DB2® 9 提供了 pureXML 存儲並給出 XQuery 和 SQL/XML 作為查詢語言。XML 索引是高查詢性能所必需的,但是其在查詢評估方面的使用取決於查詢謂詞的表示方式。本文以一致的方式給出了一組指導原則,用於編寫 XML 查詢和創建 XML 索引,從而如期加快查詢速度。還介紹了需要在 XML 查詢執行計劃中查找的內容,以便檢測性能問題,然後找到解決這些問題的方法。可下載的 “備忘單” 概括了最重要的一些指導原則。
簡介
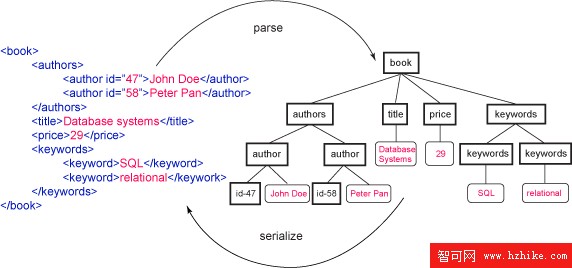
DB2 9 提供了 pureXML 存儲以及 XML 索引、作為查詢語言的 XQuery 和 SQL/XML、XML 模式支持、對實用程序(如 Import/Export 和 Runstats)的 XML 擴展。正如在關系查詢中一樣,索引對於高性能的 XQuery 和 SQL/XML 是至關重要的。DB2 允許在 XML 列上定義 path-specific XML 索引。這意味著可以使用它們來索引頻繁在謂詞和連接中使用的所選擇的元素和屬性。例如,使用圖 1 中的示例數據,基於 author ID,可以使用下面的索引 idx1 對表 books 的 XML 列 bookinfo 中的所有文檔進行查找和連接。
create table books(bookinfo XML);
create index idx1 on books(bookinfo) generate keys
using XMLpattern '/book/authors/author/@id' as sql double;
圖 1. 以文本(連續)格式和解析(分層)格式表示的示例 XML 文檔
由於 DB2 不強制要求將單個 XML 模式與 XML 列中的所有文檔相關聯,所以特定元素和屬性的數據類型事先是未知的。因此,要求為每個 XML 索引指定一個目標類型。稍後,您將在本文了解到為什麼類型很重要。可以使用的 XML 索引數據類型如下:
VARCHAR(n):用於帶有字符串值的節點,已知字符串值的最大長度為 n。
VARCHAR HASHED:用於帶有字符串值的節點,字符串值的長度為任意長度。該索引包含實際字符串的散列值,只能用於等式謂詞,不能用於范圍謂詞。
DOUBLE:用於帶有任意數值類型的節點。
DATE and TIMESTAMP:用於帶有日期或時間戳值的節點。
VARCHAR(n) 索引的長度是一個強制約束。如果插入一個文檔,其中索引元素或屬性的值超過了最大長度 n,則插入操作將失敗。同樣,如果索引元素或屬性的值大於 n,則 VARCHAR(n) 索引的 create index 語句將失敗。
DOUBLE、DATE 或 TIMESTAMP 索引不是強制約束。例如,將 author ID 屬性上的索引 idx1 定義為 DOUBLE,是希望這些 ID 為數值。如果插入一個文檔,其中 author ID 的值為 “MN127”,它是非數型值的,則雖然仍將插入該文檔,但不會將 “MN127” 值添加到索引。這是因為 DOUBLE 索引只能評估數值謂詞,然而 “MN127” 值永遠不會匹配一個數值搜索條件。因此,索引中沒有該值是正確的。
您可以在 “Indexing XML Documents in DB2”(developerWorks,2006 年 5 月)中找到有關定義 XML 索引的更多詳細內容。下面在討論 XML 索引的使用時,也假定您熟悉查詢 DB2 中 XML 數據的基本概念。有關更多信息,請參考以前的文章:“用 SQL 查詢 DB2 XML 數據”(developerWorks,2006 年 3 月)和 “使用 XQuery 查詢 DB2 XML 數據”(developerWorks,2006 年 4 月)給出了介紹,“DB2 9 中的 pureXML:怎樣查詢您的 XML 數據?”(developerWorks,2006 年 6 月)給出了更多示例和詳細內容。
適合於 XQuery 和 SQL/XML 語句的 XML 索引
正如在關系查詢中一樣,索引對於高性能的 XQuery 和 SQL/XML 語句是至關重要的。當應用程序向 DB2 提交關系查詢或 XML 查詢時,查詢編譯器將比較查詢謂詞和現有的索引定義,然後確定是否存在可用索引用於執行查詢。該過程被稱為 “索引匹配”,並且為給定的查詢生成一組合適的索引(可能是空集)。將該組索引輸入到基於開銷的優化器,用來決定是否使用任何合適的索引。本文的專注於索引匹配,而不是優化器的索引選擇。在優化器決策方面,除了運行 “runstats” 來為優化器提供關於數據的准確的統計之外,所能做的事情不是很多。但卻有大量的工作可以做來確保索引匹配。
在關系查詢中,索引匹配通常是微不足道的。DB2 可以使用定義在單個關系列上的索引來響應此列上的任何等式謂詞或范圍謂詞。但是,對於 XML 列,這將更加復雜。關系列上的索引包含了此列的所有值,而 XML 索引僅包含那些同時匹配 XML 模式和索引定義中的數據類型的節點值。因此,僅當 XML 索引擁有 “正確的”數據類型並且至少包含滿足謂詞的所有 XML 節點時,該 XML 索引才能用於評估 XML 查詢謂詞。對於 XML 索引的合格性,有兩個主要要求:
XML 索引定義的限制等同於或低於查詢謂詞的限制(“容納”)。
索引的數據類型與查詢謂詞的數據類型相匹配。
本文說明了如何設計 XML 索引和查詢以確保符合上述要求,以及如何避免常見錯誤。先從了解查詢執行計劃開始。DB2 中現有的解釋工具(例如 Visual Explain 和 db2exfmt)可用於查看 XQuery 和 SQL/XML 的查詢執行計劃,正像它們在傳統 SQL 中的作用一樣。
XML 查詢評估:執行計劃和新運算符
為了執行 XML 查詢,DB2 9 引入了三個新的內部查詢操作符,名為 XSCAN、XISCAN 和 XANDOR。這些新操作符和現有的查詢操作符(例如 TBSCAN、FETCH 和 SORT)允許 DB2 生成 SQL/XML 和 XQuerIEs 的執行計劃。現在看一下這三個新操作符,以及它們與 XML 索引在執行計劃中是如何工作的。
XSCAN(XML 文檔掃描)
