18 復制... 1
18.1 復制配置... 3
18.1.1 基於Binary Log的數據庫復制配置... 3
18.1.2 配置基於Binary log的復制... 3
18.1.2.1 設置復制master的配置... 3
18.1.2.2 創建復制要用的用戶... 4
18.1.2.3 獲取復制Binary Log坐標... 4
18.1.2.4 選擇同步數據快照的方法... 4
18.1.2.5配置Slave. 5
18.1.2.6 為復制環境增加一個slave. 6
18.1.3 基於全局事務標示符的復制... 7
18.1.3.1 GTID概述... 7
18.1.3.2 使用GTID配置復制... 10
18.1.3.3 使用GTID故障轉移或者擴展... 11
18.1.3.4 使用GTID復制的限制... 13
18.1.4 多主復制... 14
18.1.4.1 MySQL多主復制概述... 14
18.1.4.2多主復制教程... 14
18.1.4.3 多主復制監控... 15
18.1.4.4 多主復制錯誤信息... 16
18.1.5 修改在線服務的復制模式... 17
18.1.5.1 復制模型概述... 17
18.1.5.2 在線啟動GTID事務... 18
18.1.5.3 在線關閉GTID事務... 19
18.1.5.4 驗證復制的匿名事務... 19
18.1.6 復制和Binary log選項和變量... 20
18.1.7 通常的管理任務... 20
18.1.7.1檢查復制狀態... 20
18.1.7.2 暫停Slave上的復制... 22
18.2 復制的實現... 22
18.2.1 復制格式... 22
18.2.1.1 基於語句和基於行復制的好處和壞處... 23
18.2.1.2 基於行復制的用處... 24
18.2.1.3 確定binary log中安全和非安全語句... 25
18.2.2 復制實現細節... 26
18.2.3 復制渠道... 27
18.2.3.1 單個渠道的命令和選項... 27
18.2.3.2 版本兼容... 28
18.2.3.3 復制渠道啟動選項... 28
18.2.3.4 復制渠道命名協定... 28
18.2.4 復制 Relay日志和狀態日志... 28
18.2.4.1 Slave Relay Log. 28
18.2.4.2 Slave狀態日志... 29
18.2.5 服務如何評估復制過濾規則... 29
18.2.5.1 評估數據庫級別復制和bianry log選項... 30
18.2.5.2 評估表復制選項... 31
18.2.5.3 復制規則應用... 33
18.3 復制解決方案... 33
18.3.1 使用復制備份... 33
18.3.1.1 使用mysqldump備份slave. 34
18.3.1.2 備份原生數據... 34
18.3.1.3 標記為只讀備份master或者slave. 34
18.3.2 復制Master和Slave不同引擎... 35
18.3.3使用復制的橫向擴展... 35
18.3.4 不同的slave復制不同的數據庫... 36
18.3.5 提高復制性能... 36
18.3.6 在錯誤的時候切換Master37
18.3.7 使用安全連接配置復制... 39
18.3.8 半同步復制... 41
18.3.8.1 半同步復制管理接口... 42
18.3.8.2 半同步復制安裝和配置... 42
18.3.8.3 半同步復制監控... 43
18.3.9 延遲復制... 44
18.4 復制注意和提示... 44
復制是一個MySQL服務master,復制到另外一個服務slave。復制默認是異步的。Slave不需要一直連接到slave獲取master的更新。根據配置,你可以復制所有的數據庫,或者指定數據庫,或者數據庫內的幾個表。
MySQL復制的有點:
1.可以分散負荷到多個slave來提高性能。在這個環節,所有的寫必須在master執行,讀可以在slave上執行。這個模式可以提高些性能。也提高讀性能。
2.數據安全,因為數據被復制到slave,slave可以暫停復制進場,可以執行備份,不會損壞master上的數據。
3.分析,live數據可以在master上創建,分析行為可以在slave上執行,不會影響master。
4.長距離數據分布,你可以使用在本地創建遠程數據的副本,不需要訪問master。
MySQL 5.7支持不同的復制方法。傳榮的方法是基於master的binlog,根據log文件的positions來同步。新的方法是基於全局事務標示(GTIDs)是事務標示因此不需要log文件和位置,簡化了很多復制任務。復制使用GTIDs保證了master和slave 的一致性,只要在master上提交的事務也會在slave 上提交。關於使用GTIDs復制具體看: Section 18.1.3, “Replication with Global Transaction Identifiers”
在MySQL中的復制支持不同類型的同步。通常是單路異步的同步,一個服務作為master,多個作為slave。在MySQL5.7,半同步復制也被支持,擴展了異步復制。使用半同步復制,在事務提交回復session之前,保證至少有一個slave接受到通知並且接受並且記錄了事務的日志。MySQL也支持延遲復制比如slave至少延遲指定時間的日志。
有2個核心類型的復制,基於語句的復制,語句行的復制。也可以使用混合復制類型。
復制通過一些列的選項和變量控制。
當你使用復制來解決各種不同問題,包括性能,支持不同數據庫的備份。和一些列解決方案來緩解系統錯誤。
根據數據庫的配置,Binary log的格式不同。Slave配置讀取master的binary log並且執行。
沒個slave復制整個binary log。Slave負責哪個語句要被執行。除非你執行了,否則搜有binary log 都會被執行到slave。你可以配置slave指定只執行那些數據庫或者表的binary log。
每個slave都保留了一個binary log 的相關記錄,記錄已經從master傳過來的文件名和文件中的位置。也就是說多個slave 可以連接到master並且執行不同的binary log部分。因為slave控制了這些進程,獨立的slave可以連接或者不連接到服務,不會對master操作影響。也是因為每個slave記錄了當前Binary log 的位置,可以讓slave斷開之後重新連接。
Master和每個slave必須配置一個唯一的id,server-id,另外每個slave必須配置關於master的一些信息,具體可以看change master to的參數。
大致步驟如下:
1.在master,啟動binary log配置server id。可能需要重啟服務。
2.每個slave想要連接的master,必須配置server id,可能需要重啟服務。
3.可選,創建一個獨立的用戶來驗證,讀取binary log。
4.在創建數據快照或者復制進程之前,在master上需要記錄當前binary log 的位置。你需要配置slave這樣slave知道從哪裡開始執行事件。
5.如果你已經有了數據在master上,想要使用它來同步到slave,你需要創建一個數據快照,並且復制到slave。存儲引擎會影響創建快照的方式,當你使用MyISAM你必須停止語句獲取READ-LOCK,獲取當前的binary log並且導出數據。在允許master繼續執行語句之前。如果你沒有停止服務導出數據,master 的狀態信息就不匹配,導致slave的數據庫損壞或者不一致。如果你使用innodb,不需要使用read-lock。
6.配置slave連接到master 的信息比如host,login,binary log文件名和位置。
為了配置master使用binarylog文件,你必須啟動binary log並且設置server id。如果沒有被設置,需要重啟服務。
Binary Log必須被啟動,因為binary log是傳輸修改的基礎。如果binary log 沒有啟動,那麼就不能配置復制。
在復制組內的每個服務必須配置唯一的server id。這個ID用來表示唯一的服務,必須是1到2^32-1中的一個值。
配置binary log和server id選項,關閉MySQL服務並且修改my.cnf在mysqld的配置下設置log-bin和server-id選項。如果已經存在那個根據需要來修改。例如:
[mysqld]
log-bin=mysql-bin
server-id=
修改之後需要重啟。
每個slave連接到master使用MySQL用戶名和密碼,所以必須有個用戶賬號在master,slave可以用來連接。任何賬號可以使用這個操作,必須要有REPLICATION SLAVE權限。你可以根據選擇為不同的slave創建不同的賬號,或者使用相同的賬號連接到master。
盡管你沒有創建指定的用戶用於復制,要注意復制用戶名密碼是明文保存在碼,master信息表或者文件中。
使用create user來創建用戶。授予復制需要的權限。如果你創建賬號是為了復制,只需要REPLICATION SLAVE權限就可以了。
mysql> CREATE USER 'repl'@'%.mydomain.com' IDENTIFIED BY 'slavepass';
mysql> GRANT REPLICATION SLAVE ON *.* TO 'repl'@'%.mydomain.com';
為了配置 slave啟動復制進程你需要master 當前binary log的坐標。如果master已經運行但是沒有啟動binary log那麼SHOW MASTER STATUS和mysqldump –master-data是空的。這個時候只要指定文件為空,位置為4.
