第 15 章 可擴展性設計之Cache與Search的利用
前言:
前面章節部分所分析的可擴展架構方案,基本上都是圍繞在數據庫自身來進行的,這樣是否會使我們在尋求擴展性之路的思維受到“禁锢”,無法更為寬廣的發散開來。這一章,我們就將跳出完全依靠數據庫自身來改善擴展性的問題,將數據服務擴展性的改善向數據庫之外的天地延伸!
15.1 可擴展設計的數據庫之外延伸
數據庫主要就是為應用程序提供數據存取相應的服務,提高數據庫的擴展性,也是為了更好的提供數據存取服務能力,同時包括可靠性,高效性以及易用性。所以,我們最根本的目的就是讓數據層的存儲服務能力得到更好的擴展性,讓我們的投入盡可能的與產出成正比。
我們都明白一點,數據本身肯定都會需要有一個可以持久化地方,但是我們是否有必要讓我們的所有冗余數據都進行持久化呢?我想讀者朋友們肯定都會覺得沒有這個必要,只要保證有至少兩份冗余的數據進行持久化就足夠了。而另外一些為了提高擴展性而產生的冗余數據,我們完全可以通過一些特別的技術來替代需要持久化的數據庫,如內存 Cache,Search以及磁盤文件 Cache 和 Search 等等。
尋求數據庫軟件本身之外的 Cache 和 Search 來解決數據本身的擴展性,已經成為目前各個大型互聯網站點都在積極嘗試的一個非常重要的架構升級。因為這不僅僅能更大程度的在整個應用系統提升數據處理層本身的擴展性,而且還能更大限度的提升性能。
對於這種架構方式,目前已經比較成熟的解決方案主要有基於對象的分布式內存 Cache 解決方案 Memcached,高性能嵌入式數據庫編程庫 Berkeley DB ,功能強大的全文搜索引擎 Lucene 等等。
當然,在使用成熟的第三方產品的同時,偶爾自行實現一些特定應用場景下的 Cache 和 Search,也未嘗不是一件值得嘗試的事情,而且對於公司的技術積累來說也是很有意義的一件事情。當然,決定自行開發實現之前進行全面的評估是絕對必要的,不僅僅包括自身技術實力,對應用的商業需求也需要有一定的評估才行。
其實,不論是使用現成的第三方成熟解決方案還是自主研發,都是需要在開發資源方面有一定投入的。首先要想很好的和現有 MySQL 數據庫更好的結合,就有多種思路存在。可以在數據庫端實現和 Cache 或者 Search 的數據通訊(數據更新),也可以在應用程序端直接實現 Cache 與 Search 的數據更新。數據庫和 Cache 與 Search 可以處於整體架構中不同的層次,也可以並存於相同的層次。
下面我分別針對使用第三方成熟解決方案以及自主研發來進行一些針對性的分析和架構思路探討,希望對各位讀者朋友有一定的幫助。
15.2 合理利用第三方Cache解決方案
使用較為成熟的第三方解決方案最大的優勢就在於在節省自身研發成本的同時,還能夠在互聯網上面找到較多的文檔信息,幫助我們解決一些日常遇到的問題還是非常有幫助的。
目前比較流行的第三方 Cache 解決方案主要有基於對象的分布式內存 Cache 軟件Memcached 和嵌入式數據庫編程庫 Berkeley DB 這兩種。下面我將分別針對這兩種解決方案做一個分析和架構探討。
15.2.1 分布式內存 Cache 軟件 Memcached
相信對於很多讀者朋友來說,Memcached 並不會太陌生了吧,他現在的流行程度已經比MySQL 並不會差太多了。Memcached 之所以如此的流行,主要是因為以下幾個原因:
◆ 通信協議簡單,API接口清晰;
◆ 高效的 Cache 算法,基於 libevent 的事件處理機制,性能卓越;
◆ 面向對象的特性,對應用開發人員來說非常友好;
◆ 所有數據都存放於內存中,數據訪問高效;