DB2 使用 XSCAN 操作符來遍歷 XML 文檔樹,如需要,還將評估謂詞和提取文檔片斷和值。XSCAN 不是“XML 表掃描”,但在表掃描之後,它可以出現在執行計劃中,用來處理每個文檔。
XISCAN(XML 索引掃描)
類似於現有的用於關系索引的關系索引掃描操作符 (IXSCAN),XISCAN 操作符在 XML 索引上執行查找或掃描。XISCAN 使用值謂詞作為輸入,例如類似於 /book[price = 29] 或 where $i/book/price = 29 的路徑值對。它將返回一組行 ID 和節點 ID。行 ID 用來識別包含合格文檔的行,而節點 ID 用來識別這些文檔中的合格節點。
XANDOR (連接 XML 索引)
XANDOR 操作符通過操作多個 XISCAN,來同時評估兩個或多個等式謂詞。它將返回那些滿足所有謂詞的文檔的行 ID。
下面看一個示例查詢,分別了解不帶索引、帶一個索引和帶多個索引的執行計劃:
XQUERY
for $i in db2-fn:XMLcolumn("BOOKS.BOOKINFO")
where $i/book/title = "Database systems" and $i/book/price = 29
return $i/book/authors
create index idx1 on books(bookinfo) generate keys
using XMLpattern '/book/title' as sql varchar(50);
create index idx2 on books(bookinfo) generate keys
using XMLpattern '/book/price' as sql double;
在圖 2 中可以看到該查詢的不同執行計劃(簡化了 db2exfmt 的輸出)。因為執行計劃中的邏輯流是自下而上、從左到右,所以看此類執行計劃時,最好是從樹中左下方的操作符開始。
如果該查詢中沒有合適的索引用於謂詞,則使用最左邊的計劃 (a)。表掃描操作符 (TBSCAN) 將讀取表 “BOOKS” 中的所有行。對於每一行,嵌套循環連接 (NLJOIN) 操作符把指向相應的 XML 文檔的指針傳遞給 XSCAN 操作符。同樣地,NLJOIN 並沒有充當擁有兩個輸入的標准連接,而是協助 XSCAN 操作符來訪問 XML 數據。XSCAN 操作符將遍歷每個文檔、評估謂詞,如果滿足謂詞,則提取 “authors” 元素。RETURN 操作符將完成查詢執行,並將查型結果返回到 API。
圖 2. 三個執行計劃:(a) 沒有索引、(b) 一個索引、(c) 兩個索引
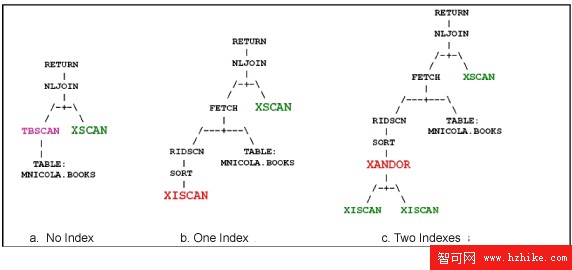
如果有一個索引用於一個或兩個謂詞,例如 /book/price 上的索引 idx1,則將看到類似於圖 2 中計劃 (b) 的執行計劃。XISCAN 使用路徑值對(/book/price,29) 來檢查索引,並返回其中價格為 29 的文檔的行 ID。對這些行 ID 進行分類,以便刪除相同項(如果有),並優化表的後續 I/O。然後行 ID 掃描 (RIDSCN) 操作符將掃描這些行,觸發行預取,並將行 ID 傳遞到 FETCH 操作符。對於每一個行 ID,FETCH 操作符將讀取表中相應的行。該計劃的好處在於僅對表中的一小部分行進行檢索,即僅對 “price” 為 29 的行進行檢索。這遠遠低於全部表掃描(即讀取每行)的開銷。對於所獲取的每一行,XSCAN 操作符將處理相應的 XML 文檔。它將在 “title” 上評估謂詞,如果滿足謂詞,則提取 “authors” 元素。可能存在這樣一些文檔,其中第二個謂詞不為真,那麼 XSCAN 仍將執行一些操作來排除這些文檔。因此,如果第二個謂詞也用索引來替代,將會獲得更好的查詢性能。
如果有用於兩個謂詞的索引,則可以參看圖 2 中的計劃 (c)。該計劃使用兩個 XISCAN,分別用於每一個謂詞和索引。XANDOR 操作符使用這些 XISCAN 來輪流檢查兩個索引,以便有效地找到同時匹配兩個謂詞的文檔的行 ID。FETCH 操作符僅對這些行進行檢索,因此將表的 I/O 減到最少。隨後對於每一個文檔,XSCAN 將提取 “authors” 元素。如果謂詞在路徑中包括了 // or *,或者使用了范圍比較(例如 < 和 >),則用索引 AND'ing (IXAND) 操作符代替 XANDOR。從邏輯上講,這兩個操作符執行了相同的操作,只不過是用於不同類型的謂詞且使用不同的優化方法。
優化器可以決定不使用索引,即使該索引是可以使用的。例如,如果第二個索引沒有有效減少表中需要檢索的行數,例如訪問索引所需的開銷比節約表的 I/O 更重要,則優化器可能選擇計劃 (b) 而不是計劃 (c)。然而,需要確保優化器考慮了所有合適的索引,從而以最低的開銷和最短的執行時間來選擇計劃。換句話說,要遵守 XML 索引合格性的兩個要求:
XML 索引至少包含了滿足謂詞的所有 XML 節點。
查詢謂詞中的數據類型與索引定義是兼容的。
XML 索引和查詢謂詞中的通配符
通配符 // 和 * 可以影響索引和查詢謂詞之間的包含關系。這是因為路徑表達式是不同的,例如 /book/price 和 //price。路徑 /book/price 識別了所有 price 元素,它們是元素 “book” 的直接子元素。而路徑 //price 識別了 XML 文檔的所有層次上的 price 元素。因此 /book/price 識別的元素是 //price 所指定的元素的子集。即 //price“包含了 ”/book/price,但反之則不行。
現在,看一下通配符是如何影響索引的合格性的。以下面的查詢為例。表 1 中演示了其 where 語句的四種變化。
XQUERY
for $i in db2-fn:XMLcolumn("BOOKS.BOOKINFO")
where $i/book/price = 29
return $i/book/authors
表 1 最右側的兩列表示兩個可選擇的索引定義,表中各行展示了謂詞可以 (+) 或不可以 (-) 由這兩個索引進行評估。下面浏覽一下表 1 中的行,來研究每個謂詞的索引合格性。