如果master已經設置了binary log,使用以下過程來獲取:
1.啟動會話連接到master,以只讀模式刷新所有的表,flush tables with read lock。
2.在其他會話中,使用SHOW MASTER STATUS語句回去binary log的位置和文件。
如果master數據庫包含的數據需要復制到所有的slave。有2個復制數據的方法:
1.使用mysqldump導出數據
2.如果是binary portable文件你可以復制原生的數據文件。比mysqldump可能要有效的多。
shell> mysqldump --all-databases --master-data > dbdump.db
使用--master-data會自動生成change master語句。
可以使用企業版的備份工具mysqlbackup備份,也可以使用xtrabackup進行備份。
配置slave前,確保以下步驟:
1.配置MySQL Master
2.獲取master狀態信息
3.在master上釋放讀鎖
每個復制slave必須有一個唯一的server id。重啟服務生效。
如果slave server id已經沒有被設置,或當前值server id和master的沖入,需要重新設置一個server id。如果有多個slave每個slave 都要有一個唯一的server id。slave上沒必要啟動binary log。但是如果你在slave 上啟動了binary log,你可以使用slave的binary log備份和恢復。也可以把slave作為復雜拓撲的一部分。比如這個slave對於其他slave是master。
為了slave可以和master交互,需要配置master的連接信息。使用如下語句:
mysql> CHANGE MASTER TO
-> MASTER_HOST='master_host_name',
-> MASTER_USER='replication_user_name',
-> MASTER_PASSWORD='replication_password',
-> MASTER_LOG_FILE='recorded_log_file_name',
-> MASTER_LOG_POS=recorded_log_position;
Change master to語句也有其他選項比如使用SSL。Change master to的所有選項可以查看:Section 13.4.2.1, “CHANGE MASTER TO Syntax”.
如果master有數據可以導入到slave中,導入方法如下:
1.如果有一個快照數據庫導入,查看: Section 18.1.2.5.3, “Setting Up Replication between a New Master and Slaves”.
2.如果你沒有快照數據庫導入可以看:Section 18.1.2.5.3, “Setting Up Replication between a New Master and Slaves”.
當沒有快照導入,為新的master配置slave。在所有slave都要執行
1.啟動MySQL Slave並且連接
2.執行change master to配置master replication server。
這個方法也可以使用在設置一個新的master,已經有了數據dump要導入的master上。
如果配置復制環境使用了其他服務器的數據來配置新master,可以dump文件來生成型的服務。數據庫更新會自動傳播到slave。
當配置復制但是已經有數據了,在復制啟動錢,把快照從master傳輸到slave。步驟如下:
1.啟動slave,但是使用—skip-slave-start,不啟動slave。
2.導入dump文件
如果使用raw data創建了快照:
1.把數據文件解壓倒slave數據目錄
2.啟動slave,--skip-slave-start
3.使用master的相關信息來配置slave。獲取change master to要的信息。
4.啟動slave
你已經處理了過程,slave連接到master並且復制master上所有的更新。
1.如果master忘記了設置server-id,slave不能連接
2.如果slave忘記了server-id,slave的error日志就會有以下錯誤
Warning: You should set server-id to a non-0 value if master_host is set; we will force server id to 2, but this MySQL server will not act as a slave.
slave使用的信息存放在master info中,跟蹤了已經處理了多少master的binary log。這個數據可以是文件或者表的方式,有—master-info-repository來決定。當參數為file,你可以在數據文件中找到2個文件master.info和relay-log.info。如果為table那麼信息保存在mysql下的master_slave_info表中。如果刪除表或者文件master信息就會丟失。
可以在不停止master的情況下為復制環境增加一個slave。為新的slave配置一個server-id。
1.關閉存在的slave
2.復制數據目錄到新的slave。你可以使用tar打包,也可以直接cp或者rsync。
當心的復制slave加入,往往會發生以下常見錯誤:
071118 16:44:10 [Warning] Neither --relay-log nor --relay-log-index were used; so
replication may break when this MySQL server acts as a slave and has his hostname
changed!! Please use '--relay-log=new_slave_hostname-relay-bin' to avoid this problem.
071118 16:44:10 [ERROR] Failed to open the relay log './old_slave_hostname-relay-bin.003525'
(relay_log_pos 22940879)
071118 16:44:10 [ERROR] Could not find target log during relay log initialization
071118 16:44:10 [ERROR] Failed to initialize the master info structure
這個錯誤是因為—relay-log沒有指定導致的,relay log文件以host名字開頭,有一個index文件,--relay-log-index文件控制。
為了避免這個問題使用,--relay-log使用和老的slave一樣的值。如果選項沒有被顯示設置使用hostname-relay-bin。設置--relay-log-index和老的slave一樣。如果沒有顯示設置默認為hostname-relay-bin.index。如果你已經設置了relay log也是有以上的錯誤:
a.如果沒有設置relay log設置,在新的slave上關閉slave,stop slave。如果來的slave也啟動了,老的slave也需要關閉。
b.復制老的slave中的relay log index文件內容到新的slave relay log index文件中。
c.執行重命名
3.復制master信息和relay log信息內容到新的slave。
4.啟動已經存在的slave
5.在新的slave 上給一個新的server-id
6.啟動新的slave,使用master信息的內容來啟動。
GTID是事務的唯一標示。並不是對某一個服務來說是唯一標示,是所有服務內都是唯一的。
GTID有2部分組成,有冒號分隔如下:
GTID = source_id:transaction_id
Source_id標示原始服務,通常使用服務的server_uuid。Transaction_id標示事務的順序好。比如第一個事務可能是1。比如有個GTID:
3E11FA47-71CA-11E1-9E33-C80AA9429562:23
這種格式來表示GTID,在show slave status和binary log輸出,也可以在show binlog events中看到。
在show master status輸出的GTID可能會被收縮到一個語句,比如:
3E11FA47-71CA-11E1-9E33-C80AA9429562:1-5
GTID set的語法格式如下:
gtid_set:
uuid_set [, uuid_set] ...
| ''
uuid_set:
uuid:interval[:interval]...
