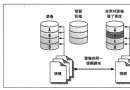
一個典型的HDFS系統包括一個NameNode和多個DataNode。NameNode維護名字空間;而DataNode存儲數據塊。
DataNode負責存儲數據,一個數據塊在多個DataNode中有備份;而一個DataNode對於一個塊最多只包含一個備份。所以我們可以簡單地認為DataNode上存了數據塊ID和數據塊內容,以及他們的映射關系。
一個HDFS集群可能包含上千DataNode節點,這些DataNode定時和NameNode通信,接受NameNode的指令。為了減輕NameNode的負擔,NameNode上並不永久保存那個DataNode上有那些數據塊的信息,而是通過DataNode啟動時的上報,來更新NameNode上的映射表。
DataNode和NameNode建立連接以後,就會不斷地和NameNode保持心跳。心跳的返回其還也包含了NameNode對DataNode的一些命令,如刪除數據庫或者是把數據塊復制到另一個DataNode。應該注意的是:NameNode不會發起到DataNode的請求,在這個通信過程中,它們是嚴格的客戶端/服務器架構。
DataNode當然也作為服務器接受來自客戶端的訪問,處理數據塊讀/寫請求。DataNode之間還會相互通信,執行數據塊復制任務,同時,在客戶端做寫操作的時候,DataNode需要相互配合,保證寫操作的一致性。
下面我們就來具體分析一下DataNode的實現。DataNode的實現包括兩部分,一部分是對本地數據塊的管理,另一部分,就是和其他的實體打交道。我們先來看本地數據塊管理部分。
安裝Hadoop的時候,我們會指定對應的數據塊存放目錄,當我們檢查數據塊存放目錄目錄時,我們回發現下面有個叫dfs的目錄,所有的數據就存放在dfs/data裡面。
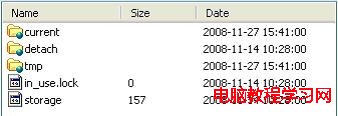
其中有兩個文件,storage裡存的東西是一些出錯信息,貌似是版本不對…雲雲。in_use.lock是一個空文件,它的作用是如果需要對整個系統做排斥操作,應用應該獲取它上面的一個鎖。
接下來是3個目錄,current存的是當前有效的數據塊,detach存的是快照(snapshot,目前沒有實現),tmp保存的是一些操作需要的臨時數據塊。
但我們進入current目錄以後,就會發現有一系列的數據塊文件和數據塊元數據文件。同時還有一些子目錄,它們的名字是subdir0到subdir63,子目錄下也有數據塊文件和數據塊元數據。這是因為HDFS限定了每個目錄存放數據塊文件的數量,多了以後會創建子目錄來保存。
數據塊文件顯然保存了HDFS中的數據,數據塊最大可以到64M。每個數據塊文件都會有對應的數據塊元數據文件。裡面存放的是數據塊的校驗信息。下面是數據塊文件名和它的元數據文件名的例子:
blk_3148782637964391313
blk_3148782637964391313_242812.meta
上面的例子中,3148782637964391313是數據塊的ID號,242812是數據塊的版本號,用於一致性檢查。
在current目錄下還有下面幾個文件:
VERSION,保存了一些文件系統的元信息。
dncp_block_verification.log.curr和dncp_block_verification.log.prev,它記錄了一些DataNode對文件系定時統做一致性檢查需要的信息。