DB2W-UA 概述
IBM DB2 Warehouse(原 Data Warehouse Edition)集成了商業智能所需的各種工具:數據轉換工具 SQW (SQL Warehousing)、數據挖掘工具 Intelligent Miner、聯機分析工具 Cubing Services、前端分析工具 Alphablox 等。
新一版的 DB2 Warehouse 9.5(以下簡稱 DB2W 9.5)中,在改進原有的數據挖掘工具的同時,引入了功能強大的非結構化數據分析工具 Unstructured Analysis(以下簡稱 DB2W-UA)。這一分析工具主要針對存儲在數據庫中的文本字段,目標是將非結構信息轉化為結構化信息,並結合其他結構化數據使用商業智能工具進行進一步的分析。DB2W-UA 能處理存儲在 CHAR、VARCHAR、CLOB 等數據類型中的文本信息。
文本分析簡介
目前,企業和政府機構中存在著大量的非結構化信息,例如呼叫中心的記錄、問卷調查的結果、問題報告、維修報告、保險索賠記錄、病歷、客戶的郵箱地址、產品反饋等。這些信息存儲在文本、音頻、視頻等不同的介質中。隨著非結構化信息的快速增長,如何分析這些信息源並將結果提供給決策者以支持決策成為一個重要的話題。
文本分析的定義
數據庫中的文本數據含有很多有價值的信息。然而,文本所代表的信息卻是復雜的、晦澀的。如果人工對這些數據進行分析,那將會是一個非常耗時和繁重的工作,或者是只能對一小部分的數據進行分析。
為了減少對文本數據的手工操作,多種文本處理技術逐漸發展起來。總的來說,對文本的處理有 3 種情況:文本檢索,文本分類和信息提取。
文本檢索是從一大堆的文本當中發現並抽出我們感興趣的、與某個主題相關想要的信息。但是,為了采用這種技術,我們不得不以某種形式指定我們想要的信息。因此,如何沒有一個清晰的目標知道要搜索什麼和可以從數據庫中搜索到什麼,那麼這種方式就對我們沒有什麼幫助。即使我們有了特定的搜索主題並且成功建立了查詢,但得到的結果是個文本列表,我們依然需要去閱讀並尋找信息。
文本分類技術可以讓我們了解文件的歸檔狀況,或者通過將文檔分類到預定義的類別中,或者是根據系統定義的相似性將具有相似內容的文檔自動分組到一個類中。通過這種技術,我們可以找出文檔中包含哪些主題,以及每個主題的大小。然而,為了詳細分析,我們依然需要閱讀主題或類中的每一個文檔。
信息提取的任務是從非結構化數據中提取出結構化信息,其目標是從特定范圍的文本中獲得分類的、上下文相關的、語義明確的數據。信息提取的一個典型例子是掃描一套由自然語言編寫的文檔,提取出結構化信息並加載到數據庫中。
DB2W 9.5 中的文本分析組件主要是指信息提取。
文本分析的商業價值
文本信息在各個領域中有著廣泛的應用。
客戶滿意度調查。企業在進行客戶滿意度調查時,通常要求客戶填寫反饋意見,這些反饋對於企業調整產品和服務質量等是非常有價值的。然而,手工識別和分類這些信息將是個乏味的、耗時的、昂貴的工作,通過文本分析可以簡化這個過程。
增強客戶保持力。獲取 / 贏得一個新的客戶的代價是很高的,因此,客戶不能被競爭對手吸引而離開。通過文本分析,我們可以抽取呼叫中心記錄中提到的最重要的問題,並結合結構化數據,通過預測技術預測客戶中止合同的傾向並實行相應措施。