對於第一個謂詞,因為它僅包含了 “book” 的直接子元素 “price”,所以 /book/price 上的索引是不合格的。索引沒有包含更深層次的 “price” 元素,表中可能存在該元素且可能與謂詞路徑 $i//price 相匹配。因此,如果 DB2 在 /book/price 價格上使用索引,則可能返回不完全的結果。第二個索引 //price 是合格的,因為它包含了文檔各層次的所有 price 元素,正如謂詞所要求的。
第三個謂詞使用了星號 (*) 作為通配符,這樣它將查找 “book” 下值為 29 的任何子元素。不僅是 “price” 元素可以滿足該謂詞。例如,元素 /book/title 的值為 29 的文檔就是一個有效匹配。但是表 1 中的兩個索引都不包括 title 元素。由於 DB2 可能為該謂詞返回不完全的結果,因此兩個索引均不能使用。
表 1:索引合格性與 XML 索引和謂詞中的通配符
# 謂詞/索引定義 ...using XMLpattern '/book/price' as sql double; ...using XMLpattern '//price' as sql double; 1 where $i//price = 29 - + 2 where $i/book/price = 29 + + 3 where $i/book/* = 29 - - 4 where $i/*/price = 29 - +
第四個謂詞 $i/*/price = 29 將查找任何根元素下的 price 元素,而不僅僅是在 “book” 元素下的。如果存在具有路徑 /journal/price 的文檔,則可能會滿足謂詞 $i/*/price = 29,但不會被包括在 /book/price 上的索引中。由於 DB2 可能將面臨返回不完全查詢結果的風險,因此不能使用該索引。但是 //price 上的索引包含任何 price 元素,與根元素無關。
在 nutshell 中,DB2 查詢編譯器必須始終能夠檢驗索引的限制等同於或低於謂詞的限制,以便包含謂詞正在查找的所有內容。
應意識到,在索引定義中使用通配符可能會不經意地索引更多節點(多於所需節點)。只要有可能,建議使用索引定義和查詢中所需元素或屬性的准確路徑,而不使用通配符。諸如 //* or //text() 這類很普通的 XML 索引模式是可以接受的,但是應慎重使用。//* 上的索引甚至會索引非末端元素,非末端元素通常是沒有用的且很容易超出 Varchar(n) 索引的長度限制。
XML 索引和查詢謂詞中的名稱空間
需要注意 XML 索引合格性是否包含了名稱空間。首先,如果表的 XML 文檔包含了名稱空間,則索引定義必須考慮名稱空間。這再次涉及到索引/謂詞的容納性。以下面的 XML 文檔和索引定義為例:
<bk:book XMLns:bk="http://mybooks.org">
<bk:title>Database Systems</bk:title>
<bk:price>29</bk:price>
</bk:book>
CREATE INDEX idx3 ON books(bookinfo)
GENERATE KEYS USING XMLPATTERN '/book/price' AS SQL DOUBLE;
因為將索引 idx3 定義為 /book/price 元素的索引,具有空的名稱空間,所以該索引未包含此示例文檔的任何索引條目。但是,以下任一索引定義都可適當地用於索引 price 元素:
CREATE INDEX idx4 ON books(bookinfo) GENERATE KEYS USING XMLPATTERN
'declare namespace bk="http://mybooks.org"; /bk:book/bk:price' AS SQL DOUBLE
CREATE INDEX idx5 ON books(bookinfo) GENERATE KEYS USING XMLPATTERN
'declare default element namespace "http://mybooks.org"; /book/price' AS SQL DOUBLE
CREATE INDEX idx6 ON books(bookinfo) GENERATE KEYS USING XMLPATTERN
'/*:book/*:price' AS SQL DOUBLE
索引 idx4 顯式地聲明了名稱空間和前綴以匹配文檔。索引 idx5 將名稱空間聲明為默認名稱空間,由於名稱空間暗含了前綴,因此在 XML 模式 /book/price 中沒有使用前綴。索引 idx6 僅使用了通配符以匹配任何名稱空間。用 XQuery 語句表示謂詞時,可以使用相同的選項:
查詢 4:XQUERY declare namespace bk="http://mybooks.org";
for $b in db2-fn:XMLcolumn("BOOKS.BOOKINFO")/bk:book
where $b/bk:price < 10
return $b
查詢 5:XQUERY declare default element namespace "http://mybooks.org";
for $b in db2-fn:XMLcolumn("BOOKS.BOOKINFO")/book
where $b/price < 10
return $b
查詢 6:XQUERY for $b in db2-fn:XMLcolumn("BOOKS.BOOKINFO")/*:book
where $b/*:price < 10
return $b
表 2 中每一行用於一個查詢,每一列分別用於前面定義的索引 idx3 到 idx6。可以先觀察一下對表 2 。首先,不帶名稱空間的 idx3 不能用於任何考慮了名稱空間的查詢。其次,可以發現查詢 4 和查詢 5 對應的行擁有同樣的條目,且索引 idx4 和 idx5 對應的列也擁有同樣的條目。這是因為顯式的名稱空間定義和默認的名稱空間定義在邏輯上是相同的,僅僅是同一個事物的不同說法。可以使用其中任一個,而不會影響到索引匹配。帶有名稱空間通配符的索引 idx6 對於所有示例查詢都是合格的,它甚至可以用於不帶名稱空間的謂詞,例如 $b/price < 10。索引 idx6 還是與查詢 6 中的謂詞相匹配的惟一索引。索引 idx4 和 idx5 包含了用於一個特定名稱空間的索引條目,但是因為查詢 6 是查找任何名稱空間中的書籍價格,所以這兩個索引不能用於查詢 6。因此,違反了包容性要求。
