1.測試環境
OS:Linux
DB:mysql-5.5.18
table:innodb存儲引擎
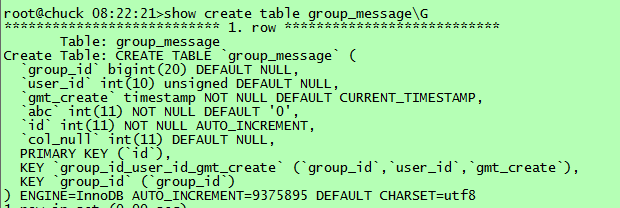
表定義如下:
2. 測試場景與分析【統計表group_message的記錄數目】
(1)select count(*)方式

(2)select count(1)方式

(3)select count(col_name)方式
分別使用
select count(group_id)
select count(user_id)
select count(col_null)
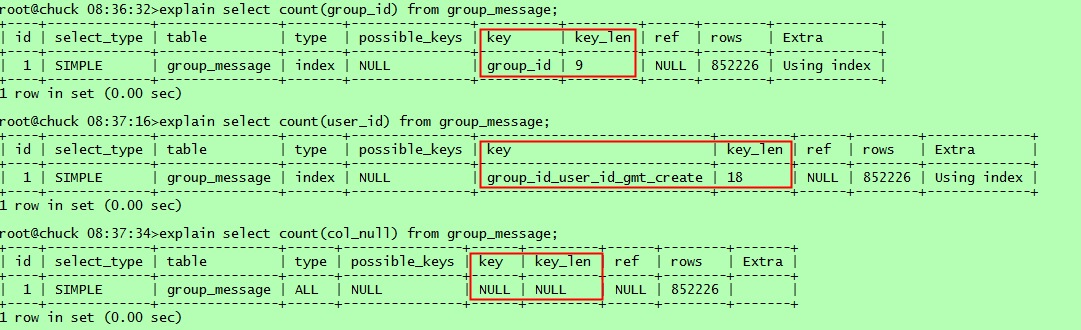
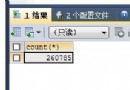
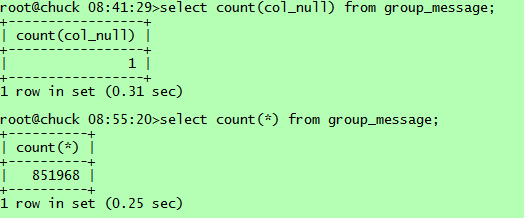
通過上述測試結果可以看到,select count(*)和select count(1)都使用了group_id這個最短的二級索引。可能有人會問為啥不用更短的主鍵索引【int類型】呢,這主要是因為innodb存儲引擎下,主鍵索引實質包含了索引和數據,掃描主鍵索引實際是掃描物理記錄,代價實質是最大的。再來看看幾種select count(col_name), count(group_id)使用了最短二級索引,因為該列就是索引列;而count(user_id)則使用了組合索引,由於user_id實質不能利用該索引,但掃描索引也能得到記錄數,而且比掃描物理記錄代價小,這裡應該是mysql的一個優化;count(col_null)則不能使用索引,因為該列含有null值,所以效率最低。另外,對於含有null值的行,count(col_null)實際不會統計,這會與你想統計表記錄數目的初衷不符,比如測試表有852226條記錄,但col_null列只有1行非空,則統計結果如下:
3.測試結論
mysql中,需要通過selct count 統計表記錄數目時,使用count(*)或count(1)就好。