第12章 可擴展設計的基本原則
前言:
隨著信息量的飛速增加,硬件設備的發展已經慢慢的無法跟上應用系統對處理能力的要求了。此時,我們如何來解決系統對性能的要求?只有一個辦法,那就是通過改造系統的架構體系,提升系統的擴展能力,通過組合多個低處理能力的硬件設備來達到一個高處理能力的系統,也就是說,我們必須進行可擴展設計。可擴展設計是一個非常復雜的系統工程,所涉及的各個方面非常的廣泛,技術也較為復雜,可能還會帶來很多其他方面的問題。但不管我們如何設計,不管遇到哪些問題,有些原則我們還是必須確保的。本章就將可擴展設計過程中需要確保的原則做一個簡單的介紹。
12.1 什麼是可擴展性
在討論可擴展性之前,可能很多朋有會問:常聽人說起某某網站某某系統在可擴展性方面設計的如何如何好,架構如何如何出色,到底什麼是擴展?怎樣算是可擴展?什麼又是可擴展性呢?其實也就是大家常聽到的Scale,Scalable和Scalability這三個詞。
從數據庫的角度來說,Scale(擴展)就是讓我們的數據庫能夠提供更強的服務能力, 更強的處理能力。而 Scalable(可擴展)則是表明數據庫系統在通過相應升級(包括增加單機處理能力或者增加服務器數量)之後能夠達到提供更強處理能力。在理論能上來說,任何數據庫系統都是 Scalable 的,只不過是所需要的實現方式不一樣而已。最後, Scalability(擴展性)則是指一個數據庫系統通過相應的升級之後所帶來處理能力提升的難以程度。雖然理論上任何系統都可以通過相應的升級來達到處理能力的提升,但是不同的系統提升相同的處理能力所需要的升級成本(資金和人力)是不一樣的,這也就是我們所說的各個數據庫應用系統的Scalability 存在很大的差異。
在這裡,我所說的不同數據庫應用系統並不是指數據庫軟件本身的不同(雖然數據庫軟件不同也會存在 Scalability 的差異),而是指相同數據庫軟件的不同應用架構設計,這也正是本章以及後面幾張將會所重點分析的內容。
首先,我們需要清楚一個數據庫據系統的擴展性實際上是主要體現在兩個方面,一個是橫向擴展,另一個則是縱向擴展,也就是我們常說的 Scale Out 和 Scale Up。
Scale Out 就是指橫向的擴展,向外擴展,也就是通過增加處理節點的方式來提高整體處理能力,說的更實際一點就是通過增加機器來增加整體的處理能力。
Scale Up 則是指縱向的擴展,向上擴展,也就是通過增加當前處理節點的處理能力來提高整體的處理能力,說白了就是通過升級現有服務器的配置,如增加內存,增加CPU,增加存儲系統的硬件配置,或者是直接更換為處理能力更強的服務器和更為高端的存儲系統。
通過比較兩種 Scale 方式,我們很容易看出各自的優缺點。
◆ Scale Out 優點:
1. 成本低,很容易通過價格低廉的PC Server 搭建出一個處理能力非常強大的計算集群;
2. 不太容易遇到瓶頸,因為很容易通過添加主機來增加處理能力;
3. 單個節點故障對系統整體影響較小;也存在缺點,更多的計算節點,大部分時候都是服務器主機,這自然會帶來整個系統維護復雜性的提高,在某些方面肯定會增加維護成本,而且對應用系統的架構要求也會比 Scale Up 更高,需要集群管理軟件的配合。
◆ Scale Out 缺點:
1. 處理節點多,造成系統架構整體復雜度提高,應用程序復雜度提高;
2. 集群維護難以程度更高,維護成本更大;
◆ Scale Up 優點:
1. 處理節點少,維護相對簡單;
2. 所有數據都集中在一起,應用系統架構簡單,開發相對容易;
◆ Scale Up 缺點
1. 高端設備成本高,且競爭少,容易受到廠家限制;
2. 受到硬件設備發展速度限制,單台主機的處理能力總是有極限的,容易遇到最終無法解決的性能瓶頸;
3. 設備和數據集中,發生故障後的影響較大;
從短期來看,Scale Up會有更大的優勢,因為可以簡化運維成本,簡化系統架構和應用系統的開發,對技術方面的要求要會更簡單一些。