表 2:索引合格性與 XML 索引和謂詞中的名稱空間
# 查詢/索引定義 idx3(沒有名稱空間) idx4(顯式的名稱空間) idx5(默認的名稱空間) idx6(名稱空間通配符) 1 查詢 4(顯式的名稱空間) - + + + 2 查詢 5(默認的名稱空間) - + + + 3 查詢 6(名稱空間通配符) - - - +
XML 索引和查詢謂詞中的數據類型
除了索引或謂詞與通配符和名稱空間的包容性之外,索引合格性的第二個要求是謂詞和索引的數據類型必須匹配。在所有上述示例中,/book/price 元素始終作為 DOUBLE 進行索引。但是,也可以將書籍價格作為 VARCHAR 進行索引,如表 3 所示。不過,請注意值謂詞也擁有由文字值類型確定的數據類型。雙引號中的值始終是字符串,而不帶引號的數字值被認為是數字。正如您在表 3 中所看到的,字符串謂詞只能由 VARCHAR 類型的 XML 索引進行評估,而數值謂詞只能由 DOUBLE 類型的索引進行評估。
關系索引的數據類型始終由索引列的類型來確定。不過,由於 DB2 不強制要求將 XML 模式與 XML 列相關聯,所以元素或屬性的數據類型不是預先確定的。因此,每個 XML 索引需要一個目標類型。而且類型是很重要的。假定 price 元素擁有值 9。字符串謂詞 "9" < "29" 為假,而數值比較 9 < 29 為真。這裡強調了如果想從語義上進行正確的數值比較,則應使用 DOUBLE 索引。最好將 “price” 元素作為 DOUBLE 進行索引。
表 3:XML 索引和謂詞中的數據類型
# 謂詞或索引定義 ...using XMLpattern '/book/price' as sql double; ...using XMLpattern '/book/price' as sql varchar(10); 1 where $i/book/price < "29" - + 2 where $i/book/price < 29 + -
使用適於 XML 連接謂詞的索引
在上述示例中,看到了包括文字值的值謂詞。這些文字值決定了比較的數據類型。通常此類決定不適用於連接謂詞。假定有一個表 “authors”,以 XML 格式表示詳細的作者信息,包括出現在 book 數據中的 author ID。現在想使用連接來檢索詳細的 author 數據,且僅對 books 表中書籍的 authors 進行檢索。在 author ID 上定義索引看起來很有用:
create table books (bookinfo XML);
create table authors (authorinfo XML);
create index authorIdx1 on books(bookinfo) generate key using
XMLpattern '/book/authors/author/@id' as sql double;
create index authorIdx2 on authors(authorinfo) generate key using
XMLpattern '/author/@id' as sql double;
XQUERY
for $i in db2-fn:XMLcolumn("BOOKS.BOOKINFO")
for $j in db2-fn:XMLcolumn("AUTHORS.AUTHORINFO")
where $i/book/authors/author/@id = $j/author/@id
return $j;
該查詢檢索了所需的作者信息,但是沒有將索引用於連接處理。請注意 author ID 上的連接謂詞沒有包含文字值,該文字值將表明比較的數據類型。因此,DB2 必須考慮匹配任何數據類型的 author ID。例如,考慮表 4 中的 book 和 author 數據。Author John Doe 有一個數值 ID 值 (47),而 author Tom Noodle 有一個非數值 ID 值 (TN28)。在其他表中二者都有有效匹配。因此,二者必須包括在連接結果中。但是,如果 DB2 使用數值索引 authorIdx1 或 authorIdx2,則不會找到 author ID “TN28”,並且會返回一個不完全的結果。因此,DB2 不能使用那些索引,而是會采取表掃描來確保正確的查詢結果。
表 4:示例 book 和 author 數據
Book
<book>Author
<authors>
<author id="47">John Doe</author>
</authors>
<title>Database Systems</title>
<price>29</price>
</book>
<book>
<authors>
<author id="TN28">Tom Noodle</author>
</authors>
<title>International Pasta</title>
<price>19.95</price>
</book><author id="47">
<name>John Doe</name>
<addr>
<street>555 Bailey Av</street>
<city>San Jose</city>
<country>USA</country>
</addr>
<phone>4084511234</phone>
</author>
<author id="TN28">
<name>Tom Noodle</name>
<addr>
<street>213 Rigatoni Road</street>
<city>Toronto</city>
<country>Canada</country>
</addr>
<phone>4162050745</phone>
</author>
在兩種情況下,您可以幫助 DB2 來使用 DOUBLE 索引:
非數值 author ID 的確存在,但是希望忽略它們。
非數值 author ID 不存在。
下面看一下這兩種情況。
