簡介
Visual Explain 是 IBM® DB2® Universal Database™ 中的傑出工具,程序員和 DBA 用它來詳細說明 DB2 優化器為 SQL 語句所選擇的存取路徑。事實上,Explain 應該是您性能監控策略的關鍵組件。Explain 為解決許多類型的性能問題提供了價值無法估量的信息,因為它提供這樣的細節:
DB2 在“幕後”所做的工作,以實現 SQL 請求的數據需求
DB2 是否使用可用的索引,如果使用,DB2 如何使用它們
為滿足連接條件而訪問 DB2 表的次序
實現 SQL 語句的鎖定需求
基於所選存取路徑的 SQL 語句的性能
對於 Borland® Delphi™ 7 程序員,Visual Explain 會是一個用於發現 DB2 如何執行 SQL 請求的神奇資源。Delphi 使用 CLI 本機接口來與 DB2 交互。因而,Delphi 使用的是動態 SQL。當將 SQL 語句提交給 DB2 執行時,DB2 會“實時”地為動態 SQL 語句設計出存取路徑。對分析者而言,在執行每條 SQL 語句之前,無法檢查 DB2 為這些語句所選擇的存取路徑。所以,使用 Visual Explain 定期地檢查 DB2 為所有 Delphi SQL 語句所選擇的存取路徑,這是很有意義的。這樣做可以觀察到哪些語句消耗了大部分資源。另外,還可以指導您如何調優 SQL 以達到更好的性能。
但在深入探討 explain 的用法之前,我首先需要研究 explain 確切地“說明”了什麼。答案很簡單,它說明了 DB2 存取路徑。存取路徑是 DB2 所使用的一種算法,以滿足 SQL 語句的需求。但有大量各種類型的存取路徑需要掌握。
DB2 存取路徑的類型及其組成部分
當 DB2 優化器為每條 SQL 語句創建優化的存取路徑時,可以挑選各種不同的技術。這些技術包括從簡單的一連串順序讀到更為復雜的策略(譬如,使用多個索引來訪問數據)。讓我們來了解優化器用來設計 DB2 存取路徑的一些最常用技術。
在優化器必須做的許多決定中,最重要的決定可能是,是否使用索引來實現查詢。在優化器做此項決定之前,它必須首先確定是否存在索引。請記住,您可以查詢任何表中的任何列,卻不能期望單單通過索引就能做到這一點。所以,優化器必須能夠訪問未建立索引的數據;它可以使用掃描來做到這一點。
在大多數情形下,DB2 優化器喜歡使用索引。這是事實,因為索引可以大大優化數據檢索。然而,如果不存在索引,就無法使用它了。並且在某些情況下僅僅使用數據的全掃描就可以極好地實現某些類型的 SQL 語句。例如,考慮下面這條 SQL 語句:
SELECT * FROM EMP;
在這條語句中,為什麼 DB2 非要試圖使用索引呢?這裡沒有 WHERE 子句,所以全掃描是最佳的。即使指定了 WHERE 子句,優化器也可能確定頁面的順序掃描要比索引式檢索更好 — 所以可能不會選擇索引式檢索這種方法。
存在索引的首要原因是它可以改善性能,那為什麼非索引式的訪問會比索引式的訪問要好?唔,索引式訪問可能比簡單的掃描要慢。例如,一個非常小的表可能只有幾個頁面。讀取所有的頁面可能比先讀取索引頁然後再讀取數據頁要快。甚至對於較大的表,在某些情況下,組織索引可能需要額外的 I/O 以實現查詢。當不使用索引來實現查詢時,產生的存取路徑會采用表掃描(或表空間掃描)方法。