◆ 軟件開源,基於 BSD 開源協議;
對於 Memcached 本身細節,這裡我就不涉及太多了,畢竟這不是本書的重點。下面我們重點看看如何通過 Memcached 來幫助我們你提升數據服務(這裡如果再使用數據庫本身可能會不太合適了)的擴展性。
要將 Memcached 較好的整合到系統架構中,首先要在應用系統中讓 Memcached 有一個准確的定位。是僅僅作為提升數據服務性能的一個 Cache 工具,還是讓他與 MySQL 數據庫較好的融合在一起成為一個更為更為高效理想的數據服務層。
1. 作為提升系統性能的 Cache 工具
如果我們僅僅只是系統通過 Memcached 來提升系統性能,作為一個 Cache 軟件,那麼更多的是需要通過應用程序來維護 Memcached 中的數據與數據庫中數據的同步更新。這時候的 Memcached 基本可以理解為比 MySQL 數據庫更為前端的一個 Cache 層。
如果我們將 Memcached 作為應用系統的一個數據 Cache 服務,那麼對於 MySQL 數據庫來說基本上不用做任何改造,僅僅通過應用程序自己來對這個 Cache 進行維護更新。這樣作最大的好處就在於可以做到完全不用動數據庫相關的架構,但是同時也會有一個弊端,那就是如果需要 Cache 的數據對象較多的時候,應用程序所需要增加的代碼量就會增加很多,同時系統復雜度以及維護成本也會直線上升。
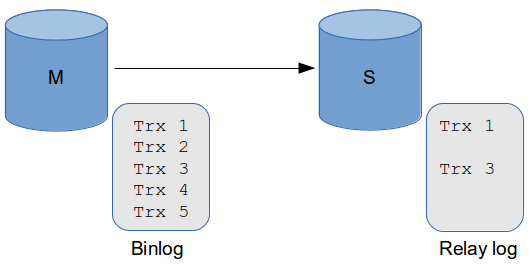
下面是將 Memcached 用為簡單的 Cache 服務層的時候的架構簡圖。 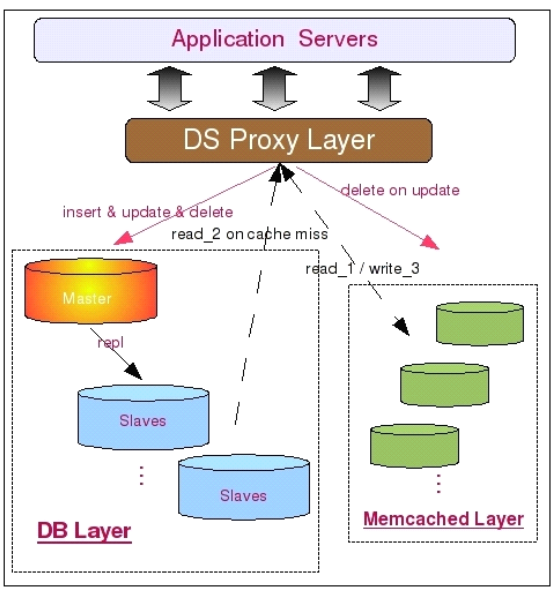
從圖中我們可以看到,所有數據都會寫入 MySQL Master 中,包括數據第一次寫入時候的INSERT,同時也包括對已有數據的 UPDATE 和 DELETE。不過,如果是對已經存在的數據,則需要在 UPDATE 或者 DELETE MySQL 中數據的同時,刪除 Memcached 中的數據,以此保證整體數據的一致性。而所有的讀請求首先會發往 Memcached 中,如果讀取到數據則直接返回,如果沒有讀取到數據,則再到 MySQL Slaves 中讀取數據,並將讀取得到的數據寫入到 Memcached 中進行 Cache。
這種使用方式一般來說比較適用於需要緩存對象類型少,而需要緩存的數據量又比較大的環境,是一個快速有效的完全針對性能問題的解決方案。由於這種架構方式和 MySQL 數據庫本身並沒有太大關系,所以這裡就不涉及太多的技術細節了。
2. 和 MySQL 整合為數據服務層
除了將 Memcached 用作快速提升效率的工具之外,我們其實還可以將之利用到提高數據服務層的擴展性方面,和我們的數據庫整合成一個整體,或者作為數據庫的一個緩沖。 我們首先看看如何將 Memcached 和MySQL 數據庫整合成一個整體來對外提供服務吧。
一般來說,我們有兩種方式將 Memcached 和 MySQL 數據庫整合成一個整體來對外提供數據服務。一種是直接利用 Memcached 的內存容量作為 MySQL 數據庫的二級緩存,提升 MySQL Server 的緩存大小,另一種是通過 MySQL 的UDF 來和 Memcached 進行數據通信,維護和更新 Memcached 中的數據,而應用端則直接通過 Memcached 來讀取數據。
對於第一種方式,主要用於業務要求非常特殊,實在難以進行數據切分,而且有很難通過對應用程序進行改造利用上數據庫之外的 Cache 的場景。 當然,在正常情況下是肯定無法做到這一點的,之少目前必須借助外界的力量,開源項目 Waffle Grid 就是我們需要借助的外部力量。I
