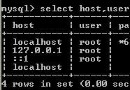
Amoeba是什麼?
Amoeba(變形蟲)項目,致力於MySQL的分布式數據庫前端代理層,它主要在應用層訪問MySQL的時候充當SQL路由功能,專注於分布式數據庫代理層(Database Proxy)開發。座落與 Client、DB Server(s)之間,對客戶端透明。具有負載均衡、高可用性、SQL過濾、讀寫分離、可路由相關的到目標數據庫、可並發請求多台數據庫合並結果。
主要解決:
• 降低 數據切分帶來的復雜多數據庫結構
• 提供切分規則並降低 數據切分規則 給應用帶來的影響
• 降低db 與客戶端的連接數
• 多數據源的高可用、讀寫分離、負載均衡、數據切片功能。
為何要使用Amoeba?
隨著傳統的數據庫技術日趨成熟、計算機網絡技術的飛速發展和應用范圍的擴充,數據庫應用已經普遍建立於計算機網絡之上。這時集中式數據庫系統表現出它的不足:集中式處理,勢必造成性能瓶頸;應用程序集中在一台計算機上運行,一旦該計算機發生故障,則整個系統受到影響,可靠性不高;集中式處理引起系統的規模和配置都不夠靈活,系統的可擴充性差。在這種形勢下,集中式數據庫將向分布式數據庫發展。而Amoeba的透明、簡易配置及多個優點使其成為分布式數據庫代理產品中的優秀選擇。
分布式數據庫代理的相關概念
Amoeba在分布式數據庫領域將致力解決數據切分,應付客戶端“集中式”處理分布式數據。這裡集中式是一個相對概念,客戶端不需要知道某種數據的物理存儲地。避免這種邏輯出現在業務端,大大簡化了客戶端操作分布式數據的復雜程度。
分布式數據庫系統的優點:
1.降低費用。分布式數據庫在地理上可以式分布的。其系統的結構符合這種分布的要求。允許用戶在自己的本地錄用、查詢、維護等操作,實行局部控制,降低通信代價,避免集中式需要更高要求的硬件設備。而且分布式數據庫在單台機器上面數據量較少,其響應速度明顯提升。
2.提高系統整體可用性。避免了因為單台數據庫的故障而造成全部癱瘓的後果。
3.易於擴展處理能力和系統規模。分布式數據庫系統的結構可以很容易地擴展系統,在分布式數據庫中增加一個新的節點,不影響現有系統的正常運行。這種方式比擴大集中式系統要靈活經濟。在集中式系統中擴大系統和系統升級,由於有硬件不兼容和軟件改變困難等缺點,升級的代價常常是昂貴和不可行的。
Amoeba for MySQL
Amoeba for MySQL致力於MySQL的分布式數據庫前端代理層,它主要在應用層訪問MySQL的時候充當query 路由功能,專注 分布式數據庫 proxy 開發。座落與Client、DB Server(s)之間。對客戶端透明。具有負載均衡、高可用性、Query過濾、讀寫分離、可路由相關的query到目標數據庫、可並發請求多台數據庫合並結果。在Amoeba上面你能夠完成多數據源的高可用、負載均衡、數據切片的功能。
那麼Amoeba for mysql 對客戶端程序來說是什麼呢?我們就當它是mysql吧,它是一個虛擬的mysql,對外提供mysql協議。客戶端連接amoeba就象連接mysql一樣。在amoeba內部需要配置相關的認證屬性。
Amoeba不能做什麼?