但是,從長遠影響來看,Scale Out 會有更大的優勢,而且也是系統達到一個規模之後的必然趨勢。因為不管怎樣,單台機器的處理能力總是會受到硬件技術的限制,而硬件技術的發展速度總是有限的,很多時候很難跟得上業務發展的速度。而且越是高處理能力的高端設備,其性價比總是會越差。所以通過多台廉價的PC Server 構建高處理能力的分布式集群,總是會成為各個公司節約成本,提高整體處理能力的一個目標。雖然在實現這個目標的時候可能會遇到各種各樣的技術問題,但總是值得去研究實踐的。
後面的內容,我們將重點針對 Scale Out 方面來進行分析設計。要能夠很好的 Scale Out,勢必需要進行分布式的系統設計。對於數據庫,要想較好的 Scale Out,我們只有兩個方向,一個是通過數據的不斷復制來實現很多個完全一樣的數據源來進行擴展,另一個就是通過將一個集中的數據源切分成很多個數據源來實現擴展。
下面我們先看看在設計一個具有很好的Scalability 的數據庫應用系統架構方面,需要遵循一些什麼樣的原則。
12.2 事務相關性最小化原則
搭建分布式數據庫集群的時候,很多人都會比較關心事務的問題。畢竟事務是數據庫中非常核心的一個功能。
在傳統的集中式數據庫架構中,事務的問題非常好解決,可以完全依賴數據庫本身非常成熟的事務機制來保證。但是一旦我們的數據庫作為分布式的架構之後,很多原來在單一數據庫中所完成的事務現在可能需要跨多個數據庫主機,這樣原來單機事務可能就需要引入分布式事務的概念。
但是大家肯定也有一些了解,分布式事務本身就是一個非常復雜的機制,不管是商業的大型數據庫系統還是各開源數據庫系統,雖然大多數數據庫廠家基本上都實現了這個功能,但或多或少都存在各種各樣的限制。而且也存在一些 Bug,可能造成某些事務並不能很好的保證,或者是不能順利的完成。
這時候,我們可能就需要尋求其他的替代方案來解決這個問題,畢竟事務是不可忽視的, 不關我們如何去實現,總是需要實現的。
就目前來說,主要存在的一些解決方案主要有以下三種:
第一、進行 Scale Out 設計的時候合理設計切分規則,盡可能保證事務所需數據在同一個 MySQL Server 上,避免分布式事務。
如果可以在設計數據切分規則的時候就做到所有事務都能夠在單個 MySQL Server 上面完成,我們的業務需求就可以比較容易的實現,應用程序就可以做到通過最少的調整來滿足架構的改動,使整體成本大大減少。畢竟,數據庫架構改造並不僅僅只是 DBA 的事情,還需要很多外圍的配合與支持。即使是在設計一個全新系統的時候,我們同樣要考慮到各個環境各項工作的整體投入,既要考慮數據庫本身的成本投入,同時也要考慮到相應的開發代價。如果各環節之間出現“利益”沖突,那我們就必須要作出一個基於後續擴展以及總體成本的權衡,尋找出一個最適合當前階段平衡點。
不過,即使我們的切分規則設計的再高明,也很難讓所有的事務所需的數據都在同一個MySQL Server 上。所以,雖然這種解決方案所需要付出的成本最小,但大多數時候也只能兼顧到一些大部分的核心事務,也不是一個很完美的解決方案。
第二、大事務切分成多個小事務,數據庫保證各個小事務的完整性,應用控制各個小事務之間的整體事務完整性。
和上一個方案相比,這個方案所帶來的應用改造就會更多,對應用的要求也會更為苛刻。
應用不僅需要分拆原來的很多大事務,同時還需要保證各個小事務的之間的完整性。也就是說,應用程序自己需要具有一定的事務能力,這無疑會增加應用程序的技術難度。
但是,這個方案也有不少自己的優勢。首先我們的數據的切分規則就會更為簡單,很難遇到限制。而且更簡單,就意味著維護成本更低。其次,沒有數據切分規則的太多限制,數據庫方面的可擴展性也會更高,不會受到太多的約束,當出現性能瓶頸的時候可以快速進行進一步拆分現有數據庫。最後,數據庫做到離實際業務邏輯更遠,對後續架構擴展也就更為有利。
第三、結合上述兩種解決方案,整合各自的優勢,避免各自的弊端。