故障原因分析。制造商可能想從維修中心的維修報告中了解引起經常返修的主要原因或者維修的順序,目的在於提高失效部件的質量以及盡早得到警告信息以避免產品回收造成的損失。
在生物醫學上的應用。我們可以從病人的歷史病歷中分析生活方式及病症可能引發的重大疾病,並進行風險評估。
文本分析與數據挖掘
文本挖掘是一個從非結構化文本信息中獲得用戶感興趣或者有用的模式的過程,其主要用途在於從文本中提取未知的知識。文本挖掘是一個多學科混雜的領域,它涵蓋了多種技術:信息抽取,信息檢索,自然語言處理以及數據挖掘技術等。由於必須處理那些本來就模糊而且非結構化的文本數據,文本挖掘是一項非常困難的工作。
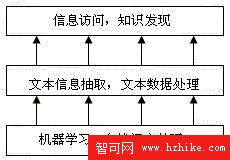
文本挖掘的過程大致分為 3 個階段:機器學習、自然語言處理;文本信息抽取、文本數據處理;信息訪問和知識發現,包括信息過濾檢索,數據分析、預測等。
圖 1. 文本挖掘過程
文本分析與 OLAP
我們可以將文本分析的結果結合結構化數據建立報表以及 OLAP(online analytical processing) 多維立方體。
例如,在呼叫中心的問題報告中,通過文本分析技術,我們可以獲得排前 10 位的客戶問題。我們可以將這些問題列為常見問題,並將相關解決辦法記錄在用戶手冊中。同時,我們可以通過文本分析,從問題報告中提取用戶遇到的問題並作為 OLAP 多維立方體的一個維度,結合結構化數據進行分析。
案例簡介
在接下來的章節中,我們將通過一個虛擬的電信公司的例子介紹如何使用 DB2W 9.5 提供的文本分析工具實現文本分析。
某電信公司提供移動電話業務,用戶在使用移動電話業務前需要到電信公司辦理開戶手續。此電信公司希望了解用戶的個人興趣愛好對於離網傾向的影響,以及各類用戶的特征。因此,開戶時,在記錄新用戶的個人信息以及將使用的各種業務的同時,電信公司會對新用戶進行問卷調查,以了解新用戶的興趣愛好。
用戶開通移動電話業務後,電信公司會記錄用戶的每次通話信息,包括通話類型、通話時長等信息。這些信息將在多維分析中使用。
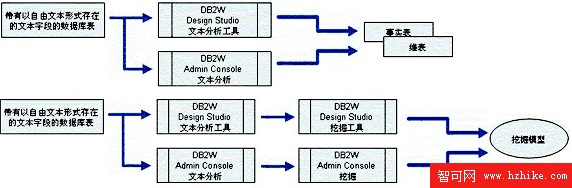
文本分析與挖掘及 OLAP 應用的結構
在 DB2W 中,文本分析與數據挖掘及 OLAP 分析的關系如下圖 2 所示。
圖 2. 文本分析與數據挖掘和 OLAP 應用
如何使用 DB2W 構建文本挖掘應用以及結合文本分析構建 OLAP 應用將在本系列文章的第二篇和第三篇中分別介紹。
使用 DB2W 的非結構化分析工具實現文本分析
文本分析理論
信息提取是信息獲取的類型之一,其目標是自動提取結構化信息。信息提取的典型任務包括:
命名實體識別,識別實體的名字,如組織、產品名稱、地名等;
識別針對同一對象的一連串名字短語;
術語抽取,尋找與某一主題相關的術語;
從文本中找出對一個人、產品或服務的正面或負面的描述。
對於上述的信息提取任務,有多種算法可以實現,每一種算法都適用於不同的商業問題。
基於規則:通過制定模式提取概念,如電話號碼、郵件地址等;
基於列表:通過枚舉與提取對象相關的詞提取概念,如人名、產品名稱、地名等;
其他算法:使用自然語言處理,機器學習,統計方式,或者是上述方法的綜合提取概念。
