緩沖池
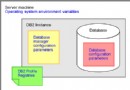
如果你有使用DB2 UDB的經驗,你應該知道, 緩沖池是內存中的一些單獨分配給DB2 數據庫管理器的空間,讓它去做為數據庫添加新數據或者去響應一個查詢從磁盤返回一些數據數據頁的緩沖區。由於從內存中訪問數據勢必比從磁盤上讀取要快的多,因此通過減少磁盤的I/O操作緩沖池改善了數據庫的整體性能。 實際上,研究緩沖池是怎樣被創建和被使用在調整優化的數據庫性能是最重要的一步。
由於緩沖區的重要性地位,每個DBA 都應該了解DB2 UDB怎麼使用他們。這裡是關於它的快速回顧課程。當新數據增加到數據庫時,它首先在緩沖區中增加新頁。最終這個頁將被具體化到數據庫存儲空間中。另一方面,為了響應查詢當數據從數據庫中被檢索出來的時候,DB2數據庫管理器首先將會將這些包含數據的頁存放在緩沖池中,然後才會把它傳遞給需要它的應用程序或者用戶。每次執行新的查詢時,將會在每個可以利用的緩沖池中搜尋是否已經有所需要數據的頁駐留在內存中。如果那樣,就會立刻將它傳遞給對應的的應用或用戶。但是,如果不能在這些緩沖池找到需要的數據的話,DB2 數據庫管理器將會講這些數據從存儲器中檢索出來並且在傳遞數據之前將它復制到緩沖區中。一旦頁被復制到緩沖池,那麼這個頁將會一直駐留在緩沖區中直到數據庫被關閉或直到它所在的空間需要存儲其他頁為止。(由於所有數據的加載和修改首先發生在緩沖區——修改過的頁最終會去刷新磁盤存儲——因此存放在緩沖池中的數據總是最新的)當緩沖池滿了之後,DB2 數據庫管理器將通過檢測頁的最後引用時間,頁類型,或者頁的修改不會影響磁盤內容的改變來選擇去除哪些頁,這些頁可能再次被引用。例如,在30 分鐘前被檢索以響應查詢的頁會比包含更新操作而沒有落實更新的頁更容易被覆蓋。
DB2 UDB缺省創建了一個緩沖池(IBMDEFAULTBP)作為數據庫創建過程的一部分。在Linux和Unix平台,該緩沖池從內存中被分配了1,000個4KB頁;在Windows平台,該緩沖池從內存中被分配了250個4KB頁。 你可以通過在控制中心找到緩沖池菜單並且選擇適當的操作或者執行ALTER BUFFERPOOL語句來增加或減少這個緩沖池的4KB 頁的數量。你也可以通過在控制中心同樣的方法或者執行CREATE BUFFERPOOL語句來創建另外的緩沖區。
由於緩沖區的重要性,你應該仔細考慮使用多少個緩沖池來適應你的實施需要;每一個究竟需要多大;以及每個緩沖池怎麼樣能被充分利用。 在多數環境裡,能被有效使用的緩沖區個數取決於可利用的系統內存的大小。 如果可利用的內存可以保留10,000個4k 頁(或更少),那麼通常的使用單獨的大緩沖池比去使用多個小緩沖池要好。 使用多個小緩沖區將導致頻繁地訪問頁來經常與內存進行進出交換,反過來會導致為存儲對象比如編目表的I/O競爭或者重復的訪問用戶表和索引。但是,如果有比較多的內存,應該考慮創兼各自的緩沖區為以下:
· 每一種臨時表空間被定義
· 包含著被一些短期的更新事務一直或者重復訪問表的表空間
· 包含著表和索引頻繁地被更新的表空間
· 包含著表和索引頻繁地被查詢但很少被更新的表空間
· 包含著表頻繁地被使用於隨意的查詢的表空間
· 包含著很少被應用程序訪問的數據的表空間
· 包含著一些你想要使用的數據和索引的表空間。
在許多情況下,大一點的緩沖池要優於較小的緩沖池。但是,考慮到可以使用的內存總額以及緩沖池將怎麼被使用。 如果你擁有一個要從一個非常大的表中執行許多隨機存取操作的應用,那麼你應該為這個特殊表創造和使用一個小緩沖池。 在這種情況下,沒有必要在緩沖池內存中保留數據頁一旦他們被用於去執行一次單獨的查詢。 另一方面,如果你擁有一個要從幾個看似很小的表中頻繁地檢索數據的應用,你應該考慮創建一個足夠大緩沖池來存放所有在這些表裡免得數據。 采用這個設計方案,數據能一次裝入內存,並且允許它反復的被獲取而沒有必要額外的磁盤I/O 。
表空間
數據庫管理的一個重要部份包括通過使用表空間來完成邏輯數據庫設計到物理存儲的映射。 DB2 UDB 使用二種類型表空間: 系統管理表空間(SMS) 和數據庫管理表空間(DMS)。使用SMS 表空間,操作系統的文件管理器負責分配和處理表空間使用存儲空間。 使用DMS表空間,表空間創建器(或者,在某些情況下是DB2 數據庫管理器) 負責分配空間, DB2 數據庫管理器負責管理。性能通常是以DMS 表空間來獲得快速的相應。 但是,SMS 表空間沒有大小限制(16,777,215 頁) ,在這點上不同於DMS 表空間。 SMS 表空間還更加容易管理,在許多情況下,因為在需要時系統可以自動地獲取額外的存儲空間。通常DMS 表空間被用於那些頻繁地的表,但增長很慢。SMS 表空間一般被用於那些連續增長的表。
