當要保證用 IBM DB2® Universal Database™(DB2 UDB)和 Borland® 工具(如 Delphi™、C++Builder™ 或 Kylix™)構建的企業應用程序擁有最優性能時,程序員可以利用 DB2 優化器的能力來處理即使是“難以處理的”SQL 語句並給出有效的存取路徑。盡管如此,拙劣編碼的 SQL 和應用程序代碼仍可能給您帶來性能問題,通過學習幾條基本准則可以輕易地避免這些問題。我將向您演示 DB2 優化器的工作方式,並提供編寫能發揮優化器最大效率的 SQL 的准則。但即使擁有了 DB2 的優化能力,編寫有效的 SQL 語句仍可能是一件復雜的事情。如果程序員和開發人員還不熟悉關系數據庫環境,這件事就尤其顯得棘手。因此,在我們深入研究編碼 SQL 以獲得最佳性能的細節之前,先花一些時間來回顧 SQL 基礎知識。
基礎知識
由於 SQL 與過程化語言不同,它提供了更高的抽象級別,因此它可以讓程序員把精力集中到他們需要 什麼樣的數據,而不是 如何檢索數據。您不必使用嵌入式數據導航指令來編碼 SQL。DB2 會分析 SQL,並“在幕後”制定數據導航指令。這些數據導航指令叫作 存取路徑。讓 DBMS 確定到數據的最優存取路徑解除了程序員肩上沉重的負擔。此外,數據庫可以更好地理解它存儲的數據的狀態,從而可以生成到數據的更有效和動態的存取路徑。其結果就是適當使用的 SQL 可以用於更快的應用程序開發。
另一個 SQL 特性是它不僅僅是一種查詢語言。您還可以使用它來定義數據結構;控制對數據的訪問;以及插入、修改和刪除數據的發生。通過提供一種公共語言,SQL 簡化了 DBA、系統程序員、應用程序員、系統分析員和最終用戶之間的通信。當項目的所有參與者都使用同一種語言時,他們之間所建立起來的協作就可以減少整體系統開發時間。
歷史證明,保證 SQL 成功的最重要的一個特性就是它使用類似英語的語法輕松地檢索數據的能力。理解這種語言比理解數據頁面的結構和程序源代碼要容易得多:
SELECT LASTNAMEFROM EMPWHERE EMPNO = '000010';
想想看:當訪問文件中的數據時,程序員必須編碼指令來打開文件、開始一個循環、讀取記錄、檢查 EMPNO 字段是否等於適當的值、檢查文件結尾、回到循環的開頭等。
SQL 本來就是非常靈活的。它使用自由格式的結構,該結構可以讓用戶開發 SQL 語句來適合他們的需要。DBMS 在執行之前會分析每個 SQL 請求,以檢查語法是否正確和優化該請求。SQL 語句不需要從任何給定的列中開始,您可以將它們串在一行中,或者把它們拆成幾行。例如,以下這條單行的 SQL 語句與我前面使用的三行示例等價:
SELECT LASTNAME FROM EMP WHERE EMPNO = '000010';
SQL 的另一個靈活特性是您可以用許多形式不同但功能等價的方法來制定一個請求。例如:SQL 可以連接表或嵌套查詢。您始終可以將嵌套查詢轉換成等價的連接。您可以在大量的函數和謂詞中看到這一靈活性的其它示例。具有等價功能的特性的示例包括:
BETWEEN vs <= / >=
IN vs 一系列和 OR 配合的謂詞
INNER JOIN vs FROM 子句中串在一起並用逗號分隔的表
OUTER JOIN vs 帶有 UNION 的簡單 SELECT 和相關的子查詢
CASE 表達式 vs 復雜的 UNION ALL 語句
