一、存儲引擎
存儲引擎,MySQL中的數據用各種不同的技術存儲在文件(或者內存)中。這些技術中的每一種技術都使用不同的存儲機制、索引技巧、鎖定水平並且最終提供廣泛的不同的功能和能力。通過選擇不同的技術,你能夠獲得額外的速度或者功能,從而改善你的應用的整體功能。InnoDB存儲引擎是5.5版本後Mysql的默認數據庫,事務型數據庫的首選引擎,支持ACID事務,支持行級鎖定。另外還有常見的MyISAM存儲引擎,它擁有較高的插入,查詢速度,但不支持事務。所以,很明顯:插入不頻繁,查詢非常頻繁,沒有事務,用MyISAM;可靠性要求高,表更新頻繁,事務多,用InnoDB。
//#查看本機MySQL提供的什麼存儲引擎 //show ENGINES; // //#查看Mysql當前默認的存儲引擎 //show variables like '%storage_engine%'; // //#查看當前表用什麼存儲引擎(DDL最後) //show create table idc_work_order_main;
//#修改當前表的存儲引擎
//ALTER TABLE idc_work_order_main ENGINE = 'MyISAM'
MySQL官方對InnoDB是這樣解釋的,InnoDB給MySQL提供了具有提交、回滾和奔潰恢復能力的事務安全存儲引擎。InnoDB是為處理巨大數據量時的最大性能設計,它的CPU效率可能是任何其它基於磁盤的關系數據庫引擎所不能匹敵的。InnoDB存儲引擎被完全與MySQL服務器整合,InnoDB存儲引擎為在主內存中緩存數據和索引而維持它自己的緩沖池。
如果使用innodb存儲引擎,我們知道該引擎最主要的特點是transactional和row lock(行級鎖)。按理說不會出現表鎖才對,但是事實上還是會出現鎖表的的情況,也會比較嚴重,下面主要就是來探討一下這個問題。查看mysql文檔會發現,雖然innodb使用的的row lock(行級鎖),但是在處理具有auto increment字段的表的時候,會使用一種特殊的表鎖:AUTO-INC。簡單來說就是Innodb會在內存裡保存一個計數器用來記錄 auto_increment的值,當插入數據時,就會用一個表鎖來鎖住這個計數器,直到插入結束。一條一條插入問題不大,但是如果高並發插入,就會造成 sql阻塞。
解決方案:1.不使用auto increment字段,自己維護主鍵生成。該方法中選擇主鍵生成策略很重要, 要綜合考慮簡單和效率問題。假設使用uuid,雖然簡單但是會造成該表的主鍵效率很低(innodb的主鍵是特殊的index,其他的index會引用主鍵)。2.升級到最新的5.2版本。