1.目前還不支持事務
2.暫時不支持存儲過程(近期會支持)
3.不適合從amoeba導數據的場景或者對大數據量查詢的query並不合適(比如一次請求返回10w以上甚至更多數據的場合)
4.暫時不支持分庫分表,amoeba目前只做到分數據庫實例,每個被切分的節點需要保持庫表結構一致
安裝和運行Amoeba
運行環境:CentOS6.3
安裝jdk1.5以上版本
卸載centos服務器自帶版本jdk
查看服務器自帶jdk版本號
[root@amoeba1 ~]# java –version
查看java信息
[root@amoeba1 ~]# rpm -qa | grep java
卸載java文件
[root@amoeba1 ~]# rpm -e --nodeps java-1.6.0-openjdk-1.6.0.0-1.45.1.11.1.el6.x86_64
再次查看java版本,已經刪除
[root@amoeba1 ~]# java –version
安裝jdk
創建/usr/java文件夾,將jdk安裝文件拷貝到此目錄
[root@amoeba1 ~]# mkdir /usr/java
[root@amoeba1 ~]# cd /usr/java
賦予權限
[root@amoeba1 java]# chmod 777 jdk-6u30-linux-x64-rpm.bin
安裝jdk
[root@amoeba1 java]# ./jdk-6u30-linux-x64-rpm.bin
配置環境變量
[root@amoeba1 java]# vi /etc/profile
在配置文件最後面添加下面3條語句
export JAVA_HOME=/usr/java/jdk1.6.0_30
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
配置完成後,重啟服務器
[root@amoeba1 java]# reboot
重啟完成後查看新安裝jdk版本
[root@amoeba1 ~]# java –version
安裝amoeba
下載amoeba,http://sourceforge.net/projects/amoeba/files/,我用的版本是amoeba-mysql-binary-2.2.0.tar
創建amoeba文件夾,將文件解壓到此文件夾
[root@amoeba1 ~]# mkdir /usr/local/amoeba
[root@amoeba1 ~]# cd /usr/local/amoeba/
[root@amoeba1 amoeba]# tar -zxvf amoeba-mysql-binary-2.2.0.tar.gz
驗證是否安裝成功
[root@amoeba1 amoeba]# /usr/local/amoeba/bin/amoeba start
參數配置
[root@amoeba1 amoeba]# cd /usr/local/amoeba/conf/
[root@amoeba1 conf]# ls
Amoeba有哪些主要的配置文件?
1.想象Amoeba作為數據庫代理層,它一定會和很多數據庫保持通信,因此它必須知道由它代理的數據庫如何連接,比如最基礎的:主機IP、端口、Amoeba使用的用戶名和密碼等等。這些信息存儲在$AMOEBA_HOME/conf/dbServers.xml中。
2.Amoeba為了完成數據切分提供了完善的切分規則配置,為了了解如何分片數據、如何將數據庫返回的數據整合,它必須知道切分規則。與切分規則相關的信息存儲在$AMOEBA_HOME/conf/rule.xml中。
3.當我們書寫SQL來操作數據庫的時候,常常會用到很多不同的數據庫函數,比如:UNIX_TIMESTAMP()、SYSDATE()等等。這些函數如何被Amoeba解析呢?$AMOEBA_HOME/conf/functionMap.xml描述了函數名和函數處理的關系。
4.對$AMOEBA_HOME/conf/rule.xml進行配置時,會用到一些我們自己定義的函數,比如我們需要對用戶ID求HASH值來切分數據,這些函數在$AMOEBA_HOME/conf/ruleFunctionMap.xml中定義。
5.Amoeba可以制定一些可訪問以及拒絕訪問的主機IP地址,這部分配置在$AMOEBA_HOME/conf/access_list.conf中
6.Amoeba允許用戶配置輸出日志級別以及方式,配置方法使用log4j的文件格式,文件是$AMOEBA_HOME/conf/log4j.xml。
配置一個DB節點
以下是配置一個DB節點,使用Amoeba做操作轉發的步驟:
1.首先,在$AMOEBA_HOME/conf/dbServers.xml中配置一台數據庫,如下:
Example 3.1. 簡單的DB節點配置
<?xml version="1.0" encoding="gbk"?>
<!DOCTYPE amoeba:dbServers SYSTEM "dbserver.dtd">
<amoeba:dbServers xmlns:amoeba="http://amoeba.meidusa.com/">
<!--
Each dbServer needs to be configured into a Pool,
If you need to configure multiple dbServer with load balancing that can be simplified by the following configuration:
add attribute with name virtual = "true" in dbServer, but the configuration does not allow the element with name factoryConfig
such as 'multiPool' dbServer
-->
#這份dbServers配置文件中,我們定義了三個dbServer元素,這是第一個dbServer元素的定義。這個名為abstractServer的dbServer,其abstractive屬性為true,這意味著這是一個抽象的dbServer定義,可以由其他dbServer定義拓展。
<dbServer name="abstractServer" abstractive="true">
<factoryConfig class="com.meidusa.amoeba.mysql.net.MysqlServerConnectionFactory">
<property name="manager">${defaultManager}</property>
#manager定義了該dbServer選擇的連接管理器(ConnectionManager),這裡引用了amoeba.xml的配置。
<property name="sendBufferSize">64</property>
<property name="receiveBufferSize">128</property>
#在第一個dbServer元素分別定義MySQL的端口號、數據庫名、用戶名以及密碼。
<!-- mysql port -->
<property name="port">3306</property>
