我們已經知道了如何開始和結束與服務器的會話,現在應該看看如何控制會話。本節介紹了如何與服務器通信以處理查詢。執行的每個查詢應包括以下幾步:
1) 構造查詢。查詢的構造取決於查詢的內容—特別要看是否含有二進制數據。
2) 通過將查詢發送到服務器執行來發布查詢。
3) 處理查詢結果。這取決於發布查詢的類型。例如, SELECT 語句返回數據行等待處理,INSERT 語句就不這樣。構造查詢的一個要素就是使用哪個函數將查詢發送到服務器。較通用的發布查詢例程是mysql_ real _ query ( )。該例程給查詢提供了一個計數串(字符串加上長度)。必須了解查詢串的長度,並將它們連同串本身一起傳遞給MySQL_real_query() 。因為查詢是一個計數的字符串,
所以它的內容可能是任何東西,其中包括二進制數據或者空字節。查詢不能是空終結串。另一個發布查詢的函數, mysql_ query ( ),在查詢字符串允許的內容上有更多的限制,但更容易使用一些。傳遞到mysql_query() 的查詢應該是空終結串,這說明查詢內部不能含有空字節(查詢裡含有空字節會導致錯誤地中斷,這比實際的查詢內容要短)。一般說來,如果查詢包含任意的二進制數據,就可能包含空字節,因此不要使用MySQL_ query( )。另一方面,當處理空終結串時,使用熟悉的標准C 庫字符串函數構造查詢是很耗費資源的,例如strcpy ( )和sprintf( )。
構造查詢的另一個要素就是是否要執行溢出字符的操作。如果在構造查詢時使用含有二
進制數據或者其他復雜字符的值時,如引號、反斜線等,就需要使用這個操作。這些將在
6.8.2節“對查詢中有疑問的數據進行編碼”中討論。
下面是處理查詢的簡單輪廓:

mysql_query() 和MySQL_real_query() 的查詢成功都會返回零值,查詢失敗返回非零值。查詢成功指服務器認為該查詢有效並接受,而且能夠執行,並不是指有關該查詢結果。例如,它不是指SELECT 查詢所選擇的行,或DELETE 語句所刪除的行。檢查查詢的實際結果要包括其他的處理。
查詢失敗可能有多種原因,有一些常見的原因如下:
■ 含有語法錯誤。
■ 語義上是非法的—例如涉及對表中不存在的列的查詢。
■ 沒有足夠的權利訪問查詢所引用的數據。
查詢可以分成兩大類:不返回結果的查詢和返回結果的查詢。INSERT、DELETE和UPDATE等語句屬於“不返回結果”類的查詢,即使對修改數據庫的查詢,它們也不返回任何行。可返回的唯一信息就是有關受作用的行數。SELECT 語句和SHOW 語句屬於“返回結果”類的查詢;發布這些語句的目的就是要返回某些信息。返回數據的查詢所生成的行集合稱為結果集,在MySQL中表示為MySQL_RES 數據類型,這是一個包含行的數據值及有關這些值的元數據(如列名和數據值的長度)的結構。空的結果集(就是包含零行的結果)要與“沒有結果”區分開。
6.6.1處理不返回結果集的查詢
處理不返回結果集的查詢,用mysql_query() 或mysql_real_query() 發布查詢。如果查詢成功,可以通過調用MySQL_ a ffected_rows() 找出有多少行需要插入、刪除或修改。下面的樣例說明如何處理不返回結果集的查詢:
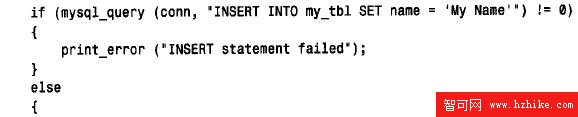

