MySQL分區按照分區的參考方式來分有RANGE分區、LIST分區、HASH分區、KEY分區。本文對這幾種分區方式進行了詳細的介紹,並且給出了簡單的示例,文章簡潔明了,對於想要初步了解MySQL分區技術的同學來說是很不錯的參考材料。
三、案例分析
這個案例是針對有個員工、部門、部門經理、頭銜和銷售記錄的模擬數據,其ER圖如下所示,數據量大概有4百萬左右。數據下載URL:https://launchpad.Net/test-db

圖11,案例分析
通過如上可知,對於同樣的數據按照分區和不分區的技術分別存儲,從而便於如下的查詢性能分析和對比。對於salarIEs表,它采用RANGE分區,定義如下:
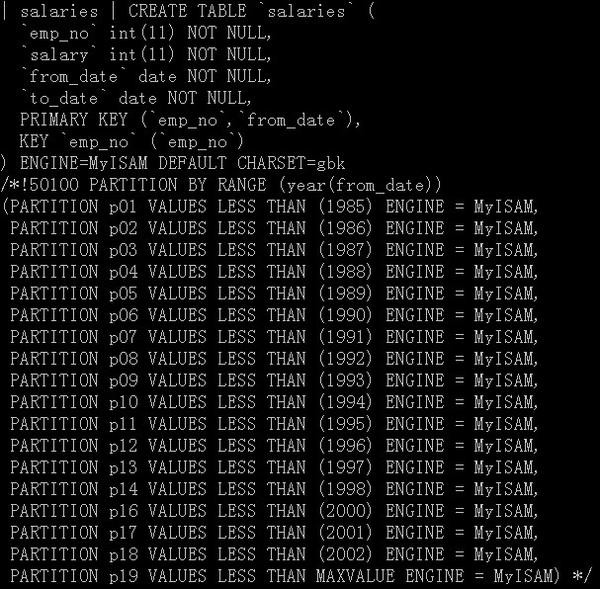
圖12,案例分析
1,單表查詢
從銷售記錄中找到1999年整年的銷售記錄有多少條,這個很簡單,查詢語句如下:
select count(*) from salarIEs s where s.from_date between"1999-01-01" and "1999-12-31" ;
那麼對於分區前後的查詢性能卻有很大的差別:

圖13,分區前後查詢性能對比
通過如上可知,利用分區之後它只需掃描p16分區,訪問的記錄明顯減少,所以性能自然有較大的提升:
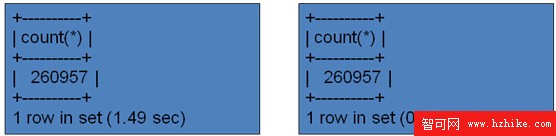
圖14,無采用分區技術和采用分區技術性能對比
2,單表查詢的badcase
若現在有如下查詢:
select count(*) from salarIEs s where year(s.from_date)=1999;
那麼它是否能夠利用到分區技術呢,答案是否定的。為什麼呢,因為分區中的key是s.from_date,而不是year(s.from_date),MySQL並不能很智能地判斷year是1999的,那麼它就是分為p16分區,這個可以通過如下的查詢計劃可以證實:
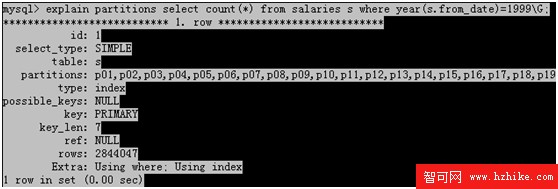
圖15,未優化前的單表查詢
也就是其實它訪問了所有的分區,所以並沒有很好地利用分區功能,將SQL改寫如下:
select count(*) from salarIEs s where year between '1999-01-01' and'1999-12-31' ;
則查詢計劃如下:
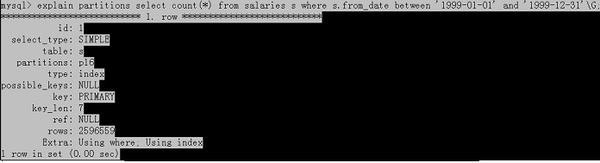
圖16,改進後的單表查詢
可知,書寫正確的SQL可以完全表現出兩種相差特別大的性能。
3,連接查詢
同樣地,對於連接查詢,在有沒有分區的條件下,將有性能3倍左右的差距。對於更大的數據量,可能會有更大的性能差距。SQL如下:
select count(*) from salarIEs s left join employees e ons.emp_no=e.emp_no where s.from_date between '1999-01-01' and '1999-12-31' ;

圖17,無采用分區和采用分區的性能對比
4,刪除查詢
為了刪除1998年的銷售數據,那麼在有分區情況下可以不利用delete查詢快速地完成垃圾數據的清理。
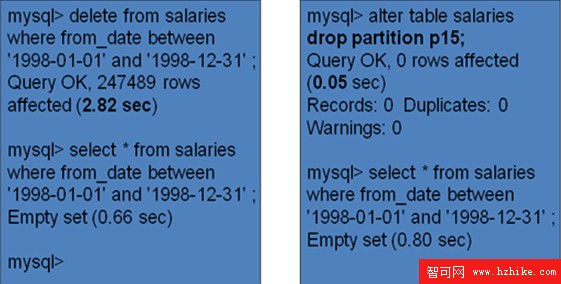
圖18,刪除查詢性能對比
可知,對於有分區的情況下,只需要將某個分區刪除掉即可,時間僅為0.05s,相對應原來的2.82s,這個提升是非常高的。當然,利用分區功能刪除之後的數據文件信息如下:

圖19,利用分區功能刪除後的文件信息
那麼接下來如果接著插入1998年的數據,數據是否丟失了呢?還是會寫不進去?答案也都是否定,它會將數據寫入p16分區中。有興趣的讀者可以自己收到試試。
四、總結和不足
分區的好處有很多:
1,與單個磁盤或文件系統分區相比,可以存儲更多的數據;
2,對於那些已經失去保存意義的數據,通常可以通過刪除與那些數據有關的分區,很容易地刪除那些數據;
3,一些查詢可以得到極大的優化,如where語句數據可以只保存在一個或多個分區內;
4,涉及到例如SUM()和COUNT()這樣聚合函數的查詢,可以很容易地進行並行處理;
5,通過跨多個磁盤來分散數據查詢,來獲得更大的查詢吞吐量。
在設計分區過程中,需要考慮的因素有很多,如:
1,分區的列;
2,分區使用的函數,特別是非Integer類型的列;
3,服務器性能;
4,內存大小。
根據分區技術,有一些技巧:
1,若索引的大小> RAM,考慮選用分區,不采用索引;
2,盡量不采用Primary Key做分區的key;
3,當CPU性能高的時候,考慮使用Archive存儲引擎;
4,對於大量的歷史數據,考慮使用Archive+PARTITION。
總之,
1,MySQL分區技術是一種邏輯的水平分表技術;
2,它只訪問需要訪問的分區,從而提高性能;
3,支持range, hash, key, list和復合分區方法;
4,支持MySQL服務器所支持的任何存儲引擎;
5,除了Key分區方法,Partition的key 必須是整數(或者能轉化成整數)。