如果想忽略非數值 author ID,則可以在查詢中指明,從而允許 DB2 使用 DOUBLE 索引。以下查詢明確地將連接謂詞的兩端轉換為 DOUBLE。這要求進行數值比較,並且顯然不接受非數值連接匹配。因此,DB2 可以使用 DOUBLE 索引用於快速連接處理。由於遇到非數字值時,DOUBLE 轉換將失敗,因此應添加謂詞,將非數值 author ID 排除在兩個表之外。例如,該查詢只考慮大於 0 的數值 ID。
XQUERY
for $i in db2-fn:XMLcolumn("BOOKS.BOOKINFO")
for $j in db2-fn:XMLcolumn ("AUTHORS.AUTHORINFO")
where $i/book/authors/author/@id > 0
and $j/author/@id > 0
and $i/book/authors/author/@id/xs:double(.) = $j/author/@id/xs:double(.)
return $j;
如果知道不存在非數值 author ID,則不需要這些額外的謂詞,查詢就像如下所示(仍使用 DOUBLE 索引):
XQUERY
for $i in db2-fn:XMLcolumn("BOOKS.BOOKINFO")
for $j in db2-fn:XMLcolumn ("AUTHORS.AUTHORINFO")
where $i/book/authors/author/@id/xs:double(.) = $j/author/@id/xs:double(.)
return $j;
由於該查詢沒有包含用來限制 books 或 authors 表的值謂詞,因此 DB2 必須在兩個表上執行表掃描,以便讀取所有 author ID。對於每個 author ID,使用索引來檢查該 ID 是否在另一個表中出現。這比不使用任何索引的兩個表掃描的嵌套循環連接要快得多。DB2 的基於開銷的優化器決定了要掃描的表以及通過索引要訪問的內容。表 5 展示了這兩個執行計劃。這兩個執行計劃也適用於采用 SQL/XML 編寫的同樣的連接,而 XMLEXISTS 謂詞的樣式決定了使用哪一個計劃:
查詢 1:select authorinfo
from books, authors
where XMLexists('$b/book/authors[author/@id/xs:double(.) =
$a/author/@id/xs:double(.) ]'
passing bookinfo as "b", authorinfo as "a");
查詢 2:select authorinfo
from books, authors
where XMLexists('$a/author[@id/xs:double(.) =
$b/book/authors/author/@id/xs:double(.) ]'
passing bookinfo as "b", authorinfo as "a");
在這兩個查詢中,方括號中表示了連接謂詞。查詢 1 中,方括號中的謂詞是以 $b 開始的表達式上的謂詞,表示是一個可以使用索引的 books 表的謂詞。因此,DB2 在 authors 上執行表掃描,然後使用索引 AUTHORIDX1 來檢查 books 表。如表 5 左側所示。
查詢 2 中,連接條件是以 $a 開始的表達式上的謂詞,即 authors 表的謂詞。因此,DB2 在 books 上執行表掃描,然後使用索引 AUTHORIDX2 來檢查 authors 表(如表 5 右側所示)。因此,編寫 XMLEXISTS 謂詞的方式可以影響連接順序,並決定 DB2 將在哪一個表使用表掃描而不是索引訪問。如果無法避免使用表掃描,則將其用在最小的表上。
表 5:XML 連接查詢的執行計劃,由 db2exfmt 產生
查詢 1
Rows
RETURN
( 1)
Cost
I/O
|
3.59881e-005
NLJOIN
( 2)
5410.62
743
/-------+-------
1.29454e-007 278
NLJOIN NLJOIN
( 3) ( 6)
4311.96 1098.66
570 173
/---+-- /-+
556 2.32831e-010 139 2
TBSCAN XSCAN FETCH XSCAN
( 4) ( 5) ( 7) ( 11)
106.211 7.5643 47.237 7.56421
14 1 34 1
| /---+---
556 139 556
TABLE: MATTHIAS RIDSCN TABLE: MATTHIAS
AUTHORS ( 8) BOOKS
15.2133
2
|
139
SORT
( 9)
15.2129
2
|
139
XISCAN
( 10)
15.1542
2
|
556
XMLIN: MATTHIAS
AUTHORIDX1
查詢 2
Rows
RETURN
( 1)
Cost
I/O
|
8.37914e-015
NLJOIN
( 2)
5410.63
743
/--------+--------
1.29454e-007 6.47269e-008
NLJOIN NLJOIN
( 3) ( 6)
4311.96 1098.67
570 173
/---+-- /---+--
556 2.32831e-010 139 4.65661e-010
TBSCAN XSCAN FETCH XSCAN
( 4) ( 5) ( 7) ( 11)
106.211 7.56429 47.2365 7.5643
14 1 34 1
| /---+---
556 139 556
TABLE: MATTHIAS RIDSCN TABLE: MATTHIAS
BOOKS ( 8) AUTHORS
15.2128
2
|
139
SORT
( 9)
15.2124
2
|
139
XISCAN
( 10)
15.1537
2
|
556
XMLIN: MATTHIAS
AUTHORIDX2
總結一下關於 XML 連接查詢的建議,通常將連接謂詞轉換為應使用的 XML 索引類型。否則,查詢語義不允許使用索引。如果將 XML 索引定義為 DOUBLE,則用 xs:double 轉換連接謂詞。如果將 XML 索引定義為 VARCHAR,則用 fn:string 轉換連接謂詞,如表 6 所示。