DB2W-UA 提供了基於規則和基於列表的信息提取方式。在 DB2W 中,基於規則的信息提取是通過規則文件實現的,我們要在規則文件中為希望從文本中提取的一個或多個概念類型定義查找模式;基於列表的信息提取由字典實現,我們可以在字典中列出與分析主體相關的所有可能情況。
使用 DB2W-UA 實現文本分析
本文采用的數據是基於已裝載到數據倉庫中的數據。這些數據是通過 ETL 過程每天從操作型環境中加載到數據倉庫中的用戶信息和通話詳單。
為了使用文本分析工具,在安裝 DB2W 時,選擇非結構化分析組件 (Unstructured TextAnalysis plug-ins 和 Unstructured Analysis Runtime)。請參照
http://www.ibm.com/software/data/db2/dwe/features.Html 安裝 DB2W 全套產品。
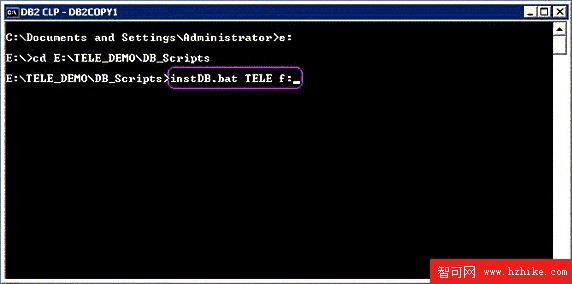
打開運行窗口 (Start -> Run),鍵入 db2cmd 調用 DB2 命令窗口,切換到附件的保存目錄,執行批處理文件 instDB.bat 並指定要生成的數據庫名字及存儲該數據庫的地方,生成本文中所使用的數據庫表及數據,如圖 3 所示。
圖 3. 命令窗口
打開 Design Studio (Start -> All Programs -> IBM DB2 Data Warehouse Edition V9.5 -> DB2COPY1 -> Design Studio),指定一個工作空間,如:C:workspace。Design Studio 打開後,關閉歡迎界面。新建一個數據倉庫項目 (File -> New -> Other…-> Data Warehouse Project),輸入項目名,如 TELE_DEMO。
數據探查
在進行文本分析前,我們必須對所要分析的文本字段的內容、相關數據分布以及值缺失狀況等有所了解,這樣將有助於我們選擇有效數據作進一步的分析。
在 Design Studio 中,我們可以通過數據探查 (Data Exploration) 獲得上述信息。從數據庫資源管理器中調用數據探查工具,如圖 4。
圖 4. 數據探查
數據探查的結果顯示了文本字段所在數據庫表的樣本數據 (Sample Content),文本統計信息 (Text Statistics),以及數據庫表中結構化數據的多變量分布狀況 (Multivariate Distribution)。
圖 5. 樣本數據
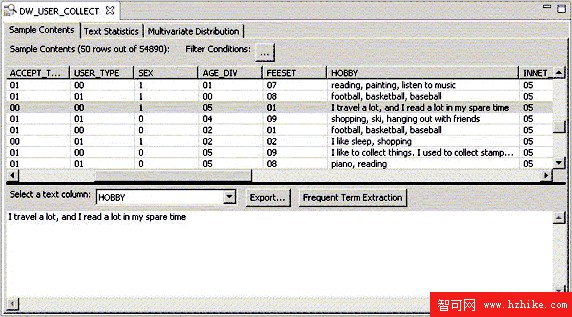
圖 6. 文本統計
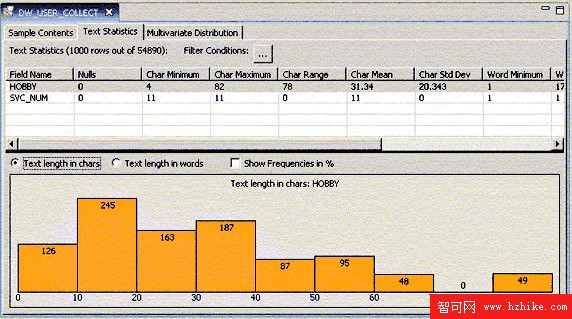
通過數據探查,我們對需要分析的文本內容有了表面的感性認識。但是,我們不清楚文本中有哪些信息類型以及術語的出現頻率。為了對文本信息有更為深入的了解,DB2W 提供了術語抽取功能(Frequent Term Extraction)。
在樣本內容頁中,點擊按鈕 < 抽取常用術語 >(Frequent Term Extraction)。在新建常用術語抽取向導中輸入文件的名字(如 HOBBY_FRE_TERM)。為了抽取常用術語,我們需要指定下列內容:
包含要分析文本的表所在的數據庫連接;
選擇包含要分析的文本的表及包含要分析的文本列;
指定輸入文本的語言及采樣率;
創建或選擇術語必須匹配的詞性模式。
從數據探查中我們發現用戶在填寫興趣愛好時大多使用名詞和動詞,有些是由多個詞性組成的詞組。常用術語抽取向導中已默認提供名詞(Noun)和動詞(Verb)兩種模式,為了提取由多個詞性組成的詞組,我們需要創建模式“任意 - 名詞”(Arbitrary-Noun)。在選擇抽取模式一頁中,點擊 < 新建 >(New),在彈出的新建詞性模式對話框中,點擊按鈕 <Arbitrary> -> <Noun>。如圖 7 所示。
圖 7. 新建詞性模式
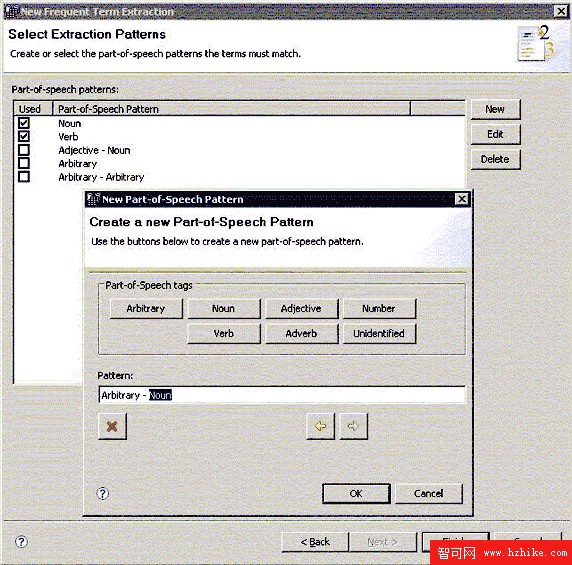
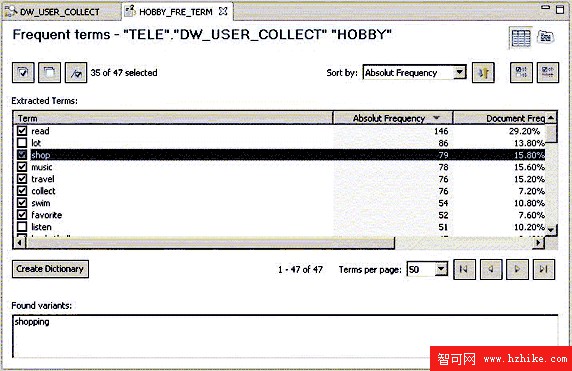
新建的模式會列在詞性模式列表中,而且默認選中。點擊 < 完成 > 後,常用術語抽取器就會根據選擇的詞性分析指定文本列中的所有信息。所需要的分析時間由文本的數量及大小決定。分析結果將會按照術語在文本中出現的絕對頻率排列。選中某一術語,與這一術語相關的變量就會顯示。
圖 8. 常用術語分析結果
文本分析准備——分析文件的創建
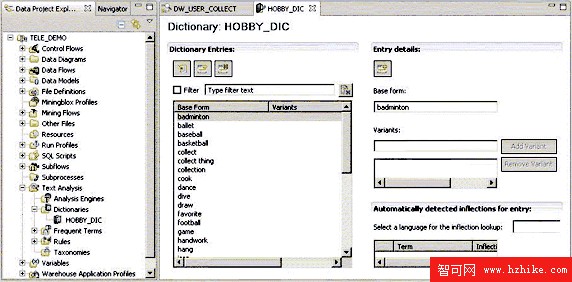
了解需要分析的文本後,下一步就是要定義記錄了興趣愛好關鍵字字典 (Dictionary)。我們可以從常用術語抽取結果選擇用於感興趣的術語生成字典文件,也可以手工建立字典。我們還可以導入第三方提供的字典或其他工程中的字典,也可以從數據庫表或文件中導入。
在常用術語抽取結果中,取消選中那些與期望分析無關的詞,如 lot, favorite, listen 等。點擊 < 創建字典 >(Create Dictionary)。在創建字典向導中輸入字典的名字,如 HOBBY_DIC。在數據項目資源管理器中,展開工程 TELE_DEMO,雙擊在字典文件夾下的字典文件 HOBBY_DIC 打開字典編輯器。
圖 9. 生成字典
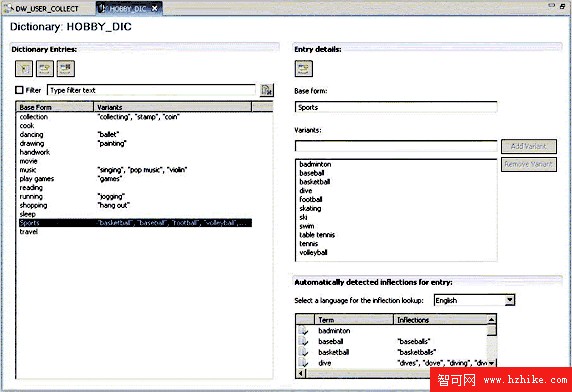
由於生成的字典不能自動匹配意義相近的詞,或者缺少了我們感興趣的關鍵字,我們需要對生成的字典做一些手工的修改。例如,jogging 和 running 都是指跑步,可以歸為一類;各種球類運動也可以歸為一類。修改後的 HOBBY_DIC 如圖 10。
圖 10. 修改後的字典
除了字典外,DB2W 提供了通過規則對分析文本的方法,以及支持使用第三方提供的符合 UIMA(Unstructured Analysis Management Architecture)規范的分析引擎。規則的建立主要基於正則表達式(Regular Expression)。規則編輯器中提供了正則表達式構建器幫助大家構建正則表達式以及驗證表達式的正確性。規則文件的建立方法將在後續的文章中介紹。
創建挖掘流
現在,我們可以利用新建的字典從文本中搜索關鍵字並將非結構化信息轉換為結構化的數據。