表掃描通常會讀取表中每個頁面。但在某些情況下,DB2 會非常聰明,它會限定要掃描的頁面。此外,DB2 可以調用順序預取以在請求某些頁面之前就讀取這些頁面。當 SQL 請求需要按照數據存儲在磁盤上的順序來順序地訪問多行數據時,順序預取特別有用。當優化器確定查詢將按照順序讀取數據頁面時,它會通知應該啟用順序預取。表掃描常常得益於順序預取所作的提前讀取的工作,因為當某個查詢請求數據時,這些數據已經放在內存中了。
快速的索引式訪問
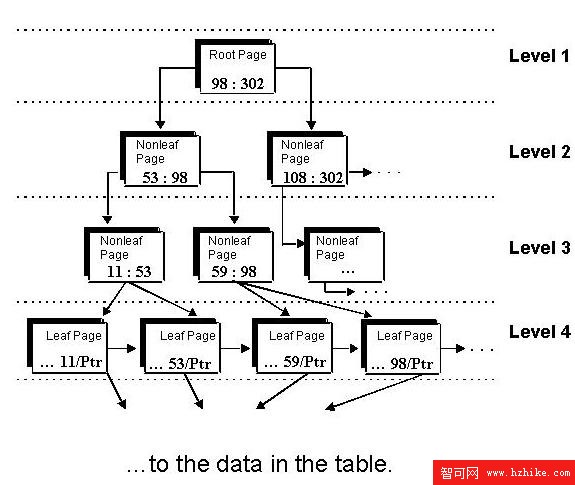
一般來講,訪問 DB2 數據的最快方式是使用索引。索引是為了能夠快速找到某個特定數據塊的目的來構造的。圖 1 顯示了 B 樹索引的結構。可以看到,通過簡單地從樹根遍歷到葉子頁,可以快速地找到相應的數據頁,在那裡有您請求的數據。但是,DB2 所采用的索引方式因語句不同而各不相同。DB2 使用各種不同的內部算法來遍歷索引結構(請參閱 圖 1)。
圖 1. B 樹索引的結構
在 DB2 使用索引來實現數據訪問請求之前,必須滿足以下條件:
至少有一個 SQL 謂詞必須是可索引的。某些謂詞因其特有的本性而為不能被索引,所以優化器從來不能夠使用索引來滿足它們。
其中一列(在任何可索引謂詞中)必須作為可用索引中的列而存在。
所以,您明白,對於 DB2,考慮使用索引的要求是相當簡單的。但關於 DB2 中的索引式訪問仍有許多要了解的內容。事實上,索引式訪問有各種類型。
第一種(也是最簡單的)索引式訪問類型是直接索引查找。對於直接索引查找,DB2 使用索引的根頁面,從頂部開始,向下遍歷,經過中間葉子頁直到抵達相應的葉子頁。在那裡,它將讀取實際數據頁面的指針。根據索引條目,DB2 將讀取正確的數據頁面以返回期望的結果。對於 DB2,為了執行直接索引查找,在索引中必須為每個列提供值。例如,考慮一個 EMPLOYEE 表,該表有一個關於 DEPTNO、TYPE 和 EMPCODE 列的索引。現在考慮這個查詢:
SELECT FIRSTNAME, LASTNAME
FROM EMPLOYEE
WHERE DEPTNO = 5
AND TYPE = 'X'
AND EMPCODE = 10;
如果只指定這些列中的一列或兩列,則不可能采用直接索引查找,因為 DB2 沒有針對每列的值,不可能匹配整個索引關鍵字。相反,可以選用索引掃描。有兩類索引掃描:匹配索引掃描和非匹配索引掃描。有時稱匹配索引掃描為絕對定位;稱非匹配索引為相對定位。還記得前面所討論的表掃描嗎?索引掃描與此類似。在索引掃描中,按順序讀取索引的葉子頁。
匹配索引掃描從索引的根頁開始,遍歷至葉子頁,這種掃描方式與直接索引查找方式完全一樣。然而,因為無法用完整的索引關鍵字,所以 DB2 必須使用它所擁有的值來掃描葉子頁,直到檢索出所有匹配的值。現在考慮重寫前面那個查詢,這次沒有用 EMPCODE 謂詞:
SELECT FIRSTNAME, LASTNAME
FROM EMPLOYEE
WHERE DEPTNO = 5
AND TYPE = 'X';
通過從根部開始遍歷索引,匹配索引掃描用相應的 DEPTNO 和 TYPE 值來查找第一個葉子頁。但可能有多條索引條目具有這兩個值的組合,而這些索引條目的 EMPCODE 值卻不同。所以,會按順序掃描至右邊的葉子頁,直到不再遇到有效的 DEPTNO、TYPE 和各種 EMPCODE 的組合。