<!-- mysql schema -->
<property name="schema">test</property>
<!-- mysql user -->
<property name="user">root</property>
<!-- mysql password -->
<property name="password">password</property>
</factoryConfig>
#dbServer下有poolConfig的元素,這個元素的屬性主要配置了與數據庫的連接池。
<poolConfig class="com.meidusa.amoeba.net.poolable.PoolableObjectPool">
<property name="maxActive">500</property>
<property name="maxIdle">500</property>
<property name="minIdle">10</property>
<property name="minEvictableIdleTimeMillis">600000</property>
<property name="timeBetweenEvictionRunsMillis">600000</property>
<property name="testOnBorrow">true</property>
<property name="testWhileIdle">true</property>
</poolConfig>
</dbServer>
#命名為server1的dbServer元素,正如你設想的那樣,這個server1是abstractServer的拓展,parent屬性配置了拓展的抽象dbServer,它拓展了abstractServer的ipAddress屬性來指名數據庫的IP地址,而在端口、用戶名密碼、連接池配置等屬性沿用了abstractServer的配置。
<dbServer name="server1" parent="abstractServer">
<factoryConfig>
<!-- mysql ip -->
#server1拓展了abstractServer的ipAddress屬性。
<property name="ipAddress">127.0.0.1</property>
</factoryConfig>
</dbServer>
#這一段其實並不需要配置,並不會影響到基本使用。以下大致介紹下此配置的含義:multiPool是一個虛擬的數據庫節點,可以將這個節點配置成好幾台數據庫組成的數據庫池。比如上面這個配置中僅配置了一台server1,負載均衡策略為ROUNDROBIN(輪詢)。與虛擬數據庫節點相關的詳細教程會在後面的章節中介紹。
<dbServer name="multiPool" virtual="true">
<poolConfig class="com.meidusa.amoeba.server.MultipleServerPool">
<!-- Load balancing strategy: 1=ROUNDROBIN , 2=WEIGHTBASED , 3=HA-->
<property name="loadbalance">1</property>
<!-- Separated by commas,such as: server1,server2,server1 -->
<property name="poolNames">server1</property>
</poolConfig>
</dbServer>
</amoeba:dbServers>
由此,你大概可以理解定義abstractServer的原因:當我們有一個數據庫集群需要管理,這個數據庫集群中節點的大部分信息可能是相同的,比如:端口號、用戶名、密碼等等。因此通過歸納這些共性定義出的abstractServer極大地簡化了dbServers配置文件:
Example 3.2. 一個利用定義抽象節點配置集群的例子
<?xml version="1.0" encoding="gbk"?>
<!DOCTYPE amoeba:dbServers SYSTEM "dbserver.dtd">
<amoeba:dbServers xmlns:amoeba="http://amoeba.meidusa.com/">
<dbServer name="abstractServerForBilling" abstractive="true">
<factoryConfig class="com.meidusa.amoeba.mysql.net.MysqlServerConnectionFactory">
<property name="manager">${defaultManager}</property>
<property name="sendBufferSize">64</property>
<property name="receiveBufferSize">128</property>
<property name="port">3306</property>
<property name="schema">test</property>
<property name="user">root</property>
<property name="password">password</property>
</factoryConfig>
<poolConfig class="com.meidusa.amoeba.net.poolable.PoolableObjectPool">
<property name="maxActive">500</property>
<property name="maxIdle">500</property>
<property name="minIdle">10</property>
<property name="minEvictableIdleTimeMillis">600000</property>
<property name="timeBetweenEvictionRunsMillis">600000</property>
<property name="testOnBorrow">true</property>
<property name="testWhileIdle">true</property>
</poolConfig>
</dbServer>
<dbServer name="billing1" parent="abstractServer">
<factoryConfig>
<!-- mysql ip -->
<property name="ipAddress">192.168.0.1</property>
</factoryConfig>
</dbServer>
<dbServer name="billing2" parent="abstractServer">
<factoryConfig>
<!-- mysql ip -->
<property name="ipAddress">192.168.0.2</property>
</factoryConfig>
</dbServer>
......