SQL 展示的這一靈活性並不總是稱心的,因為形式不同但功能等價的 SQL 公式可以提供非常不同的性能。我將在本文的以後部分討論該靈活性所造成的結果,並提供開發有效的 SQL 的准則。
如我所說的,SQL 指定了要檢索或操作什麼數據,但沒有指定數據庫如何完成這些任務。這就使 SQL 本身變得很簡單。如果您能夠記得關系數據庫的一次處理一個集合(set-at-a-time)的特點,您就開始掌握 SQL 的本質和性質了。一條 SQL 語句可以作用於多行。作用於一組數據而不需要建立如何檢索和操作數據的能力將 SQL 定義成非過程化語言
因為 SQL 是一種非過程化語言,所以一條語句可以代替一系列過程。同樣,由於 SQL 使用集合級別的處理以及 DB2 優化查詢來確定數據導航邏輯,所以這是可能的。有時,如果不使用 SQL 語句,一條或兩條 SQL 語句可以完成的任務就需要完整的過程化程序來完成。
優化器
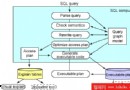
優化器是 DB2 的心髒和靈魂。它分析 SQL 語句並確定可以滿足每條語句的最有效的存取路徑(請參閱圖 1)。DB2 UDB 通過解析 SQL 語句來確定必須訪問哪些表和列,從而完成該操作。DB2 優化器然後查詢存儲在 DB2 系統目錄中的系統信息和統計信息,以確定完成滿足 SQL 請求所必需的任務的最佳方法。
圖 1. 運行中的 DB2 優化
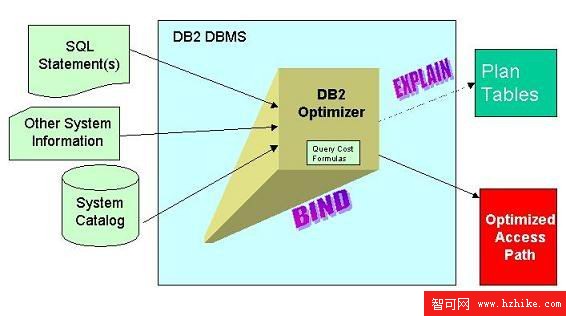
優化器在功能上等價於一個專家系統。專家系統是一個標准規則集合,當與情境數據組合時,它返回一個“專家”意見。例如,醫學專家系統采用一個規則集合,用來確定哪些藥可以用於哪些疾病,將規則集與描述疾病症狀的數據組合,並將知識庫應用於輸入症狀的列表。DB2 優化器會根據存儲在 DB2 系統目錄中的情境數據和 SQL 格式的查詢輸入來生成對數據檢索方法的專家意見。
在 DBMS 中優化數據訪問的概念是 DB2 最強大的能力之一。請記住,您訪問 DB2 數據時應告訴 DB2 要檢索什麼,而不是如何檢索。無論數據實際上是如何存儲和操作的,DB2 和 SQL 都可以訪問該數據。從物理存儲特征中分離出訪問標准叫作物理數據獨立性。DB2 的優化器是完成該物理數據獨立性的組件。
如果您不要索引,DB2 仍然能夠訪問數據(盡管效率會降低)。如果將一列添加到正在被訪問的表中,DB2 仍然可以在不更改程序代碼的情況下操作數據。因為到 DB2 數據的物理存取路徑並不是由程序員在應用程序中編碼的,而是由 DB2 生成的,所以這種情況是完全有可能發生的。
這個特點與非 DBMS 系統非常不同,在那種系統中,程序員必須知道數據的物理結構。如果有索引,程序員就必須編寫適當的代碼來使用該索引。如果某人刪除了索引,程序就不能工作,除非程序員進行更改。而使用 DB2 和 SQL 就不必如此。這一靈活性完全歸功於 DB2 自動優化數據操作請求的能力。
優化器根據許多信息執行復雜的計算。要使優化器的工作方式直觀化,可以將優化器想象成執行一個四步驟的過程:
接收並驗證 SQL 語句的語法。
分析環境並優化滿足 SQL 語句的方法。
創建計算機可讀指令來執行優化的 SQL。
執行指令或存儲它們以便將來執行。
這個過程的第二步是最有趣的。優化器怎樣決定如何以它的方式執行您可以發送的大量 SQL 語句?
