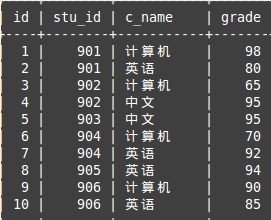
在 MySQL 查詢中,可能會包含重復值。這並不成問題,不過,有時您也許希望僅僅列出不同(distinct)的值。
關鍵詞 DISTINCT 用於返回唯一不同的值,就是去重啦。用法也很簡單:
SELECT DISTINCT * FROM tableName
DISTINCT 這個關鍵字來過濾掉多余的重復記錄只保留一條。
另外,如果要對某個字段去重,可以試下:
SELECT *, COUNT(DISTINCT nowamagic) FROM table GROUP BY nowamagic
這個用法,MySQL的版本不能太低。
在編寫查詢之前,我們甚至應該對過濾條件進行排序,真正高效的條件(可能有多個,涉到同的表)是查詢的主要驅動力,低效條件只起輔助作用。那麼定義高效過濾條件的准則是什呢?首先,要看過濾條件能否盡快減少必須處理的數據量。所以,我們必須倍加關注條件的寫方式。
假設有四個表: customers 、 orders 、 orderdetail 、 articles ,現在假設 SQL 要處理的問題是:找出最近六個月內居住在 Gotham 市、訂購了蝙蝠車的所有客戶。當然,編寫這個查詢有多種方法, ANSI SQL 的推崇者可能寫出下列語句:
select distinct c.custname from customers c join orders o on o.custid = c.custid join orderdetail od on od.ordid = o.ordid join articles a on a.artid = od.artid where c.city = 'GOTHAM' and a.artname = 'BATMOBILE' and o.ordered >= somefunc
其中, somefunc 是個函數,返回距今六個月前的具體日期。注意上面用了 distinct ,因為考慮到某個客戶可以是大買家,最近訂購了好幾台蝙蝠車。
暫不考慮優化器將如何改寫此查詢,我們先看一下這段代碼的含義。首先,來自 customers 表的數據應只保留城市名為 Gotham 的記錄。接著,搜索 orders 表,這意味著 custid 字段最好有索引,否則只有通過排序、合並或掃描 orders 表建立一個哈希表才能保證查詢速度。對 orders 表 ,還要針對訂單日期進行過濾:如果優化器比較聰明,它會在連接( join )前先過濾掉一些數據,從而減少後面要處理的數據量;不太聰明的優化器則可能會先做連接,再作過濾,這時在連接中指定過濾條件利於提高性能,例如:
join orders o on o.custid = c.custid and a.ordered >= somefunc
注意,如果是:
left outer join orders o on o.custid = c.custid and a.ordered >= somefunc
此處關於left表的篩選條件將失效,因為是左外連接,左表的所有列都將出現在這次連接結果集中)。
即使過濾條件與連接( join )無關,優化器也會受到過濾條件的影響。例如,若 orderdetail 的主鍵為( ordid, artid ),即 ordid 為索引的第一個屬性,那麼我們可以利用索引找到與訂單相關的記錄。但如果主鍵是( artid, ordid )就太不幸了(注意,就關系理論而言 ,無論哪個版本都是完全一樣),此時的訪問效率比( ordid, artid )作為索引時要差,甚至一些數據庫產品無法使用該索引(注 3 ),唯一的希望就是在ordid 上加獨立索引了。
連接了表 orderdetail 和 orders 之後,來看 articles 表,這不會有問題,因為表 order 包括 artid 字段。最後,檢查 articles 中的值是否為 Batmobile 。查詢就這樣結束了,因為用了 distinct ,通過層層篩選的客戶名還必須要排序,以剔除重復項目。
避免在最高層使用 distinct 應該是一條基本規則 。原因在於,即使我們遺漏了連接的某個條件, distinct 也會使查詢 " 看似正確 " 地執行 —— 無可否認,發現重復數據容易,發現數據不准確很難,所以避免在最高層使用 distinct 應該是一條基本規則。
發現結果不正確更難,例如,如果恰巧有多位客戶都叫 " Wayne " , distinct 不但會剔除由同個客戶的多張訂單產生的重復項目,也會剔除由名字相同的不同客戶產生的重復項目。事實上,應該同時返回具唯一性的客戶 ID 和客戶名,以保證得到蝙蝠車買家的完整清單。
要擺脫 distinct ,可考慮以下思路:客戶在 Gohtam 市,而且滿足存在性測試,即在最近六個月訂購過蝙蝠車。注意,多數(但非全部) SQL 方言支持以下語法:
select c.custname from customers c where c.city = 'GOTHAM' and exists (select null from orders o, orderdetail od, articles a where a.artname = 'BATMOBILE' and a.artid = od.artid and od.ordid = o.ordid and o.custid = c.custid and o.ordered >= somefunc )