</amoeba:dbServers>
2.再配置完dbServer.xml後,繼續配置amoeba.xml文件:
Example 3.3. 一個基本的amoeba.xml例子
<?xml version="1.0" encoding="gbk"?>
<!DOCTYPE amoeba:configuration SYSTEM "amoeba.dtd">
<amoeba:configuration xmlns:amoeba="http://amoeba.meidusa.com/">
<proxy>
<!-- server class must implements com.meidusa.amoeba.service.Service -->
#Service節點定義了需要啟動的服務,在本配置中其class屬性為“com.meidusa.amoeba.net.ServerableConnectionManager”,這意味著這是一個Proxy Service。在這個元素下的connectionFactory元素中定義其class屬性為“com.meidusa.amoeba.mysql.net.MysqlClientConnectionFactory”,這意味著這是一個MySQL Proxy Service。相應的也會有MongoDB Proxy Service以及Aladdin Proxy Service。
<service name="Amoeba for Mysql" class="com.meidusa.amoeba.net.ServerableConnectionManager">
#這裡定義了之前我們所定義的MySQL Proxy Service的服務端口和主機地址。
#Caution:通常Proxy Service服務的主機地址並不需要定義,如果Amoeba所在的服務器在多個網絡環境內你可以定義該機器的其中一個IP來指定Amoeba所服務的網絡環境。如果設置為127.0.0.1將導致其他機器無法訪問Amoeba的服務。
<!-- port --
<property name="port">8066</property>
<!-- bind ipAddress -->
<!--
<property name="ipAddress">127.0.0.1</property>
-->
<property name="manager">${clientConnectioneManager}</property>
<property name="connectionFactory">
<bean class="com.meidusa.amoeba.mysql.net.MysqlClientConnectionFactory">
<property name="sendBufferSize">128</property>
<property name="receiveBufferSize">64</property>
</bean>
</property>
#這裡配置了MySQL Proxy Service的認證器,user和passwd屬性分別定義Amoeba對外服務的用戶名和密碼。你的程序或者數據庫客戶端需要使用該用戶名和密碼來通過Amoeba連接之前定義的dbServer。
<property name="authenticator">
<bean class="com.meidusa.amoeba.mysql.server.MysqlClientAuthenticator">
<property name="user">root</property>
<property name="password">password</property>
<property name="filter">
<bean class="com.meidusa.amoeba.server.IPAccessController">
<property name="ipFile">${amoeba.home}/conf/access_list.conf</property>
</bean>
</property>
</bean>
</property>
</service>
<!-- server class must implements com.meidusa.amoeba.service.Service -->
<service name="Amoeba Monitor Server" class="com.meidusa.amoeba.monitor.MonitorServer">
<!-- port -->
<!-- default value: random number
<property name="port">9066</property>
-->
<!-- bind ipAddress -->
<property name="ipAddress">127.0.0.1</property>
<property name="daemon">true</property>
<property name="manager">${clientConnectioneManager}</property>
<property name="connectionFactory">
<bean class="com.meidusa.amoeba.monitor.net.MonitorClientConnectionFactory"></bean>
</property>
</service>
#runtime元素定義了一些Proxy相關的運行期配置,如客戶端及數據庫服務器端的線程數以及SQL超時時間設定等等。
<runtime class="com.meidusa.amoeba.mysql.context.MysqlRuntimeContext">
<!-- proxy server net IO Read thread size -->
<property name="readThreadPoolSize">20</property>
<!-- proxy server client process thread size -->
<property name="clientSideThreadPoolSize">30</property>
<!-- mysql server data packet process thread size -->
<property name="serverSideThreadPoolSize">30</property>