優化器有許多類型的優化 SQL 的策略。它如何選擇在優化存取路徑中使用這些策略中的哪一個?IBM 並沒有發布優化器如何確定最佳存取路徑的真正和深入的詳細信息,但優化器是一個 基於成本的優化器。這意味著優化器將始終嘗試為每個查詢制定減少總體成本的存取路徑。要實現這個目標,DB2 優化器會應用查詢成本公式,該公式對每條可能的存取路徑的四個因素進行評估和權衡:CPU 成本、I/O 成本、DB2 系統目錄中的統計信息和實際的 SQL 語句。
性能准則
因此,只要記住關於 DB2 優化器的信息,您就可以實現這些准則以便獲得更好的 SQL 性能:
1) 使 DB2 統計信息保持最新 :如果沒有存儲在 DB2 系統目錄中的統計信息,優化器在優化任何事物時都會遇到困難。這些統計信息向優化器提供了與正在被優化的 SQL 語句將要訪問的表狀態相關的信息。存儲在系統目錄中的統計信息的類型包括:
關於 表的信息,包括總的行數、關於壓縮的信息和總頁數;
關於 列的信息,包括列的離散值的數量和存儲在列中的值的分布范圍;
關於 表空間的信息,包括活動頁面的數量;
索引的當前狀態,包括是否存在索引、索引的組織(葉子頁的數量和級別的數量)、索引鍵的離散值的數量以及是否群集索引;
關於表空間和索引節點組或分區的信息。
當執行 RUNSTATS 或 RUN STATISTICS 實用程序時,統計信息就會填充 DB2 系統目錄。您可以從控制中心(Control Center)、批處理作業或通過使用命令行處理器來調用該實用程序。一定要與您的 DBA 一起工作以確保在適當的時候積累統計信息,尤其是在生產環境中。
2) 構建適當的索引 :也許您為保證最佳 DB2 應用程序性能而可以做的最重要的事就是根據應用程序使用的查詢為您的表創建正確的索引。當然,說總比做更容易。但我們可以從一些基礎開始。例如,考慮以下這條 SQL 語句:
SELECT LASTNAME,SALARY FROM EMP WHERE EMPNO = '000010' AND DEPTNO = 'D01'
什麼索引會對這個簡單查詢有作用?首先,考慮您可以創建的所有可能的索引。您的第一個簡短列表可能看起來如下:
EMPNO 上的 Index1
DEPTNO 上的 Index2
EMPNO 和 DEPTNO 上的 Index3
這是一個好的開始,Index3 可能是最好的。它讓 DB2 使用索引來立即查找滿足 WHERE 子句中的兩個簡單謂詞的行。當然,如果您已經有許多關於 EMP 表的索引,您也許應該檢查再創建另一個關於表的索引所帶來的影響。要考慮的因素包括:
修改影響 :DB2 將自動維護您創建的每個索引。這表示對該表的每個 INSERT 和每個 DELETE 都將不僅在表中插入和刪除,而且會在其索引中插入和刪除。如果您對在索引中的列的值進行 UPDATE 操作,那麼您還更新了該索引。因此索引加快了檢索過程的速度,但減慢了修改的速度。
現有索引中的列 :如果在 EMPNO 或 DEPTNO 上已經有了一個索引,那麼創建另一個關於該組合的索引也許並不明智。但是,更改另一個索引以添加缺少的列也許可以起作用。但也不一定,因為索引中列的順序也許會根據查詢而有很大差異。例如,考慮以下查詢:SELECT LASTNAME, SALARYFROM EMPWHERE EMPNO ='000010'AND DEPTNO > 'D01';
在這種情況下,在索引中應該首先列出 EMPNO。然後列出 DEPTNO,從而允許 DB2 對第一列(EMPNO)執行直接索引查找,然後針對大於號掃描第二列(DEPTNO)。
而且,如果已經存在關於這兩列的索引(一個關於 EMPNO,一個關於 DEPTNO),DB2 可以使用它們來滿足該查詢,因此創建另一個索引也許是沒有必要的。