早些時候,我提及過數據是在表空間存儲容器之間傳送(譬如文件系統目錄、文件和裸設備)並且緩沖池是被稱之為頁的一些分離塊組成。DB2 UDB 提供四不同頁面大小(4KB 、8KB 、16KB ,和32KB) 。缺省情況下在數據庫創建過程期間產生的三個表空間(SYSCATSPACE, USERSPACE1和 TEMPSPACE1) 被分配4KB 頁面大小。各個表空間必須與緩沖區結合;一個特殊表空間所使用頁面大小必須與它關聯的緩沖區的頁面大小相匹配。 另外,如果你創建可一個頁面大小是4KB之外的一個表空間,你應該創建一個使用同樣頁面大小的系統臨時表空間。否則,在執行一個需要臨時表空間的操作時性能可能會降低(譬如排序和表重組)。
當表空間橫跨多個容器時,數據將會用round-robin方式寫入每個容器。所謂擴展長度的屬性是控制當數據要寫入列表中下一個容器之前在一個容器中寫多少頁數據。這種方法有助於對屬於所給定表空間的所有容器之間的數據平衡。
為了減少查詢的相應時間,DB2數據庫管理器使用了一種被稱之為prefetching的技術去檢索(或取得)那些數據庫管理器確定用戶可能需要在實際執行之前的數據。(數據與需要的實際頁一起被復制到緩沖區;表空間的prefetch 大小將決定在響應一個查詢時有多少額外的數據頁被復制到緩沖池裡。)
缺省的,所有表空間被創建成extent和prefetch均為32頁的大小。你通常可以通過超過這個缺省的extent和prefetch大小來改進整體性能。以下二個算式將確定適當的extent大小:
Min Extent Size = [Number of physical disks used by the tablespace * 4096 (bytes)] / Tablespace Page Size (in bytes)
Max Extent Size = 524288 (bytes) / Tablespace Page Size (in bytes)
(如果你感覺象你以前從未看了這些等式或者是我提供的prefetch的大小,這都是正常的現象。因為我沒有在任何IBM 指南或文獻中發現它們。相反的,這些是我作為DB2 UDB 性能組的成員在多倫多IBM 實驗室工作期間研究出來的結果。)
最合適的extent大小應該是計算出來的最小值與最大值中間某處的值。切記,對於extent的大小,更多不一定意味著更好。在理想狀態下,你在從最小值向最大值過渡的過程中會發現一個合適的extent大小,運行性能測試和評估每次設置的結果。注意,extent大小在表空間創建以後無法修改, 所以,在每次測試的時候表空間將必須刪除,再創建並且重新計算。
一旦你決定了extent的大小,你就可以通過下面的方程來得到prefetch 大小:
Min Prefetch Size = (Extent Size * Number of Containers Used) * Factor
Factor是一個常量,一般為3。
對於prefetch大小,與extent不同的是它在通常狀況下比較好。
分離數據
仔細查看在一個DB2UDB數據庫裡面大多數數據是如何存放你就會發現這裡有三種不同的對象:常規用戶數據存儲為數據對象;索引數據聯系了在表中定義了的索引信息存儲為索引對象;長字段數據被存儲成一個長字段對象 (長字段對象只存在於表包含一個或多個長數據列中——LONG VARCHAR, LONG VARGRAPHIC, BLOB, CLOB, DBCLOB) 。如果采用DMS類型的標空間,這些對象分開地被存放並且每個都被存放在它自己的單獨表空間裡面。在缺省情況下,這三個對象都被存放在同一個表空間裡; 但是,性能可能通過將數據分別存放在上述三種類型的表空間中存放時常得到改善。
關於db2empfa
在SMS 表空間,文件系統(而不是DB2 數據庫管理器)負責在需要時分配額外的存儲空間。並且在缺省情況下,SMS 表空間每次擴展一頁。但是,在某些工作負荷下(例如,當進行一次大批量的插入操作)它也許傾向於使用在extent中分配的存儲空間而不是頁。這就是db2empfa工具起了作用。 當db2empfa運行的時候, 數據庫配置參數multipage_alloc被設置位YES(雖然它是一個只讀配置參數),它會導致 DB2 UDB 每次擴展SMS 表空間一個extent而不是一頁。db2empfa工具在DB2安裝路徑下的SQLLIB/Bin目錄裡面。
索引與性能