請注意在打印時mysql_ a ffected_rows() 的結果是如何轉換為unsigned long 類型的,這個函數返回一個my_ulonglong 類型的值,但在一些系統上無法直接打印這個類型的值(例如,筆者觀察到它可在FreeBSD 下工作,但不能在Solaris 下工作)。把值轉換為unsigned long 類型並使用‘% l u’打印格式可以解決這個問題。同樣也要考慮返回my_ulonglong 值的其他函數,如mysql_num_rows() 和MySQL_ insert _ id ( )。如果想使客戶機程序能跨系統地移植,就要謹記這一點。
mysql_ rows _ affected() 返回查詢所作用的行數,但是“受作用的行”的含義取決於查詢的類型。對於INSERT、DELETE 和UPDATE,是指插入、刪除或者更新的行數,也就是MySQL實際修改的行數。如果行的內容與所要更新的內容相同,則MySQL就不再更新行。這就是說雖然可能選擇行來更新(通過UPDATE 語句的WHERE 子句),但實際上該行可能並未改變。
對於UPDATE,“受作用的行”的意義實際上是個爭論點,因為人們想把它當成“被匹配的行”—即選擇要更新的行數,即使更新操作實際上並未改變其中的值也是如此。如果應用程序需要這個信息, 則當與服務器連接時可以用它來請求以實現這個功能。將CLIENT_FOUND_ROWS 的flags 值傳遞給mysql_ real _ connect( )。也可以將CLIENT _ FOUND _ROWS 作為flags 參數傳遞給do _ connect ( );它將把值傳遞給MySQL_ real _ connect( )。
6.6.2 處理返回結果集的查詢
通過調用mysql_query() 和mysql_real_query() 發布查詢之後,返回數據的查詢以結果集形式進行。在MySQL中實現它非常重要, SELECT 不是返回行的唯一語句, SHOW、DESCRIBE 和EXPLAIN 都需要返回行。對所有這些語句,都必須在發布查詢後執行另外的處理行操作。
處理結果集包括下面幾個步驟:
■ 通過調用mysql_store_result() 或mysql_use_result() 產生結果集。這些函數如果成功則返回MYSQL_RES 指針,失敗則返回N U LL。稍後我們將查看mysql_store_result() 與MySQL_use_result() 的不同,以及選擇其中一個而不選另一個時的情況。我們的樣例使
用MySQL_ store _ result( ),它能立即從服務器返回行,並將它們存儲到客戶機中。
■ 對結果集的每一行調用mysql_ fetch _ rows ( )。這個函數返回MYSQL_ROW 值,它是一個指向字符串數組的指針,字符串數組表示行中每列的值。要根據應用程序對行進行操作。可以只打印出列值,執行有關的統計計算,或者做些其他操作。當結果集中不再有行時, MySQL_fetch_rows() 返回NULL。
■ 處理結果集時,調用MySQL_free_result() 釋放所使用的內存。如果忽略了這一點,則應用程序就會洩露出內存(對於長期運行的應用程序,適當地解決結果集是極其重要的;否則,會注意到系統將由一些過程所取代,這些過程消耗著經常增長的系統資源量)。
下面的樣例輪廓介紹了如何處理返回結果集的查詢:
我們通過調用函數process_result_set() 來處理每一行,這裡有個竅門,因為我們並沒有定義這個函數,所以需要這樣做。通常,結果的處理集函數是基於下面的循環:

從mysql_fetch_row() 返回的MYSQL_ROW 值是一個指向數值數組的指針,因此,訪問每個值就是訪問row[i],這裡i 的范圍是從0到該行的列數減1。這裡有幾個關於MySQL_ROW 數據類型的要點需要注意:
■ MYSQL_ROW 是一個指針類型,因此,必須聲明類型變量為MYSQL_ROW row,而不是MySQL_ROW *row。
■ MySQL_ROW 數組中的字符串是空終結的。但是,列可能含有二進制數據,這樣,數據中就可能含有空字節,因此,不應該把值看成是空終結的。由列的長度可知列值有多長。
■ 所有數據類型的值都是作為字符串返回的,即使是數字型的也是如此。如果需要該值為數字型,就必須自己對該字符串進行轉換。
■ 在MySQL_ROW 數組中,NULL 指針代表NULL,除非聲明列為NOT NULL,否則應該經常檢查列值是否為NULL 指針。
應用程序可以利用每行的內容做任何想做的事,為了舉例說明這一點,我們只打印由制表符隔開列值的行,為此還需要另外一個函數, MySQL_num_fIElds() ,它來自於客戶機庫;這個函數告知我們該行包括多少個值(列)。
下面就是process_result_set() 的代碼:
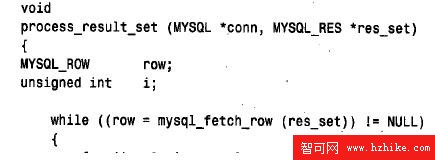