uuid:
hhhhhhhh-hhhh-hhhh-hhhh-hhhhhhhhhhhh
h:
[0-9|A-F]
interval:
n[-n]
(n >= 1)
GTID set在服務很多方面都被使用,比如,qtid_executed和qtid_purged系統變量使用GTID set表示。另外GTID_SUBSET和GTID_SUBTRACT需要GTID set作為輸入。
GTID會在master和slave保留。也就是說你可以決定通過檢查binary log可以知道slave應用了那些事務。另外一旦有GTID的事務被提交,任何語句使用這個GTID的都會被服務忽略。因此在master上的提交事務可以被多次應用到slave,也保證了一致性。
當GTID被使用,slave不需要本地數據,比如master上的文件名或者位置。所有必要的信息在master中被獲取直接來至於復制數據流。GTIDs代替文件位置來決定開始,結束和恢復的點。也沒有必要在change master上設置master_log_file和master_log_pos只需要啟動master_auto_position選項。
GTID的生成和生命周期:
1.事務在master上被提交和執行。
GTID是由master的uuid和一個非0的順序號,GTID會被寫入到binary log。
2.binary log數據被傳輸到slave並且保存到slave的relay log。slave讀取GTID並且設置gtid_next系統變量最為它的GTID。告訴slave下一個事務必須使用這個GTID來記錄。
3.slave驗證這個GTID是否已經被使用記錄到binary log。如果GTID沒有被使用,slave寫GTID,應用事務,並且把事務寫入到binary log。先讀取和檢查事務的GTID,然後執行事務本身,保證了之前沒有事務使用過這個GTID,也沒有其他事務讀取了這個GTID,但是沒有提交的情況。也就是說多個客戶端不允許並行的應用同一個事務。
4.因為gtid_next是非空的,slave沒有試圖為事務生成GTID,而是寫入被保存在這個變量的GTID。
Mysql.gtid_executed表
從MySQL 5.7.5開始,GTID被存儲在gtid_executed表中。每個GTID,GTID set都有一樣,uuid,事務的開始和結束id,如果只有一個那麼開始和結束是一樣的。在mysql安裝或者更新的時候就已經被創建。
CREATE TABLE gtid_executed (
source_uuid CHAR(36) NOT NULL,
interval_start BIGINT(20) NOT NULL,
interval_end BIGINT(20) NOT
NULL,
PRIMARY
KEY (source_uuid, interval_start)
)
只有在gtid_mode=on或者on_premissive的時候GTID才會保存在mysql. gtid_executed下,存儲方式的不同取決於log_bin是on或者off。
1.如果binary log沒有啟動,服務存儲每個事務的GTID到這個表
2.如果binary log啟動,除了把GTID保存在這個表上,不管binary log是不是被回繞或者服務關閉,服務把所有事務的GTID寫入到之前binary log 的都寫入到新的Binary log 上。
當服務異常關閉,GTID沒有被保存到mysql.gtid_executed表。在恢復的時候GTID被加入到表並且gtid_executed系統變量。
Reset master重置mysql.gtid_executed。
Mysql.gtid_executed表壓縮
一段時間之後,這個表就會變得很大,考慮到空間問題,可以把一些事務折疊比如:
mysql> SELECT * FROM mysql.gtid_executed;
+--------------------------------------+----------------+--------------+
| source_uuid | interval_start | interval_end |
|--------------------------------------+----------------+--------------|
| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 37 | 37 |
| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 38 | 38 |
| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 39 | 39 |
| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 40 | 40 |
| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 41 | 41 |
| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 42 | 42 |
| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 43 | 43 |
...
壓縮成
+--------------------------------------+----------------+--------------+
| source_uuid | interval_start | interval_end |
|--------------------------------------+----------------+--------------|
| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 37 | 43 |
...
當GTID啟動,服務定期對mysql.gtid_executed這類壓縮。你可以設置executed_gtids_commpression_period修改壓縮比率,默認是1000,表示每1000個事務一次壓縮。設置為0表示不進行壓縮。
有一個專門的後台線程來執行壓縮,show processlist無法顯示,可以用thread表查看:
mysql> SELECT * FROM PERFORMANCE_SCHEMA.THREADS WHERE NAME LIKE '%gtid%'\G
*************************** 1. row ***************************
THREAD_ID: 21
NAME: thread/sql/compress_gtid_table
TYPE: FOREGROUND
PROCESSLIST_ID: 139635685943104
PROCESSLIST_USER: NULL
PROCESSLIST_HOST: NULL
PROCESSLIST_DB: NULL
PROCESSLIST_COMMAND: Daemon
PROCESSLIST_TIME: 611
PROCESSLIST_STATE: Suspending
PROCESSLIST_INFO: NULL
PARENT_THREAD_ID: 1
ROLE: NULL
INSTRUMENTED: YES
當線程一次執行後,下次執行需要睡眠executed_gtids_commpression_period,再啟動運行壓縮。如果當binary log禁用設置為0,表示一直睡眠不執行壓縮。
配置復制的關鍵步驟如下:
1.如果復制已經在運行,把同步服務都設置為只讀。
2.關閉2個服務。
3.啟動GTID和正確的配置啟動2個服務。
4.指示使用master作為slave數據源,並且使用自動位置,然後啟動slave。
5.啟動read模式,讓他們可以接受寫請求。
一下例子是,2個服務已經是master和slave了,使用MySQL binary log位置為基礎的復制協議。一下很多操作需要root賬號或者SUPER權限。
步驟1:同步服務,保證服務是只讀的,2個服務都啟動只讀模式
mysql> SET @@global.read_only = ON;
步驟2:關閉2個服務,
shell> mysqladmin -uusername -p shutdown
步驟3:重啟2個服務並且啟動GTID,為了使用基於GTID的服務,每個服務必須啟動GTID模式,通過設置gtid_mode,設置--enforce-gtid-consistency選項保證只有對於GTID復制安全的語句才會被記錄日志。另外使用—skip-slave-start啟動slave。
Mysql 5.7.5沒有強制要求使用使用GTID要啟動binary log因為有額外的mysql.gtid_executed表。也就是說slave可以使用gtid不啟動binary log。
shell> mysqld --gtid-mode=ON --enforce-gtid-consistency &
在Mysql 5.7.4或者更早的版本,使用GTID要啟動binary log
shell> mysqld --gtid-mode=ON --log-bin --enforce-gtid-consistency &
步驟4:slave直接使用master,告訴slave使用使用master的作為復制源,並且使用基於GTID的自動位置,而不是基於文件的位置。執行change master to,使用master_auto_position選項告訴slave事務由GTID標示。
mysql> CHANGE MASTER TO
> MASTER_HOST = host,
> MASTER_PORT = port,
> MASTER_USER = user,
> MASTER_PASSWORD = password,
> MASTER_AUTO_POSITION = 1;
不需要再設置master_log_file選項和master_log_pos選項。使用master_auto_position設置為1,如果這麼做可能導致change master to語句錯誤。
假設change master to語句執行正確,啟動slave:
mysql> START SLAVE;
步驟5:取消只讀模式
mysql> SET @@global.read_only = OFF;
MySQL復制基於GTID對加入的slave通過一些技術提供擴展和master的故障轉移:
1.簡單復制
2.復制數據和事務到slave
3.注入空的事務
4.使用gtid_purged清空事務
5.還原gtid模式的slave
GTID被加入的復制的目的是讓復制的數據量和故障轉移行為關閉變得更加簡單。每個唯一標示是一組binary log 的時間,表示一個事務。GTID在數據庫修改起到關鍵的作用:服務自動跳過任何已經被服務識別為已經運行過的事務。這個行為對於復制重新定位和正確故障轉移很重要。