要請求執行匹配索引,必須指定索引關鍵字中的高次序列,就是前面這個示例中的 DEPTNO。這向 DB2 提供了遍歷索引結構的啟始點,從根頁開始遍歷,直到相應的葉子頁。但如果沒有指定這個高次序列,則會發生什麼呢?假定對上面這個樣本查詢做點改動,不指定 DEPTNO 謂詞:
SELECT FIRSTNAME, LASTNAME
FROM EMPLOYEE
WHERE TYPE = 'X'
AND EMPCODE = 10;
在這實例中,會用到非匹配索引掃描。在這種情形下,DB2 不能使用索引樹結構,因為關鍵字中第一列不可用。非匹配索引掃描從索引中的第一個葉子頁開始遍歷,應用可用的謂詞,順序掃描後續的葉子頁。不使用根頁和任何中間葉子頁。
一種特殊類型的索引掃描是“僅索引訪問”。如果所需要的全部數據都位於索引中,則 DB2 完全可以避免讀取數據頁。例如:
SELECT DEPTNO, TYPE
FROM EMPLOYEE
WHERE EMPCODE = 10;
請記住,本文中的這個數據庫包含關於 DEPTNO、TYPE 和 EMPCODE 列的索引。在前面的查詢中,只請求查詢這幾列。所以,DB2 完全不需要訪問表,因為在索引中可以找到所有數據。
DB2 可使用的另一類索引式訪問是多索引訪問。針對一個存取路徑,多索引訪問將使用多個索引。例如,查詢 EMPLOYEE 表,其中只有兩個索引:關於 EMPNO 列的 IX1 和關於 DEPTNO 列的 IX2。然後,要求這條查詢顯示在某個特定部門工作的員工:
SELECT LASTNAME, FIRSTNME, MIDINIT
FROM EMPLOYEE
WHERE EMPNO IN ('000100', '000110', '000120')
AND DEPTNO = 5;
DB2 將會使用用於 EMPNO 謂詞的 IX1 還是使用用於 DEPTNO 謂詞的 IX2?為什麼不一起使用這兩者呢?這就是多索引訪問的實質所在。根據謂詞是用 AND 連接還是用 OR 連接,可將多索引訪問分為兩類。
理解連接方法
至此,已經討論了涉及單個表的簡單存取路徑。而連接以及更復雜的 SQL 語句怎樣呢?DB2 優化器有一系列可供自己使用的技術來用於連接表數據。當在 FROM 子句中引用多個 DB2 表(或指定了 JOIN 子句)時,SQL 會請求 DB2 執行連接操作。根據連接標准,必會執行一系列的指令來組合表中的數據。
DB2 如何做這件事?每個多表查詢會分解成數個單獨的存取路徑。為完成此連接操作,DB2 優化器先選擇其中的兩張表並創建一條經過優化的存取路徑。它不是隨機地做這件事,而是根據它認為是此連接的最優方式來進行選擇。然後,優化器繼續連接其它表,直到優化完整條查詢。
在連接表時,優化器將必須確定要使用的最佳連接算法。連接算法(或連接方法)定義了組合表的基本過程。DB2 可以采用三類連接方法:嵌套循環(nested loop)、歸並掃描(merge scan)和散列連接(hash join)。每種連接方法的運行方式各不相同,但可得出相同的結果。然而,連接方法的選用會極大地影響到連接性能。DB2 根據這樣的方式來采用每種連接方法:基於一組統計,采用這種方法可以達到最佳性能。所以,您應該掌握各種連接方法,以及促成選擇這些方法的因素。
