SELECT語句,去除某個字段的重復信息,例如:
表名:table
id uid username message dateline
1 6 a 111 1284240714(時間戳)
2 6 a 222 1268840565
3 8 b 444 1266724527
4 9 c 555 1266723391
執行語句(去除username字段重復信息並按時間排序):
SELECT *
FROM table a INNER JOIN ( SELECT max( dateline ) AS dateline
FROM table GROUP BY uid ) b ON a.dateline = b.dateline
GROUP BY id ORDER BY a.dateline DESC
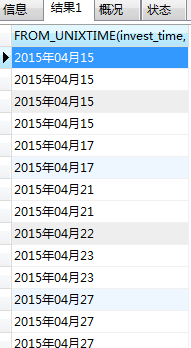
結果:
id uid username message dateline
1 6 a 111 1284240714(時間戳)
3 8 b 444 1266724527
4 9 c 555 1266723391
此語句用於顯示最新記錄信息,在一個區域內不允許某個信息(例如:用戶)同時出現多次(一次以上)。
後記:效率問題
開始用了個這語句:
select * from table where dateline IN ( select max(dateline) from table GROUP BY uid ) ORDER BY dateline DESC
IN:當處理數據量比較大的時候,就沒效率可言了,所以優化成內聯,計算下快了6倍多。。。
繼續條效率就加索引了~~