表 6:轉換連接謂詞以便允許使用 XML 索引
索引 SQL 類型 轉換連接謂詞時使用: 注釋 double xs:double 用於任何數值比較 varchar(n), varchar hashed fn:string 用於任何字符串比較 date xs:date 用於日期比較 timestamp xs:dateTime 用於時間戳謂詞
“between” 謂詞的索引支持
XQuery 沒有類似於關系查詢中 “between” 謂詞的專用功能或操作符。另外,當表達 “between” 條件時,需要注意 XQuery 一般比較謂詞的存在本質。
假定您想找到價格在 20 到 30 之間的書。直觀上您可能使用謂詞 /book[price > 20 and price < 30],但是它並沒有構成 “between 謂詞”。這表示如果您有一個 /book/price 上的索引,DB2 也無法在 20 到 30 之間執行索引的范圍掃描以便找到該價格范圍內的書。這是因為 book 文檔可能有多個 price 子元素,如以下示例所示:
<book>
<title>Database Systems</title>
<price currency="RMB">40</price>
<price currency="USD">10</price>
</book>
由於一般比較(>、<、=、<= 等等)有存在語義,如果存在值大於 20 的子元素 “price”,同時存在值小於 30 的子元素 “price”,則謂詞 /book[price > 20 and price < 30] 將選擇該 book 元素。這些子元素可以是同一個 “price” 元素或兩個不同的 “price” 元素。上述示例文檔滿足了謂詞,因為有一個高於 20 的價格,且還有一個低於 30 的(不同的)價格。但是,這兩個價格都不在 20 到 30 之間。
如果 DB2 在 20 到 30 之間使用單個索引范圍掃描,則會錯過該文檔,並返回不完全的查詢結果。或者 DB2 必須計算兩個索引掃描的交集,通常這樣做的開銷將相當高。執行計劃的差別如圖 3 所示。左側的執行計劃展示了索引 AND'ing 的執行計劃,DB2 必須考慮捕獲示例文檔。該計劃是無效的,因為兩個 XISCAN 可能產生相當多數量的行 ID,需要使用上述 IXAND 操作符從中排除許多 ID。原因是很多書價格高於 $20,同時還有很多價格低於 $30 的書。實際上,兩個組合的 XISCAN 產生的行 ID 多於表中的行。這需要 IXAND 操作符僅僅為了找到一個小交集而進行繁重的工作。
如果您的目的是要實現真正的 “between” 謂詞,則右側的執行計劃會更好一些,因為帶有啟動謂詞的單個范圍掃描僅傳遞匹配的行 ID。只有相當少的索引訪問且沒有索引 AND'ing,這樣整體性能將提高一個或兩個數量級 —— 取決於謂詞選擇。
圖 3:對比索引 AND'ing 和單個范圍掃描,評估一對范圍謂詞
RETURN
|
NLJOIN
|
/-+-
/
FETCH XSCAN
|
/---+---
/
RIDSCN TABLE:
| BOOKS
SORT
|
IXAND
|
/---+---
XISCAN XISCAN
price > 20 price < 30
RETURN
|
NLJOIN
|
/-+-
/
FETCH XSCAN
|
/---+---
/
RIDSCN TABLE:
| BOOKS
SORT
|
XISCAN
20 < price < 30
僅當 DB2 可以確定數據項是單個項且不是多於一項的序列時,相同數據項上的一對范圍謂詞才可以由 DB2 編譯器解釋為 “between”,並由單個索引掃描進行評估。換句話說,必須這樣來表示謂詞,即 between(> 和 <)的兩個部分始終用於相同的單個項。利用值比較(>、<、=)、self 軸或屬性可以實現上述要求。
值比較
如果知道某個 book 至多有一個 price 元素,則可以使用 XQuery 的值比較來編寫查詢,這迫使進行比較的操作數是單個數。例如,可以安全地將 /book[price > 20 and price < 30] 解釋為 “between”,且通過 price 索引的單個范圍掃描進行評估。如果出現某個 book 擁有多個 price 子元素,則運行時查詢將失敗,並產生錯誤。
Self 軸
除了值比較,還可以使用 self 軸(由點“.”表示)來表達 “between” 謂詞。表達式 /book/price[. > 20 and . < 30] 中的 self 軸確保將那兩個謂詞用於相同的 price 元素。由於 self 軸始終對單個值進行評估,因此上述表達式構成了 “between” 謂詞。該謂詞允許 book 擁有多個 price,但是要求所有 price 的取值在 20 到 30 之間。這種方式較之使用值比較的優勢在於不會有運行時錯誤的風險。
屬性
如果 book price 是屬性,則該屬性在每個 book 元素至多出現一次。在表達式 /book[@price>20 and @price<30] 中,范圍謂詞的操作數是單個數,因此 DB2 可以執行單個索引范圍掃描,來評估 “between”。
索引文本節點以及 XPath “/text()”
簡單回顧一下什麼是文本節點。圖 4 展示了示例文檔及其在 XML 數據模式中的分層格式。每個元素由元素節點表示,實際的數據值由文本節點表示。在 XML 數據模型中,將元素的值定義為該元素下子樹中所有文本節點的串聯。因此,元素 “book” 的值為 “Database Systems29”。最底層元素的值等於其文本節點,例如,元素 “price” 的值為 29。
圖 4:示例文檔的 XML 數據模型
<book>
<title>Database Systems</title>
<price>29</price>
</book>
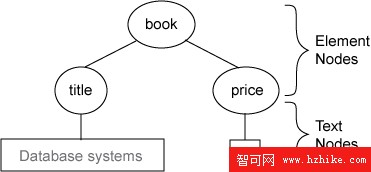
XPath 表達式 /book/price 和 /book/price/text() 是不同的。前者識別了元素節點 “price”,而後者指向值為 “29” 的文本節點。因此,下面兩個查詢將返回不同的結果。
XQUERY for $b in db2-fn:XMLcolumn("BOOKS.BOOKINFO")/book