每種連接方法通常都涉及一些特定的基本步驟。通常,首先確定先處理哪個表。稱這個表為外表。做出決定之後,對該外表執行一系列的操作,為連接做准備。然後,將該表中的各行與第二個表(稱之為內表)進行組合。另外,還要對內表執行的一系列操作,這可以在連接發生之前進行,也可以連接發生時進行,或者在這兩者時進行。雖然所有連接方法包含的步驟都類似,但除這一點之外,這三種連接方法都各不相同。優化器知道每種方法的優缺點,知道采用哪種方法會怎樣影響到性能。根據系統目錄中的當前統計,優化器還知道哪些表最適合做內表,哪些表最適合做外表。以下從較高層面匯總了優化器所要考慮的一些事項:
表越小,越有可能被選為外表。這有助於減少必須再次訪問內表的次數。
如果選擇謂詞可以應用到某個表,則該表更適合於被選作外表,因為在訪問內表時只會用那些符合這些謂詞(應用於該外表的)的行。
如果可能對其中某個表做索引查找,則該表很適合於作為內表。如果一個表沒有索引,則最好不要將其作為內表,因為每掃描外表中的一行,就要掃描一遍整個內表。
在連接操作中,重復元素最少的表傾向於被選作外表。
當然,這些不是固定不變的規則。最後,優化器將根據詳細的代價估計來選擇外表和內表。現在,我將討論可用於 DB2 的連接類型,以及這些連接類型之間的區別。
最常用的連接類型可能是嵌套循環連接(nested loop join,NLJ)。要執行 NLJ,先在外表中確定符合條件的行,然後掃描內表來搜索匹配。符合條件的行是指與針對表中列的謂詞相匹配的行。在完成對內表的掃描之後,再在外表中確定另一符合條件的行。然後,再掃描內表以查找匹配,如此反復。通常,用索引來重復掃描內表以將 I/O 代價降到最低。
DB2 采用的第二類連接方法是歸並連接(merge join,MJ)。用 MJ 時,需要按照連接謂詞對要連接的表進行排序。這意味著必須按照指定連接標准的列的順序訪問每個表。這個順序可以用排序或索引式訪問來實現。在確保對外表和內表正確排序之後,按照順序讀取每個表,然後匹配連接列。在歸並掃描連接中,每個表只掃描一遍。
第三類連接取決於運行 DB2 的平台。對於 DB2 for OS/390 and z/OS,存在混合連接(hybrid join)。混合連接組合數據和指針來訪問和組合正在連接的表中的行。關於這種連接類型的完整討論超出了本文的討論范圍。
對於 DB2 for Linux、UNIX 和 Windows,第三類連接是散列連接(hash join)。散列連接要求有一個或多個 table1.ColX = table2.ColY 形式的謂詞,並要求列類型必須相同。掃描內表,然後將行復制到為排序堆分配的內存緩沖區。根據“散列代碼”將內存緩沖區分成幾個分區,這些“散列代碼”是根據連接謂詞的列計算得來的。如果第一個表的大小超過了可用的排序堆空間,則選中分區的緩沖區被寫到臨時表中。處理完內表之後,掃描外表,通過比較“散列代碼”,將外表的行與內表的行進行匹配。散列連接可能需要大量內存。所以,要使散列連接真正提高性能,可能需要更改 sortheap 數據庫配置參數和 sheapthres 數據庫管理器配置參數的值。
可是,您知道何時應該使用哪種連接方法?通常,當符合連接的行數較少時,就執行代價而言,建議使用嵌套循環連接。隨著行數的增加,歸並連接成為較好的選擇。最後,在散列連接這種情形下,內表是保存在內存緩沖區中。如果內存緩沖區太少,則散列連接不得不溢出。優化器會試圖避免這種情況,所以選兩個表中較小的表作為內表,較大的作為外表。
