GTID簡介
什麼是GTID
GTID(Global Transaction ID)是對於一個已提交事務的編號,並且是一個全局唯一的編號。
GTID實際上是由UUID+TID組成的。其中UUID是一個MySQL實例的唯一標識。TID代表了該實例上已經提交的事務數量,並且隨著事務提交單調遞增。下面是一個GTID的具體形式
3E11FA47-71CA-11E1-9E33-C80AA9429562:23
更詳細的介紹可以參見:官方文檔
GTID的作用
那麼GTID功能的目的是什麼呢?具體歸納主要有以下兩點:
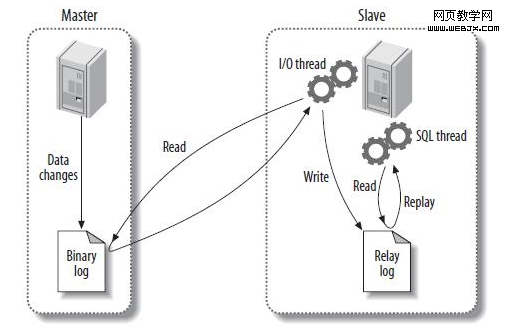
根據GTID可以知道事務最初是在哪個實例上提交的GTID的存在方便了Replication的Failover 這裡詳細解釋下第二點。我們可以看下在MySQL 5.6的GTID出現以前replication failover的操作過程。假設我們有一個如下圖的環境
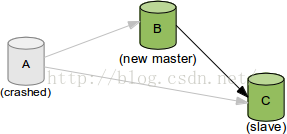
此時,Server A的服務器宕機,需要將業務切換到Server B上。同時,我們又需要將Server C的復制源改成Server B。復制源修改的命令語法很簡單即CHANGE MASTER TO MASTER_HOST='xxx', MASTER_LOG_FILE='xxx', MASTER_LOG_POS=nnnn。而難點在於,由於同一個事務在每台機器上所在的binlog名字和位置都不一樣,那麼怎麼找到Server C當前同步停止點,對應Server B的master_log_file和master_log_pos是什麼的時候就成為了難題。這也就是為什麼M-S復制集群需要使用MMM,MHA這樣的額外管理工具的一個重要原因。
這個問題在5.6的GTID出現後,就顯得非常的簡單。由於同一事務的GTID在所有節點上的值一致,那麼根據Server C當前停止點的GTID就能唯一定位到Server B上的GTID。甚至由於MASTER_AUTO_POSITION功能的出現,我們都不需要知道GTID的具體值,直接使用CHANGE MASTER TO MASTER_HOST='xxx', MASTER_AUTO_POSITION命令就可以直接完成failover的工作。 So easy不是麼?
基於GTID的主從復制簡介
搭建
搭建使用了mysql_sandbox腳本為基礎,先創建了一個一主三從的基於位置復制的環境。然後通過配置修改,將整個架構專為基於GTID的復制。
根據MySQL官方文檔給出的GTID搭建建議。需要一次對主從節點做配置修改,並重啟服務。這樣的操作,顯然在production環境進行升級時是不可接受的。Facebook,Booking.com,Percona都對此通過patch做了優化,做到了更優雅的升級。具體的操作方式會在以後的博文當中介紹到。這裡我們就按照官方文檔,進行一次實驗性的升級。
主要的升級步驟會有以下幾步:
確保主從同步在master上配置read_only,保證沒有新數據寫入修改master上的my.cnf,並重啟服務修改slave上的my.cnf,並重啟服務在slave上執行change master to並帶上master_auto_position=1啟用基於GTID的復制由於是實驗環境,read_only和服務重啟並無大礙。只要按照官方的GTID搭建建議做就能順利完成升級,這裡就不贅述詳細過程了。下面列舉了一些在升級過程中容易遇到的錯誤。
常見錯誤
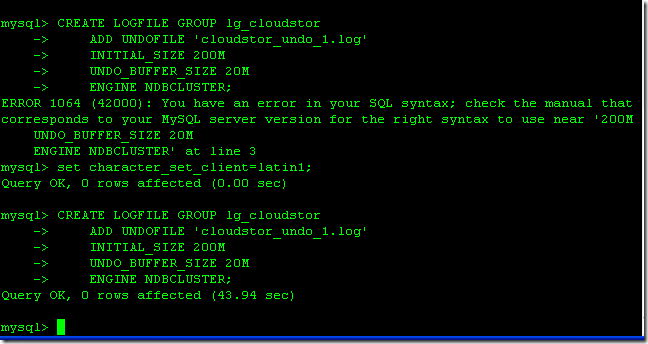
gtid_mode=ON,log_slave_updates,enforce_gtid_consistency這三個參數一定要同時在my.cnf中配置。否則在mysql.err中會出現如下的報錯
2016-10-08 20:11:08 32147 [ERROR] --gtid-mode=ON or UPGRADE_STEP_1 or UPGRADE_STEP_2 requires --log-bin and --log-slave-updates
2016-10-08 20:13:53 32570 [ERROR] --gtid-mode=ON or UPGRADE_STEP_1 requires --enforce-gtid-consistency
change master to 後的warnings
在按照文檔的操作change master to後,會發現有兩個warnings。其實是兩個安全性警告,不影響正常的同步(有興趣的讀者可以看下關於該warning的具體介紹。warning的具體內容如下:
slave1 [localhost] {msandbox} ((none)) > stop slave;
Query OK, 0 rows affected (0.03 sec)
slave1 [localhost] {msandbox} ((none)) > change master to master_host='127.0.0.1',master_port =21288,master_user='rsandbox',master_password='rsandbox',master_auto_position=1;
Query OK, 0 rows affected, 2 warnings (0.04 sec)
slave1 [localhost] {msandbox} ((none)) > show warnings;
+-------+------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Level | Code | Message |
+-------+------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Note | 1759 | Sending passwords in plain text without SSL/TLS is extremely insecure. |
| Note | 1760 | Storing MySQL user name or password information in the master info repository is not secure and is therefore not recommended. Please consider using the USER and PASSWORD connection options for START SLAVE; see the 'START SLAVE Syntax' in the MySQL Manual for more information. |
+-------+------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
