環境中,當數據量很大的時候,索引也隨之變得很大,從而導致一些的性能上降低。
在 DB2 V9.7 中,索引也可以是分區的,這一特性稱之為分區索引(partitioned index)。分區索引由多個索引分區(index partition)組成,每個索引分區中的鍵值指向相應的唯一一個數據分區(data partition)的數據,系統創建的索引或者用戶的創建的索引都可以是分區索引。
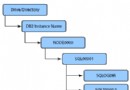
在圖 2 中,在一個有 4 個數據分區的分區表上建立了三個索引,其中 index1 和 index2 是分區索引,分別由 4 個索引分區組成,index3 是非分區索引(nonpartitioned index),或者稱之為全局索引(global index),相對應的,我們可以把分區索引稱為本地索引(local index)。
圖 2. DB2 V9.7 中的分區索引
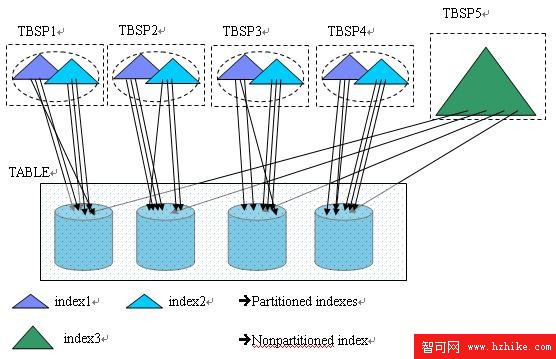
圖片看不清楚?請點擊這裡查看原圖(大圖)。
分區索引帶來的一個顯著優勢在於,在使用 ALTER TABLE ATTACH PARTITION 和 DETAICH PARTITION 命令進行數據的轉入( roll-in )和轉出( roll-out) 時, 使用分區索引能夠很大程度的提高性能。
在 DB2 V9.7 中,以下類型的索引不能是分區索引,只能是非分區索引。
XML 索引
空間數據( spatial data )索引
MDC 塊索引( block index ,系統生成索引)
XML path index (系統生成索引)
准備工作
在開始之前,我們先創建一個新的數據庫名字叫做 MYDB,如清單 1 所示。當然用已經存在的數據庫也可以,但是為了能夠簡化環境,清楚的、逐步的進行我們接下來的討論,建議使用一個全新的數據庫。
本文中所有操作都是在 LinuxAMD64 平台上的 DB2 V97 版本進行,V97 版本之前的版本都沒有分區索引特性。
清單 1. 創建數據庫
db2 CREATE DB mydb
創建數據庫之後我們創建若干個表空間,如清單 2 所示。
清單 2. 創建表空間
CREATE TABLESPACE TbspT MANAGED BY DATABASE using (FILE 'tspT' 4 M) AUTORESIZE YES;
CREATE TABLESPACE TbspX MANAGED BY DATABASE using (FILE 'tspX' 4 M) AUTORESIZE YES;
CREATE TABLESPACE TbspD MANAGED BY DATABASE using (FILE 'tspD' 4 M) AUTORESIZE YES;
CREATE TABLESPACE TbspY MANAGED BY DATABASE using (FILE 'tspY' 4 M) AUTORESIZE YES;
CREATE TABLESPACE TbspW MANAGED BY DATABASE using (FILE 'tspW' 4 M) AUTORESIZE YES;
創建分區表
首先創建一個分區表,V9.7 中的分區索引特性為 CREATE TABLE 語法引入了新的子句,即分區級的 INDEX IN 子句。在創建分區表時,我們可以通過表級的 INDEX IN <tablespace> 來指定非分區索引的存放位置,同時可以通過分區級的 INDEX IN <tablespace> 為每一個數據分區對應的索引分區指定單獨的表空間。如果沒有對於某一個或者多個數據分區指定索引分區的存放表空間,默認是將索引分區存放在與數據分區相同的表空間內。
使用如清單 3 所示的語句創建一個分區表 datapartT,包括 5 個分區。
清單 3. 創建分區表
CREATE TABLE datapartT (a int, b int )IN TbspT INDEX IN TbspXPARTITION BY ( a,b )
(
PARTITION Part0 STARTING (0, 0) ENDING (0, 10)IN TbspD,
PARTITION Part1 ENDING (20,20)INDEX IN TbspY,
PARTITION Part2 ENDING (40,40)INDEX IN TbspW,
PARTITION Part3 STARTING (100,100) ENDING (150, 150)