Waffle Grid 是國外的幾位 DBA 在工作之余突發奇想出來的一個點子:既然 PC Server 的低廉成本如此的吸引我們,而其 Scale Up 的能力又很難有一個較大的突破,何不利用上現在非常流行的 Memcached 作為突破單台 PC Server 的內存上限呢?就在這個想法的推動下,幾位小伙子啟動了 Waffle Grid 這個開源項目,利用 MySQL 和 Memcached 雙雙開源的特性,結合 Memcached 通信協議簡單的特點,將 Memcached 成功實現成為MySQL 主機的外部“二級緩存”,目前僅支持用於 Innodb 的 Buffer Pool。
Waffle Grid 的實現原理其實並不復雜,他所做的事情就是當 Innodb 在本地的Buffer Pool(我們姑且稱其為 Local Buffer Pool吧)的時候,在從磁盤數據文件讀取數據之前,先通過 Memcached 的通信 API 接口嘗試從 Memcached 中讀取相應的緩存數據(我們稱之為 Remote Buffer吧),只有在 Remote Buffer 中也不存在需要的數據的時候, Innodb 才會訪問磁盤文件來讀取數據。而且,只有處於 Innodb Buffer pool 中的 LRU List 中的數據會被發送到 Remote Buffer Pool 中,而這些數據一旦被修改,就會 Innodb 就會將之移入 FLUSH List ,Waffle Grid 同時會將進入 FLUSH List 的數據從 Remote Buffer Pool 中清除掉。所以可以說,Remote Buffer Pool 中永遠不會存在 Dirty Pages, 這也保證了當 Remote Buffer Pool 出現故障的時候不會產生數據丟失的問題。下圖是使用Waffle Grid 項目時候的架構簡圖: 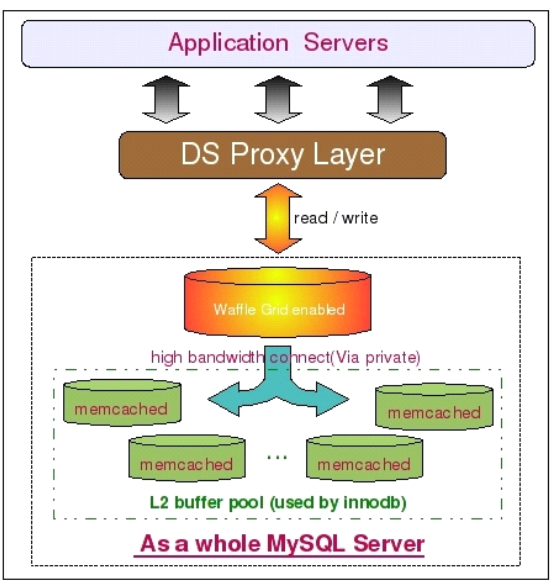
如架構圖上所示,我們首先在 MySQL 數據庫端應用 Waffle Grid Patch,通過他連與其他的 Memcached 服務器通信。為了保證網絡通信的性能,MySQL 與 Memcached 之間盡可能用高帶寬私有網絡。另外,這裡的架構圖中並沒有再將數據庫區分 Master 和 Slave 了,並不是說一定不能區分,只是一個示意圖。在實際應用過程中,大部分時候只需要在 Slave 上面應用 Waffle Grid 即可,Master 本身並不需要如此大的內存。
看了 Waffle Grid 的實現原理,可能有些讀者朋友會有些疑問了。這樣做不是所有需要產生物理讀的 Query 的性能就會受到直接影響了嗎?所有讀取 Remote Buffer 的操作都需要通過網絡來獲取,其性能是否足夠高呢?對此,我同樣使用作者對 Waffle 的實測數據來接觸大家的疑慮: 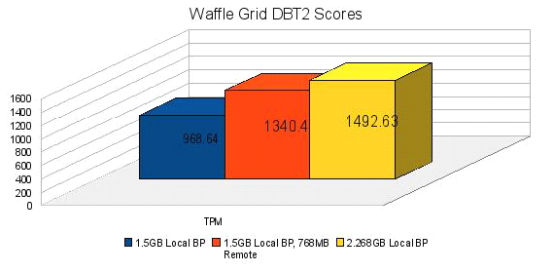
通過 DBT2 所得到的這組測試對比數據,在性能我想並不需要太多的擔憂了吧。至於Waffle Grid 是否適合您的應用場景,那就只能依靠各位讀者朋友自己進行評估了。
下面我們再來介紹一下 Memcached 和 MySQL 的另外一種整合方式,也就是通過 MySQL 所提供的 UDF 功能,自行編寫相應的程序來實現 MySQL 與 Memcached 的數據通信更新操作。