最終性能一般取決於確切的符合條件的行數以及其它因素(譬如,數據庫的設計、數據庫的組織、統計信息的精確性、硬件類型和 DB2 環境的設置等)。
用優化等級指定搜索策略
連接方法的選擇還取決於正在使用的優化等級。優化等級指定了各種搜索策略,當編譯和優化 SQL 語句時,優化器將使用這些策略。所以,優化器並非總是使用上面所描述的每種存取路徑技術。相反,根據優化等級,優化器使用各種不同的技術。優化等級的用途是通過它來指導 DB2 何時采用哪種搜索策略和優化技術。通常,優化器考慮的搜索策略越多,用於查詢的存取方案就越好。然而,當優化器被指導去考慮的搜索策略越多,把 SQL 編譯成可執行的存取路徑的時間就越長。幸運的是,可以設置優化等級來限制優化查詢時所應用的技術數目。對於較簡單的查詢、資源受限系統和動態 SQL,這是非常有用的。表 1 概括了優化等級。
表 1. DB2 優化等級。
等級 描述 0 指導優化器使用最少的優化來生成存取方案。只可使用嵌套循環連接和索引掃描訪問方法。限制使用統計信息(例如,不考慮非一致性分布統計)。 1 類似於等級 0,但添加了歸並連接、表掃描和非常基本的查詢重寫(再加一些額外的特性)。 3 極大地改進了等級 1,但比等級 3 所付出的編譯代價要低得多。這個等級利用了所有可用的統計信息、大多數查詢重寫規則、列表預取裝和匯總表路由。類似於等級 5,但它使用貪婪的連接枚舉(Greedy join enumeration),而不是動態編程。 5 該等級最接近於 DB2 for OS/390® 所采用的查詢優化。它提供了中等數量的優化,需要中等數量資源來編譯。 7 提供了極多的優化,需要比等級 3 更多的資源來編譯。優化器智能地確定何時不保證額外資源用於動態 SQL。對於兼有復雜和較簡單的查詢這種混合情形,等級 5 是很好的選擇。 9 該等級類似於等級 5,但它添加了一些在等級 5 中不可用的優化技術。該等級不會確定對於動態 SQL 什麼時候會出現額外資源不足。 0 使用所有可用的優化技術。
雖然可以選擇上表中所描述的任何查詢優化等級,但只有很少一些情形才會使用等級 0 和 9。等級 0、1 和 2 使用貪婪連接枚舉算法;對於復雜查詢,這個算法與等級 3 及其之上的等級相比,考慮的備用計劃極少,因此編譯時間也少得多 。等級 3 和這之上的等級使用動態編程連接枚舉(Dynamic Programming join enumeration)算法;這個算法與等級 0、1 和 2 相比,考慮的備用計劃更多,這可能促成需要極其多的編譯時間。
設定具體的查詢優化等級方式取決於是使用靜態 SQL 還是使用動態 SQL。對於靜態 SQL 語句,在 PREP 和 BIND 命令上指定優化等級。SYSCAT.PACKAGES 目錄表中的 QUERYOPT 列記錄了用於綁定包的優化等級。動態 SQL 語句使用由 CURRENT QUERY OPTIMIZATION 專用寄存器指定的優化等級,可以用 SQL SET 語句來設置 CURRENT QUERY OPTIMIZATION。
最後,讓我總結一下兩類搜索策略及其特征。第一類,貪婪連接枚舉,等級 0、1 和 2 使用該算法。使用貪婪連接枚舉時,對於兩個表,一旦選定連接方法之後,在進一步的優化期間,不會更改連接方法。所以,當連接許多表時,這種策略所選擇的可能不是絕對最佳的存取方案。對於僅連接幾個表的查詢而言,另一類搜索策略(動態編程連接枚舉)所選定的存取方案極有可能與貪婪連接枚舉所選定的存取方案相同。隨著正在連接的表的數目增加,動態編程連接枚舉將需要更多的時間和資源。這比貪婪連接枚舉更有可能選出最佳存取方案。
