我們設計關系數據庫Schema的都有一套完整的方案,而NoSQL卻沒有這些。半年前筆者讀了本《SQL反模式》的書,覺得非常好。就開始留意,對於NoSQL是否也有反模式?好的反模式可以在我們設計Schema告訴哪裡是陷阱和懸崖。NoSQL宣傳的時候往往宣稱是SchemaLess的,這會讓人誤解其不需要設計Schema。但如果不意識到設計Schema的必要,陷阱就在一直在黑暗中等著我們。這篇文章就總結一些別人的,也有自己犯過的深痛的設計Schema錯誤。
NoSQL數據庫最主流的有文檔數據庫,列存數據庫,鍵值數據庫。三者分別有代表作MongoDB,HBase和Redis。如果將NoSQL比作兵器的話,可以這樣(MySQL是典型的關系型數據庫,一樣參與比較):">
MySQL產生年代較早,而且隨著LAMP大潮得以成熟。盡管其沒有什麼大的改進,但是新興的互聯網使用的最多的數據庫。就像傳統的菜刀,結構簡單,幾百年沒有改進。但是不妨礙產生各式各樣的刀法,只要有一把,就能勝任廚房裡的大部分事務。MySQL也是一樣,核心已經穩定。但是切庫,分表,備份,監控,等等手段一應俱全。MongoDB是個新生事物,提供更靈活的Schema,Capped Collection,異步提交,地理位置索引等五花十色的功能。就像瑞士軍刀,不但可以當刀用,還可以開瓶蓋,剪指甲。但是他也不比MySQL強,因為還缺乏時間的磨砺。一是系統本身的穩定性,二是開發,運維需要更多經驗才能流行。HBase是個仗勢欺人的大象兵。依仗著Hadoop的生態環境,可以有很好的擴展性。但是就像象兵一樣,使用者需要養一頭大象(Hadoop),才能驅使他。Redis是鍵值存儲的代表,功能最簡單。提供隨機數據存儲。就像一根棒子一樣,沒有多余的構造。但是也正是因此,他的伸縮性特別好。就像悟空手裡的金箍棒,大可捅破天,小能成縮成針。文檔數據庫的得失
關系模型試圖將數據庫模型和數據庫實現分開,讓開發者可以脫離底層很好的操作數據。但筆者以為關系模型在一些應用場景下有弱點,現在已經不得不面對。
SQL弱點一:必須支持Join。因為數據不能夠有重復。所以使用范式的關系模型會不可避免的大量Join。如果參與Join的是一張比內存小的表還好。但是如果大表Join或者表分布在多台機器上的話,Join就是性能的噩夢。SQL弱點二:計算和存儲耦合。關系模型作為統一的數據模型既可以用於數據分析,也可以用於在線業務。但這兩者一個強調高吞吐,一個強調低延時,已經演化出完全不同的架構。用同一套模型來抽象顯然是不合適的。Hadoop針對的就是計算的部分。MongoDB,Redis等針對在線業務。兩者都拋棄了關系模型。
針對這兩個夢魇。文檔數據庫如MongoDB的的主要目的是 提供更豐富的數據結構來拋棄Join來適應在線業務。當然也不是MongoDB完全不能用Join,不能拿來做數據分析,討論這個只是見仁見智的問題。所以文檔數據庫並不比關系數據庫強大,由於對Join的弱支持,功能會弱許多。設計關系模型的時候,通常只需要考慮好數據直接的關系,定義數據模型。而設計文檔數據庫模型的時候,還需要考慮應用如何使用。因此設計好一個的文檔數據庫Schema比設計關系模型更加的困難。除此之外,由於文檔數據庫事務的支持也是比較弱,一般NoSQL只會提供一個行鎖。這也給設計Schema更加增加了難度。對於文檔數據庫的使用有很多需要注意的地方,本文只關注模型設計的部分。
反模式一:慣性思維/沿用關系模型
關系模型是數據存儲的經典模型,使用數據模型范式的好處非常的明顯。但是由於文檔數據庫不支持Join(包括和外鍵息息相關的外鍵約束)等特性,習慣性的沿用關系模型有的時候會出現問題。需要利用起文檔數據庫提供的豐富的數據模型來應對。