標示符和一組事件組成的事務可以在binary log獲得。這樣可能一個新的服務從老的服務獲取數據有一些問題。為了讓新的服務重新生成標記,有必要把老服務的標記復制到新服務,並且保存標示符之間和實際事件之間的關系。這個對於一個新還原的slave馬上能夠成為故障轉移或者切換的候選很重要。
簡單復制
最簡單的方式在新服務上生成所有的標示和事務是把新的服務弄成slave。
一旦服務啟動,新的服務從master上復制整個binary log,獲取所有關於gtid的信息。
這個方法簡單而且有效,但是需要slave從master上讀取binary log。可能slave要趕上master要花相當長的一段時間。所以這個方法不適用於快速故障轉移或者備份恢復。
復制數據和事務到slave
重播整個事務歷史是很耗時的,會是啟動新slave的瓶頸。為了消除這個請求,對數據集進行快照,binary log和全局信息導入到slave。Binary log重播完之後啟動復制,使用了剩下的事務之後,就可以跟上。
有很多方式來完成這個方法,不同點是如何dump數據並且傳輸binary log到slave。
Data Set
Transaction History
· 使用mysql客戶端導入mysqldump導出的文件。使用—master-data選項在導出時獲取binary log信息。--set-gtid-purged=auto或者on,來包含已經執行的事務信息,如果是在slave導入服務要啟動—gtid-mode=on
· 關閉slave,復制master的數據文件到slave的數據目錄文件然後重啟slave。
如果gtid-mode不是on,重啟服務並且啟動gtid模式。
· 使用mysqlbinlog程序導入bin log,並且使用—read-from-remote-server和—read-from-remote-master選項
· 復制master的binary log文件到slave。你可以使用—read-from-remote-server –raw來做復制。然後用一下方法讀入到slave中:
§ 更新binlog.index指向到復制的binary log執行CHANGE MASTER TO 指向第一個日志文件,然後啟動start slave。
§
使用mysqlbinlog > file (不使用—raw選項)
導出Binary log文件稱為可以被mysql客戶端執行的sql文件。
這個方法有個好處是新的服務可以很快的被使用,只有某些事物在快照或者dump文件產生的事務還是需要從master上獲取。也就是說slave可用不是瞬間的,但是相對來說slave獲取這些事務是很快能夠完成的。
復制binary log到目標服務通常比讀取整個事務執行歷史要快。但是移動這些文件並不是一直可用的因為文件大小伙子其他原因。
注入空的事務
Master的全局gtid_executed變量包含了所有在master 上執行過的事務。為新服務提供快照之後,不通過復制binary log,而是觀察gtid_executed在快照執行完之後的變化。在新服務加入到復制鏈之前,簡單的提交再gtid_executed上包含的內容比如:
SET GTID_NEXT='aaa-bbb-ccc-ddd:N';
BEGIN;
COMMIT;
SET GTID_NEXT='AUTOMATIC';
一旦所有事務使用這種方式恢復。你要刷新日志並且清理之前的所有binary log。
FLUSH LOGS;
PURGE BINARY LOGS TO 'master-bin.00000N';
為了防止事件中的錯誤事務導致大量錯誤。(FLUSH LOGS語句強制創建一個新的binary log,PURGE BINARY LOGS清理空的事務,但是保留了標示符。)
這個創建的服務根據快照,但是可以馬上變成master,因為已經趕上了master。
使用gtid_purged跳過事務
Master的全局變量gtid_purged包含所有被master binary log清理的事務。你可以記錄gtid_executed在master快照的時候的值。不想之前的方法需要清空事務,或者purge binary logs。而是直接在slave上設置gtid_purged,根據快照時候發生的gtid_executed。
和空事務方法一樣,服務通過快照創建,只要binary log 趕上master就能夠使用。
恢復GTID模式的Slave
當恢復在GTID復制中的slave,注入空事務不能解決問題因為這個事件沒有GTID。
使用mysqlbinlog找出下一個事務,這個事件後哪個可能是下一個日志文件的第一個事務。復制所有東西直到commit語句,確保包含了set @@SESSION.GTID_NEXT。當你使用基於行的復制,你可以任然在客戶端上運行binary log的行事件。
停止slave,運行復制的事務。Mysqlbinlog會把定義符號設置為/*!*/,要設置回來。
mysql> DELIMITER ;
重啟復制使用自動定位:
mysql> SET GTID_NEXT=automatic;
mysql> RESET SLAVE;
mysql> START SLAVE;
因為GTID復制依賴於事務,一些特性在mysql可用,但是不支持。
更新非事務存儲引擎
當使用GTID,更新非事務表比如MyISAM的時候不會產生事務。
這個限制是因為這個表是非事務引擎上的表如果混合了更新了事務表,那麼一個事務會產生多個GTID。這樣的話一對一的事務和GTID的對應就破壞了。
CREATE TABLE … SELECT語句
Create table select語句對於給予語句的復制是不安全的,當使用基於行復制,實際上被記錄為2個事件一個是創建表,另外一個是插入記錄到新表。當語句在一個事務內執行,很有可能是2個事件有一個GTID。也就是說插入語句會被跳過,因此create table…select不會被GTID支持。
臨時表
創建或者刪除臨時表語句使用GTID不被事務支持(當啟動了—enforce-gtid-consistencyt的情況)。這個語句是可以被支持的,但是要在事務外面。或者自動提交的事務。
阻止不支持的語句
為了阻止會導致GTID復制失敗的語句,所有服務必須以—enforce-gtid-consistency選項啟動。這樣前面說的任何語句都會報錯。
Sql_slave_skip_counter不能被支持。如果你需要跳過事務,你使用master上的gtid_executed注入空事務。
GTID模式和mysqldump
導入一個從沒有啟動了GTID模式的MySQL服務的數據到一個GTID啟動了mysql服務是很有可能。
GTID模式和mysql_upgrade
不推薦在使用了gtid-mode=on的服務使用mysql_upgrade,因為mysql_upgrade會修改系統表,系統表是使用myisam,非事務引擎。
MySQL多主復制可以讓復制slave從多個源中獲得事務。多主復制可以用來備份多個服務到單個服務上,共享表,並且把多個服務的數據聯合到一個服務上。多主復制沒有實現事務的沖突發現和解決,如果有需要這些工作就丟給了應用程序。在多主復制拓撲上slave為每個master創建一個replication channel用來獲取事務。
本節解釋如何配置多主復制拓撲,提供詳細的master和slave配置。比如拓撲至少要2個master和一個slave。
Master可以是基於GTID,也可以基於binary log的。
多主復制不支持復制信息存放在文件中,要存放在表中,啟動mysql要加以下配置:
--master-info-repository=TABLE --relay-log-info-repository=TABLE
為了修改現在的復制slave,把文件模式改為表模式。
STOP SLAVE;
SET GLOBAL master_info_repository = 'TABLE';
SET GLOBAL relay_log_info_repository = 'TABLE';
假設你有一個啟動了GTID的master,使用了gtid_mode=on,啟動復制用戶,並且保證slave是使用了table保存復制信息。使用change master to語句加上for channel子句,比如:
CHANGE MASTER TO MASTER_HOST='master1', MASTER_USER='rpl', MASTER_PORT=3451, MASTER_PASSWORD='', \
MASTER_AUTO_POSITION = 1 FOR CHANNEL 'master-1';
多主復制兼容自動定位,對每個額外的master使用這個步驟,加入到一個channel。
假設你有一個基於binary log的master,注意當前的binary log位置保證slave的復制信息是保存在表中的。根據知道的master_log_file,master_log_position設置change master to,把master增加到新的channel中。
CHANGE MASTER TO MASTER_HOST='master1', MASTER_USER='rpl', MASTER_PORT=3451, MASTER_PASSWORD='' \
MASTER_LOG_FILE='master1-bin.000006', MASTER_LOG_POS=628 FOR CHANNEL 'master-1';
一旦你都已經配置了所有master信息,使用start slave thread_types語句來啟動復制。當你在slave啟動了多主復制,你可以選擇啟動所有的channel或者選擇特定的channel。
1.啟動所有channel
START SLAVE thread_types;
2.指定某個channel
START SLAVE thread_types FOR CHANNEL channel;
Stop slave語句可以用來停止多主復制的slave。默認使用stop slave語句停止所有的channel。也可以使用for channel指定一個channel。
1.停止所有的channel
STOP SLAVE thread_types;
2.停止一個命名的channel
STOP SLAVE thread_types FOR CHANNEL channel;
使用thread_type選項選擇想要停止的slave。
Reset slave語句可以用來重置多主復制slave。默認reset slave重置所有channel。也可以指定channel。
1.重置所有channel
RESET SLAVE;
2.重置指定channel
RESET SLAVE FOR CHANNEL channel;
為了監控多主復制channel的狀態:
1.使用復制性能框架表。這些表的第一列都是channel_name.