INDEX IN TbspW,PARTITION Part4 ENDING (200, 200) );
創建分區索引
在 DB2 V9.7 中,創建索引的語法增加了兩個保留字 PARTITIONED 和 NOT PARTITIONED,分別用來創建分區索引和非分區索引。如果在創建索引時沒有指定這兩個保留字中任何一個,默認將建立分區索引。這就意味著,當用戶在 DB2 V9.7 上使用於之前相同的語句創建索引時,事實上 DB2 數據庫管理系統自動的為用戶應用了分區索引這一新特性。
我們已經知道,在 DB2 V9.7 之前,在分區表上創建索引(非分區索引)時可以使用“ CREATE INDEX … ON … IN <tablespace> ”語法將索引放到不同的表空間中,如圖 1 所示。在 DB2 V9.7 中,我們仍然可以使用類似語句將非分區索引放到不同的表空間中,而對於分區索引,不允許在創建索引時指定“ IN <tablespace> ”子句,這是因為分區索引的特性,每個索引分區的存放位置取決於創建分區表時分區級“ INDEX IN <tablespace> ”子句,如果某個數據分區沒有指定該字句,則相應的索引分區將存放在與數據分區相同的表空間中。
創建索引的語句如清單 4 所示,這裡創建了兩個分區索引 purpleidx 和 greenidx,以及一個非分區的索引 blueidx 。
清單 4. 創建分區索引以及非分區索引
CREATE INDEX purpleidx on datapartT(a,b) PARTITIONED;
CREATE INDEX greenidx on datapartT(b) PARTITIONED;
CREATE INDEX blueidx on datapartT(a) NOT PARTITIONED;
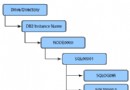
此時分區表 datapartT 中各個數據分區和索引的存放如圖 3 所示。
圖 3. 分區表上分區索引和非分區索引的存放
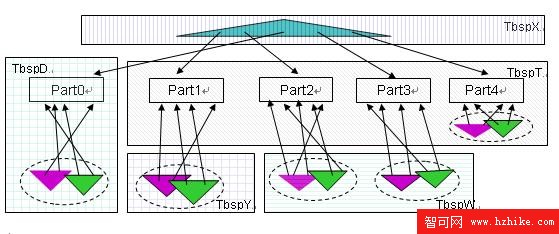
圖片看不清楚?請點擊這裡查看原圖(大圖)。
在圖 3 中,
分區 Part0,在創建表時指定了“ IN TbspD ”,沒有分區級的 INDEX IN 子句,於是 Part0 的數據分區放在表空間 TbspD 中,相應的索引分區存放在相同的表空間 TbspD 中。
分區 Part1,在創建表時沒有指定分區級的 IN 子句,但是由於存在表級的“ IN TbspT ”,於是 Part1 的數據分區放在 TbspT,同時對於 Part1 指定了分區級的“ INDEX IN TbspY ”,於是 Part1 相應的索引分區放在表空間 TbspY 上。
分區 Part2 和 Part3,都沒有指定分區級 IN 字句,都有分區級的“ INDEX IN TbspW ”,於是這兩個數據分區放在表空間 TbspT,相應的索引分區放在表空間 TbspW 中。
分區 Part4,即沒有指定分區級的 IN 子句,也沒有指定分區級的 INDEX IN 子句,於是這個數據分區放在表級“ IN TbspT ”所指定的表空間 TbspT 中,索引分區放在與數據分區相同的表空間 TbspT 中。
對於非分區索引 blueidx,在創建索引沒有指定 IN 子句,根據規則這個索引將存放在創建表時的表級 INDEX IN 子句所指定的表空間中,即 TbspX 。
分區索引管理
在這裡我們來介紹如何維護分區索引,包括
如何判斷分區索引
如何取得分區索引的信息
如何把非分區索引移植為分區索引。
如何判斷分區索引
對於已經存在的數據庫中的索引,我們如何判斷是分區索引或非分區索引,可以通過 DB2 提供的命令 DESCRIBE INDEXES 來判斷,使用的命令和結果如清單 5 所示。
清單 5. 用 DESCRIBE 命令查看是否為分區索引
db2 describe indexes for table datapartt
Index Index Unique Number of Index Index
schema name rule columns type partitioning
------ ------ ------ ------- --------- --------
TESTUSERS PURPLEIDX D 2 RELATIONAL DATA P
TESTUSERS GREENIDX D 1 RELATIONAL DATA P
TESTUSERS BLUEIDX D 1 RELATIONAL DATA N 3 record(s) selected.