前面兩種解決方案都存在各自的優缺點,而且基本上都是相互對立的,我們完全可以利用兩者各自的優勢,調整兩個方案的設計原則,在整個架構設計中做一個平衡。比如我們可以在保證部分核心事務所需數據在同一個 MySQL Server 上,而其他並不是特別重要的事務,則通過分拆成小事務和應用系統結合來保證。而且,對於有些並不是特別重要的事務, 我們也可以通過深入分析,看是否不可避免一定需要使用事務。
通過這樣相互平衡設計的原則,我們既可以避免應用程序需要處理太多的小事務來保證其整體的完整性,同時也能夠避免拆分規則太多復雜而帶來後期維護難度的增加及擴展性受阻的情況。
當然,並不是所有的應用場景都非要結合以上兩種方案來解決。比如對於那些對事務要求並不是特別嚴格,或者事務本身就非常簡單的應用,就完全可以通過稍加設計的拆分規則就可滿足相關要求,我們完全可以僅僅使用第一中方案,就可以避免還需要應用程序來維護某些小事務的整體完整性的支持。這在很大程度上面可以降低應用程序的復雜度。
而對於那些事務關系非常復雜,數據之間的關聯度非常高的應用,我們也就沒有必要為了保持事務數據能夠集中而努力設計,因為不管我們如何努力,都很難滿足要求,大都是遇到顧此失彼的情景。對於這種情況,我們還不如讓數據庫方面盡可能保持簡潔,而讓應用程序做出一些犧牲。
在當前很多大型的互聯網應用中,不論是上面哪一種解決方案的使用案例都有,如大家所熟知的 Ebay,在很大程度上就是第三種結合的方案。在結合過程中以第二種方案為主,第一種方案為輔。選擇這樣的架構,除了他們應用場景的需求之外,其較強的技術實力也為開發足夠強壯的應用系統提供了保證。又如某國內大型的 BBS 應用系統(不便公開其真實名稱),其事務關聯性並不是特別的復雜,各個功能模塊之間的數據關聯性並不是特別的高, 就是完全采用第一種解決方案,完全通過合理設計數據拆分的規則來避免事務的數據源跨多個 MySQL Server。
最後,我們還需要明白一個觀點,那就是事務並不是越多越好,而是越少越好越小越好。
不論我們使用何種解決方案,那就是在我們設計應用程序的時候,都需要盡可能做到讓數據的事務相關性更小,甚至是不需要事務相關性。當然,這只是相對的,也肯定只有部分數據能夠做到。但可能就是某部分數據做到了無事務相關性之後,系統整體復雜度就會降低很大一個層次,應用程序和數據庫系統兩方面都可能少付出很多的代價。
12.3 數據一致性原則
不論是 Scale Up 還是 Scale Out,不論我們如何設計自己的架構,保證數據的最終一致性都是絕對不能違背的原則,保證這個原則的重要性我想各位讀者肯定也都是非常明白清楚的。
而且,數據一致性的保證就像事務完整性一樣,在我們對系統進行 Scale Out 設計的時候,也可能會遇到一些問題。當然,如果是 Scale Up,可能就很少會遇到這類麻煩了。
當然,在很多人眼中,數據的一致性在某種程度上面也是屬於事務完整性的范疇。不過這裡為了突出其重要性和相關特性,我還是將他單獨提出來分析。
那我們又如何在 Scale Out 的同時又較好的保證數據一致性呢?很多時候這個問題和保證事務完整性一樣讓我們頭疼,也同樣受到了很多架構師的關注。經過很多人的實踐,大家最後總結出了 BASE 模型。即:基本可用,柔性狀態,基本一致和最終一致。這幾個詞看著挺復雜挺深奧,其實大家可以簡單的理解為非實時的一致性原則。
也就是說,應用系統通過相關的技術實現,讓整個系統在滿足用戶使用的基礎上,允許數據短時間內處於非實時狀態,而通過後續技術來保證數據在最終保證處於一致狀態。這個理論模型說起來確實聽簡單,但實際實現過程中我們也會遇到不少難題。
首先,第一個問題就是我們需要讓所有數據都是非實時一致嗎?我想大多數讀者朋友肯定是投反對票的。那如果不是所有的數據都是非實時一致,那我們又該如何來確定哪些數據需要實時一致哪些數據又只需要非實時的最終一致呢?其實這基本可以說是一個各模塊業務優先級的劃分,對於優先級高的自然是規屬於保證數據實時一致性的陣營,而優先級略低的應用,則可以考慮劃分到允許短時間端內不一致而最終一致的陣營。這是一個非常棘手的問題。我們不能隨便拍腦袋就決定,而是需要通過非常詳細的分析和仔細的評估才能作出決定。因為不是所有數據都可以出現在系統能不短時間段內不一致狀態,也不是所有數據都可以通過後期處理的使數據最終達到一致的狀態,所以之少這兩類數據就是需要實時一致的。