使用 Visual Explain
既然我們已經基本掌握了 DB2 可以選擇以實現 SQL 請求的存取路徑,那麼,讓我們討論如何弄清楚 DB2 對這些查詢使用了哪種存取路徑。可以使用 explain 來做到這一點。explain 可以用於單個的 SQL 語句或者包中一系列 SQL 語句。當然,在“說明”包時,只會“說明”靜態 SQL。對於 Delphi,這是沒有幫助的,正如前面所提到的,這是因為所有 SQL 是動態的,而不是靜態的。
當請求 explain 時,通過 DB2 優化器傳遞 SQL 語句,並將 DB2 所選定的存取路徑以代碼格式外部化成一組 DB2 explain 表。explain 表只不過是標准的 DB2 表,必須用預先確定的列、數據類型和長度來定義這些表。但是,請記住,explain 表不是自動創建的。為了使用 explain,您(或者您的 DBA)必須首先創建這些 explain 表。可以在安裝了 DB2 的 sqllib 目錄的 misc 子目錄中找到名為 explain.ddl 的 DB2 CLP 腳本。執行該腳本將會創建 explain 表。一旦成功地創建了 explain 表之後,可以用幾個選項來“說明”DB2 存取路徑。
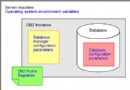
Visual Explain 是最方便的方法,因為可以用帶有簡單的點擊式命令和下拉菜單的 GUI 來訪問它(請參閱 圖 2)。可以作為單獨的工具或者從 DB2 命令中心來訪問 Visual Explain。Visual Explain 的主要好處是它提供了存取路徑的圖形化描述,所以不需要理解 explain 表中的代碼信息。每個存取路徑操作都被置於樹狀結構中帶顏色的代碼節點。在節點上,簡單地移動鼠標,並單擊鼠標,就可以顯示存取路徑中該部分的參數、統計信息和成本估計。還可以用 db2vexp.exe 命令從命令行運行 Visual Explain。
圖 2. Visual Explain GUI
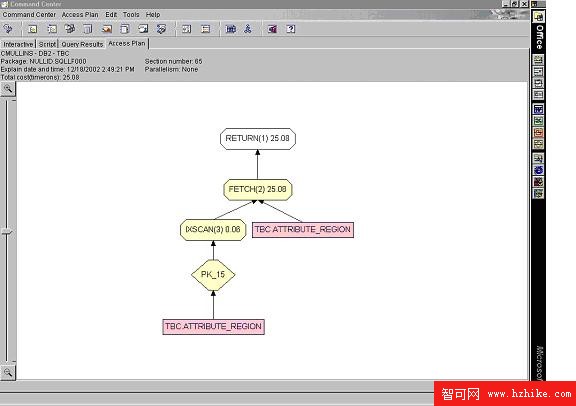
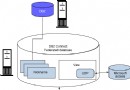
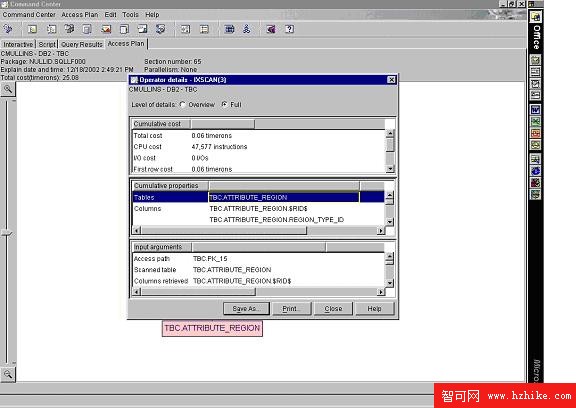
圖 2中的這個示例顯示了 DB2 使用索引 PK_15 的索引掃描來選擇 ATTRIBUTE_REGION 表中的數據。單擊節點,可以獲得其它一些有關存取路徑每個部分中各組成部分的詳細信息。正如我們在前面有關存取路徑一節中所討論的,將有表示掃描、索引式訪問和排序的節點。圖 3 顯示了單擊 IXSCAN 節點後的結果。我們可以看到將對 REGION_TYPE_ID 列進行索引掃描。通過查看 explain 的輸出,可以方便地確定 DB2 將用於實現每條 SQL 查詢的存取路徑(請參閱圖 3)。
圖 3. Visual Explain 詳細信息