2.使用show slave status for channel。默認如果for channel子句沒有使用,語句會顯示所有channel的狀態。Channel_name作為結果的一個列。如果提供了for channel結果顯示了改channel的狀態。
一下顯示所有channel的連接狀態:
mysql> SELECT * FROM replication_connection_status\G;
*************************** 1. row ***************************
CHANNEL_NAME: master1
GROUP_NAME:
SOURCE_UUID: 046e41f8-a223-11e4-a975-0811960cc264
THREAD_ID: 24
SERVICE_STATE: ON
COUNT_RECEIVED_HEARTBEATS: 0
LAST_HEARTBEAT_TIMESTAMP: 0000-00-00 00:00:00
RECEIVED_TRANSACTION_SET: 046e41f8-a223-11e4-a975-0811960cc264:4-37
LAST_ERROR_NUMBER: 0
LAST_ERROR_MESSAGE:
LAST_ERROR_TIMESTAMP: 0000-00-00 00:00:00
*************************** 2. row ***************************
CHANNEL_NAME: master2
GROUP_NAME:
SOURCE_UUID: 7475e474-a223-11e4-a978-0811960cc264
THREAD_ID: 26
SERVICE_STATE: ON
COUNT_RECEIVED_HEARTBEATS: 0
LAST_HEARTBEAT_TIMESTAMP: 0000-00-00 00:00:00
RECEIVED_TRANSACTION_SET: 7475e474-a223-11e4-a978-0811960cc264:4-6
LAST_ERROR_NUMBER: 0
LAST_ERROR_MESSAGE:
LAST_ERROR_TIMESTAMP: 0000-00-00 00:00:00
2 rows in set (0.00 sec)
以上輸出有2個channel,一個為master1,一個為master2.
通過表也可以查指定的channel_name。
新的錯誤代碼和信息已經被加入到了MySQL 5.7.6 來提供在多主復制的錯誤信息。這些錯誤代碼和信息只有在多主復制啟動的時候才會發生,並且提供那個channel錯處,比如:
Slave is already running and Slave is already stopped have been replaced with Replication thread(s) for channel channel_name are already running and Replication threads(s) for channel channel_name are already stopped respectively.
這些服務日志信息會根據channel_name不同變化。
為了安全的配置在線服務的的復制模型,理解復制的關聯原理十分重要。復制模型是否可用依賴於識別事務的技術。復制使用的事務類型:
1.GTID事務是通過GTID來識別。每個GTID事務都有gtid_log_event.GTID事務可以通過GTID或者文件名和位置識別。
2.匿名事務沒有GTID分配,MySQL 5.7.6和之後的保本保證每個匿名事務在日志裡面有一個anonymous_gtid_log_event。在之前的版本匿名事務,之前沒有特殊事務。匿名事務只能通過文件和位置確定。
當使用GTID可以使用自動決定位置,自動故障轉移,也可以使用WAIT_FOR_EXECUTED_GTID_SET()。Session_track_gtids和使用性能框架表,監控復制事務。使用GTID你不能使用sql_slave_skip_counter,可以使用空事務代替。
可以在線配置復制模式就表示可以童泰的修改gtid_mode,enforce_gtid_consistency變量。在之前的版本這2個參數不能動態被設置。Gtid_mode可以設置為on,off表示是否啟動gtid標記事務。當gtid_mode=on不能復制匿名事務,當gtid_mode=off只能復制匿名事務。在MySQL 5.7.6 gtid_mode變量多了2個不同的狀態,off_permissive, on_permissive。當為on_permissive表示當允許復制事務是GTID或者匿名,新的事務使用GTID。也就是說就可以復制拓撲的服務既可以用匿名或者GTID事務。比如gtid_mode=on,可以復制到gtid_mode=onpermissvie的slave。
Gtid_mode取值:off,off_permissive,on_permissive,on。Gtid_mode設置每次只能設置一次,並且嚴格這個順序。比如如果是off,那麼只能修改到off_permissive狀態。因為要保證匿名事務到GTID事務已經被服務正確處理。當你在on和off之前切換的時候,GTID狀態是不變的。不管個gtid_mode修改,保證GTID集合已經被服務應用。
master使用gtid_mode=on提供自動定位,配置change master to的時候使用master_auto_position=1,如果自動定位啟動了,當匿名事務發生就會出錯。強烈推薦在啟動自動定位前,保證沒有匿名事務。master和slave的可用GTID模式的組合如下:
Master/Slave gtid_mode
OFF
OFF_PERMISSIVE
ON_PERMISSIVE
ON
OFF
Y
Y
N
N
OFF_PERMISSIVE
Y
Y
Y
Y*
ON_PERMISSIVE
Y
Y
Y
Y*
ON
N
N
Y
Y*
Y:表示master,slave的gtid_mode模式兼容
N:表示master,slave的gtid_mode模式不兼容
*:表示支持自動定位。
當前選擇的gtid_mode會影響gitd_next的變量,以下表顯示服務gtid_mode,gtid_next的可用組合:
gtid_next
AUTOMATIC
binary log on
AUTOMATIC
binary log off
ANONYMOUS
UUID:NUMBER
OFF
ANONYMOUS
ANONYMOUS
ANONYMOUS
Error
OFF_PERMISSIVE
ANONYMOUS
ANONYMOUS
ANONYMOUS
UUID:NUMBER
ON_PERMISSIVE
New GTID
ANONYMOUS
ANONYMOUS
UUID:NUMBER
ON
New GTID
ANONYMOUS
Error
UUID:NUMBER
ANONYMOUS:生成匿名事務
Error:生成一個錯誤無法設置gtid_next
UUID:NUMBER:使用uuid:number生成GTID。
New GTID:使用自動生成的數值,生成GTID。
當binary log關閉,gtid_next設置為automatic,沒有gtid會被生成。
本節介紹在服務online情況下啟動GTID事務。這個過程不需要重啟服務。當然先offline在設置會簡單一點。
在啟動前有一些前置條件:
1.所有服務必須是MySQL 5.7.6或者之後的版本。單個拓撲內的服務online不能啟動GTID事務。
2.所有gtid_mode都設置為OFF。
一下過程可以被任何時間展廳並且之後繼續:
1.在每個服務上執行:
SET @@GLOBAL.ENFORCE_GTID_CONSISTENCY = WARN;
服務在一般負荷情況下運行一會兒,然後監控日志。如果步驟導致了一些告警,調整應用程序這樣只是用GTID的兼容特性並且不會生成任何警告。第一步很重要,要保證錯誤日志上沒有告警,才能進入下一步。
2.在每個服務商執行:
SET @@GLOBAL.ENFORCE_GTID_CONSISTENCY = ON;
3.在每個服務商執行:
SET @@GLOBAL.GTID_MODE = OFF_PERMISSIVE;
不管在哪個服務商先運行這個語句,要現在所有服務上運行完,才能執行下一個步驟。
4.在所有服務上運行;
SET @@GLOBAL.GTID_MODE = ON_PERMISSIVE;
同上,在所有的服務上運行完,再執行下一步。
5.等待直到變量ONGOING_ANONYMOUS_TRANSACTION_COUNT為0.