值得一提的是文檔數據庫的設計和關系模型不同,是靈活多樣的。對於同一個情形,可以設計出有多種能夠工作的模型,沒有絕對意義上最好的模型。
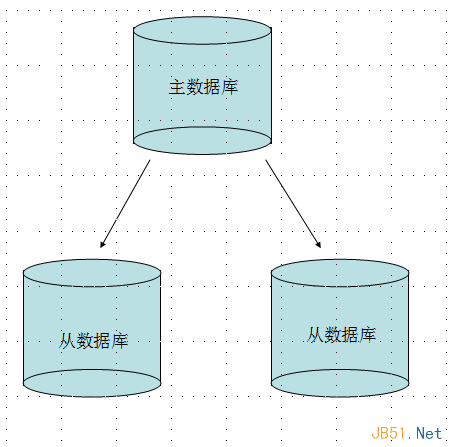
下圖是關系模型和文檔模型的對比。

關系模型 VS 文檔模型
這個一個博客的數據模型,有Blog,User等表。左側是關系模型,右側是文檔模型。這個文檔模型並不是完全合理,可以作為“正反兩面教材”在下文不斷闡述。
問題一:存在描述多對多的關系表症狀:文檔數據庫中存儲在有純粹的關系表,例如:
id user_id blog_id 0 0 0 1 0 1 這樣的表就算在關系模型中也是不妥的,因為這個ID非常的多余,可以用聯合主鍵來解決。但是在文檔數據庫中,由於必須強制單主鍵,不得不采取這樣的設計。
壞處:
破壞數據完備性。由於ID是主鍵,在數據模型上沒有約束來保證不出現重復的user_id,blog_id對。一旦數據出現重復,更新刪除都是問題。索引過多。由於是關系表,必須在user_id和blog_id上面分別建一個索引。影響性能。
解決方案:使用文檔數據庫典型的處理多對多的辦法。不是建立一張關系表,而是在其中一個文檔(如User)中,加入一個List字段。
user_id user_name blog_id[] …… 0 Jake 0,1 …… 1 Rose 1,2 ……
問題二:沒有區分"一對多關系"和“多對一關系”症狀:關系模型不區分“一對多”和“多對一”,對於文檔數據庫來講,關系模型只有“多對一”。就像這張Comment表:
comment_id user_id content …… 0 0 “NoSQL反模式是好文章” …… 1 0 “是啊” ……
如果整個模型都是這樣的“多對一”關系就需要反思了。
壞處:
額外索引。如果客戶端已知user_id,需要獲得User信息和Comment信息,需要執行兩次查詢。其中一次查詢需要使用索引。並且要在客戶端自己Join。這樣可能有潛在性能問題。
解決方案:問題的核心在於是已知user_id查詢兩張表,還是已知comment_id查詢兩張表。如果是已知comment_id這樣的設計就是合理的,但是如果是已知user_id來查詢,把關系放在user表裡的設計更合理一些。
user_id user_name comment_id[] …… 0 Jake 0,1 …… 1 Rose 1,2 ……
這樣的設計,就可以避免一個索引。同理,對於多對多也是一樣的,通過合理的安排字段的位置可以避免索引。
正確使用的場合:
關系型模型是非常成功的數據模型,合理的沿用是非常好的。但是由於文檔數據庫的特點,需要適當的調整,這樣得出的數據模型,盡管性能不是最優,但是有最好的靈活性。並且也有利於和關系數據庫轉換。
反模式二:處處引用客戶端Join
症狀:數據庫設計中充滿了xx_id的字端,在查詢的時候需要大量的手動Join操作。就涉及到了這個反模式。正如上面提到的博客的關系模型,如果已知blog_id查詢comments,需要至少執行3次查詢,並且手動Join。
壞處:
手動Join,麻煩且易出錯。文檔數據庫不支持Join且沒有外鍵保證。因此需要在客戶端Join,這樣的操作對於軟件開發來講是比較繁瑣的。由於沒有外鍵保證,因此不能保證取得的ID在數據庫裡面是有數據的。在處理的時候需要不斷判斷,容易出錯。多次查詢。如果引用過多,查詢的時候需要多次查詢才能查到足夠的數據。本來文檔數據庫是很快的,但是由於多次查詢,給數據庫增加了壓力,獲取全部數據的時間也會增加。事務處理繁瑣。文檔數據庫一般不支持一般意義上事務,只支持行鎖。如果文檔數據庫有給多個連接。在插入的時候,事務的處理就是噩夢。在文檔數據庫中使用事務,需要使用行鎖,在進行大量的處理。太過繁瑣,感興趣的讀者可以搜一下。