這種方式和 Waffle Grid 不一樣的是 Memcached 中的數據並不完全由 MySQL 來控制維護,而是由應用程序和 MySQL 一起來維護數據。每次應用程序從 Memcached 讀取數據的時候,如果發現找不到自己需要的數據,則再轉為從數據庫中讀取數據,然後將讀取到的數據寫入 Memcached 中。而 MySQL 則控制 Memcached 中數據的失效清理工作,每次數據庫中有數據被更新或者被刪除的時候,MySQL 則通過用戶自行編寫的 UDF 來調用 Memcached 的 API 來通知 Memcached 某些數據已經失效並刪除該數據。
基於上面的實現原理,我們可以設計出如下這樣的一個數據服務層架構: 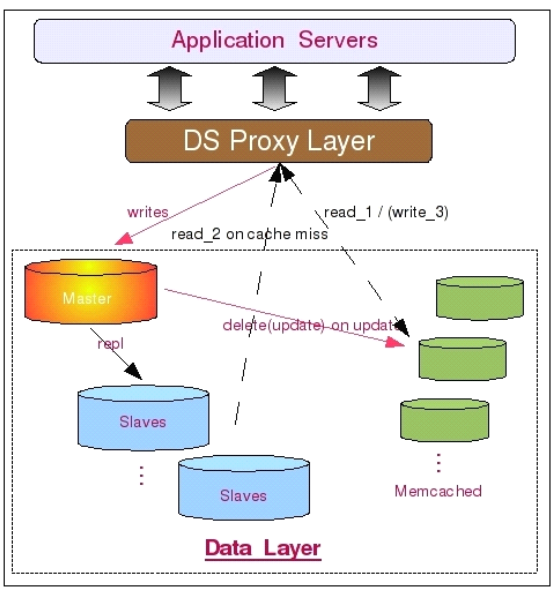
如圖中所示,此架構和上面將 Memcached 完全和 MySQL 讀離開作為常規的 Cache 服務器來比較,最大的區別在於 Memcached 的數據變為由 MySQL 數據庫來維護更新,而不是應用程序來更新。首先數據被應用程序寫入 MySQL 數據庫,這時候將會觸發 MySQL 上面用戶自行編寫的相關 UDF,然後通過該 UDF 調用 Memcached 的相關通信接口,將數據寫入 Memcached。而當 MySQL 中的數據被更新或者刪除的時候,MySQL 中的相關 UDF 同樣會更新或者刪除 Memcached 中的數據。當然,我們也可以讓 MySQL 做更少一些的事情, 僅僅只是遇到數據被更新或者刪除的時候,通過 UDF 來刪除 Memcached 中的數據,寫入工作則像前面的架構一樣由應用程序來作。
由於 Memcached 基於對象的數據存取,以及通過 Hash 進行數據檢索的特性,所以所有存儲在 Memcached 中的數據都需要我們設定一個用於標識該數據的 Key,所有數據的存取操作都通過該 Key 來進行。也就是說,如果您並不能像 MySQL 的 Query 語句一樣通過某一個(或者多個)關鍵字條件來讀取包含多條數據的結果集,僅適用於通過某個唯一鍵來獲取單條數據的數據讀取方式。
15.2.2 嵌入式數據庫編程庫 Berkeley DB
說實話,數據庫編程庫這個叫法實在有些別扭,但我也實在找不到其他合適的名詞來稱呼 Berkeley DB 了,那就姑且使用網上較為通用的叫法吧。
Memcached 所實現的是內存式 Cache,如果我們對性能的要求並沒有如此之高,在預算方面也不是太充裕的話,我們還可以選擇 Berkeley DB 這樣的數據庫型 Cache 軟件。可能很多讀者朋友又會產生疑惑了,我們使用的 MySQL 數據庫,為什麼還要再使用一個 Berkeley DB 這樣的“數據庫”呢?實際上 Berkeley DB 在之前也是 MySQL 的存儲引擎之一,只不過後期不知道是何原因(獲取與商業競爭有關吧),被 MySQL 從支持的存儲引擎中移除了。之所以在使用數據庫的同時還使用 Berkeley DB 這樣的數據庫型 Cache,是因為我們可以充分發揮出二者各自的優勢,在使用傳統通用型數據庫的同時,同時可以利用Berkeley DB 高效的鍵值對存儲方式作為高效數據檢索的性能補充,以得到更好的數據服務層擴展性和更高的整體性能。
Berkeley DB 自身架構可以分為五個功能模塊,五個模塊的在整個系統中相對比較獨立,而且可以設置使用或者禁用某一個(或者幾個)模塊,所以可能稱之為五個子系統會更為恰當一些。這五個子系統及基本介紹分別如下:
◆ 數據存取
數據存取子系統主要負責最主要也是最基本的數據存與取的工作。而且 Berkeley DB 同時支持了以下四種數據的存儲結果方式:Hash,B-Tree,Fixed Length以及Dynamic Length。實際上,這四種方式對應了四種數據文件存儲的實際格式。數據存儲子系統可以完全單獨使用,也是必須開啟的一個子系統。