2 rows in set (0.00 sec)
實驗一:如果slave所需要事務對應的GTID在master上已經被purge了
根據show global variables like '%gtid%'的命令結果我們可以看到,和GTID相關的變量中有一個gtid_purged。從字面意思以及官方文檔可以知道該變量中記錄的是本機上已經執行過,但是已經被purge binary logs to命令清理的gtid_set。
本節中我們就要試驗下,如果master上把某些slave還沒有fetch到的gtid event purge後會有什麼樣的結果。
以下指令在master上執行
master [localhost] {msandbox} (test) > show global variables like '%gtid%';
+---------------------------------+----------------------------------------+
| Variable_name | Value |
+---------------------------------+----------------------------------------+
| binlog_gtid_simple_recovery | OFF |
| enforce_gtid_consistency | ON |
| gtid_executed | 24024e52-bd95-11e4-9c6d-926853670d0b:1 |
| gtid_mode | ON |
| gtid_owned | |
| gtid_purged | |
| simplified_binlog_gtid_recovery | OFF |
+---------------------------------+----------------------------------------+
7 rows in set (0.01 sec)
master [localhost] {msandbox} (test) > flush logs;create table gtid_test2 (ID int) engine=innodb;
Query OK, 0 rows affected (0.04 sec)
Query OK, 0 rows affected (0.02 sec)
master [localhost] {msandbox} (test) > flush logs;create table gtid_test3 (ID int) engine=innodb;
Query OK, 0 rows affected (0.04 sec)
Query OK, 0 rows affected (0.04 sec)
master [localhost] {msandbox} (test) > show master status;
+------------------+----------+--------------+------------------+------------------------------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+------------------+----------+--------------+------------------+------------------------------------------+
| mysql-bin.000005 | 359 | | | 24024e52-bd95-11e4-9c6d-926853670d0b:1-3 |
+------------------+----------+--------------+------------------+------------------------------------------+
1 row in set (0.00 sec)
master [localhost] {msandbox} (test) > purge binary logs to 'mysql-bin.000004';
Query OK, 0 rows affected (0.03 sec)
master [localhost] {msandbox} (test) > show global variables like '%gtid%';
+---------------------------------+------------------------------------------+
| Variable_name | Value |
+---------------------------------+------------------------------------------+
| binlog_gtid_simple_recovery | OFF |
| enforce_gtid_consistency | ON |
| gtid_executed | 24024e52-bd95-11e4-9c6d-926853670d0b:1-3 |
| gtid_mode | ON |
| gtid_owned | |
| gtid_purged | 24024e52-bd95-11e4-9c6d-926853670d0b:1 |
| simplified_binlog_gtid_recovery | OFF |
+---------------------------------+------------------------------------------+
7 rows in set (0.00 sec)
在slave2上重新做一次主從,以下命令在slave2上執行
slave2 [localhost] {msandbox} ((none)) > change master to master_host='127.0.0.1',master_port =21288,master_user='rsandbox',master_password='rsandbox',master_auto_position=1;
Query OK, 0 rows affected, 2 warnings (0.04 sec)
slave2 [localhost] {msandbox} ((none)) > start slave;
Query OK, 0 rows affected (0.01 sec)
slave2 [localhost] {msandbox} ((none)) > show slave status\G
*************************** 1. row ***************************
......