process_result_set() 以制表符分隔的形式打印每一行(將NULL值顯示為單詞“NULL”),它跟在被檢索的行計數的後面, 該計數通過調用mysql_num_rows() 來計算。像mysql_ affected_rows() 一樣,MySQL_num_rows() 返回my_ulonglong 值,因此,將值轉換為
unsigned long 型,並用‘% l u’ 格式打印。
提取行的循環緊接在一個錯誤檢驗的後面,如果要用MySQL_store_result() 創建結果集,
mysql_fetch_row() 返回的NULL值通常意味著“不再有行”。然而,如果用mysql_ use _ result( )創建結果集,則MySQL_fetch_row() 返回的NULL 值通常意味著“不再有行”或者發生了錯誤。無論怎樣創建結果集,這個測試只允許process_result_set() 檢測錯誤。
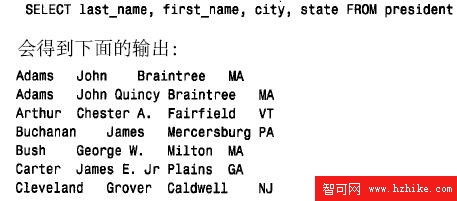
process_result_set() 的這個版本是打印列值要求條件最低的方法,每種方法都有一定的缺點,例如假設執行下面的查詢:
我們可以通過提供一些信息如列標簽,及通過使這些值垂直排列,而使輸出結果漂亮一點。為此,我們需要標簽和每列所需的最寬的值。這個信息是有效的,但不是列數據值的一部分,而是結果集的元數據的一部分(有關數據的數據)。簡單歸納了一下查詢處理程序後,我們將在6 . 6 . 6節“使用結果集元數據”中給出較漂亮的顯示格式。
打印二進制數據
對包含可能含有空字節的二進制數據的列值,使用‘ % s’printf() 格式標識符不能將它正確地打印; printf() 希望一個空終結串,並且直到第一個空字節才打印列值。對於二進制數據,最好用列的長度,以便打印完整的值,如可以用fwrite() 或putc( )。
6.6.3 通用目標查詢處理程序
前面介紹的處理查詢樣例應用了語句是否應該返回一些數據的知識來編寫的。這是可能的,因為查詢固定在代碼內部:使用INSERT 語句時,它不返回結果,使用SHOW TABLES語句時,才返回結果。
然而,不可能始終知道查詢用的是哪一種語句,例如,如果執行一個從鍵盤鍵入或來源於文件的查詢,則它可能是任何的語句。不可能提前知道它是否會返回行。當然不想對查詢做語法分析來決定它是哪類語句,總之,並不像看上去那樣簡單。只看第一個單詞是不夠的,因為查詢也可能以注釋語句開始,例如:
/* comment * / SELECT
幸運的是不必過早地知道查詢類型就能夠正確地處理它。用MySQLC API 可編寫一個能很好地處理任何類型語句的通用目標查詢處理程序,無論它是否會返回結果。在編寫查詢處理程序的代碼之前,讓我們簡述一下它是如何工作的:
■ 發布查詢,如果失敗,則結束。
■ 如果查詢成功,調用MySQL_store_result() 從服務器檢索行,並創建結果集。
■ 如果mysql_store_result() 失敗,則查詢不返回結果集,或者在檢索這個結果集時發生錯誤。可以通過把連接處理程序傳遞到MySQL_fIEld_count() 中,並檢測其值來區別這兩種情況,如下:
■ 如果MySQL_fIEld_count() 非零,說明有錯誤,因為查詢應該返回結果集,但卻沒有。這種情況發生有多種原因。例如:結果集可能太大,內存分配失敗,或者在提取行時客戶機和服務器之間發生網絡中斷。
這種過程稍微有點復雜之處就在於, MySQL3.22.24 之前的早期版本中不存在mysql_ field _ count( ),它們使用的是mysql_ num _ fIElds ( )。為編寫MySQL任何版本都能運行的程序,在調用MySQL_fIEld_count() 的文件中都包含下面的代碼塊:

這就將對mysql_fIEld_count() 的一些調用看作是比MySQL3.22.24 更早版本中的MySQL_num_fIElds() 的調用。
■ 如果MySQL_fIEld_count() 返回0,就意味著查詢不返回結果(這說明查詢是類似於INSERT、DELETE、或UPDATE 的語句)。
■ 如果mysql_store_result() 成功,查詢返回一個結果集,通過調用MySQL_fetch_row() 來處理行,直到它返回NULL 為止。
下面的列表說明了處理任意查詢的函數,給出了連接處理程序和空終結查詢字符串:


6.6.4 可選擇的查詢處理方法
process_query() 的這個版本有三個特性:
■ 用MySQL_query() 發布查詢。
■ 用MySQL_store_query() 檢索結果集。
■ 沒有得到結果集時,用MySQL_fIEld_count() 把錯誤事件和不需要的結果集區別開來。針對查詢處理的這些特點,有如下三種方法:
■ 可以用計數查詢字符串和mysql_ real _ query( ),而不使用空終結查詢字符串和MySQL_ query( )。
■ 可以通過調用mysql_use_result() 而不是調用MySQL_store_result() 來創建結果集。
■ 可以調用mysql_error() 而不是調用MySQL_fIEld_count() 來確定結果集是檢索失敗還是僅僅沒有設置檢索。
可用以上部分或全部方法代替process _ query( )。以下是一個process_real_query() 函數,它與process_query() 類似,但使用了所有三種方法:


6.6.5 mysql_store_result() 與MySQL_use_result() 的比較
函數mysql_store_result() 與mysql_use_result() 類似,它們都有連接處理程序參數,並返回結果集。但實際上兩者間的區別還是很大的。兩個函數之間首要的區別在於從服務器上檢索結果集的行。當調用時, mysql_store_result() 立即檢索所有的行,而mysql_use_result() 啟動查詢,但實際上並未獲取任何行, mysql_store_result() 假設隨後會調用MySQL_ fetch _ row( )檢索記錄。這些行檢索的不同方法引起兩者在其他方面的不同。本節加以比較,以便了解如何選擇最適合應用程序的方法。
當mysql_store_result() 從服務器上檢索結果集時,就提取了行,並為之分配內存,存儲到客戶機中,隨後調用mysql_fetch_row() 就再也不會返回錯誤,因為它僅僅是把行脫離了已經保留結果集的數據結構。mysql_fetch_row() 返回NULL 始終表示已經到達結果集的末端。相反,mysql_use_result() 本身不檢索任何行,而只是啟動一個逐行的檢索,就是說必須對每行調用mysql_fetch_row() 來自己完成。既然如此,雖然正常情況下, mysql_ fetch _ row( )返回NULL 仍然表示此時已到達結果集的末端,但也可能表示在與服務器通信時發生錯誤。可通過調用mysql_errno() 和MySQL_error() 將兩者區分開來。
與mysql_use_result() 相比,mysql_store_result() 有著較高的內存和處理需求,因為是在客戶機上維護整個結果集,所以內存分配和創建數據結構的耗費是非常巨大的,要冒著溢出內存的危險來檢索大型結果集,如果想一次檢索多個行,可用mysql_ use _result( )。mysql_use_result() 有著較低的內存需求,因為只需給每次處理的單行分配足夠的空間。這樣速度就較快,因為不必為結果集建立復雜的數據結構。另一方面, mysql_use_result() 把較大的負載加到了服務器上,它必須保留結果集中的行,直到客戶機看起來適合檢索所有的行。這就使某些類型的客戶機程序不適用MySQL_ use _ result( ):
■ 在用戶的請求下提前逐行進行的交互式客戶機程序(不必僅僅因為用戶需要喝杯咖啡而讓服務器等待發送下一行)。
■ 在行檢索之間做了許多處理的客戶機程序。在所有這些情況下,客戶機程序都不能很快檢索結果集的所有行,它限制了服務器,並對其他客戶機程序產生負面的影響,因為檢索數據的表在查詢過程中是讀鎖定的。要更新表的客戶機或要插入行的任何客戶機程序都被阻塞。
偏移由mysql_store_result() 引起的額外內存需求對一次訪問整個結果集帶來相當的好處。結果集中的所有行都是有效的,因此,可以任意訪問: mysql_ data _ seek( )、mysql_ rowseek( )和mysql_row_tell() 函數允許以任意次序訪問行。而mysql_use_result() 只能以mysql_fetch_row() 檢索的順序訪問行。如果想要以任意次序而不是從服務器返回的次序來處理行,就必須使用mysql_ store _ result( )。例如,如果允許用戶來回地浏覽查詢所選的行,最好使用MySQL_ store _ result( )。
使用mysql_store_result() 可以獲得在使用mysql_use_result() 時是無效的某些類型的列信息。通過調用mysql_num_rows() 來獲得結果集的行數,每列中的這些值的最大寬度值存儲在MYSQL_FIELD 列信息結構的max_width 成員中。使用mysql_ use _ result( ),直到提取完所有的行,MySQL_num_rows() 才會返回正確值,而且max_width 無效,因為只有在每行的數據都顯示後才能計算。
由於mysql_use_result() 比mysql_store_result() 執行更少的操作,所以mysql_ use _ result( )就強加了一個mysql_store_result() 沒有的需求:即客戶機對結果集中的每一行都必須調用mysql_ fetch _ row( ),否則,結果集中剩余的記錄就會成為下一個查詢結果集中的一部分,並且發生“不同步”的錯誤。這種情形在使用MySQL_store_result() 時不會發生,因為當函數返
回時,所有的行就已被獲取。事實上,使用mysql_store_result() 就不必再自己調用MySQL_ fetch _ row( )。對於所有感興趣的事情就是是否得到一個非空的結果,而不是結果所包含的內容的查詢來說,它是很有用的。例如,要知道表my_tbl 是否存在,可以執行下面的查詢:
SHOW TABLES LIKE "my_tb1"
如果在調用mysql_store_result() 之後,mysql_num_rows() 的值為非零,這個表就存在,就不必再調用mysql_fetch_row() (當然仍需調用mysql_ free _ result( ))。如果要提供最大的靈活性,就給用戶選擇使用任一結果集處理方法的選項。mysql和mysqldump 是執行這個操作的兩個程序,缺省時,使用mysql_ store _ result( ),但是如果指定--quick 選項,則使用MySQL_ use _ result( )。
6.6.6 使用結果集元數據
結果集不僅包括數據行的列值,而且還包括數據信息,這些信息成為元數據結果集,包括:
■ 結果集中的行數和列數,通過調用mysql_num_rows() 和MySQL_num_fIElds() 實現。
■ 行中每列值的長度,通過調用MySQL_fetch_lengths() 實現。
■ 有關每列的信息, 例如列名和類型、每列值的最大寬度和列來源的表等。
MYSQL_FIELD 結構存儲這些信息,通過調用mysql_fetch_fields() 來獲得它。附錄F詳細地描述了MYSQL_FIELD 結構,並列出了提供訪問列信息的所有函數。元數據的有效性部分決定於結果集的處理方法,如在上節中提到的,如果要使用行計數或者列長度的最大值,就必須用mysql_store_result() 而不是MySQL_use_result() 創建結果集。結果集元數據對確定有關如何處理結果集非常有幫助:
■ 列名和寬度信息對漂亮地生成帶有列標題並垂直排列的格式化輸出是非常有用的。
■ 使用列計數來確定處理數據行的連續列值的循環所迭代的次數。如果要分配取決於結果集中已知的行數或列數的數據結構,就可以使用行或列計數。
■ 可以確定列的數據類型。可以看出列是否是數字的,是否可能包括二進制數據等等。在前面的6.6.1節“處理返回結果集的查詢”中,我們編寫了從結果集的行中以制表符分隔的形式打印出結果的process_result_set() 程序。這對某些目的是很好的(例如要把數據輸入到電子制表軟件中),但對於可視化檢查或打印輸出,就不是一個漂亮的顯示格式。回憶前面的process_result_set() 版本,產生過這樣的輸出:

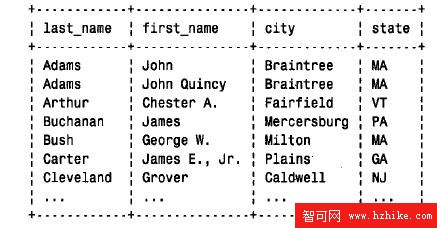
讓我們在每列加上標題和邊框來對process_result_set() 做些修改,以生成表格式的輸出。這種修正版看上去更美觀,輸出的結果是相同的,如下所示:
顯示算法的基本要點是這樣的:
1) 確定每列的顯示寬度。
2) 打印一列帶有邊框的列標題(由垂直豎線和前後的虛線分隔)。
3) 打印結果集每行的值、帶邊框的列(由垂直豎線分隔),並垂直排列,除此之外,打印
正確的數字,將NULL 值打印為單詞“NULL”。
4) 最後,打印檢索的行的計數。該練習為結果集元數據的使用提供了一個很好的示范。為了顯示所描述的輸出,除了行所包含的數據值之外,我們還需了解許多有關結果集的內容。您可能想,“這個描述聽起來與mysql顯示的輸出驚人地相似”。是的,歡迎把MySQL源代碼和修正版的process_result_set() 代碼比較一下,它們是不同的,可以發現對同一問題使用兩種方法是有指導作用的。
首先,我們需要確定每列的顯示寬度,下面列出如何做這件事情。可觀察到這些計算完全基於結果集元數據,無論行值是什麼,它們都沒有引用:

列寬度通過結果集中列的MYSQL_FIELD 結構的迭代來計算,調用mysql_ fetch _ seek( )定位第一個結構,後續的MySQL_fetch_fIEld() 調用返回指向連續列的結構的指針。顯示出來的列寬度是下面三個值中的最大值,其中每一個都取決於列信息結構中的元數據:
■ fIEld - > name的長度,也就是列標題的長度。
■ fIEld - > max _ length,列中最長的數據值的長度。
■ 如果列中可能包括NULL值,則為字符串“ NULL”的長度,field->flag 表明列是否包含NULL。請注意,已知要顯示的列的寬度後,我們將這個值賦給max _ length,max_length 是從客戶機庫獲取的結構中的一個成員。這種獲取是允許的嗎?或者MYSQL_FIELD 結構的內容應該為只讀?一般來說,是“只讀的”,但是MySQL分發包中的一些客戶機程序以同樣的方式改變了max_length 的值,因此,假設這也是正確的(如果更喜歡不改變max_length 值的方法,則分配一個unsigned int 值的數組,將計算的寬度存儲到這個數組中)。顯示寬度的計算包括一個說明,回想當使用mysql_use_result() 創建結果集時,max_length 沒有意義。因為我們需要max_length 來確定列值的顯示寬度,所以該算法的正確操作需要使用mysql_store_result() 產生的結果集( MYSQL _ FIELD結構的length 成員告知列值可以取得的最大值,如果使用mysql_store_result() 而不是MySQL_ use _ result( )的話,這可能是個有用的工作環境)。
一旦知道了列的寬度,就可以准備打印,處理標題很容易;對於給定的列,只需使用由fIEld 指向的列信息結構,用已計算過的寬度打印出name 成員。
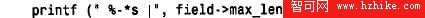
對於數據,我們對結果集中的行進行循環,在每次迭代時打印當前行的列值。從行中打印列值有些技巧,因為值可能是NULL,也可能代表一個數(無論哪種情況都如實打印)。列值的打印如下,這裡row[i] 包括數據值和指向列信息的fIEld 指針:

如果fIEld->type 指明的列類型是數字型,如INT、FLOAT或者DECIMAL,那麼宏IS _ NUM的值為真。顯示該結果集的最終的代碼如下所示。注意,因為我們需要多次打印虛線,所以這段代碼封裝在它自己的函數中,函數print_dashes() 是這樣的:



MySQL客戶機庫提供了訪問列信息結構的幾種方法,例如,前面樣例的代碼多次使用如下形式的循環訪問這些結構:

然而,mysql_field_seek() 與mysql_fetch_field() 的結合是獲得MYSQL_FIELD 結構的唯一途徑,可在附錄F 中查看mysql_fetch_fIEld() 函數和MySQL_fetch_fIEld_direct() 函數,尋找其他獲得列信息結構的方法。