◆ 事務管理
事務管理子系統主要是針對有事務要求的數據處理服務,提供完整的 ACID 事務屬性。在開啟事務管理子系統的時候,出了需要開啟最基本的數據存取子系統外,還至少需要開啟鎖管理子系統和日志系統來幫助實現事務的一致性和完整性。
◆ 鎖管理
鎖管理系統主要就是為了保證數據的一致性而提供的共享數據控制功能。支持行級別和頁級別的鎖定機制,同時為事務管理子系統提供服務。
◆ 共享內存
共享內存子系統我想大家看到名稱就應該基本知道是做什麼事情的了,就是用來管理維護共享 Cache 和 Buffer 的,為系統提升性能而提供數據緩存服務。
◆ 日志系統
日志系統主要服務於事務管理系統,為保證事務的一致性,Berkeley DB 也采用先寫日志再寫數據的策略,一般也都是與事務管理系統同時使用同時關閉。
基於 Berkeley DB 的特性,我們很難像使用 Memcached 那樣將他和 MySQL 數據庫結合的那麼緊密。數據的維護與更新操作主要還是需要通過應用程序來完成。一般來說,在使用 MySQL 的同時還要使用 Berkeley DB 的主要原因就是為了提升系統的性能及擴展性。所以,大多數時候都主要是使用 Hash 和 B-Tree 這兩種結構的數據存儲格式,尤其是 Hash 格式,是使用最為廣泛的,因為這種方式也是存取效率最高的。
在應用程序中,每次數據請求,都先通過預先設定的 Key 到 Berkeley DB 中取查找一次,如果存在數據,則返回取得的數據,如果位檢索到數據,則再次到數據庫中讀取。然後將讀取到的數據按照預先設定的 Key,整條存入 Berkeley DB 中,再返回給客戶端。而當發生數據修改的時候,應用程序在修改 MySQL 中的數據之後必須還要將 Berkeley DB 中的數據刪除。當然,如果您願意,也可以直接修改 Berkeley DB 中的數據,但是這樣就可能引入更多的數據一致性風險並提高系統復雜度了。
從原理來看,使用 Berkeley DB 的方式和將 Memcached 作為純 Cache 來使用差別不大嘛,為什麼我們不用 Memcached 來做呢?其實主要有兩個原因,一個是 Memcached 是使用純內存來存放數據的,而 Berkeley DB 則可以使用物理磁盤,兩者在成本方面還是有較大差別的。另外一個原因就是 Berkeley DB 所能支持的數據存儲方式除了 Memcached 所使用的 Hash 存儲格式之外,同時還可以使用其他存儲格式,如 B-Tree 等。 由於和 Memcached 的基本使用原理區別不大,所以這裡就不再畫圖示意了。
15.3 自行實現Cache服務
實際上,除了使用比較成熟的現成第三方軟件的解決方案之外,如果有一定的技術實力,我們還可以通過自行實現的 Cache 軟件來達到完全相同的效果。
當然,您也不要被上面所說的“技術實力”所嚇倒,其實也並沒有想象中的那麼難。只要您不要一開始就希望作出一個能夠解決所有問題,而且包含所有其他第三方 Cache 軟件的所有優點,還不能遺留任何缺點的軟件,不要一開始就希望作出一個多麼完美的產品花的軟件。從小做起,從精做起。千萬別希望一口氣吃成一個胖子,這樣的解決很可能就是被咽死。
自主研發實現 Cache 服務軟件的前提是系統中存在比較特殊的應用場景,通過自主研發可以最大限度的實現比較個性化的需求。當然,也可以針對自己的應用場景進行特定的優化方式來最大限度的提升擴展性和性能。畢竟,只有我們自己才是真正最了解我們的應用系統的人。
決策是否需要自行開發最需要考慮的一個問題就是我的應用系統場景是否真的如此特別,以至於現成的第三方軟件很難解決目前的主要問題?