新建挖掘流,從 Design Studio 主菜單中選擇 File -> New -> Mining Flow。在新建文件向導中輸入挖掘流的名字,選擇 Work against database(Online) 選項,並在下一步中指定要連接的數據庫連接 (TELE)。分別建立挖掘流 MF_HobbyDimension 和 MF_HobbyFact。
挖掘流 MF_HobbyDimension 的目標是通過文本分析,將文本字段中的用戶興趣愛好抽取出來生成維表,以用於 OLAP 分析模型的創建。完成後的 MF_HobbyDimension 如圖 11。
圖 11. 挖掘流 MF_HobbyDimension

具體步驟為:
從操作符面板上拖拽 Table Source 到挖掘流畫板上。在打開的 Select Database Table 窗口中選擇數據庫表 TELE.DW_USER_COLLECT
從操作符面板上拖拽 Dictionary Lookup 到挖掘流畫板上,連接 Table Source 和 Dictionary Lookup。在 PropertIEs 視圖中設置 Dictionary Lookup 的屬性。
在 Dictionary Settings 頁中選擇要分析的文本列 HOBBY,選擇文本所對應的語言 English(United States);
在 Analysis Results 頁中,選擇字典 HOBBY_DIC 及注釋類型 HOBBY_DIC;刪除結果列表中除 BASEFORM 的所有行,將列名改為 HOBBY。如圖 12。
圖 12. 分析結果屬性設置
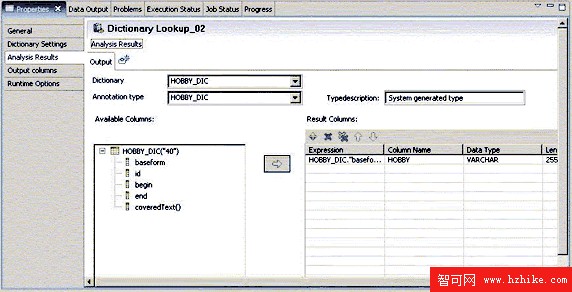
結果列表中 BASEFORM 對應了字典中定義的基本格式 (Base Form),在文本中查找到的與字典中定義的變體將以其對應的基本格式作為結果;ID 是指對應基本格式的編號;BEGIN 和 END 標示了查找到的術語在文本中的起止位置;COVEREDTEXT 指的是在文本中查找到的變體。
例如對字典
表 1. 字典示例
Base Form Variant Instrument piano, violin, guitar Ball games football, baseball
對於文本 I like football,分析結果為:
表 2. 分析結果示例
BASEFORM ID BEGIN END COVEREDTEXT Ball games 2 8 15 football
在 Output Columns 頁中,把 USER_ID 和 MONTH 從可用列表加到結果列表中。由於分析結果可能會將一行數據拆分為多行。如帶有文本 I like football and baseball 的一行數據,將會由於有 2 個匹配的術語 (football,baseball) 而別分為 2 行數據。在 Output Columns 中選擇的字段可用於識別這些來源於同一條數據的多條數據。
不同的用戶會有相同的興趣愛好,因此單純的文本分析結果會有重復,通過 Distinct 操作符可以去除重復的結果。
從操作符面板上拖拽 Distinct 到挖掘流畫板上,連接 Dictionary Lookup 和 Distinct。在 Distinct 的屬性視圖中,轉到 Column Select 頁,並把 HOBBY 加到選擇列表中。