上例的存在性測試,同一個名字可能出現多次,但每個客戶只出現一次,不管他有多少訂單。有人認為我對 ANSI SQL 語法的挑剔有點苛刻(指 " 蝙蝠車買主 " 的例子),因為上面代碼中customers 表的地位並沒有降低。其實,關鍵區別在於,新查詢中 customers 表是查詢結果的唯一來源(嵌套的子查詢會負責找出客戶子集),而先前的查詢卻用了 join 。
這個嵌套的子查詢與外層的 select 關系十分密切。如代碼第 11 行所示(粗體部分),子查詢參照了外層查詢的當前記錄,因此,內層子查詢就是所謂的關聯子查詢( correlated subquery )。
此類子查詢有個弱點,它無法在確定當前客戶之前執行。如果優化器不改寫此查詢,就必須先找出每個客戶,然後逐一檢查是否滿足存在性測試,當來自 Gotham 市的客戶非常少時執行效率倒是很高,否則情況會很糟(此時,優秀的優化器應嘗試其他執行查詢的方式)。
select custname from customers where city = 'GOTHAM' and custid in (select o.custid from orders o, orderdetail od, articles a where a.artname = 'BATMOBILE' and a.artid = od.artid and od.ordid = o.ordid and o.ordered >= somefunc)
在這個例子中,內層查詢不再依賴外層查詢,它已變成了非關聯子查詢( uncorrelated subquery ),只須執行一次。很顯然,這段代碼采用了原有的執行流程。在本節的前一個例子 中 ,必須先搜尋符合地點條件的客戶(如均來自 GOTHAM ),接著依次檢查各個訂單。而現在,訂購了蝙蝠車的客戶,可以通過內層查詢獲得。
不過,如果更仔細地分析一下,前後兩個版本的代碼還有些更微妙的差異。含關聯子查詢的代碼中,至關重要的是 orders 表中的 custid 字段要有索引,而這對另一段代碼並不重要,因為這時要用到的索引(如果有的話)是表 customers 的主鍵索引。
你或許注意到,新版的查詢中執行了隱式的 distinct 。的確,由於連接操作,子查詢可能會返回有關一個客戶的多條記錄。但重復項目不會有影響,因為 in 條件只檢查該項目是否出現在子查詢返回的列表中,且 in 不在乎某值在列表中出現了一次還是一百次。但為了一致性,作為整體,應該對子查詢和主查詢應用相同的規則,也就是在子查詢中也加入存在性測試:
select custname from customers where city = 'GOTHAM' and custid in (select o.custid from orders o where o.ordered >= somefunc and exists (select null from orderdetail od, articles a where a.artname = 'BATMOBILE' and a.artid = od.artid and od.ordid = o.ordid))
或者
select custname from customers where city = 'GOTHAM' and custid in (select custid from orders where ordered >= somefunc and ordid in (select od.ordid from orderdetail od, articles a where a.artname = 'BATMOBILE' and a.artid = od.artid)
盡管嵌套變得更深、也更難懂了,但子查詢內應選擇 exists 還是 in 的選擇規則相同:此選擇取決於日期與商品條件的有效性。除非過去六個月的生意非常清淡,否則商品名稱應為最有效的過濾條件,因此子查詢中用 in 比 exists 好,這是因為,先找出所有蝙蝠車的訂單、再檢查銷售是否發生在最近六個月,比反過來操作要快。如果表 orderdetail 的 artid 字段有索引,這個方法會更快,否則,這個聰明巧妙的舉措就會黯然失色。
每當對大量記錄做存在性檢查時,選擇 in 還是 exists 須斟酌。
利於多數 SQL 方言,非關聯子查詢可以被改寫成 from 子句中的內嵌視圖。然而,一定要記住的是, in 會隱式地剔除重復項目,當子查詢改寫為 from 子句中的內嵌視圖時,必須要顯式地消除重復項目。例如:
select custname from customers where city = 'GOTHAM' and custid in (select o.custid from orders o, (select distinct od.ordid from orderdetail od, articles a where a.artname = 'BATMOBILE' and a.artid = od.artid) x where o.ordered >= somefunc and x.ordid = o.ordid)
總結:保證 SQL 語句返回正確結果,只是建立最佳 SQL 語句的第一步。