如果目前的第三方軟件已經基本解決了我們系統當前遇到的80%以上的問題,可能就需要考慮是否有必要完全自主研發了。畢竟我們選擇的所有第三方軟件都是開源的,如果有某些小地方無法滿足要求,我們完全可以在第三方軟件的基礎上增加一些我們自己的東西,來滿足一些個性化需求。
當我們選擇自主研發 Cache 服務軟件之後,有以下幾點內容是需要注意的:
1. 功能需求
a) 是完全內存還是可以部分磁盤?
b) 需要實時同步更新還是可以允許 Cache 數據有延時?
c) 是否需要支持分布式?
這裡所說的功能,實際上就是需求范圍的設定。在開始研發之前,我們比需要有一個非常清晰的需求范圍,而不是天馬行空的邊開發邊調整,想到啥做啥。畢竟任何軟件系統,都是需要以第一線的需求為導向,而且一旦開始開發之後,需求的控制也不能馬虎。要不然, 很可能就會中途夭折,以失敗而告終。
2. 技術實現
a) 數據同步(或異步)更新機制;
b) 數據存儲方式(Hash Or B-Tree);
c) 通訊協議;
技術實現可能會成為研發過程中很大的一個難點,能否有穩定可靠的數據同步(或異步) 更新機制決定了該 Cache 軟件最終的成敗。當然,你可以說數據同步(或異步)更新完全交由需要訪問數據的應用程序來自行維護,但是你是否有足夠的能力申請在自行研發實現出一個 Cache 軟件的同時,還需要前端應用程序作出巨大的調整來適應這個 Cache 軟件是一個很大的未知數。老板很可能會說,既然你都自行研發實現了,為啥不能完成數據更新維護功能呢?而數據存儲方式直接決定數據的訪問方式,同時實現算法也直接決定了軟件的性能。最後,數據傳輸的通訊協議可能也會讓人傷透腦筋。如何設計一個足夠簡單,但是又做到盡可能不會限制後期的擴展升級的通訊協議,可能並不是一件太輕松的事情。畢竟,如果每次升級都需要動到數據傳輸通訊協議,那每次升級所帶來的應用改造成本也太大了。而太過復雜呢,很可能又會影響到前端應用使用的便利性,而且對性能可能也會有一定影響。
3. 可維護性
a) 方便的管理接口;
b) 高可用支持(自動或人工切換);
c) 基本監控接口;
千萬不要忽視了軟件系統的維護成本,一個軟件一旦開始使用之後,主要工作就是對其進行各種維護。如果可維護性太差,很可能帶來極大的維護工作量,甚至帶來一線應用人員和運維人員對該軟件的信任和使用熱情。
使用自行研發的 Cache 服務基於不同的功能特性,可能會有不同的架構組成,但基本上和上面使用 Memcached 所使用的架構區別不大了,所以這裡也就不再詳細討論了。
最後,我個人有一個建議就是,在使用比較通用 Cache 服務(也包括自行實現的 Cache 軟件服務)的時候,我們應該盡可能將該 Cache 軟件與我們的 MySQL 數據庫 進行一定的整合,讓彼此能夠互補。而且前端的應用程序盡量不要直接操作後端的數據服務集群,盡量通過一個中間代理層來接受處理所有的數據處理服務,對前端應用透明化。這樣才能夠盡可能做到後端數據服務(數據庫與 Cache)層在進行任何擴展的時候,影響到的僅僅只是中間代理層,而對前端完全透明,讓我們的數據層擁有真正的高擴展性。
15.4 利用Search實現高效的全文檢索
不論是使用 Memcached 還是使用 Berkeley DB ,大多數時候都只能通過特定的方式來進行數據的檢索,只能滿足少部分的檢索需求。而數據庫本身對於全模糊 LIKE 操作的性能大家應該也很清楚,是非常低下的,因為這種操作無法利用索引。雖然 MySQL 的 MyISAM 存 儲引擎支持了全文索引,而且官方版本還不支持多字節字符集的數據,所以對於需要存放中文或者需要使用 MyISAM 之外的存儲引擎的用戶來說,是完全無法使用的。