6.等待直到步驟5的事務都已經復制到了所有服務。
7.如果binary log有其他用途,比如備份,等待直到不需要老的binary log(沒有GTID的)。
如果第6步完成你可以執行flush logs然後對binary log進行備份。
8.在每個服務上執行:
SET @@GLOBAL.GTID_MODE = ON;
9.在每個服務的配置文件中加入,gtid-mode=on
現在你生成的所有事務都是帶GTID的了。有了GTID之後就可以執行自動故障轉移,執行以下語句到每個slave。如果你有多主復制,在每個slave上執行以下語句。
STOP SLAVE [FOR CHANNEL 'channel'];
CHANGE MASTER TO MASTER_AUTO_POSITION = 1 [FOR CHANNEL 'channel'];
START SLAVE [FOR CHANNEL 'channel'];
在線關閉GTID事務。
在啟動前有一些前提條件:
1.所有服務必須是MySQL 5.7.6或者之後的版本。單個拓撲內的服務online不能關閉GTID事務。
2.所有gtid_mode都設置為ON。
1.執行以下語句在每個slave上,如果是多主復制使用for channel子句
STOP SLAVE [FOR CHANNEL 'channel'];
CHANGE MASTER TO MASTER_AUTO_POSITION = 0, MASTER_LOG_FILE = file, \
MASTER_LOG_POS = position [FOR CHANNEL 'channel'];
START SLAVE [FOR CHANNEL 'channel'];
2.在每個服務上執行
SET @@GLOBAL.GTID_MODE = ON_PERMISSIVE;
SET @@GLOBAL.GTID_MODE = OFF_PERMISSIVE;
3.在服務商等待直到@@global.gtid_owned為空
4.等待所有當前存在的事務都復制到所有的slave
5.如果binary log有其他用處,等待直到不需要老的binary log。
6.在每個服務商執行
SET @@GLOBAL.GTID_MODE = OFF;
7.在配置文件上設置gtid-mode=off
本節解釋如何監控復制拓撲驗證所有匿名事務已經被復制。在修改復制模式的時候這個很有用。
有一些方法可以來等待事務到服務。
最簡單的方法,如果不關心拓撲只和延遲有關,如果你確定最多N秒延遲,只要等待N秒就可以了。
如果和拓撲有關:如果有一個master和多個slave那麼:
1.在master上執行,show master status
2.在每個slave上使用master上的文件和位置:
SELECT MASTER_POS_WAIT(file, position);
如果你沒有master和多個slave級別,或者slave的slave。在每個級別上運行上面的語句。
如果你有一個重要的復制拓撲有多個寫入客戶端,在每個master-slave上執行第二步語句。直到完成整個循環。
比如A->B->C->A:
在A上執行步驟1,在B上執行步驟2
在B上執行步驟1,在C上執行步驟2
在C上執行步驟1,在A上執行步驟2
具體看:http://dev.mysql.com/doc/refman/5.7/en/replication-options.html
最常用的管理復制的方法是保證復制已經執行並且沒有錯誤是使用SHOW SLAVE STATUS。
mysql> SHOW SLAVE STATUS\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: master1
Master_User: root
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000004
Read_Master_Log_Pos: 931
Relay_Log_File: slave1-relay-bin.000056
Relay_Log_Pos: 950
Relay_Master_Log_File: mysql-bin.000004
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 931
Relay_Log_Space: 1365
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids: 0
· Slave_IO_State:當前 slave的狀態
· Slave_IO_Running:I/O線程讀取master binary log是否在執行。通常是yes的除非沒有啟動復制或者顯示的使用stop slave停止了。
· Slave_SQL_Running:時候在執行relay log上的信息。和slave_io_running一樣一般是yes的。
· Last_IO_Error,Last_SQL_Error:在執行的時候,最後一次IO slave線程或者sql slave線程報出的錯誤。
· Seconds_Behind_Master:已經被master binary log落下的秒數,如果一直很大,說明slave無法及時的處理這些事件。這個狀態值也有可能不能真實的反應情況,當Slave SQL線程追上IO線程的時候為0,但是有一個隊列的事件,也有可能值很大。
· Master_Log_file,Read_Master_Log_Pos:表示slave IO線程已經讀取了多少日志。
· Relay_Master_Log_File,Exec_Master_Log_Pos:Master Binary Log中已經被執行了多少日志。
· Relay_Log_File,Relay_Log_Pos:Relay log 已經有多少已經被執行過了,表示relay的文件和位置,和master binary log無關。
在master,你可以通過show processlist查看在運行進程的狀態。
mysql> SHOW PROCESSLIST \G;
*************************** 4. row ***************************
Id: 10
User: root
Host: slave1:58371
db: NULL
Command: Binlog Dump
Time: 777
State: Has sent all binlog to slave; waiting for binlog to be updated
Info: NULL
因為是slave來執行復制進程的,因此master上只能看到很少的信息。
你可以使用stop slave,start slave來啟動和停止復制。
當你要停止某個線程的時候,可以使用如下命令:
mysql> STOP SLAVE IO_THREAD;
mysql> STOP SLAVE SQL_THREAD;
啟動指定線程,可以使用如下命令:
mysql> START SLAVE IO_THREAD;
mysql> START SLAVE SQL_THREAD;
slave的update只來之於對event的執行,如果你要備份,可以停止sql thread然後執行備份。IO線程會一直讀取event,但是並不執行他們。
只停止I/O thread保證relay log中的events都已經被執行。當你需要管理slave的時候保證slave已經運行到了指定的點。
復制是基於master server的binary log,記錄了所有寫入性事件,比如數據庫結構修改和數據內容修改。通常select不會被記錄到binary log中。
每個slave連接到master獲取binary log的副本。從master拉走數據,而不是master推送數據。slave執行獲取的binary log的events,和在master上執行過的一樣。