//#MySQL5.1.22版本之前,這種方式的特點就是“表級鎖定”,並發性較差 //innodb_autoinc_lock_mode = 0 (“traditional” lock mode:全部使用表鎖) // //#推薦使用“consecutive”,並發性相對較高,特點是,即保證同一條insert語句中新插入的auto_increment id都是連續的 //innodb_autoinc_lock_mode = 1 (“consecutive” lock mode) // //#這種模式是來一個分配一個,而不會鎖表,只會鎖住分配id的*過程*,和innodb_autoinc_lock_mode = 1的區別在於 //#不會預分配多個,這種方式並發性最高。但是在replication中當binlog_format為statement-based時 //#(簡稱SBR statement-based replication)存在問題,因為是來一個分配一個,這樣當並發執行時, //#“Bulk inserts”在分配時會同時向其他的INSERT分配,會出現主從不一致(從庫執行結果和主庫執行結果不一樣),因為binlog只會記錄開始的 insert id。 //innodb_autoinc_lock_mode = 2 (“interleaved” lock mode:全部使用新方式,不安全,不適合replication)
關於數據的拷貝問題,常用的數據表引擎是MyISAM和InnoDB。MyISAM的數據表的後綴名是.frm(表結構)、.myd(數據)和.myi(索引),其索引和數據是分開的,可以直接拷貝;InnoDB的數據表的後綴名是.frm(表結構)和.ibd(數據),索引和數據都在同個文件ibdata*,不能直接拷貝,需要先導出再導入。拷貝完之後別忘了重啟數據庫服務。
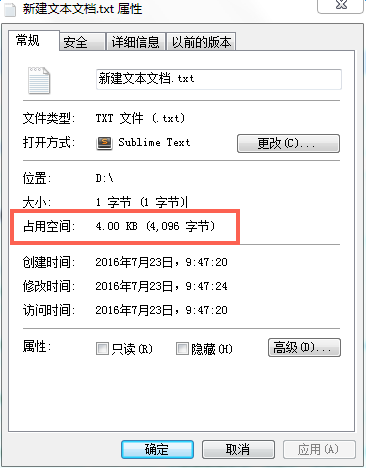
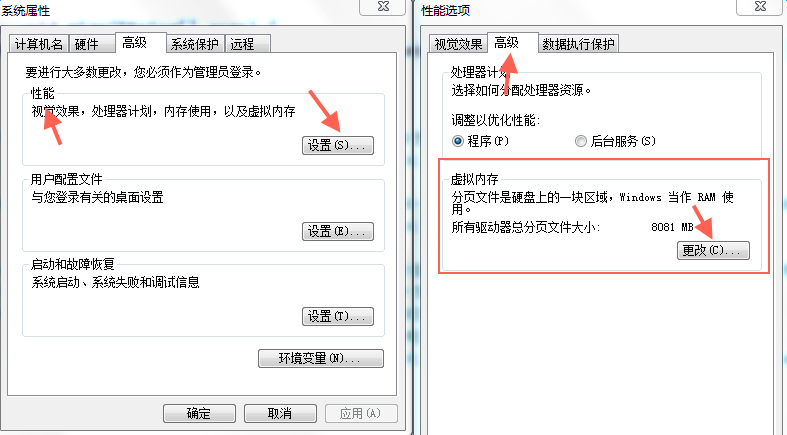
既然是存儲引擎,那麼我們看看這些數據庫的存儲是什麼樣的。block是相對於磁盤來講的,page是相對於內存來講的。第一幅圖是新建一個txt文檔,文件寫入1,然後再屬性中看占用空間的大小,也就是一個block的大小是4k個字節。通過右圖的方式可以用來查看內存中頁的大小。
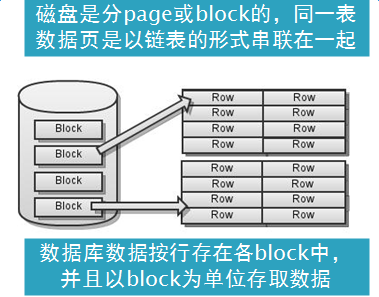
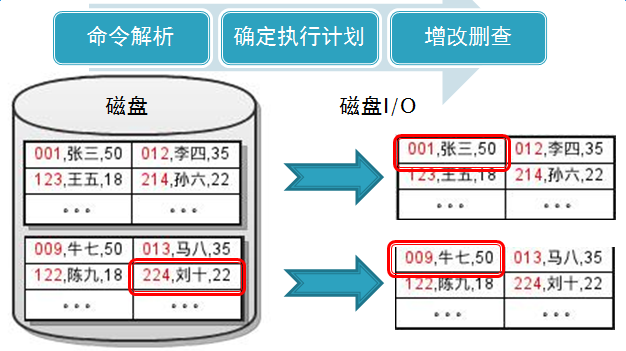
磁盤是分block塊的,同一表的數據頁是以鏈表的形式串聯在一起的,數據庫數據按行存在各個block中,並且以block為單位來存取數據。執行一條SQL的時候,從命令解析、確定執行計劃、增刪改查。這樣磁盤的I/O帶來了性能問題。如何減少磁盤的I/O次數呢?