這種特定查詢的重要性 :查詢越重要,那麼您可能就越應該通過創建索引來進行調優。如果您正在編碼 CIO 要每天都運行的查詢,那麼您應該確保它提供最佳性能。因此,為該特定查詢構建索引是很重要的。反之,職員的查詢也許就沒有必要看得那麼重,所以也許應該利用現有索引來執行查詢。當然,決定取決於應用程序對業務的重要性 - 而不只是用戶的重要性。
索引設計涉及的內容比到目前為止我所討論的要多得多。例如,您也許要考慮索引重載以實現僅索引訪問(index-only Access)。如果 SQL 查詢要尋找的所有數據都包含在索引中,那麼 DB2 也許只使用索引就可以滿足該請求。請考慮我們前面的 SQL 語句。給定了關於 EMPNO 和 DEPTNO 的信息,我們要尋找 LASTNAME 和 SALARY。我們還從創建關於 EMPNO 和 DEPTNO 列的索引開始。如果我們在索引中還包含了 LASTNAME 和 SALARY,我們就不再需要訪問 EMP 表,因為我們需要的所有數據都已經在索引中。該技術可以大大提高性能,因為它減少了 I/O 請求的數量。
請記住:使每個查詢成為僅索引訪問是不謹慎,甚至也是不可能的。您應該謹慎使用該技術以便用於特別棘手或重要的 SQL 語句。
SQL 編碼准則
當您編寫訪問 DB2 數據的 SQL 語句時,要確保遵循以下三個編碼 SQL 的准則以獲得最佳性能。當然,SQL 性能是一個復雜的話題,而且了解 SQL 的執行方式的每一個細微差別可能要花一生的時間。但是,這些簡單的規則可以使您進入開發高性能 DB2 應用程序的正軌。
第一條規則是始終在每條 SQL SELECT 語句的 SELECT 列表中只提供 確實需要檢索的那些列 。另一種說法就是“不要使用 SELECT *”。簡寫 SELECT * 表示您要檢索正在被訪問的表中的所有列。這適用於“快捷但不恰當的方式獲得的“(quick and dirty)查詢,但卻是應用程序的壞實踐,因為:
DB2 表在將來可能需要更改,以包括附加列。SELECT * 也會檢索那些新的列,而如果沒有進行費時的更改,您的程序也許無法處理附加的數據。
DB2 將為被請求返回的每一列消耗附加資源。如果程序不需要數據,它就不會尋找它。即使程序需要每一列,最好根據 SQL 語句中的名稱來顯式地尋找每一列,以便增加清晰度和避免以前犯的錯誤。
不要尋找您已經知道的東西 。這聽起來似乎顯而易見,但大多數程序員都曾經違反過這條規則。舉一個典型的示例,考慮以下 SQL 語句有什麼錯誤:
SELECT EMPNO, LASTNAME, SALARYFROM EMPWHERE EMPNO = '000010';
放棄嗎?問題是 EMPNO 已經包含在 SELECT 列表中。您已經知道了 EMPNO 將等於值“000010”,因為那就是 WHERE 子句要 DB2 做的事。但在 WHERE 子句中列出了 EMPNO,DB2 還會盡職地檢索該列。這會產生附加開銷,從而降低性能。
在 SQL 中 使用 WHERE 子句過濾數據 ,而不是在程序中到處使用它進行過濾。這也是新手容易犯的錯誤。在 DB2 將數據返回到程序之前,最好由 DB2 過濾數據。這是因為 DB2 使用附加 I/O 和 CPU 資源來獲取每一行數據。傳遞到程序的行越少,SQL 的效率就越高:
SELECT EMPNO, LASTNAME, SALARYFROM EMPWHERE SALARY > 50000.00;
與只讀取所有數據而不使用 WHERE 子句,然後在程序中檢查 SALARY 是否大於 50000.00 的做法相比,該 SQL 更好。