解決方案:適當使用內聯數據結構。由於文檔數據庫支持更復雜的數據結構可以將引用轉換為內聯的數據,而不用新建一張表。這樣做可以解決上面的一些問題,是一個推薦的方案。就像上面博客的例子一樣。將五張表簡化成了兩張表。那什麼時候使用內聯呢?一般認為
使用內聯可以解決讀性能問題,明顯減少Query的次數的時候。可以簡化數據模型,化簡表之間的關系,而同時不會影響靈活性的時候。事務可以得到簡化為單行事務的時候正確使用的場合:
范式化的使用場景,文檔數據庫會被多個應用使用。由於數據庫設計無法估計多個應用現在及將來的查詢情況,需要極大的靈活性。在這個時候,使用引用比內聯靠譜。
反模式三 濫用內聯後患無窮
問題一 妨礙到查詢的內聯症狀:頻繁查詢一些內聯字段,丟棄其他字段。
壞處:
無ID約束:使用內聯字段和引用不同,是沒有ID約束的。因此不能通過ID(主鍵)來管理,如果經常需要單獨操作內聯對象會非常不便。索引泛濫:如果以內聯字段為條件進行查詢,需要建立索引。有可能造成索引泛濫。性能浪費:大部分文檔數據庫的實現是按行存儲的,也就意味著,盡管只查詢一個字段,但是DB需要將整行從磁盤中取出。如果字段夠小,文檔夠大,是很不合算的。
解決方案:如果出現以上的症結,就可以考慮使用引用代替內聯了。內聯特性主要的用途在於提高性能,如果出現性能不升反降,那就沒有意義了。如果對性能有很強烈的要求,可以考慮使用重復數據,同樣的數據即在內聯字段中也在引用的表裡面。這樣可以結合內聯和引用的性能優勢。缺點是數據出現重復,維護會比較麻煩。
問題二 無限膨脹的內聯症狀:List,Map類型的內聯字段不斷膨脹,而且沒有限制。就像前面提到的Blog的內聯字段Comment。如果對每一篇Blog的Comment數量沒有限制的話,Comment會無限膨脹。輕則影響性能,重則插入失敗。
Blog_id content Comment[] …… 0 “…” “NoSQL反模式是好文章”, “是啊”,”無限增長中”… …… 壞處:
插入失敗。文檔數據庫的每條記錄都有最大大小,並且也有推薦最佳的大小。一般不會超過4M。就像剛剛提到的例子,如果是篇熱門的博文的話,評論的大小很容易就超過4M。屆時文檔將無法更新,新的評論無法插入。性能拖油瓶。由於內聯字段膨脹,其大小將遠遠超過其他部分,影響其他部分的性能表現。並且因此導致該記錄大小頻繁變化,對檔數據庫的數據文件內部可能因此產生很多碎片。
解決方案:設定最大數目或者使用引用。還是Blog和Comment的例子,可以將Comment從Blog中剝離出成一張表。如果考慮到性能,可以在Blog表中新建一個字段如最近的評論。這樣既保證了性能,又能夠預防膨脹。
Blog_id content last_five_comment[] …… 0 “…” “NoSQL反模式是好文章”, “是啊”,”最多5條”… …… 問題三 無法維護的內聯症狀:DBA想單獨維護內聯字段,但無法做到。
壞處:
權限管理難。數據庫的權限管理的最小粒度是表。如果使用內聯技術,就意味著內聯部分必須和其他字段用同一個權限來管理。沒有辦法在DB級別隱藏。切表難。如果發現一張表的龐大需要切表。這個時候就比較糾結了。如果一刀切,partion Key的選擇;索引的失效都會成為問題。如果覺得拆為兩張表,就會很好操作的話,就是內聯的過度使用了 。備份難。關系數據庫中每張表可以有不同的備份策略。但是如果內聯起來,這樣的備份就做不到了。解決辦法:設計數據庫模型的時候需要考量之後的維護操作,尤其是內聯的字段需不需要單獨的維護。需要和運維商量。如果對內聯的字段有單獨維護的要求,可以拆分出來作為引用。
問題四 盯死應用的內聯症狀:應用可以非常好的運行在數據庫上。但是當新的應用接入的時候會很麻煩。因為設計數據模型的時候考慮到了查詢。所以當有新應用,新查詢接入的時候,就會難於使用原有的模型。