<!-- per connection cache prepared statement size -->
<property name="statementCacheSize">500</property>
<!-- query timeout( default: 60 second , TimeUnit:second) -->
<property name="queryTimeout">60</property>
</runtime>
</proxy>
<!--
Each ConnectionManager will start as thread
manager responsible for the Connection IO read , Death Detection
-->
#connectionManagerList定義了一系列連接管理器,這些連接管理器可以在其他地方被引用,比如clientConnectioneManager在amoeba.xml中被引用作為MySQL Proxy Service的客戶端連接管理器;defaultManager在dbServers.xml中被引用作為dbServer的數據庫服務器端連接管理器。連接管理器主要配置了用於網絡處理的CPU核數,默認其processor屬性為Amoeba所在主機的CPU核數。
<connectionManagerList>
<connectionManager name="clientConnectioneManager" class="com.meidusa.amoeba.net.MultiConnectionManagerWrapper">
<property name="subManagerClassName">com.meidusa.amoeba.net.ConnectionManager</property>
<!--
default value is avaliable Processors
<property name="processors">5</property>
-->
</connectionManager>
<connectionManager name="defaultManager" class="com.meidusa.amoeba.net.MultiConnectionManagerWrapper">
<property name="subManagerClassName">com.meidusa.amoeba.net.AuthingableConnectionManager</property>
<!--
default value is avaliable Processors
<property name="processors">5</property>
-->
</connectionManager>
</connectionManagerList>
#最後一部分dbServerLoader定義了dbServers.xml的位置。queryRouter定義了規則配置及函數配置等相關文件的位置。
<!-- default using file loader -->
<dbServerLoader class="com.meidusa.amoeba.context.DBServerConfigFileLoader">
<property name="configFile">${amoeba.home}/conf/dbServers.xml</property>
</dbServerLoader>
<queryRouter class="com.meidusa.amoeba.mysql.parser.MysqlQueryRouter">
<property name="ruleLoader">
<bean class="com.meidusa.amoeba.route.TableRuleFileLoader">
<property name="ruleFile">${amoeba.home}/conf/rule.xml</property>
<property name="functionFile">${amoeba.home}/conf/ruleFunctionMap.xml</property>
</bean>
</property>
<property name="sqlFunctionFile">${amoeba.home}/conf/functionMap.xml</property>
<property name="LRUMapSize">1500</property>
<property name="defaultPool">server1</property>
<!--
<property name="writePool">server1</property>
<property name="readPool">server1</property>
-->
<property name="needParse">true</property>
</queryRouter>
</amoeba:configuration>
在Master/Slave結構下的讀寫分離
首先說明一下amoeba 跟 MySQL proxy在讀寫分離的使用上面的區別:
在MySQL proxy 6.0版本上面如果想要讀寫分離並且讀集群、寫集群機器比較多情況下,用mysql proxy 需要相當大的工作量,目前mysql proxy沒有現成的 lua腳本。mysql proxy根本沒有配置文件, lua腳本就是它的全部,當然lua是相當方便的。那麼同樣這種東西需要編寫大量的腳本才能完成一個復雜的配置。而Amoeba只需要進行相關的配置就可以滿足需求。
假設有這樣的使用場景,有三個數據庫節點分別命名為Master、Slave1、Slave2如下:
Master: Master (可讀寫)
Slaves:Slave1、Slave2 (2個平等的數據庫。只讀/負載均衡)
針對這樣的使用方式,首先在dbServers.xml中將Slave1和Slave2配置在一個虛擬的dbServer節點中,使他們組成一個數據庫池。
Example 4.3. 數據庫池在dbServers.xml的定義與配置
<?xml version="1.0" encoding="gbk"?>
<!DOCTYPE amoeba:dbServers SYSTEM "dbserver.dtd">
<amoeba:dbServers xmlns:amoeba="http://amoeba.meidusa.com/">
...