如果沒有象 Visual Explain 這樣的工具來提供易於閱讀的存取路徑信息,則需要一個手工過程。而且,必須能夠解釋 explain 表中的代碼信息,以理解手工 explain 的輸出。有了 Visual Explain,就不需要您親自關注 explain 表的實際格式或內容 — 這個工具會為您做所有這一切。
DB2 還提供其它 EXPLAIN 工具。其中包括 db2expln,它是這樣一種“基石”工具:僅為靜態包提供存取路徑的文本描述。對於 Delphi,該工具沒有用;相反,您可能選擇用 dynexpln,它提供了動態 SQL 查詢的文本分析。dynexpln 工具將打包動態查詢,然後調用 db2expln 來做這項工作。但是,一般情況下,請堅持使用 Visual Explain,因為它更易於使用,並且提供了調優 SQL 所需的基本信息。
對於 Delphi 用戶,好的經驗規則是使用 Visual Explain 來顯示 Delphi 程序中 SQL SELECT 語句的存取路徑。對於大多數 SELECT 語句,請嘗試使用索引式訪問。要做到這一點,可以創建其它索引(在生產環境中,只有在 DBA 的指導下才能這樣做),或者修改 SQL 語句以包含可索引的謂詞。分析正在使用的連接方法,理解其中的含義。例如,歸並掃描連接需要排序嗎?這是可以接受的,還是性能會受到影響?
請記住,的結果僅僅相當於 DB2 系統目錄中的統計信息。在使用 explain 之前,請確保 DB2 系統目錄統計信息是最新的。在系統目錄中,DB2 表、索引和列的精確統計信息有助於優化器選擇有效的存取方案。如果最近沒有收集統計信息,則在運行 explain 之前,驗證這些信息是否仍合適。
最後,要意識到還有一些方面這裡未討論到,它們都是做好 SQL 調優工作所必需的。要正確分析 SQL 性能,需要的內容將不僅僅是 explain 結果。正確的性能分析需要:
實際的 SQL 語句
正在被訪問和/或修改的對象的 DDL(或系統目錄信息)的列表
內嵌 SQL 語句的 Delphi 代碼
在執行 explain 時,存在當前的系統目錄統計信息
了解將執行 SQL 語句的 DB2 環境(包括緩沖區和鎖定參數等設置)
了解正在運行 SQL 的環境(包括操作系統、處理器的數目和類型以及內存大小等)
了解在執行(或將要執行)SQL 語句時,系統中的並發活動
可以將這些附加信息和 explain 輸出一起使用,以估計任何給定 SQL 語句的性能。Delphi 代碼很重要,它可以幫助您調節應用程序性能,因為 explain 不能提供有關內嵌 SQL 的高級語言的信息。explain 輸出可以顯示 SQL 語句的有效存取路徑,不過,如果 SQL 語句嵌入在運行數千次的循環中,則性能很可能會受到影響。
使用 explain 來幫助確保索引被正確地用於連接謂詞、本地謂詞以及 GROUP BY 和 ORDER BY 子句,以避免排序。而且,應用您對表中數據的了解來確定正采用的連接類型是否正確,以及正在用於連接的內表和外表的表是否正確。對這些類型細節的注意會因優化的應用程序和較慢執行者的不同而不同。
結束語
有效地使用 Visual Explain 工具可以幫助 Delphi 程序員了解正在用於實現 DB2 SQL 請求的存取路徑。有許多可供 DB2 選擇的技術來實現對數據的請求 — 其中一些技術比其它技術要有效得多。博學的 Delphi 程序員可以使用 explain 來優化其代碼,從而能有效地訪問 DB2 數據。