壞處:
新應用接入難。當新的應用試圖使用同一個數據庫的時候,接入比較困難。因為查詢時不同的,需要調整數據模型才能適應。但是調整模型又會影響原有應用。集成難。不同的關系型數據庫可以集成在一起,共同使用。但是對於文檔數據庫,雖然功能上可以互補,但是由於內聯數據結構的差異,也比較難於集成。ETL難。現在大部分的數據分析系統使用的是關系模型,就連Hadoop雖然不用關系模型,但是其上的Hive的常用工具也是按關系模型設計的。
解決方案:
使用范式設計數據庫,即用引用代替內聯。或者在使用內聯的時候,給每個內聯對象一個全局唯一的Key,保證其和關系模型直接可以存在映射關系,這樣可以提高數據模型的靈活性。如Blog表:
Blog_id content Comment[] …… 0 “…” [{"id"=1,"content"=“NoSQL反模式是好文章”}, {"id"=2,"content"=“是啊”}…] ……
這樣的設計既可以利用到內聯的好處,又能將其和關系模型映射起來。確定是需要手動維護comment_id,保證其全局唯一性。
反模式四:在線計算
症狀:有一些運行時間很長的Query,由於有聚合計算,索引也不能解決。隨著數據量的增長,逐漸成為性能瓶頸。
壞處:
影響用戶體驗。在線業務中,如果一個查詢大於4s,用戶體驗會急劇下降。按主鍵和按索引的查詢都能滿足要求。但是聚合操作往往需要掃描全表或者大量的數據,隨著數據量的增加,查詢時間會變長,用戶不可容忍。影響數據庫性能。長查詢的壞處數不清。在線上應用中,如果出現長查詢,可能會霸占數據的大部分資源,包括IO,連接,CPU等等。導致其他很好的查詢,輕則性能也下降,重者無法使用數據庫。長查詢可以稱之為DB殺手。
解決方案:首先要權衡,這個聚合操作是不是必要的,必須實時完成。如果沒有必要實時完成的話,可以采取離線操作的方案。在夜深人靜的時候,跑一個長查詢,將結果緩存起來,給第二天使用。如果必須實時完成,則可以新建一個字段,用“incr”這樣的操作,在運行的時候,實時聚合結果。而不是查詢的時候執行一次長查詢。如果邏輯比較復雜,或者覺得大量“incr”操作給數據庫系統帶來了壓力,可以使用Storm之類的實時數據處理框架。總之,要慎用長查詢。
反模式五:把內聯Map對象的Key當作ID用
症狀:文檔數據庫支持內聯Map類型。將其中Map的Key當作數據庫的主鍵來用。
Blog_id content Comment{} …… 0 “…” {"1"=“NoSQL反模式是好文章”, "2"=“是啊”} …… 這個反模式很容易犯,因為在編程語言中Map數據結構就是這麼用的。但是對於數據庫模型來說,這是不折不扣的反模式。
壞處:
無法通過數據庫做各種(><=)查詢。對於關系型數據庫來說,雖然數據結構可以很靈活,但查詢的時候都是按層次的。比如comment.id,comment.content。也就是說其Map類型中的Key可以理解為屬性名的,而不是用作ID。因此一旦這樣使用,就脫離的數據庫管制,無法使用各種查詢功能。無法通過索引查詢。文檔數據可建立索引是需要列名的。比如comment.id。而這樣的數據結構沒有固定的列名,因此無法建立索引。
解決方案:使用數組+Map來解決。如:
Blog_id content Comment[] …… 0 “…” [{"id"=1,"content"=“NoSQL反模式是好文章”}, {"id"=2,"content"=“是啊”}…] …… 這樣,就可以使用comment.id作為索引,也可以使用數據庫的查詢功能。簡單有效。Map類型中的Key是屬性名,Value是屬性值。這樣的用法是文檔數據庫數據模型的本意,因此其提供的各種功能才能利用上。否則就無法使用。