在 DESCRIBE INDEXES 的輸出中有一列“ Index partitioning ”,“ P ”表示該索引為分區表上的分區索引,“ N ”表示該索引為分區表上的非分區索引。如果所指定的不是分區表,對於表上的索引 DESCRIBE 將輸出“ _ ”。
如何取得分區索引的信息
在故障診斷和數據恢復時,我們需要獲得表和索引的一些基本信息,除了表名、索引名之外我們經常需要獲得表和索引的對象 ID(object ID),表空間 ID 以及其他的信息,其中對象 ID 和表空間 ID 是兩個最重要的信息,可以用來唯一標識數據庫中的一個對象。
我們可以通過熟知的 CATALOG 表中獲取相應信息,我們已經知道,對於表和索引的基本信息,可以分別查詢 SYSCAT.TABLES 和 SYSCAT.INDEXES 。查詢語句和輸出結果如清單 6 所示。
清單 6. 查詢 CATALOG 表獲取表和索引信息
select substr(tabname, 1,10) tabname, TABLEID ,TBSPACEID
from syscat.tables where tabname='DATAPARTT'
TABNAME TABLEID TBSPACEID
---------- ------- ---------
DATAPARTT -32768
-6 1 record(s) selected.
select substr(TABNAME, 1,10)TABNAME,SUBSTR(INDNAME, 1, 10)
INDNAME, INDEXTYPE, TBSPACEID, INDEX_OBJECTID
from syscat.indexes where tabname='DATAPARTT'
TABNAME INDNAME INDEXTYPE TBSPACEID INDEX_OBJECTID
---------- ---------- --------- ----------- --------------
DATAPARTT PURPLEIDX REG 65530
32768
DATAPARTT GREENIDX REG 65530
32768
DATAPARTT BLUEIDX REG 10
4 3 record(s) selected.
對於分區表,從 SYSCAT.TABLES 中獲取到的對象 ID 和表空間 ID 是邏輯 ID(-32768, -6),並不是表空間存儲中真正的 ID,也並不存在這樣一個物理的對象,這是因為分區表是由若干個數據分區組成的,每一個分區分別對應一個表空間中的數據對象。
類似的,對於分區索引從 SYSCAT.INDEXES 中獲取到的對象 ID 和表空間 ID 也是邏輯 ID(65530, 32768),同樣原因是因為分區索引是由若干個索引分區組成,每個索引分區分別對應著一個表空間的索引對象。
我們可以通過查詢 SYSCAT.DATAPARTITIONS 來獲取每一個數據分區的信息,使用的查詢語句和輸出的結果如清單 7 所示。
清單 7. 查詢 CATALOG 表獲取每個數據分區信息
select substr(DATAPARTITIONNAME, 1,10) DATAPARTITIONNAME, PARTITIONOBJECTID,
tbspaceid ,substr(tabname,1,10) tabname
from syscat.datapartitions where tabname='DATAPARTT'
DATAPARTITIONNAME PARTITIONOBJECTID TBSPACEID TABNAME
----------------- ----------------- ----------- ----------
PART0 4 11 DATAPARTT
PART1 4 9 DATAPARTT
PART2 5 9 DATAPARTT
PART3 6 9 DATAPARTT
PART4 7 9 DATAPARTT 5 record(s) selected.
