問題背景
周一上班,首先向同事了解了一下上周的測試情況,被告知在多實例場景下 MySQL Server hang 住,無法測試下去,原生版本不存在這個問題,而新版本上出現了這個問題,不禁心頭一顫,心中不禁感到奇怪,還好現場環境還在,為排查問題提供了一個好的環境,隨即便投入到緊張的問題排查過程當中。問題實例表現如下:
復制代碼 代碼如下:
並發量為 384 的時候出現的問題;
MySQL 服務器無法執行事務相關的語句,即使簡單的 select 語句也無法執行;
所有線程處於等待狀態,無法 KILL。
現場環境的收集
首先,通過 pstack 工具獲取當前問題實例的堆棧信息以便後面具體線程的查找 & 問題線程的定位:
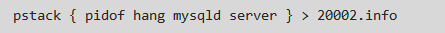
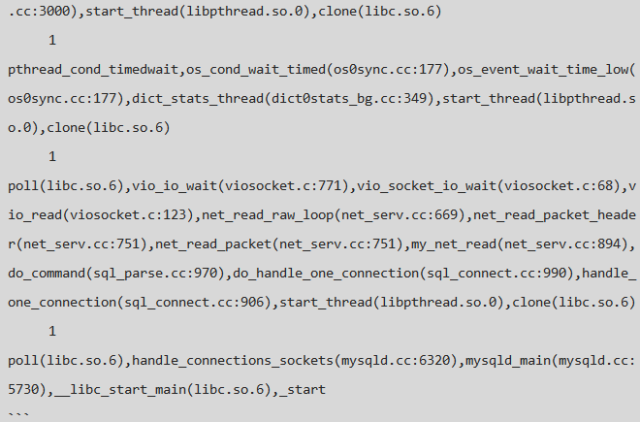
使用 pt-pmp 工具統計 hang.info 中的進程信息,如下:








問題分析
從堆棧上可以看出,有這樣幾類線程:
等待進入 INNODB engine 層的用戶線程,測試環境中 innodb_thread_concurrency=16, 當 INNODB 層中的活躍線程數目大於此值時則需要排隊,所以會有大量的排隊線程,這個參數的影響&作用本身就是一篇很不錯的文章,由於篇幅有限,在此不做擴展,感興趣者可以參考官方文檔:14.14 InnoDB Startup Options and System Variables;
操作過程中需要寫 redo log 的後台線程,主要包括 page cleaner 線程、異步 io threads等;
正在讀取Page頁面的 purge 線程 & 操作 change buffer 的 master thread;
大量的需要寫 redo log 的用戶線程。
從以上的分類不難看出,所有需要寫 redo log 的線程都在等待 log_sys->mutex,那麼這個保護 redo log buffer 的 mutex 被究竟被哪個線程獲取了呢,因此,我們可以順著這個線索進行問題排查,需要解決以下問題:
問題一:哪個線程獲取了 log_sys->mutex ?
問題二:獲取 log_sys->mutex 的線程為什麼沒有繼續執行下去,是在等其它鎖還是其它原因?
問題三:如果不是硬件問題,整個資源竟爭的過程是如何的?
1.問題一:由表及裡
在查找 log_sys->mutex 所屬線程情況時,有兩點可以幫助我們快速的定位到這個線程:
由於 log_sys->mutex 同時只能被同一個線程獲得,所以在 pt-pmp 的信息輸出中就可以排除線程數目大於1的線程;
此線程既然已經獲取了 log_sys->mutex, 那就應該還是在寫日志的過程中,因此重點可以查看寫日志的邏輯,即包括:mtr_log_reserve_and_write 或 log_write_up_to 的堆棧。
順著上面的思路很快的從 pstack 中找到了以下線程:



這裡我們簡單介紹一下MySQL寫 redo log 的過程(省略undo & buffer pool 部分),當對數據進行修改時,MySQL 會首先對針對操作類型記錄不同的 redo 日志,主要過程是:
記錄操作前的數據,根據不同的類型生成不同的 redo 日志,redo 的類型可以參考文件:src/storage/innobase/include/mtr0mtr.h 記錄操作之後的數據,對於不同的類型會包含不同的內容,具體可以參考函數:recv_parse_or_apply_log_rec_body(); 寫日志到 redo buffer,並將此次涉及到髒頁的數據加入到 buffer_pool 的 flush list 鏈表中; 根據 innodb_flush_log_at_trx_commit 的值來判斷在commit 的時候是否進行 sync 操作。
上面的堆棧則是寫Redo後將髒頁加到 flush list 過程中時 hang 住了,即此線程在獲取了 log_sys->mutex 後,在獲取 log_sys->log_flush_order_mutex 的過程中 hang 住了,而此時有大量的線程在等待該線程釋放log_sys->mutex鎖,問題一 已經有了答案,那麼log_sys->log_flush_order_mutex 是個什麼東東,它又被哪個占用了呢?
說明:
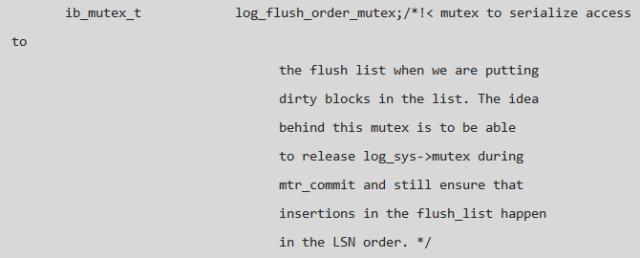
1、MySQL 的 buffer pool 維護了一個有序的髒頁鏈表 (flush list according LSN order),這樣在做 checkpoint & log_free_check 的過程中可以很快的定位到 redo log 需要推進的位置,在將髒頁加入;
2、flush list 過程中需要對其上鎖以保證 flush list 中 LSN 的有序性, 但是如果使用 log_sys->mutex,在並發量大的時候則會造成 log_sys->mutex 的 contention,進而引起性能問題,因此添加了另外一個 mutex 來保護髒頁按 LSN 的有序性,代碼說明如下:
2.問題二:彈盡糧絕
在問題一的排查過程中我們確定了 log_sys->mutex 的所屬線程, 這個線程在獲得 log_sys->log_flush_order_mutex 的過程中 hang 住了,因此線程堆棧可以分以為下幾類:
Thread 446, 獲得 log_sys->mutex, 等待獲取 log_sys->log_flush_order_mutex 以把髒頁加入到 buffer_pool 的 flush list中; 需要獲得 log_sys->mutex 以寫日志或者讀取日志信息的線程; 未知線程獲得 log_sys->log_flush_order_mutex,在做其它事情的時候被 hang 住。
因此,問題的關鍵是找到哪個線程獲取了 log_sys->log_flush_order_mutex。
為了找到相關的線程做了以下操作:
查找獲取 log_sys->log_flush_order_mutex 的地方;
結合現有 pstack 中的線程信息,仔細查看上述查找結果中的相關代碼,發現基本沒有線程獲得 log_sys->log_flush_order_mutex; gdb 進入 MySQL Server, 將 log_sys->log_flush_order_mutex 打印出來,發現 {waiters=1; lock_word= 0}!!!,即 Thread 446 在等待一個空閒的 mutex,而這個Mutex也確實被等待,由於我們的版本為 Release 版本,所以很多有用的信息沒有辦法得到,而若用 debug 版本跑則很難重現問題,log_flush_order_mutex 的定義如下:


由以上的分析可以得出 問題二 的答案:
只有兩個線程和log_sys->log_flush_order_mutex有關,其中一個是 Thread 446 線程, 另外一個則是最近一次調用 log_flush_order_mutex_exit() 的線程; 現有線程中某個線程在釋放log_sys->log_flush_order_mutex的過程中沒有喚醒 Thread 446,導致Thread 446 hang 並造成其它線程不能獲得 log_sys->mutex,進而造成實例不可用; log_sys->log_flush_order_mutex 沒有被任何線程獲得。 3.問題三:絕處逢生
由問題二的分析過程可知 log_sys->log_flush_order_mutex 沒有被任何線程獲得,可是為什麼 Thread 446 沒有被喚醒呢,信號丟失還是程序問題?如果是信號丟失,為什麼可以穩定復現?官方的bug list 列表中是沒有類似的 Bug的,搜了一下社區,發現可用信息很少,這個時候分析好像陷入了死胡同,心裡壓力開始無形中變大……好像沒有辦法,但是任何問題都是有原因的,找到了原因,也就是有解的了……再一次將注意力移到了 Thread 446 的堆棧中,然後查看了函數:

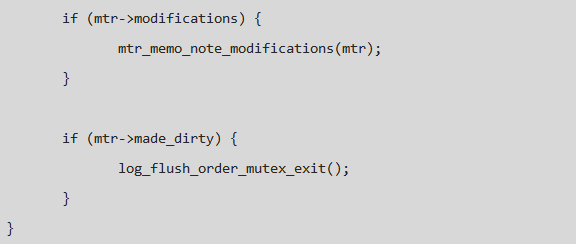
由問題二的分析過程可以得出某線程在 log_flush_order_mutex_exit 的退出過程沒有將 Thread 446 喚醒,那麼就順著這個函數找,看它如何喚醒其它本程的,在沒有辦法的時候也只有這樣一步一步的分析代碼,希望有些收獲,隨著函數調用的不斷深入,將目光定在了 mutex_exit_func 上, 函數中的注釋引起了我的注意:


從上面的注釋中可以得到兩點信息:
由於 memory barrier 的存在,mutex_get_waiters & mutex_reset_lock_word 的調用順序可能與執行順序相反,這種情況下會引起 hang 問題; 專門寫了一個函數 sync_arr_wake_threads_if_sema_free() 來解決上述問題。
由上面的注釋可以看到,並不是信號丟失,而是多線程 memory barrier 的存在可能會造成指令執行的順序的異常,這種問題確定存在,但既然有sync_arr_wake_threads_if_sema_free() 規避這個問題,為什麼還會存在 hang 呢?有了這個線索,瞬間感覺有了些盼頭……經過查找 sync_arr_wake_threads_if_sema_free 只在 srv_error_monitor_thread 有調用,這個線程是專門對 MySQL 內部異常情況進行監控並打印出 error 信息的線程,臭名昭著的 600S 自殺案也是它的傑作, 那麼問題來了:
機器周末都在 hang 著,為什麼沒有檢測到異常並 abort 呢? 既然 sync_arr_wake_threads_if_sema_free 可以喚醒,為什麼沒有喚醒呢?
順著這個思路,查看了pstack 中 srv_error_monitor_thread 的堆棧,可以發現此線程在獲取 log_sys->mutex 的時候hang 住了,因此無法執行sync_arr_wake_threads_if_sema_free() & 常歸的異常檢查,正好回答了上面的問題,詳細堆棧如下:
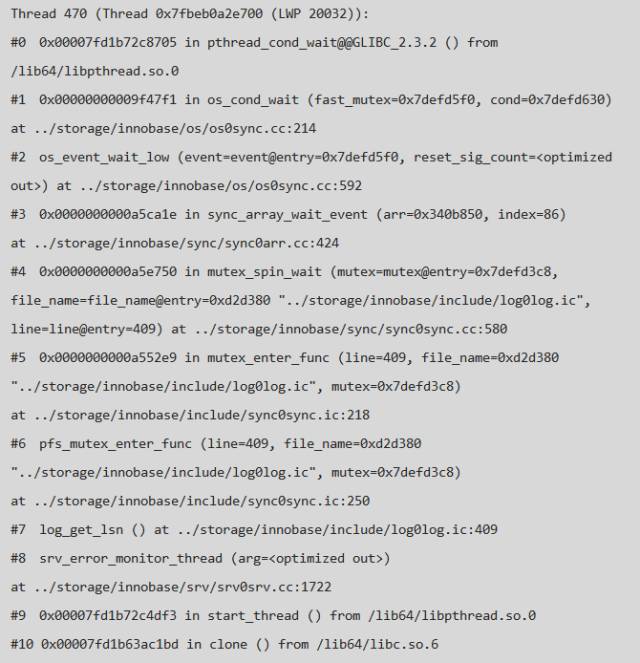
經過上面的分析問題越來越明朗了,過程可以簡單的歸結為:
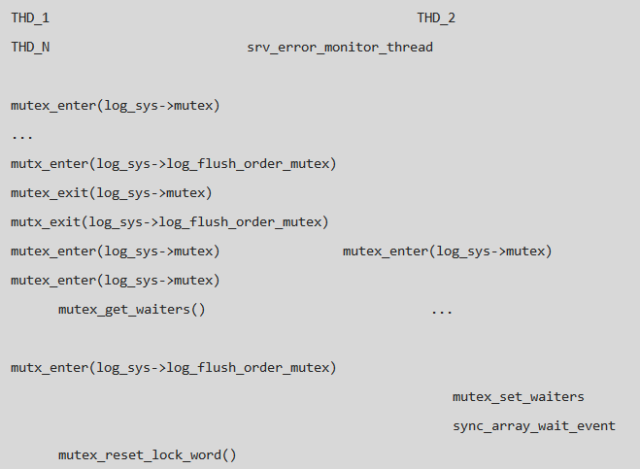
Thread 446 獲得 log_sys->mutex, 但是在等待 log_sys->log_flush_order_mutex 的過程中沒有被喚醒; Thread XXX 在釋放 log_sys->log_flush_order_mutex 的過程中出現了 memory barrier 問題,沒有喚醒 Thread 446; Thread 470 獲得 log_sys->mutex 時被 hang 住,導致無法執行 sync_arr_wake_threads_if_sema_free(), 導致了整個實例的 hang 住; Thread 470 需要獲得 Thread 446 的 log_sys->mutex, 而 Thread 446 需要被 Thread 470 喚醒才會釋放 log_sys->mutex;
結合 log_sys->log_flush_order_mutex 的狀態信息,實例 hang 住的整個過程如下:
關於 Memory barrier 的介紹可以參考 :
Memory barrierhttp://name5566.com/4535.html
問題解決
既然知道了問題產生的原因,那麼問題也就可以順利解決了,有兩種方法:
直接移除 log_get_lsn 在此處的判斷,本身就是開發人員加的一些判斷信息,為了定位 LSN 的異常而寫的,用到的時候也Crash了,用處不大; 保留判斷,將 log_get_lsn 修改為 log_peek_lsn, 後者會首先進行 try_lock,當發現上鎖失敗的時候會直接返回,而不進行判斷,這種方法較優雅些; 經過修改之後的版本在測試過程中沒有沒有再復現此問題。
問題擴展
雖然問題解決了,但官方版本中肯定存在著這個問題,為什麼 buglist 沒有找到相關信息呢,於是在查看了最新代碼,發現這個問題已經修復,修復方法為上面列的第二種方法,詳細的 commit message 信息如下:
bug影響范圍:MySQL 5.6.28 及之前的版本都有此問題。