Slave_IO_Running: No
Slave_SQL_Running: Yes
......
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 0
Relay_Log_Space: 151
......
Last_IO_Errno: 1236
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: 'The slave is connecting using CHANGE MASTER TO MASTER_AUTO_POSITION = 1, but the master has purged binary logs containing GTIDs that the slave requires.'
Last_SQL_Errno: 0
Last_SQL_Error:
......
Auto_Position: 1
1 row in set (0.00 sec)
實驗二:忽略purged的部分,強行同步
那麼實際生產應用當中,偶爾會遇到這樣的情況:某個slave從備份恢復後(或者load data infile)後,DBA可以人為保證該slave數據和master一致;或者即使不一致,這些差異也不會導致今後的主從異常(例如:所有master上只有insert沒有update)。這樣的前提下,我們又想使slave通過replication從master進行數據復制。此時我們就需要跳過master已經被purge的部分,那麼實際該如何操作呢?
我們還是以實驗一的情況為例:
先確認master上已經purge的部分。從下面的命令結果可以知道master上已經缺失24024e52-bd95-11e4-9c6d-926853670d0b:1這一條事務的相關日志
master [localhost] {msandbox} (test) > show global variables like '%gtid%';
+---------------------------------+------------------------------------------+
| Variable_name | Value |
+---------------------------------+------------------------------------------+
| binlog_gtid_simple_recovery | OFF |
| enforce_gtid_consistency | ON |
| gtid_executed | 24024e52-bd95-11e4-9c6d-926853670d0b:1-3 |
| gtid_mode | ON |
| gtid_owned | |
| gtid_purged | 24024e52-bd95-11e4-9c6d-926853670d0b:1 |
| simplified_binlog_gtid_recovery | OFF |
+---------------------------------+------------------------------------------+
7 rows in set (0.00 sec)
在slave上通過set global gtid_purged='xxxx'的方式,跳過已經purge的部分
slave2 [localhost] {msandbox} ((none)) > stop slave;
Query OK, 0 rows affected (0.04 sec)
slave2 [localhost] {msandbox} ((none)) > set global gtid_purged = '24024e52-bd95-11e4-9c6d-926853670d0b:1';
Query OK, 0 rows affected (0.05 sec)
slave2 [localhost] {msandbox} ((none)) > start slave;
Query OK, 0 rows affected (0.01 sec)
slave2 [localhost] {msandbox} ((none)) > show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
......
Master_Log_File: mysql-bin.000005
Read_Master_Log_Pos: 359
Relay_Log_File: mysql_sandbox21290-relay-bin.000004
Relay_Log_Pos: 569
Relay_Master_Log_File: mysql-bin.000005
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
......
Exec_Master_Log_Pos: 359
Relay_Log_Space: 873
......
Master_Server_Id: 1
Master_UUID: 24024e52-bd95-11e4-9c6d-926853670d0b
Master_Info_File: /data/mysql/rsandbox_mysql-5_6_23/node2/data/master.info
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Slave has read all relay log; waiting for the slave I/O thread to update it
......
Retrieved_Gtid_Set: 24024e52-bd95-11e4-9c6d-926853670d0b:2-3
Executed_Gtid_Set: 24024e52-bd95-11e4-9c6d-926853670d0b:1-3
Auto_Position: 1
1 row in set (0.00 sec)
可以看到此時slave已經可以正常同步,並補齊了24024e52-bd95-11e4-9c6d-926853670d0b:2-3范圍的binlog日志。
以上所述是小編給大家介紹的MySQL 5.6 GTID新特性實踐,希望對大家有所幫助,如果大家有任何疑問請給我留言,小編會及時回復大家的。在此也非常感謝大家對網站的支持!