使用參數化查詢 。參數化 SQL 語句包含了變量,也稱作參數(或參數標記)。典型的參數化查詢使用這些參數來代替文字值,因此 WHERE 子句條件可以在運行時更改。通常程序被設計成最終用戶可以在運行查詢之前提供參數的值。這允許使用一個查詢根據提供給參數的不同的值返回不同的結果。
參數化查詢的主要性能好處是優化器可以制定在重復執行語句時能夠再使用的存取路徑。與每次 WHERE 子句中需要一個新值就發出一條全新的 SQL 語句相比,這可以給程序增加很大的性能收益。
但是,這些規則並不是 SQL 性能調優的最終和最高目標 - 決不是。您可能需要附加的、深入的調優。但遵循前面的規則將確保您不會犯降低應用程序性能的“新手”錯誤。
特定數據庫應用程序開發技巧
無論您使用的是 Delphi、C++Builder 還是 Kylix,某些技巧和准則將幫助您確保在訪問 DB2 數據時獲得好的性能。例如,在某些情況下,使用 dbExpress TM來代替 ODBC/JDBC 或 ADO 可以提高查詢性能。dbExpress 是用於從 Delphi(或 Borland Kylix™)處理動態 SQL 的跨平台接口。
要確保在您的應用程序中經常發出 COMMIT 語句。COMMIT 語句控制工作單元。發出 COMMIT 會將自上一個 COMMIT 語句之後的所有工作“永遠”記錄到數據庫中。在發出 COMMIT 之前,可以使用 ROLLBACK 語句回滾工作。當修改數據(使用 INSERT、UPDATE 和 DELETE)但沒有發出 COMMIT 時,DB2 將在數據上加一把鎖並保持該鎖 - 這把鎖會使其它應用程序在等待檢索被鎖住的數據時超時。通過在工作完成時發出 COMMIT 語句,並且確保數據是正確的,就釋放了該數據以供其它應用程序使用。
另外,構建應用程序時要考慮使用情況。例如,當某個特定查詢返回幾千行給最終用戶時,要慎重處理。對於在程序和最終用戶之間的在線交互,很少會用到幾百行以上的數據。您可以在 SQL 語句上使用 FETCH FIRST nROWS ONLY 子句來限制返回到查詢的數據量。例如,考慮以下查詢:
SELECT EMPNO, LASTNAME, SALARYFROM EMPWHERE SALARY >
10000.00FETCH FIRST 200 ROWS ONLY;
該查詢將只返回 200 行。如果有超過 200 行符合條件也沒有關系;如果您嘗試從查詢中 FETCH(訪存)超過 200 行,DB2 將用 +100 SQLCODE 表明數據結束。當您想要限制返回給程序的數據量時,這種方法很有用。
DB2 支持另一個名為 OPTIMIZE FOR nROWS 的子句,該子句不限制要返回給游標的行數,但從性能角度看可能是有幫助的。使用 OPTIMIZE FOR nROWS 子句告訴 DB2 如何處理 SQL 語句。例如:
SELECT EMPNO,LASTNAME,SALARYFROM EMPWHERE SALARY >
10000.00OPTIMIZE FOR 20 ROWS;
這告訴 DB2 嘗試盡快訪存前 20 行。如果您的 Delphi 應用程序在顯示從數據庫檢索出來的數據行時每次顯示 20 行,那麼這將非常有用。
對於只讀游標,使用 FOR READ ONLY 子句確保游標無歧義。Delphi 不能在 DB2 游標中執行位置更新,因此將 FOR READ ONLY 附加到每條 SELECT 語句後面可以使游標成為無歧義的只讀游標,從而對 DB2 有所幫助。例如:
SELECT EMPNO,LASTNAME, SALARYFROM EMPWHERE SALARY > 10000.00FOR READ ONLY;