為了生成興趣愛好維表,我們要給各種 HOBBY 指定唯一標識。
從操作符面板上拖拽 Select List 到挖掘流畫板上,連接 Distinct 和 Select List。在 Select List 屬性頁中,在結果列表中,刪除列名為 USER_ID 和 MONTH 的行;新增一列並移至列表的最頂端;修改新增列的名字為 HOBBY_ID,將 Expression 設置如表 3
表 3. Expression 設置
Case when (rownumber() over() < 10)
then ('0' || char(rownumber() over()))
else char(rownumber() over())
end
右鍵點擊 Select List 的 Output 輸出口,從上下文菜單中選擇 Create Suitable Table…並指定生成表的模式及名字為 TELE 和 DIM_HOBBY。
挖掘流 MF_HobbyFact 的目標是通過文本分析,結合上面建成的興趣愛好維表生成帶有興趣愛好信息的事實表。完成後的 MF_HobbyFact 如圖 13。
圖 13. 挖掘流 MF_HobbyFact
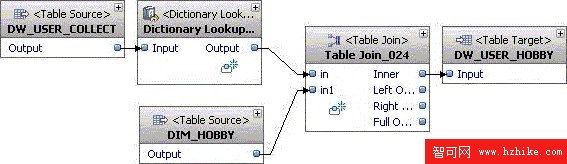
挖掘流 MF_HobbyFact 的操作步驟和 MF_HobbyDimension 相似。將 Dictionary Lookup 和 DIM_HOBBY 連接到 Table Join 後,按照表 4 設置 Condition 屬性。
表 4. Condition 屬性
IN_024.HOBBY = IN1_024.HOBBY
在 Select List 頁中,刪除 Column Name 為 HOBBY 和 HOBBY_1 的行,選中 HOBBYID 並上移到 USER_ID 下。右鍵點擊 Table Join 的 Inner 輸出口,從上下文菜單中選擇 C reate Suitable Table…並指定生成表的模式及名字為 TELE 和 DW_USER_HOBBY。
創建控制流
下面創建控制流 CF_HobbyCreation 用於控制維表及事實表數據的生成。
新建控制流,從 Design Studio 主菜單中選擇 File -> New -> Control Flow。在新建文件向導中輸入控制流的名字。完成後的控制流 CF_HobbyCreation 如圖。
圖 14. 控制流 CF_HobbyCreation
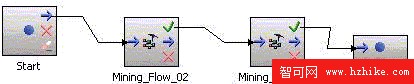
具體步驟為:
從操作符面板中拖拽 Mining Flow 到挖掘流畫板上,連接 Start 和 Mining Flow,在 Mining Flow 的屬性頁中,點擊圖標 <…>,選擇挖掘流 MF_HOBBY_DIMENSION。再次使用 Mining Flow 操作符,選擇挖掘流 MF_HOBBY_FACT,並連接 2 個 Mining Flow 操作符。從操作符面板上選中 End 並拖拽到控制流畫板上,連接 Mining Flow 和 End。