對於這種情況,我們只有一個辦法可以解決,那就是通過全文索引軟件,也就是我們常說的Search(搜索引擎)對數據進行全文索引,才能達到較為高效的數據檢索效率。
同樣,Search 軟件的使用也有使用較為成熟的第三方解決方案與自行研發兩種方式。
目前最為有名的第三方解決方案主要就是基於 Java 實現的 Lucene,隸屬於 Apache 軟件基金 Jakarta 項目組下面的一個子項目。當然,他並不是一個完整的搜索引擎工具,而是一個全文檢索引擎的框架,他同時提供了完整的用於檢索的查詢引擎和數據索引引擎。
這裡我就不深入討論 Lucene 本身的技術細節了,感興趣的讀者朋友可以通過訪問官方站點(http://lucene.apache.org) 來了解更多也更為權威的細節。我這裡主要是介紹一下 Luence 能夠給我們帶來什麼,我們可以怎樣來使用他。
由於 Lucene 高效的全文索引和分詞算法,以及高效的數據檢索實現,我們完全可以很好的利用這一優點來解決數據庫和傳統的 Cache 軟件完全無法解決的全文模糊搜索功能。
我們的需求和傳統的通用全網搜索引擎並不一樣,並不需要“Spider”到處去爬取互聯網上面的數據,只需要將我們數據庫中被持久化下來的數據通過應用程序調用 Lucene 的相關API 寫入,並利用 Lucene 創建好索引,然後就可以通過調用 Lucene 所提供的數據檢索API 得到需要訪問的數據,而且可以進行全模糊匹配。由於從數據庫到 Lucene 這一過程完全由我們自己來實現,所以我們非常容易控制數據的實時性。可以做到完全實時,同樣也可以做到固定(或動態)時間段刷新。
雖然 Lucene 的數據也是存放在磁盤上而不是內存中,但是由於高效的分詞算法和索引結構,其效率也是非常的好。看到很多網友在網上討論,當數據量稍微大一些如幾十個 G 之後 Lucene 的效率會下降的非常快,其實這是不科學的說法,就從我親眼所見的場景中, 就有好幾百G的數據在 Lucene 中,性能仍然很出色。這幾年性能優化的工作經歷及經驗中我有一個很深的體會,那就是一個軟件性能的好壞,實際上並不僅僅只由其本身所決定,很多時候一個非常高效的軟件不同的人使用會有截然不同效果。所以,很多時候當我們使用的第三方軟件性能出現問題的時候,不要急著下結論認為是這個軟件的問題,更多的是先從自身找找看我們是否真的正確使用了他。
除了使用第三方的 Search 軟件如 Lucene 之外,我們也可以自行研發更適用於我們自身應用場景的 Search 軟件。就像我目前所供職的公司一樣,自行研發了一套純內存存儲的更適合於自身應用場景的高性能分布式 Search 軟件,讓各個應用系統能夠作出很多高效的更為個性化的特色功能。通過多年的技術和經驗的積累,現在都已經發展成為和數據庫並列的另一個應用系統數據源了。
當然,自行研發 Search 軟件的技術門檻可能也比較高,有此技術實力的開發團隊並不是很多,所以在決定自行研發之前,一定要做好各方面的評估。不過,如果我們無法實現一個很通用的 Search 軟件,但是僅僅只是針對某些特定功能來說,可能實現也並沒有想象的那麼復雜,更何況如今的開源世界裡各種各樣的軟件數不勝數,利用現有的工具,加上自身個性化定制的二次開發,對於有些特定功能的實現可能就會比較輕松了。
加入了 Search 軟件來實現高效的全文檢索功能之後,我們的架構可以通過如下這張圖 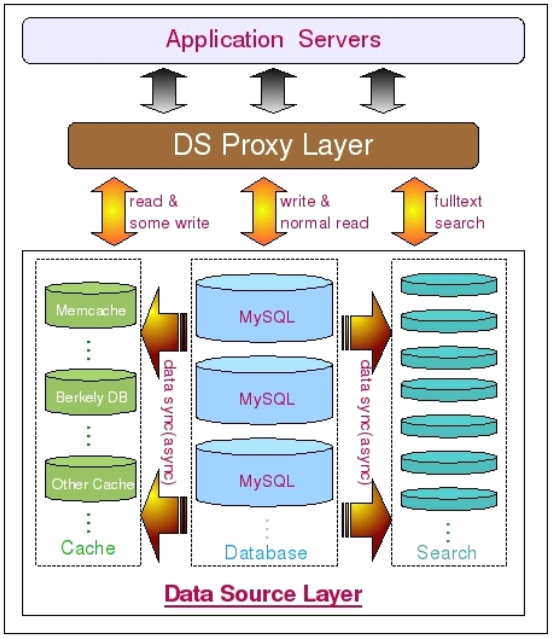
來展示:
15.5 利用分布式並行計算實現大數據量的高性能運算
說到大規模大數據量的高性能運算的時候,可能很多人都會想到最近風靡整個 IT 界的一個關鍵詞:雲計算,亦或是幾年前的“網格計算”。