在結果中我們可以看到每一個數據分區都有各自的對象 ID 和表空間 ID,這裡的 ID 都是物理 ID,對應一個數據庫對象。
對於分區索引的每一個索引分區,在 DB2 V9.7 中有一個新的 CATALOG 表 SYSCAT.INDEXPARTITIONS 來記錄其信息,從這個表中我們也可以獲取每一個索引分區唯一的對象 ID 和表空間 ID 。使用的查詢語句和輸出結果如清單 8 所示。
清單 8. 查詢 CATALOG 表獲取每個索引分區的信息
select substr(TABNAME, 1,10)TABNAME,SUBSTR(INDNAME, 1, 10) INDNAME,
INDPARTITIONTBSPACEID, INDPARTITIONOBJECTID, DATAPARTITIONID
from SYSCAT.INDEXPARTITIONS where tabname='DATAPARTT'
TABNAME INDNAME INDPARTITIONTBSPACEID INDPARTITIONOBJECTID DATAPARTITIONID
------ ----- ------------ ------------ ----------
DATAPARTT PURPLEIDX 11 4 0
DATAPARTT PURPLEIDX 12 4 1
DATAPARTT PURPLEIDX 13 4 2
DATAPARTT PURPLEIDX 13 5 3
DATAPARTT PURPLEIDX 9 7 4
DATAPARTT GREENIDX 11 4 0
DATAPARTT GREENIDX 12 4 1
DATAPARTT GREENIDX 13 4 2
DATAPARTT GREENIDX 13 5 3
DATAPARTT GREENIDX 9 7 4 10 record(s) selected.
在結果中我們發現一個現象,索引 purpleidx 的索引分區 0 對應的對象 ID 和表空間 ID 為(4,11),而索引 greeninx 的索引分區 0 對應的對象 ID 和表空間 ID 也是(4,11),其他的分區也有相同的重復問題,我們在上文也指出每一個對象有唯一的對象 ID 和表空間 ID,這是否矛盾呢?其實,對於每一個數據分區的所有索引分區,都是存放在同一個索引對象中,例如,對於數據分區 Part0,它對應兩個索引分區分別是 purpleidx 的分區 0 和 greenidx 的分區 0,這兩個索引分區都存放在對象 ID 和表空間 ID 為(4,11)的索引對象裡。假如我們繼續在這個 datapartT 表上創建更多的分區索引,那數據分區 Part0 相應的所有索引分區都將共享這一個索引對象(4,11)。
如何把非分區索引移植為分區索引
分區索引是 DB2 V9.7 中的新特性,但是在實際環境中,我們經常需要把數據庫從一個之前的 DB2 版本移植到更新的 DB2 版本上來,對於移植到 DB2 V9.7 上的舊數據庫來說,其中分區表上的索引都是非分區索引,這種情況下如何將非分區索引移植為分區索引而且要保證索引一直可用?