數據倉庫應用的生成、部署和應用
我們可以通過控制流生成數據倉庫應用並部署到數據倉庫管理控制台中執行。
新建數據倉庫應用,從 Design Studio 主菜單中選擇 File -> New -> Data Warehouse Application。在新建文件向導中選擇當前工程;指定 HobbyCreate_APP 作為概要文件的名字;在控制流選擇中選擇控制流 CF_HobbyCreation;其余設置使用默認值。在 Package Generation 頁中,選擇存儲生成文件的目錄,點擊 <Finish>。HobbyCreate_APP.zip 就會生成在指定的目錄中。
接下來,我們要將生成的 TELE_APP.zip 文件部署到 DB2 數據倉庫管理控制台中。
在 IE 浏覽器中輸入 URL http://localhost:9060/ibm/console,輸入用戶名和密碼。
在控制台中,展開 DB2 Warehouse -> SQL Warehousing -> Data Warehouse Applications,點擊菜單 Deploy Warehouse Applications,選擇上面步驟中生成的應用 HobbyCreate_APP.zip,如圖 15 所示;
圖 15. 部署應用
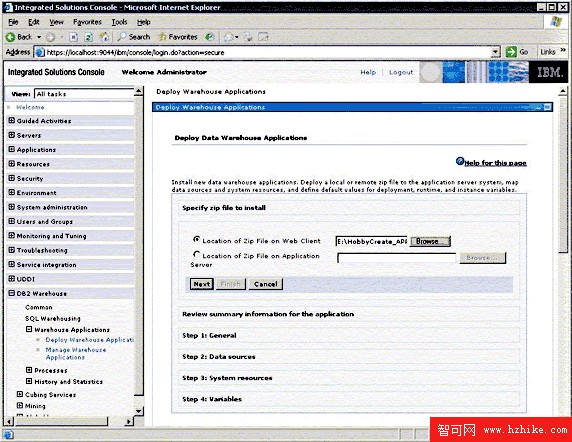
點擊 <Next> 直到進入 General 頁。在 General 頁中,指定應用的 Home 目錄 ( 如 c:/home)、日志目錄 ( 如 c:/logs) 及工作目錄 ( 如 c:/temp)
Data Source 頁列出了當前可用的數據倉庫應用數據源。點擊 <Create> 進入 Create Data Source 頁面,輸入顯示的名字 TELE,取消選中 Managed by Websphere,點擊 <Next>;設置連接信息:JNDI Name 為 jdbc/tele,Database Name 為 TELE,Database Alias 為 TELE,Host Name 為 localhost,Port Number 為 50000;在下一個設置單元中,輸入數據庫連接的用戶名和密碼,點擊 <Finish> 返回應用發布。選擇 jdbc/tele 為 TELE 對應的 Runtime JNDI Name;在後續的頁面中均使用默認值,直至部署結束。如果部署成功,應該會顯示在管理數據倉庫應用列表中並有成功安裝應用的信息。
部署成功後,我們就可以在控制台中執行該分本分析應用。
進入 DB2 Warehouse -> SQL Warehousing -> Processes -> Run Processes,選中應用 HobbyCreation 點擊 <Start>。運行完成後,我們可以查看數據庫表 DIM_HOBBY 和 DW_USER_HOBBY 中是否生成了相應的數據。
總結
本文主要介紹了文本分析的基本概念以及如何使用 DB2W 9.5 的非結構化分析工具創建用於文本分析的挖掘流、控制流和數據倉庫應用。
源代碼下載:http://FlashvIEw.ddvip.com/2008_12/dm-0801liangpp.zip