// 1.保證讀取數據量在合理大小 // 2.保證存取數據能夠順序讀取 // 3.減少需要掃描數據占用空間
保證讀取數據量在合理大小;保證存取數據能夠順序讀取;減少需要掃描數據占用空間。解決措施,就是使用index索引。dense index是稠密索引,也叫全索引。sparse index是稀疏索引。dense indexes是通過對每一個record在磁盤上持久保存一些額外的數據,用於提高查詢的效率。Sparse index結合sequential file和dense index file的優點,通過保存部分key K作為它的record,能很好的支持二分查找快速查找record,並且能進一步減少所需的磁盤I/O。
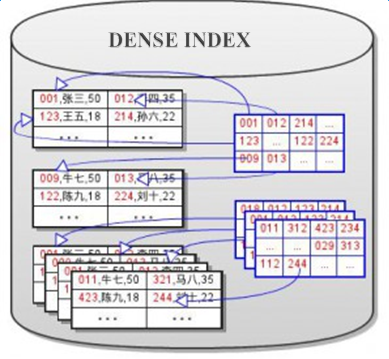
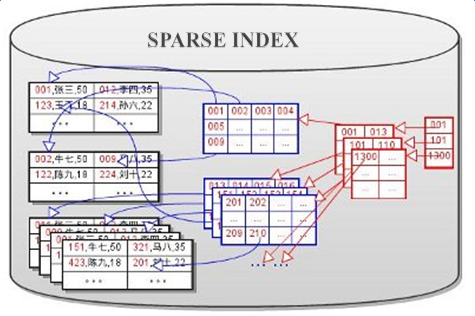
二、索引
索引是幫助MySQL高效獲取數據的數據結構。介紹MySQL的索引結構,索引原理,進而學習索引的優化。MySQL的索引結構包括:B-tree索引、Tree索引、哈希索引(Hash)、位圖索引(Bitmap)、跳表。
//#查看表的當前索引 執行結果顯示(Index_type: BTREE) //SHOW INDEX FROM idc_work_order_main
命令用於查看我們的數據庫中表的當前索引,執行結果顯示當前表結構使用功能的索引是BTREE。通常我們通過如下方式給表建索引:
//#查詢表當前使用的索引(表的主鍵自動建立唯一索引unique index) //SHOW INDEX FROM idc_work_order_main; // //#創建索引index //CREATE INDEX aaa ON idc_work_order_main(remark) //DROP INDEX aaa ON idc_work_order_main // //#創建唯一索引unique INDEX(唯一的索引意味著兩個行不能擁有相同的索引值,否則創建失敗) //CREATE UNIQUE INDEX aaa ON idc_work_order_main(id) //DROP INDEX aaa ON idc_work_order_main // //#創建組合索引 //CREATE INDEX aaa ON idc_work_order_main(id,remark) //DROP INDEX aaa ON idc_work_order_main
我們知道索引並不是隨便亂建的,在考慮是否建索引時,我們一般考慮如下的一些情況:
1.表記錄太少。如果一個表只有5條記錄,采用索引去訪問記錄的話,那首先需訪問索引表,再通過索引表訪問數據表,一般索引表與數據表不在同一個數據塊,這種情況下至少要往返讀取數據塊兩次。而不用索引的情況下ORACLE會將所有的數據一次讀出,處理速度顯然會比用索引快。
2.經常插入、刪除、修改的表。對一些經常處理的業務表應在查詢允許的情況下盡量減少索引。
3.數據重復,且分布平均的表字段。假如一個表有10萬行記錄,有一個字段A只有T和F兩種值,且每個值的分布概率大約為50%,那麼對這種表A字段建索引一般不會提高數據庫的查詢速度。
建立索引,一般是在對針對百萬級以上的數據才建立索引的,以期來提高性能。在創建索引時,首先要考慮表空間和磁盤空間是否足夠。我們知道索引也是一種數據,在建立索引的時候勢必也會占用大量表空間。因此在對一大表建立索引的時候首先應當考慮的是空間容量問題。其次,在對建立索引的時候要對表進行加鎖,因此應當注意操作在業務空閒的時候進行。其次考慮因素便是磁盤I/O。物理上應當盡量把索引與數據分散到不同的磁盤上。邏輯上,數據表空間與索引表空間分開。這是在建索引時應當遵守的基本准則。
//一般情況下不鼓勵使用like操作,如果非使用不可,如何使用也是一個問題。like “%aaa%” 不會使用索引而like “aaa%”可以使用索引。 //NOT IN和操作都不會使用索引將進行全表掃描。NOT IN可以NOT EXISTS代替,id3則可使用id>3 or id
索引結構,當前Mysql版本只有BTree和Hash兩種索引類型,默認為BTree。Oracle或其他類型數據庫中會有Bitmap索引(位圖索引)。下面將主要介紹B樹索引、哈希索引、位圖索引這三種索引結構。
B樹(Blance Tree)索引,數據結構原型是多路搜索樹,它是一種常見的數據結構,常用做數據庫的索引。使用BTree結構可以顯著減少定位記錄時所經歷的中間過程,從而加快存取速度。