return $b/price
XQUERY for $b in db2-fn:XMLcolumn("BOOKS.BOOKINFO")/book
return $b/price/text()
第一個查詢將返回完整的元素節點,即 <price>29</price>,而第二個查詢僅返回其文本節點值 29。如果在查詢謂詞中使用了不帶 /text() 的 XPath 表達式,例如下面查詢中的 $b/book,則 DB2 將自動使用元素的值來評估謂詞。由於 “book” 元素的值是 “Database Systems29”,因此該查詢將返回示例文檔作為有效匹配。
XQUERY for $b in db2-fn:XMLcolumn("BOOKS.BOOKINFO")
where $b/book = "Database Systems29"
return $b
但是,在下一個查詢中,將 /text() 添加到 where 子句的路徑中,將不會返回示例文檔。這是因為文本節點不是直接位於元素 “book” 下。
XQUERY for $b in db2-fn:XMLcolumn("BOOKS.BOOKINFO")
where $b/book/text()= "Database Systems29"
return $b
因此,一般情況下,查詢語義是不同的,這取決於 /text() 的使用。對於僅擁有單個文本節點的最底層元素,不論是否使用 /text(),它們都將可能展示相同的行為。例如,下面兩個查詢可能返回相同的結果,但條件是僅當查詢執行過程中所遇到的全部 “price” 元素都擁有單個文本節點且沒有其他子節點。
XQUERY for $b in db2-fn:XMLcolumn("BOOKS.BOOKINFO")
where $b/book/price < 10
return $b
XQUERY for $b in db2-fn:XMLcolumn("BOOKS.BOOKINFO")
where $b/book/price/text() < 10
return $b
既然 /text() 通常會使查詢語義不同,它也會使索引合格性不同。在表 7 中,可以看到帶有 /text() 的謂詞只能由在其 XML 模式中也指定了 /text() 的索引來評估。如果索引沒有使用 /text(),則謂詞也不應使用 /text()。
表 7:帶有或不帶有 /text() 的索引和謂詞
謂詞或索引定義 ...using XMLpattern '/book/title/text()' as sql varchar(128); ...using XMLpattern '/book/title' as sql varchar(128); where $i/book/title = "Database Systems" - + where $i/book/title/text() = "Database Systems" + -
簡單地說,建議不要在 XML 索引定義或查詢謂詞中使用 /text()。為了支持以 /text() 結尾的任何路徑表達式的謂詞,可能會在 XML 模式 //text() 上定義索引。但是此類索引將包含 XML 列中所有文檔的全部文本節點值。因此,該索引是非常龐大的,並且在插入、更新和刪除操作過程中進行維護的開銷也是很大的。一般情況下,應該避免使用此類索引,除非應用程序大部分是只讀的,並且確實無法預測在搜索條件中使用哪些元素。
索引非末端元素
在上述章節中,看到了在元素 /book 上的謂詞,該元素被稱為非末端(非原子)元素,因為它包含了其他元素。盡管可以在非末端元素上定義索引,但是僅在少數情況下這些索引才有用。考慮下面的 XML 文檔。XML 模式 /book 上的索引包含了該文檔的單個索引項,此索引項的值為 “John DoePeter PanDatabase Systems29SQLrelational”。此索引項是沒有用的,因為普通查詢不會在其謂詞中使用此類串聯值。大多數索引總是位於末端元素上。
<book>
<authors>
<author id="47">John Doe</author>
<author id="58">Peter Pan</author>
</authors>
<title>Database Systems</title>
<price>29</price>
<keyWords>
<keyword>SQL</keyWord>
<keyword>relational</keyWord>
</keyWords>
</book>
有一些情況下,非末端元素上的索引是有意義的。例如,假定您的查詢包含區號和完整電話號碼上的謂詞。在這種情況下,您可以選擇設計 phone 元素,如本文檔中所示。
<author id="47">
<name>John Doe</name>
<phone>
<areacode>408</areacode>
<number>4511234</number>
</phone>
</author>
然後,可以在非末端元素 “phone” 和元素 “areacode” 上分別定義一個 XML 索引:
create index phoneidx on authors(authorinfo) generate key using
XMLpattern '/author/phone' as sql double;
create index areaidx on authors(authorinfo) generate key using
XMLpattern '/author/phone/areacode' as sql double;
這將允許下面兩個查詢來使用索引訪問,而不是表掃描。
select authorinfo from authors
where XMLexists('$a/author[phone=4084511234]' passing authorinfo as "a");
select authorinfo from authors
where XMLexists('$a/author[phone/areacode=408]' passing authorinfo as "a");