曾經有朋友建議我將本節標題中的“分布式並行計算”更改為“雲計算”,考慮再三之後還是沒有更改。說實話,從我個人的理解,不論是“雲計算”還是“網格計算”,其實其實質都是一樣,都是“分布式並行計算”,只不過是各個商業公司為了吸引大家的眼球所玩的一些“概念游戲”而已,個人認為純屬商業行為。當然,可能有人會認為從“分布式並行計算”到“網格計算”再到“雲計算”,每一次“升級”都是在可以利用的計算資源上面有所擴展。可這種擴展都是在概念上面的擴展,而真正技術實現方面所依靠的並不是這些概念,而是各種軟硬件的發展。更何況,最初的“分布式並行計算”概念中本就沒有限定我們只能以哪種方式使用哪些資源。
目前比較流行的分布式並行計算框架主要就是以 Google 的 MapReduce 和 Yahoo 的 Hadoop 二者。其實更為准確的說應該是 Google的 MapReduce + GFS + BigTable 以及 Yahoo 的 Hadoop + HDFS + HBase 這兩大架構體系。二者都是由三個負責不同功能的組件組成,MapReduce 與 Hadoop 同為解決認任務分解與合並的功能,GFS 與 HDFS 都是分布式文件系統,解決數據存儲的基礎設施問題,最後 BigTable 與 HBase 則同為處理結構化數據存儲格式的類數據庫模塊。三大模塊共同協作,最終組成一個分布式並行計算的框架體系整體。
其實這分屬於兩家互聯網巨頭的分布式並行計算架構框架體系的實現原理基本上可以說是完全一樣的。通過前面端的任務分解合並引擎將計算(或者數據存取)任務分解成多個任務,同時發送給多台計算(或數據)節點來進行計算,而後面的每一個節點利用分布式文件系統來作為存儲計算數據的基礎平台,當然,不論是計算前還是計算後的數據,都是通過BigTable 或者是 Hbase 這樣的模塊進行組織。三者組成一個完整的整體,相互依賴。當然, 不得不說的是 Hadoop 本身也是由 Google 最初的一篇關於 MapReduce 的論文原理為思想所開發出來的。只不過 Google 在 Open 思想方面所做的貢獻很多時候僅限於論文形式,對於其自身技術架構方面的信息公開的實在是有些少。
其實除了這兩個重量級的分布式計算框架之外,完全利用現有開源數據庫實現的完整解決方案也有一些,如 Inforbright 與 MySQL 合作實現的 BI 解決方案,Greenplum 公司與Sun 利用 PostGresql 開源數據庫實現的 Greenplum 系統,而且兩個系統都是依賴MapReduce 理論所實現。
雖然這兩個系統目前並沒有前面兩個分布式計算框架那樣大的伸縮性,但是所針對的場景是實實在在的 DB 場景,數據訪問接口完全實現了 SQL 規范。對於使用習慣了通過 SQL 語句來玩數據庫的分析方法來說,無疑是非常有誘惑力的,更何況這兩個系統基本上都不怎麼需要開發,已經是一個完整的產品了。
考慮到篇幅以及非本書重點所在,這裡就不深入討論相關的技術細節了,大家如果對這些內容比較感興趣,可以通過各自官方網站了解更多更為全面的信息。
15.6 小結
數據庫只是存儲數據的一種工具,其特殊性只是能將數據持久化,且提供統一規范的訪問接口而已。除了數據庫,其實我們還可以很多其他的數據存儲處理方式,結合各種數據存儲處理方式,充分發揮各自的特性,揚長避短,形成一個綜合的數據中心,這樣才能讓系統的數據處理系統的擴展性得到最大的提升,性能得到最優化。
摘自:《MySQL性能調優與架構設計》簡朝陽
轉載請注明出處:
作者:JesseLZJ
出處:http://jesselzj.cnblogs.com