因為每個slave都是獨立的,重播master上的修改也是獨立的。另外每個slave獲取master binary log,但是slave可以更新讀取自己的數據庫。也可以停止啟動復制進程,對master不影響。
復制能工作是因為master的binary log被獲取並且在slave上執行。事件被記錄到binary log有很多種格式。不同的binary log格式,決定了復制的格式。
· 當使用基於語句的binary log,master把sql語句寫入到binary log。復制這些binary log到slave,並執行這些語句。這個叫基於語句的復制,基於語句的是標准的binary log格式。
· 當使用基於行的格式,master表內行的修改寫入到binary log。復制使用這些binary log執行修改。這個稱為基於行的復制。
· 還有一種是混合了基於語句的和基於行的日志格式,根據哪種是最適合記錄的來決定。稱為混合日志格式。相應的復制稱為混合復制。
每個binary log格式有自己的好處和壞處。對於很多用戶來說混合復制格式可能是性能和數據一致性上兼顧的最好的。
基於語句復制的好處
· 很早就已經提供這個功能
· 寫入的數據少到binary log,當更新和刪除影響很多行,log文件的空間要求也不會很高。
· 所有的語句都在binary log上,可以用來審計。
基於語句復制的壞處
· SBR的語句不安全,並不是所有的語句都可以使用基於語句的復制。當使用基於語句復制的時候,任何不確定的行為很難復制:
o 語句依賴於UDF或者存儲過程是不確定的,因為UDF或者存儲過程的返回和輸入的參數有關。
o delete和update語句使用了limit子句,但是沒有order by。
o 確定性的UDF必須應用在slave
o 使用了一下函數的語句:
· Insert…select,會生產比基於行復制多的行級鎖。
· update語句要全表掃描的,會生產大量的行級鎖。
· 對於InnoDB,insert語句使用了自增和其他非沖突insert語句。
· 對於復雜的語句,語句在被執行前必須先評估,對於基於行的復制就不需要可以直接執行語句。
· 如果復雜的語句運行超過時間閥值,那麼執行就會報錯。
· 存儲過程裡面的now(),但是在master和slave上執行結果是不一樣的。
· 表的定義在master和slave上必須唯一。
基於行復制的好處
· 所有的修改都是安全的。
· 以下語句行鎖會很少:
o Insert…select
o insert有自增字段的
o update或者delete語句有where但是沒有走索引的。
基於行復制的壞處
· RBR會生成比SBR更多的數據。
· 確定性的UDF如果生成blob會很慢
· 無法查看從master獲取的語句
· 對於使用MyISAM存儲引擎,insert的鎖會很強力。
MySQL使用SBL,RBL或者混合日志模式。binary log的模式影響日志的大小和對日志的效率。因此選擇RBR或者SBR要更具你的應用和環境決定。
ž
基於行的臨時表日志。臨時表在使用基於行的模式下是不能復制。當使用混合模式的安全的語句設計到臨時表的會被以基於語句格式記錄。臨時表是不會被復制的,因為沒有必要。另外因為臨時表只能由創建他們的線程讀取,復制他們很少能夠獲得好處,不管是不是在使用基於語句的日志格式下。
在MySQL 5.7,你可以把基於語句的方式切換到基於日志的方式。
ž RBL和非實物表同步。當很多行被響應,那麼修改會被分為多個事件,當語句提交,這些事件被寫入到binary log上。當在slave執行時,所有涉及到的表都會被鎖表,然後行會以batch方式寫入。
ž 延遲和binary log文件大小。RBL把每行的修改都寫入到binary log,因此大小會迅速上升。這樣會上升應用到slave的時間。要注意程序時候能夠忍受這些延遲。
ž 讀binary log。mysqlbinlog使用binlog語句來顯示基於行事件的binary log。語句顯示了以64編碼的字符串,當使用了--base64-output=DECODE-ROWS 和--verbose選項,mysqlbinlog會把內容格式化為已讀的。當binary log事件被以基於行格式寫入,如果出現錯誤就可以使用這個命令讀取binary log的內容。
ž
Binary log執行錯誤和slave_exec_mode。如果slave_exec_mode不是嚴格的,錯誤不會因為原來的行找不到而觸發錯誤,導致復制失敗。也就意味著可能沒有被應用到slave,所以master和slave就不是同步狀態。如果是非事務表,slave_exec_mode=IDEMPOTENT會導致master和slave未來分叉。
對於其他場景,設置slave_exec_mode=STRICT一般都可以滿足,也是除了NDB儲存引起之外的其他引擎的默認值。
ž 基於server id過濾不支持。在mysql 5.7,你可以CHANGE MASTER TO的選項設置IGNOGE_SERVER_IDs對server id進行過濾。這個選項適用於基於語句和基於行的日志格式。另外一個方法是使用where子句包含@@server_id <>id_value。不過在基於行的日志下並不能正確的工作。如果使用server_id系統變量來過濾語句,那麼要使用基於語句的日志。
ž 數據庫級別的復制選項。--replicate-do-db,--replicate-ignore-db,--replicate-rewrite-db選項根據不同的場景,是否基於行或者基於語句決定。因此,推薦避免使用數據庫級別的選項,而是用表級別的,--replicate-do-table,--replicate-ignore-table。
ž RBL,非事務表和slave停止。當使用基於行的日志,如果當slave線程在更新非事務表的時候,slave服務停止,那麼就會進入非一致性狀態,因為這個原因推薦使用事務存儲引擎,比如使用INNODB表語句行格式。
語句的安全性在mysql復制中,會影響語句應用到slave的正確性。
通常語句是安全的,因為是確定的,一些使用浮點數學函數的基本都是不安全的。
控制語句是否安全。語句對待不同是因為考慮語句是否安全,並且和binary log格式有關。
ž 當使用行日志模式,安全和非安全沒有什麼區別。
ž 當使用混合模式,如果語句被標記為不安全就會以行格式被記錄,語句如果是安全的就以基於語句格式被記錄
ž 當使用基於語句的日志,語句如果被標記為不安全的就會生成一個警告。如果是安全的就會正常記錄日志。
每個語句被標記為不安全都會生成一個日志。如果大量語句在master被生成,會導致大量的error生成在錯誤日志上。為了防止這個,MySQL 5.7提供了一個機制,如果最近的50個ER_BINLOG_UNSAFE_STATEMENT被生成在任意50秒內,告警抑制就會被啟動。當達到就不會被寫入到錯誤日志,而是每50個生成一個提醒,寫入到錯誤日志,直到50秒內生成的錯誤少於50個,之後還是一個錯誤一條記錄正常記錄。告警抑制不會影響安全語句的應用,告警如何發到客戶端。MySQL客戶端還是回收到告警。
語句被認為是不安全。語句如果有下列特性就是不安全的:
ž
語句包含以下系統函數,因為在slave會返回不同的值。FOUND_ROWS(), GET_LOCK(), IS_FREE_LOCK(),IS_USED_LOCK(), LOAD_FILE(), MASTER_POS_WAIT(),PASSWORD(), RAND(), RELEASE_LOCK(), ROW_COUNT(),SESSION_USER(), SLEEP(), SYSDATE(), SYSTEM_USER(),USER(), UUID(), and UUID_SHORT().