XML 索引不能組合類似多列關系索引的關鍵索引。即,不能在兩個或多個 XML 模式上定義單個索引。但是如果對元素進行了適當地嵌套,則有時可以模擬組合索引。例如,上述索引 phoneidx 更像是 /phone/areacode 和 /phone/number 上的組合索引。
不能使用 XML 索引的特殊情況
XMLQUERY 和 XMLEXISTS 的特殊情況
所有已討論的 XML 索引合格性的指導原則都適用於 XQuery 和 SQL/XML 查詢。另外,對於 SQL/XML 函數 XMLQUERY 和 XMLEXISTS,還需要考慮一些特定因素。
如果在 SQL 語句的 select 子句的 XMLQUERY 函數中使用 XML 謂詞,則這些謂詞不會從結果集中排除任何行,因此不能使用索引。它們一次只能用於一個文檔,且返回文檔片斷(可能為空)。因此,應該將任何文檔過濾謂詞和行過濾謂詞放入 SQL/XML 語句的 where 子句的 XMLEXISTS 謂詞中。
在 XMLEXISTS 中表示謂詞時,請確保使用了方括號,例如 $a/author[phone=4084511234],而不是 $a/author/phone=4084511234。後者是 Boolean 謂詞,如果 phone 元素沒有所需的值,則返回 “false”。由於 XMLEXISTS 實際上是檢查值的存在,甚至 “false” 值的存在也將滿足 XMLEXISTS,因此任何文檔都可以成為結果集。如果使用了方括號,則 XPath 表達式將對存在測試失敗的空序列進行評估,然後排除相應的行(如果文檔沒有所需的電話號碼)。
有關這些 XMLQUERY 和 XMLEXISTS 語義的更多詳細示例,請參考 “DB2 9 中 15 個 pureXML 性能最佳實踐”(developerWorks,2006 年 10 月)。
Let 和 return 子句
請注意 XQuery let 和 return 子句不會過濾結果集。因此,如果涉及到元素結構,則它們不能使用索引。下面兩個查詢不能使用索引,因為必須為每個 author 返回元素 “phone408”,即使是區號 408 之外的 author 的空元素。
XQUERY for $a in db2-fn:XMLcolumn("AUTHORS.AUTHORINFO")/author
let $p := $a/phone[areacode="408"]//text()
return <phone408>{$p}</phone408>
XQUERY for $a in db2-fn:XMLcolumn("AUTHORS.AUTHORINFO")/author
return <phone408>{$a/phone[areacode="408"]//text()}</phone408>
父級
DB2 9 也不會將索引用於出現在父級(“..”)下的謂詞,例如下面兩個查詢中 “price” 上的謂詞:
XQUERY for $b in db2-fn:XMLcolumn("BOOKS.BOOKINFO")/book/title[../price < 10]
return $b
XQUERY for $b in db2-fn:XMLcolumn("BOOKS.BOOKINFO")/book/title
where $b/../price < 10
return $b
這不是一個很重要的限制,因為可以始終不用 parent 軸來表示這些謂詞:
XQUERY for $b in db2-fn:XMLcolumn("BOOKS.BOOKINFO")/book[price < 10]/title
return $b
XQUERY for $b in db2-fn:XMLcolumn("BOOKS.BOOKINFO")/book
where $b/price < 10
return $b/title
帶有雙斜線 (//) 的特殊情況
另一個需要注意的情況是使用帶有 descendant 軸或 self 軸(一般省略為 //)的謂詞。假定您想找到 ID 為 129 的作者的書籍。如果 author ID 屬性出現在多個層次,或者您不確定 ID 屬性位於哪一層或哪一個元素下,則您可能會編寫以下這個不適宜的查詢:
錯誤!
XQUERY for $b in db2-fn:XMLcolumn("BOOKS.BOOKINFO")/book/authors[//@id = 129]
return $b
該查詢的意圖是檢查 “authors” 元素中或 “authors” 元素下任何位置的 ID 屬性。但是,方括號中謂詞前的單斜線或雙斜線(/ 或 //)沒有上下文,所以引用到文檔的根。因此,查詢將返回下面的文檔作為結果,但這並不是預期的結果。
<book id="129">
<authors>
<author id="47">John Doe</author>
<author id="58">Peter Pan</author>
</authors>
<title>Database Systems</title>
<price>29</price>
</book>
為了避免此類問題,您必須添加一個點(self 軸),以便表明您想應用文檔樹中從 “authors” 元素向下的 descendant 軸或 self 軸 (//)。
正確!
XQUERY for $b in db2-fn:XMLcolumn("BOOKS.BOOKINFO")/book/authors[.//@id = 129]
return $b
這還允許 DB2 使用定義在 /book//@id 或 //@id 上的索引。如果沒有點,則不會使用任何索引。
您可以在 “On the Path to Efficient XML QuerIEs” 一文中找到有關 XQuery 和 SQL/XML 語言語義對索引合格性的影響的更多示例。
結束語
XML 索引對於 XML 查詢的高性能是至關重要的,但是 XML 查詢的通配符、名稱空間、數據類型、連接、文本節點以及其他語義方面決定了是否可以使用某個索引。需要注意這些方面,以確保 XML 索引定義和查詢謂詞是兼容的。本文給出了一組指導原則和示例,用來展示如何使用 XML 索引來避免表掃描並提高查詢性能。在可下載的備忘單中對最重要的指導原則進行了總結。