反模式六:不合理的ID
症狀:使用String甚至更復雜數據結構作為的ID,或者全部使用數據庫提供的自生成ID。如:
id(該ID系系統自生成) Blog_id content …… 0 0 ... …… 壞處:
ID混亂。如果使用數據庫提供的自生成ID,同時表中還有一個類似有主鍵含義的Blog_id,這樣很不好,容易造成邏輯混亂。由於文檔數據庫不支持ID的重命名,習慣關系數據庫做法的人可能會再建立一個自己的邏輯ID字段。這是沒有必要的。索引龐大,性能低下。ID是數據庫的非常重要的部分。ID的長度將決定索引(包括主鍵的索引)的大小,直接影響到數據庫性能。如果索引比內存小,性能會很好。但一旦索引大小超過內存,出現數據交換,性能會急劇下降。一個Long占8字節,一個20個字符的UTF8 String占用約60個字節。相差10倍之巨,不能不考慮。
解決方案:盡量使用有一定意義的字段做ID,並且不在其他字段中重復出現。不使用復雜的數據類型做ID,只使用int,long或者系統提供的主鍵類型做ID。
文檔數據庫的反模式總結
闡述了這麼多的反模式,下面有個一覽表,涵蓋了上面所有的反模式。這個一覽表,是按照文檔數據庫模型建立的。是個文檔數據庫模型的例子。
ID
反模式名
問題
0
存在描述多對多的關系表
[{ID:00
症狀:文檔數據庫中存儲在有純粹的關系表
壞處:[破壞數據完備性,索引過多]
解決方案:加入一個List字段
},{
ID:01
症狀:關系模型不區分“一對多”和“多對一”
壞處:額外索引
解決方案:合理的安排字段的位置
}]
1
處處引用客戶端Join
[{
ID:10
症狀:查詢的時候需要大量的手動Join操作
壞處:[手動Join,多次查詢, 事務處理繁瑣]
解決方案:適當使用內聯數據結構。
}]
2
濫用內聯後患無窮
[{
ID:20
症狀:頻繁查詢一些內聯字段,丟棄其他字段
壞處:[無ID約束,索引泛濫, 性能浪費]
解決方案:使用引用代替內聯了,允許重復數據
},{
ID:21
症狀:List,Map類型的內聯字段不斷膨脹,而且沒有限制
壞處:[插入失敗, 性能拖油瓶]
解決方案:設定最大數目或者使用引用。
},{
ID:22
症狀:DBA想單獨維護內聯字段,但無法做到
壞處:[權限管理難, 切表難, 備份難]
解決方案:設計數據庫模型的時候需要考量之後的維護操作
},{
ID:23
症狀:應用可以非常好的運行在數據庫上。但是當新的應用接入的時候會很麻煩。內聯盯死了應用
壞處:[新應用接入難, 集成難, ETL難]
解決方案:使用范式設計數據庫,即用引用代替內聯。保證其和關系模型直接可以存在映射關系
}]
3
在線計算
[{
ID:30
症狀:有一些運行時間很長的Query, 逐漸成為性能瓶頸。
壞處:[影響用戶體驗,影響數據庫性能]
解決方案:取消不必要的聚合操作. 運行的時候,實時聚合結果.使用第三方實時或非實時工具。如Hadoop,Storm.
}]
4
把內聯Map對象的Key當作ID用
[{
ID:40
症狀:文檔數據庫支持內聯Map類型。將其中Map的Key當作數據庫的主鍵來用。
壞處:[無法通過數據庫做各種(><""" =)查詢,無法通過索引查詢]
解決方案:使用數組+Map來解決。
}]
5
不合理的ID
[{
ID:50
症狀:用String甚至更復雜數據結構作為的ID,或者全部使用數據庫提供的自生成ID。
壞處:[ID混亂,索引龐大]
解決方案:盡量使用有一定意義的字段做ID。不使用復雜的數據類型做ID。
}]
本文試圖總結了筆者知道的重要的文檔數據庫的反模式。現在關於NoSQL數據模型設計模式的討論才剛剛起步,將來也許會逐漸自成體系。對於列數據庫和Key-Value的反模式,筆者等到有了足夠積累的時候,再和大家分享。