會經常發現開發人員查一下沒用索引的語句或者沒有limit n的語句,這些沒語句會對數據庫造成很大的影響,例如一個幾千萬條記錄的大表要全部掃描,或者是不停的做filesort,對數據庫和服務器造成io影響等。這是鏡像庫上面的情況。
而到了線上庫,除了出現沒有索引的語句,沒有用limit的語句,還多了一個情況,mysql連接數過多的問題。說到這裡,先來看看以前我們的監控做法
1. 部署zabbix等開源分布式監控系統,獲取每天的數據庫的io,cpu,連接數
2. 部署每周性能統計,包含數據增加量,iostat,vmstat,datasize的情況
3. Mysql slowlog收集,列出top 10
以前以為做了這些監控已經是很完美了,現在部署了mysql節點進程監控之後,才發現很多弊端
第一種做法的弊端: zabbix太龐大,而且不是在mysql內部做的監控,很多數據不是非常准備,現在一般都是用來查閱歷史的數據情況
第二種做法的弊端:因為是每周只跑一次,很多情況沒法發現和報警
第三種做法的弊端: 當節點的slowlog非常多的時候,top10就變得沒意義了,而且很多時候會給出那些是一定要跑的定期任務語句給你。。參考的價值不大
那麼我們怎麼來解決和查詢這些問題呢
對於排查問題找出性能瓶頸來說,最容易發現並解決的問題就是MYSQL的慢查詢以及沒有得用索引的查詢。
OK,開始找出mysql中執行起來不“爽”的SQL語句吧。
=========================================================
方法一: 這個方法我正在用,呵呵,比較喜歡這種即時性的。
復制代碼 代碼如下:
Mysql5.0以上的版本可以支持將執行比較慢的SQL語句記錄下來。
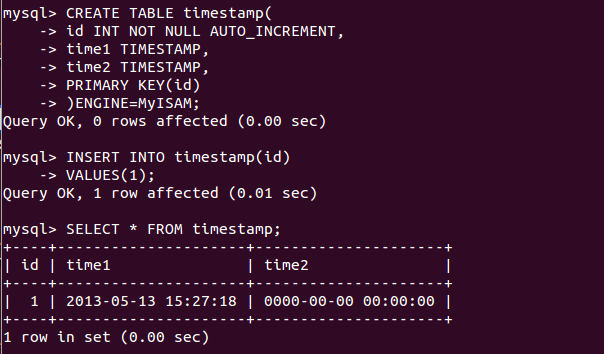
mysql> show variables like 'long%'; 注:這個long_query_time是用來定義慢於多少秒的才算“慢查詢”
+-----------------+-----------+
| Variable_name | Value |
+-----------------+-----------+
| long_query_time | 10.000000 |
+-----------------+-----------+
1 row in set (0.00 sec)
mysql> set long_query_time=1; 注: 我設置了1, 也就是執行時間超過1秒的都算慢查詢。
Query OK, 0 rows affected (0.00 sec)
mysql> show variables like 'slow%';
+---------------------+---------------+
| Variable_name | Value |
+---------------------+---------------+
| slow_launch_time | 2 |
| slow_query_log | ON | 注:是否打開日志記錄
| slow_query_log_file | /tmp/slow.log | 注: 設置到什麼位置
+---------------------+---------------+
3 rows in set (0.00 sec)
mysql> set global slow_query_log='ON' 注:打開日志記錄
一旦slow_query_log變量被設置為ON,mysql會立即開始記錄。
/etc/my.cnf 裡面可以設置上面MYSQL全局變量的初始值。
long_query_time=1
slow_query_log_file=/tmp/slow.log
方法二:mysqldumpslow命令
復制代碼 代碼如下:
/path/mysqldumpslow -s c -t 10 /tmp/slow-log
這會輸出記錄次數最多的10條SQL語句,其中:
-s, 是表示按照何種方式排序,c、t、l、r分別是按照記錄次數、時間、查詢時間、返回的記錄數來排序,ac、at、al、ar,表示相應的倒敘;
-t, 是top n的意思,即為返回前面多少條的數據;
-g, 後邊可以寫一個正則匹配模式,大小寫不敏感的;
比如
/path/mysqldumpslow -s r -t 10 /tmp/slow-log
得到返回記錄集最多的10個查詢。
/path/mysqldumpslow -s t -t 10 -g “left join” /tmp/slow-log
得到按照時間排序的前10條裡面含有左連接的查詢語句。
最後總結一下節點監控的好處
1. 輕量級的監控,而且是實時的,還可以根據實際的情況來定制和修改
2. 設置了過濾程序,可以對那些一定要跑的語句進行過濾
3. 及時發現那些沒有用索引,或者是不合法的查詢,雖然這很耗時去處理那些慢語句,但這樣可以避免數據庫掛掉,還是值得的
4. 在數據庫出現連接數過多的時候,程序會自動保存當前數據庫的processlist,DBA進行原因查找的時候這可是利器
5. 使用mysqlbinlog 來分析的時候,可以得到明確的數據庫狀態異常的時間段
有些人會建義我們來做mysql配置文件設置
調節tmp_table_size 的時候發現另外一些參數
Qcache_queries_in_cache 在緩存中已注冊的查詢數目
Qcache_inserts 被加入到緩存中的查詢數目
Qcache_hits 緩存采樣數數目
Qcache_lowmem_prunes 因為缺少內存而被從緩存中刪除的查詢數目
Qcache_not_cached 沒有被緩存的查詢數目 (不能被緩存的,或由於 QUERY_CACHE_TYPE)
Qcache_free_memory 查詢緩存的空閒內存總數
Qcache_free_blocks 查詢緩存中的空閒內存塊的數目
Qcache_total_blocks 查詢緩存中的塊的總數目
Qcache_free_memory 可以緩存一些常用的查詢,如果是常用的sql會被裝載到內存。那樣會增加數據庫訪問速度。