而如何區分出這兩類數據,就必須經過詳細的分析業務場景商業需求後進行充分的評估才能得出結論。
其次,如何讓系統中的不一致數據達到最終一致?一般來說,我們必須將這類數據所設計到的業務模塊和需要實時一致數據的業務模塊明確的劃分開來。然後通過相關的異步機制技術,利用相應的後台進程,通過系統中的數據,日志等信息將當前並不一致的數據進行進一步處理,使最終數據處於完全一致狀態。對於不同的模塊,使用不同的後台進程,既可以避免數據出現紊亂,也可以並發執行,提高處理效率。如對用戶的消息通知之類的信息,就沒有必要做到嚴格的實時一致性,只需要現記錄下需要處理的消息,然後讓後台的處理進程依次處理,避免造成前台業務的擁塞。
最後,避免實時一致與最終一致兩類數據的前台在線交互。由於兩類數據狀態的不一致性,很可能會導致兩類數據在交互過程中出現紊亂,應該盡量讓所有非實時一致的數據和實時一致數據在應用程序中得到有效的隔離。甚至在有些特別的場景下,記錄在不同的 MySQL Server 中來進行物理隔離都是有必要的。
12.4 高可用及數據安全原則
除了上面兩個原則之外,我還想提一下系統高可用及數據安這兩方面。經過我們的Scale Out 設計之後,系統整體可擴展性確實是會得到很大的提高,整體性能自然也很容易得到較大的改善。但是,系統整體的可用性維護方面卻是變得比以前更為困難。因為系統整體架構復雜了,不論是應用程序還是數據庫環境方面都會比原來更為龐大,更為復雜。這樣所帶來的最直接影響就是維護難度更大,系統監控更難。
如果這樣的設計改造所帶來的結果是我們系統經常性的 Crash,經常性的出現 Down 機事故,我想大家肯定是無法接受的,所以我們必須通過各種技術手段來保證系統的可用性不會降低,甚至在整體上有所提高。
所以,這裡很自然就引出了我們在進行 Scale Out 設計過程中另一個原則,也就是高可用性的原則。不論如何調整設計系統的架構,系統的整體可用性不能被降低。
其實在討論系統可用性的同時,還會很自然的引出另外一個與之密切相關的原則,那就是數據安全原則。要想達到高可用,數據庫中的數據就必須是足夠安全的。這裡所指的安全並不針對惡意攻擊或者竊取方面來說,而是針對異常丟失。也就是說,我們必須保證在出現軟/硬件故障的時候,能夠保證我們的數據不會出現丟失。數據一旦丟失,根本就無可用性可言了。而且,數據本身就是數據庫應用系統最核心的資源,絕對不能丟失這一原則也是毋庸置疑的。
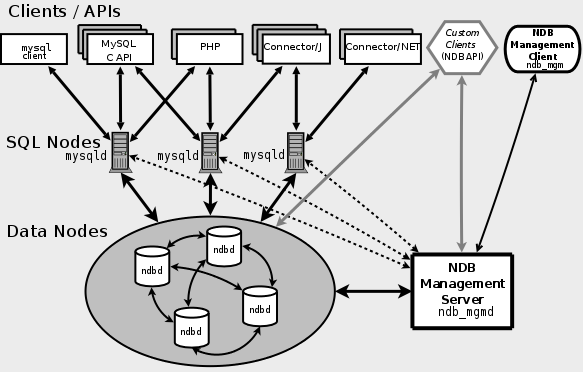
要確保高可用及數據安全原則,最好的辦法就是通過冗余機制來保證。所有軟硬件設備都去除單點隱患,所有數據都存在多份拷貝。這樣才能夠較好的確保這一原則。在技術方面,我們可以通過 MySQL Replication,MySQL Cluster 等技術來實現。
12.5 小結
不論我們如何設計架構,不管我們的可擴展性如何變化,本章中所提到的一些原則都是非常重要的。不論是解決某些問題的原則,還是保證性的原則,不論是保證可用性的原則,還是保證數據安全的原則,我們都應該在設計中時時刻刻都關注,謹記。MySQL 數據庫之所以在互聯網行業如此火爆,除了其開源的特性,使用簡單之外,還有一個非常重要的因素就是在擴展性方面有較大的優勢。其不同存儲引擎各自所擁有的特性可以應對各種不同的應用場景。其 Replication 以及 Cluster 等特性更是提升擴展性非常有效的手段。
摘自:《MySQL性能調優與架構設計》簡朝陽
轉載請注明出處:
作者:JesseLZJ
出處:http://jesselzj.cnblogs.com