一個可行的方法是,創建一個分區索引,具有與原有的非分區索引相同的定義,在這個新索引建立的過程中,原有的非分區索引仍然可用,當新索引創建完成之後,刪掉原有的非分區索引,最後用命令“ RENAME INDEX … TO … ”把新索引更改為與原有索引相同的名字。這是移植過程全部完成,整個過程中始終有索引可用。提示: DB2 V9.7 中允許在相同的一個或多個列上分別創建一個分區索引和一個非分區索引。
分區索引如何提高性能
之前提到,分區索引帶來的一個顯著優勢在於,在使用 ALTER TABLE ATTACH PARTITION 和 DETAICH PARTITION 命令進行數據的轉入( roll-in )和轉出( roll-out) 時, 使用分區索引能夠很大程度的提高性能。
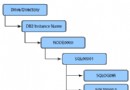
在使用分區索引特性之前,分區表上的所有索引都是非分區索引,在進行數據的轉入( roll-in )和轉出( roll-out) 時,需要對索引進行維護,包括在數據的轉入時需要在索引中建立新的鍵值對新數據分區作索引(如圖 4 所示),在數據的轉出時需要將索引中相應的鍵值清除(如圖 5 所示)。當索引很大的時候,這些維護工作需要非常的代價,將會嚴重影響數據庫系統的性能。
圖 4. 使用非分區索引時的數據轉入
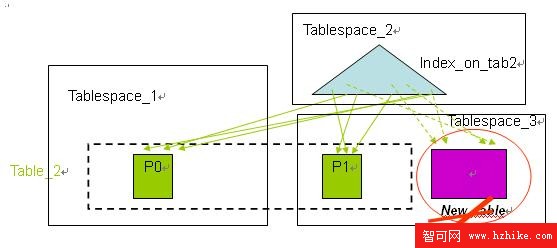
圖片看不清楚?請點擊這裡查看原圖(大圖)。
圖 5. 使用非分區索引時的數據轉出
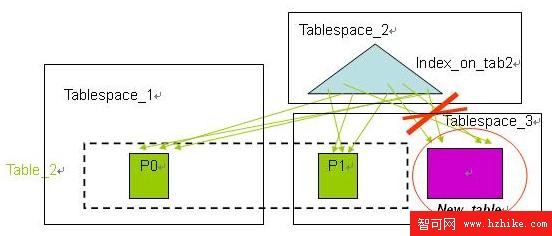
圖片看不清楚?請點擊這裡查看原圖(大圖)。
在 DB2 V9.7 上有了分區索引特性,當分區表上只有分區索引時,這時的進行數據的轉入和轉出變得更加便捷。如圖 6 所示,表 SalesTab 有兩個數據分區和兩個分區索引,表 New_table 是一個相同結構的普通表,並創建了相同定義的兩個索引。
圖 6. 使用分區索引時的數據轉入
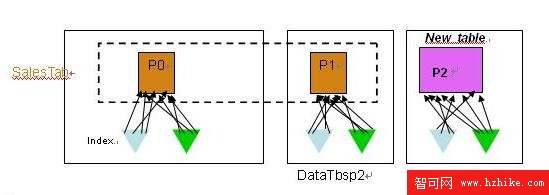
當使用數據轉入方式把表 New_table 連接(ATTACH)到表 SalesTab 上時,表 New_table 的數據將成為表 SalesTab 的一個數據分區,表 New_table 上的兩個索引分別成為表 SalesTab 上分區索引的新的索引分區,然後執行 Set Integrity 命令是所有的數據可用。整個過程不需要任何的數據移動,也不需要大量的索引維護,只需要很少的代價在很短的時間可以完成。類似的,當需要數據轉出時,被轉出的數據分區成為新表的數據對象,原有的分區索引的索引分區成為新表上的索引。
當然,在實際應用環境中可能遇到一些情況仍然需要對索引進行維護,例如
目標表上的分區索引在源表上沒有定義;
源表上的索引與目標表上索引不一致;
目標表上既有分區索引又有非分區索引。
另外, DB2 V9.7 的優化器對分區索引也有相應的處理,能夠根據情況選擇更加優化的執行計劃。限於篇幅以及復雜性,這個主題不在此介紹。
總結
本文可以使讀者獲得 DB2 V9.7 的分區索引特性的第一手體驗,包括什麼是分區索引,如何創建和維護分區索引,並且分析了分區索引帶來的性能提高。分區索引這一特性,能夠給數據倉庫、商業智能數據庫系統帶來性能上的巨大的提高。