// Blance Tree索引不適合的場景: // 1.單列索引的列不能包含null的記錄,復合索引的各個列不能包含同時為null的記錄,否則會全表掃描; // 2.不適合鍵值較少的列(重復數據較多的列,is_deleted "y" "n"); // 3.前導模糊查詢不能利用索引(like '%XX'或者like '%XX%')
圖片展示了B樹索引,在插入和刪除的時候,對Blance Tree的影響。 哈希索引(Hash),Hash散列索引是根據HASH算法來構建的索引。雖然 Hash 索引效率高,但是 Hash 索引本身由於其特殊性也帶來了很多限制和弊端,主要有以下這些:精確查找非常快(包括= <> 和in),其檢索效率非常高,索引的檢索可以一次定位,不像BTree 索引需要從根節點到枝節點,所以 Hash 索引的查詢效率要遠高於 B-Tree 索引。
// Hash 索引不適合的場景: // 1.不適合模糊查詢和范圍查詢(包括like,>,<,between……and等),由於 Hash索引比較的是進行 Hash運算之後的 Hash值,所以它只能用於等值的過濾,不能用於基於范圍的過濾 // 因為經過相應的 Hash 算法處理之後的 Hash值的大小關系,並不能保證和Hash運算前完全一樣; // 2.不適合排序,數據庫無法利用索引的數據來提升排序性能,同樣是因為Hash值的大小不確定; // 3.復合索引不能利用部分索引字段查詢,Hash索引在計算 Hash值的時候是組合索引鍵合並後再一起計算Hash值,而不是單獨計算Hash值, // 所以通過組合索引的前面一個或幾個索引鍵進行查詢的時候,Hash 索引也無法被利用。 // 4.同樣不適合鍵值較少的列(重復值較多的列)
位圖索引(Bitmap),就是用位圖表示的索引,對列的每個鍵值建立一個位圖。相對於BTree索引,占用的空間非常小,創建和使用非常快。位圖索引由於只存儲鍵值的起止Rowid和位圖,占用的空間非常少。
如test表中有state這樣一列,10行數據如下: 10 20 30 20 10 30 10 30 20 30 那麼會建立三個位圖,如下: BLOCK1 KEY=10 1 0 0 0 1 0 1 0 0 0 BLOCK2 KEY=20 1 0 0 0 1 0 1 0 0 0 BLOCK3 KEY=30 1 0 0 0 1 0 1 0 0 0 //位圖索引適合場景: //1.適合決策支持系統; //2.當select count(XX) 時,可以直接訪問索引中一個位圖就快速得出統計數據; //3.當根據鍵值做and,or或 in(x,y,..)查詢時,直接用索引的位圖進行或運算,快速得出結果行數據。 //位圖索引不適合場景: //1.不適合鍵值較多的列(重復值較少的列); //2.不適合update、insert、delete頻繁的列,代價很高。
跳表,利用了鏈表的結構圖。一個節點存儲了下下一個節點的信息,讓性能提升了一倍。
三、MySQL優化
1.limit start, count分頁的優化,limit語句的查詢時間與起始位置(start)的位置成正比。建議加索引,利用MySQL提供的索引緩存,不要直接去找數據地址,而是去索引地址先去查索引。
2.表的數據類型,能小就小,能用char(1)就不用varchar。避免使用null,count(列)不統計值為null的行數,且不利於索引。
3.char是固定大小,varchar可以動態存儲數據。優先用tinyint、smallint,再用int、bigint。
4.在存儲相同數值范圍的數據時,浮點數類型float通常都會比decimal類型使用更少的空間。float字段使用4字節存儲數據。double類型需要8個字節並擁有更高的精確度和更大的數值范圍,decimal類型的數據將會轉換成double類型。
附錄:
1、全文索引,全文索引技術是目前搜索引擎的關鍵技術。試想在1M大小的文件中搜索一個詞,可能需要幾秒,在100M的文件中可能需要幾十秒,如果在更大的文件中搜索那麼就需要更大的系統開銷,這樣的開銷是不現實的所以在這樣的矛盾下出現了全文索引技術。InnoDB不支持,Myisam支持性能比較好,一般在 CHAR、VARCHAR 或 TEXT 列上創建。
2.聚集索引,該索引中鍵值的邏輯順序決定了表中相應行的物理順序。 聚集索引確定表中數據的物理順序。Mysql中myisam表是沒有聚集索引的,innodb有(主鍵就是聚集索引),聚集索引在下面介紹innodb結構的時有詳細介紹。