#定義了Master節點,parent為abstractServer,關於abstractServer的定義方式參照第三章。
<dbServer name="Master" parent="abstractServer">
<factoryConfig>
<!-- mysql ip -->
<property name="ipAddress">192.168.0.1</property>
</factoryConfig>
</dbServer>
#定義了Slave1和Slave2節點。
<dbServer name="Slave1" parent="abstractServer">
<factoryConfig>
<!-- mysql ip -->
<property name="ipAddress">192.168.0.2</property>
</factoryConfig>
</dbServer>
<dbServer name="Slave2" parent="abstractServer">
<factoryConfig>
<!-- mysql ip -->
<property name="ipAddress">192.168.0.3</property>
</factoryConfig>
</dbServer>
#定義了virtualSlave的虛擬節點,這是由Slave1和Slave2組成的一個數據庫池。
<dbServer name="virtualSlave" virtual="true">
<poolConfig class="com.meidusa.amoeba.server.MultipleServerPool">
#loadbalance元素設置了loadbalance策略的選項,這裡選擇第一個“ROUNDROBIN”輪詢策略,該配置提供負載均衡、failOver、故障恢復功能。
<!-- Load balancing strategy: 1=ROUNDROBIN , 2=WEIGHTBASED , 3=HA-->
<property name="loadbalance">1</property>
#poolNames定義了其中的數據庫節點配置(當然也可以是虛擬的節點)。此外對於輪詢策略,poolNames還定義了其輪詢規則,比如設置成“Slave1,Slave1,Slave2”那麼Amoeba將會以兩次Slave1,一次Slave2的順序循環對這些數據庫節點轉發請求。
<!-- Separated by commas,such as: server1,server2,server1 -->
<property name="poolNames">Slave1,Slave2</property>
</poolConfig>
</dbServer>
...
</amoeba:dbServers>
如果不需要配置規則那麼可以不使用rule.xml而直接配置amoeba.xml中的queryRouter,配置如下:
Example 4.4. 配置amoeba.xml不使用切分功能直接配置queryRouter以讀寫分離
<?xml version="1.0" encoding="gbk"?>
<!DOCTYPE amoeba:configuration SYSTEM "amoeba.dtd">
<amoeba:configuration xmlns:amoeba="http://amoeba.meidusa.com/">
...
<queryRouter class=”com.meidusa.amoeba.mysql.parser.MysqlQueryRouter”>
#LRUMapSize屬性定義了Amoeba緩存的SQL語句解析的條數。
<property name="LRUMapSize">1500</property>
#defaultPool配置了默認的數據庫節點,一些除了SELECT\UPDATE\INSERT\DELETE的語句都會在defaultPool執行。
<property name="defaultPool">Master</property>
#writePool配置了數據庫寫庫,通常配為Master,如這裡就配置為之前定義的Master數據庫。
<property name="writePool">Master</property>
#readPool配置了數據庫讀庫,通常配為Slave或者Slave組成的數據庫池,如這裡就配置之前的virtualSlave數據庫池。
<property name="readPool">virtualSlave</property>
<property name="needParse">true</property>
</queryRouter>
...
</amoeba:configuration>
通過Amoeba對數據進行簡單的分片
配置dbServers.xml
首先根據前一小節的配置,在dbServers.xml中增加一個dbServer元素(即是我們新增用於水平切分的數據庫)如下:
<?xml version="1.0" encoding="gbk"?>
<!DOCTYPE amoeba:dbServers SYSTEM "dbserver.dtd">
<amoeba:dbServers xmlns:amoeba="http://amoeba.meidusa.com/">
...
<dbServer name="server2" parent="abstractServer">
<factoryConfig>
<!-- mysql ip -->
#這裡僅僅在之前的dbServers.xml文件中增加了一段新的節點配置,server2同樣繼承了abstractServer的配置,唯一不同的是其主機地址不一樣,因此它有自己的主機地址屬性,你需要按自己的實際需求配置這個主機地址。
<property name="ipAddress">192.168.0.1</property>
</factoryConfig>
</dbServer>
...