索引的主要目的就是幫助DB2 數據庫管理器快速的從表中查出記錄。為表中經常被使用的列創建索引通常有助於數據存取和更新操作性能的改善。此外,索引還考慮到當多重事務處理在同一時間裡訪問同一個表時候的更好的並發性;這樣,行檢索更加快速並且鎖迅速被獲取而且不必擔心它長期的掛起。但是這些優勢需要成本。索引會占用數據庫空間,並且它們可能導致在插入和更新操作執行過程的輕微型能降低。 (所有插入操作和部分更新操作必須發生在表和它對應的索引中。)
那麼怎麼才能告訴你是否創建索引將改進性能?DB2 UDB 8.1封裝了一個工具包來協助你,它可通過控制中心訪問。它被稱為設計顧問,它會捕獲關於數據庫的典型工作負荷以及推薦修改的特定信息,譬如根據提供的信息可以去創建新索引或刪除未使用的索引。
RUNSTATS工具與性能
每當SQL語句被發送到到DB2 數據庫管理器中處理時,SQL 優化器會去讀取系統編目表來確定被引用的列的特性以及在被引用的表中時候已經定義了索引,同時被語句引用的每個表的大小也包括在內。根據這些得到的信息,優化器可以估算出能滿足SQL語句需要的每一種數據存取路徑的成本,然後推薦最佳的一個。 優化器用於做決策的數據庫統計集合數據在系統編目表中是一個關鍵性的元素。所以,統計的變化可能導致選擇存取路徑的變化;如果信息丟失或過時,優化器也許選擇出來的存取計劃將導致SQL語句執行時間比正常的要長。
擁有合法的信息在SQL語句的復雜性增加的時候變得更加關鍵。當只引用一張表(沒有定義索引)時,優化器選擇的數量是有限的。但是,當多個表被引用時(每個表都有一個或多個索引) ,那麼可供優化器選擇的數量會大大加大。但不幸的是,優化器所使用的統計信息是不會自動得保持更新。反而必須階段性地通過使用運行統計工具(RUNSTATS)重新生成。可以通過控制中心和命令行兩種方式執行RUNSTATS工具。語法如下:
RUNSTATS ON TABLE [TableName] < WITH DISTRIBUTION | WITH DISTRIBUTION AND < DETAILED > INDEXES ALL | WITH DISTRIBUTION AND < DETAILED > INDEX [IndexName] > < SHRLEVEL [CHANGE | REFERENCE] >
或者
RUNSTATS ON TABLE [TableName] < [AND | FOR] < DETAILED > INDEXES ALL | [AND | FOR] < DETAILED > INDEX [IndexName] > < SHRLEVEL [CHANGE | REFERENCE] >
TableName 是需要收集(或者更新)統計信息的表的名稱。IndexName 是需要收集或者更新統計信息的索引的名稱。
注:被顯示在角括號裡(< > )的參數是可選的;方括號([ ])中的參數是必須的。
例如,更新存儲在系統編目表中的關於表DEFAULT.EMPLOYEE的統計信息。你可以執行以下命令:
RUNSTATS ON TABLE DEFAULT.EMPLOYEE WITH DISTRIBUTION AND INDEXES ALL SHRLEVEL CHANGE
運行統計工具不會輸出信息。但是,你能通過查詢系統編目視圖SYSCAT.TABLES的CARD, OVERFLOW, NPAGES, FPAGES列來觀看它的結果。(如果這些列的值是21,就意味著統計信息尚未對該行所代表的對象起作用。)
那麼應該多久去收集表的統計信息呢?理想狀況下,你應該在下面一些事件之後去使用運行統計工具:
· 大量的插入、更新或刪除操作
· 導入操作
· 裝載操作
· 在現有表中插入一個新的字段
· 創建新索引
· 表重組
每當表的統計信息被收集或更新的時候,所有引用它的程序包都要被重新與它綁定這樣優化器就可以利用新統計信息並且在可能的時候,會指出它們所包含的SQL語句的更好的訪問計劃。 如果重新綁定失敗或者忘記重新綁定這些程序包可能導致動態sql操作執行起來會比靜態sql操作要快(譯者注:我對此不太明白,詢問別人後得到的解釋是:靜態可能采取的一個費時間的路線,數據變了但訪問的策略沒有變;重新綁定就意味著重新改變訪問策略),相反也適用。
最後,將它們放到一起
對DB2 UDB 系統或任一復雜RDBMS的調優,為了得到最佳的性能將會是一個長的過程。在這一系列專欄我通過對數據庫的分析,解釋了性能問題是如何典型地出現從一個或更多的下列:
粗劣的系統(環境) 配置
粗劣的實例配置
粗劣的數據庫配置
粗劣的數據庫設計
粗劣的應用設計。
系統調優應該從DB2UDB注冊變量,DB2 數據庫管理器實例配置參量以及可能有對性能產生巨大影響的數據庫配置參量開始。接下來再考慮緩沖池如何使用並且確定是否使用附加的緩沖池或不同的緩沖池大小會有所幫助。選擇適當的表空間類型,extent大小和prefetch 大小,並且保持系統目錄統計最新,最終完成基本性能調整。