</amoeba:dbServers>
配置rule.xml
Example 3.4. 一個基本的rule.xml配置示例
<?xml version="1.0" encoding="gbk"?>
<!DOCTYPE amoeba:rule SYSTEM "rule.dtd">
<amoeba:rule xmlns:amoeba="http://amoeba.meidusa.com/">
#tableRule的name屬性定義了表名、schema為數據庫名、defaultPools定義了該表的默認庫。
<tableRule name="staff" schema="test" defaultPools="server1,server2">
#在tableRule中定義了名為rule1的規則,規則的返回結果為POOLNAME,在這裡ruleResult還有其他配置項,將在後面介紹。
<rule name="rule1" ruleResult="POOLNAME">
#parameters元素定義了切分的參數,比如在例子的場景中就是按照員工號來進行切分。通常parameters的配置為該表的某列列名或幾列列名。
<parameters>ID</parameters>
#expression元素定義了類似VB Script的切分表達式。在本例中,Amoeba對ID(員工號)取余,如果員工號是單數則存儲在server2中,員工號是雙數則存儲在server1中。
<expression><![CDATA[
var division = ID % 2;
case division when 0 then 'server1';
when 1 then 'server2';
end case;
]]></expression>
</rule>
</tableRule>
</amoeba:rule>
基於Amoeba的數據水平切分
數據水平切分這種方式應該是大家都能想到的,但數據切分以後我們如何訪問我們的應用,我們應用如何按照規則做實時的數據切分?在應用層面還是其他層?這個難題可以托付給Amoeba來解決。 Amoeba提供對dba非常友好的數據切分規則表達式。
之前已經有一個通過Amoeba將員工ID通過奇偶不同水平切分到兩台機器上的實例。這裡會使用一些稍稍復雜一些的函數來完成。
假設我們messagedb 需要根據id hash進行水平切分,我們可以根據hash范圍分成2台:
規則1: abs(hash(id)) mod 2 = 0 → blogdb-1
規則2: abs(hash(id)) mod 2 = 1 → blogdb-2
這裡abs、hash 都是amoeba 規則中使用到的函數,amoeba允許開發人員增加新的規則函數,這在本章節的Amoeba自定義函數配置詳解小節中介紹。
數據的水平切分主要通過對rule.xml文件的配置,如以下這個配置示例:
Example 4.1. 通過配置rule.xml完成水平分區
<?xml version="1.0" encoding="gbk"?>
<!DOCTYPE amoeba:rule SYSTEM "rule.dtd">
<amoeba:rule xmlns:amoeba="http://amoeba.meidusa.com/">
...
#配置該表的表明和數據庫名,defaultPools為需要MESSAGE表被分片到的兩個數據庫節點以逗號分隔符。defaultPools屬性中的數據庫節點須是dbServers.xml中配置的虛擬數據庫節點或真實數據庫節點。
<tableRule name="MESSAGE" schema="test" defaultPools="blogdb-1,blogdb-2">
<rule name="rule1">
#parameters元素定義了用作分區規則的字段,這裡是MESSAGE.ID。
<parameters>ID</parameters>
#expression元素定義了分區規則,可以從這裡了解到rule1中ID哈希取絕對值後模2為0的數據被分片到blogdb-1上。
<expression><![CDATA[ abs(hash(id)) mod 2 = 0 ]]></expression>
<defaultPools>blogdb-1</defaultPools>
</rule>
<rule name="rule2">
<parameters>ID</parameters>
<expression><![CDATA[ abs(hash(id)) mod 2 = 1 ]]></expression>
<defaultPools>blogdb-2</defaultPools>
</rule>
</tableRule>
...
</amoeba:rule>
基於Amoeba的數據垂直切分
垂直切分(縱向)數據是數據按照網站業務、產品進行切分,比如用戶數據、博客文章數據、照片數據、標簽數據、群組數據等等每個業務一個獨立的數據庫或者數據庫服務器。
如果一個應用只針對單純的業務功能模塊。那麼可以直接連接相應的被垂直切分的數據庫。但一些復雜的應用需要用到相當多的業務數據,涉及到幾乎所有的業務數據。那麼垂直切分將會給應用帶來一定的復雜度,而且對工程師開發也會有一定影響。整個應用的復雜度將上升。
Amoeba在其中充當了門面功能,相當於水利樞紐。疏通應用與多個數據庫數據通訊。
假設有3個數據庫:userdb、blogdb、otherdb
userdb:包含有user表
blogdb:包含有message、event
otherdb:其他表所在的數據庫
數據的垂直切分主要通過對rule.xml文件的配置,如以下這個配置示例:
Example 4.2. 通過配置rule.xml完成垂直分區
<?xml version="1.0" encoding="gbk"?>
<!DOCTYPE amoeba:rule SYSTEM "rule.dtd">
<amoeba:rule xmlns:amoeba="http://amoeba.meidusa.com/">
...
文章大部分參考於amoeba的首頁文檔:
http://docs.hexnova.com/amoeba/