非確定性函數但是不認為是不安全的。盡管這些函數是不確定的,但是會被認為是安全的:CONNECTION_ID(),CURDATE(), CURRENT_DATE(), CURRENT_TIME(),CURRENT_TIMESTAMP(), CURTIME(),, LAST_INSERT_ID(),LOCALTIME(), LOCALTIMESTAMP(), NOW(), UNIX_TIMESTAMP(),UTC_DATE(), UTC_TIME(), and UTC_TIMESTAMP().
ž 引用了系統變量。很多系統變量不能被正確的復制,在基於語句格式下。
ž UDFs,因為我們無法控制UDF是做什麼的,我們會假設是不安全的。
ž 全文插件。這個插件可能在不同的MySQL服務是不一樣的,因此依賴於語句的會導致不同的結果。所有的依賴於全文插件的都會被認為是不安全的。
ž
觸發器,存儲過程更新帶AUTO_INCREMENT的列。這個是不安全的因為master上的相應行和slave上的不一樣。
另外,INSERT into表是組合主鍵,如果主鍵包含AUTO_INCREMENT並且不是第一個主鍵的列,那麼也是不安全的。
ž INSERT…ON DUPLICATE KEY UPDATE語句在表中有多個primary或者唯一鍵。當執行的表包含多余一個primary key或者唯一鍵。這個語句被認為是不安全的,因為存儲引擎檢查key,是不確定的。所以是不安全的。
ž 使用limit更新。因為獲取的行是無法確定的,所以是不安全的。
ž 訪問和應用日志表。系統日志表在slave和master是不同的所以不安全。
ž 在事務之後執行非事務操作。在事務內,任何事務的讀寫之後運行,非事務的讀寫都認為是不安全的。
ž LOAD DATE INFILE語句,LOAD DATE INFILE被認為不安全。
MySQL復制能力的實現有3個線程,一個在master上,2個在slave上:
ž
Binlog dump線程。當slave連接,master會創建一個線程用來發送binary log的內容。這個可以使用show
processlist發現。
binary log dump線程獲取master binary log的讀鎖,當事件讀完,鎖就釋放,甚至在發送到slave之前。
ž
Slave I/O 線程。當執行start slave語句,slave創建I/O先,用來連接到master,並且要求發送binary log中的記錄。
slave I/O先讀取binary log dump的記錄復制到本地relay
log中
可以通過show slave status 查看slave_io_running的狀態。
ž Slave SQL thread,slave黃建一個線程來讀取relay log的內容並且執行它們。
按上面,master和slave中有3個線程。如果有多個slave,那麼master會為每個slave連接創建一個binary log dump線程,每個slave都有自己的I/O,SQL線程。
slave使用2個線程來分離讀取master上的更新和執行這些更新,因此,讀取語句不會因為語句執行的慢,而被拉後。如果slave在SQL thread執行完所有的語句前停止了。因為有一份安全的副本在relay log,因此下次slave啟動的時候會正常執行。
show processlist語句提供了一些關於復制的信息:
ž 在master上show processlist輸出
mysql> SHOW PROCESSLIST\G
*************************** 1. row ***************************
Id: 2
User: root
Host: localhost:32931
db: NULL
Command: Binlog Dump
Time: 94
State: Has sent all binlog to slave; waiting for binlog to
be updated
Info: NULL
thread 2就是binlog dump,state信息表示等待更多的更新發生。如果沒有發現這個線程,表示服務沒有啟動,沒有slave連接到master上。
ž 在slave上,show processlist輸出:
mysql> SHOW PROCESSLIST\G
*************************** 1. row ***************************
Id: 10
User: system user
Host:
db: NULL
Command: Connect
Time: 11
State: Waiting for master to send event
Info: NULL
*************************** 2. row ***************************
Id: 11
User: system user
Host:
db: NULL
Command: Connect
Time: 11
State: Has read all relay log; waiting for the slave I/O
thread to update it
Info: NULL
線程10 的狀態信息表示I/O線程已經連接到了master,線程11表是已經執行了relay log中的日志。這個時候所有的線程都是理想狀態等待後續的更新。
MySQL 5.7.6出了一個復制渠道的概念,表示從master 到slave的路徑。為了兼容以前的版本在MySQL服務啟動後自動創建默認的渠道,渠道名為“”。
復制渠道表示事務從master到slave的提交。多主復制的slave會打開多個渠道,每個master一個,每個渠道都有自己的relay log和SQL 線程。一旦事務在渠道接收器 IO thread接收,就被增加到這個渠道的relay log文件並且傳遞到應用線程。
復制渠道也有自己的host和端口, 你可以配置多個渠道使用相同的host和端口,在MySQL 5.7,一個slave最多可以有256個多主復制拓撲。沒有復制渠道要有唯一的名稱。
以下命令有 FOR CHANNEL 選項:
· CHANGE MASTER TO
· START SLAVE
· STOP SLAVE
· SHOW RELAYLOG EVENTS
· FLUSH RELAY LOGS
· SHOW SLAVE STATUS
· RESET SLAVE
以下函數可以參入channel_name參數:
· MASTER_POS_WAIT()
· WAIT_UNTIL_SQL_THREAD_AFTER_GTIDS()
如果沒有指定FOR CHANNEL那麼會應用到所有的channel:start slave,stop slave,show slave status,flush relay logs,reset slave。
有些語句不能在所有的channel上執行,需要指定 FOR CHANNEL:
· SHOW RELAYLOG EVENTS
· CHANGE MASTER TO
· MASTER_POS_WAIT()
· WAIT_UNTIL_SQL_THREAD_AFTER_GTIDS()
· WAIT_FOR_EXECUTED_GTID_SET()
具體看:http://dev.mysql.com/doc/refman/5.7/en/channels-startup-options.html
具體看:
http://dev.mysql.com/doc/refman/5.7/en/channels-naming-conventions.html
在復制的時候,slave服務創建一些日志用來保存從master傳過來的binary log。記錄信息和當前狀態記錄在relay log。這裡有3種類型的日志處理:
1.Relay log由從master讀過來的binary log組成。
2.master info log包含當前用來連接到master的配置信息。這個日志包含master host,登錄憑證和相關的讀取了多少master binary log。一般寫在mysql.slave_master_info表,可以通過參數—master-info-repository=table來設置。
3.relay log信息保存了執行點的狀態信息。通過—replay-log-info-repository=table來設置保存到mysql.slave_relay_log_info表裡面。
Crash-safe replication。為了讓復制能夠crash safe使用表來記錄狀態和日志信息,這些表必須是innodb表。因此為了保證crash safe 要把--relay-log-recovery和參數--relay-log-info-repository=table。
在MySQL 5.7,mysqld不能夠啟用初始化日志日志表 ,但是slave依然可以啟動。
在MySQL 5.7,在復制執行中,slave_master_info或者slave_relay_log_info,執行任何語句獲取寫鎖,都是不被運行的。只有讀可以允許被執行。
Relay log和binary log相似,有一系列編號的文件包含了事件,這些事件用來描述數據庫的修改。
Relay log和binary log格式一樣,可以使用mysqlbinlog讀取。默認relay log的文件名為 host_name-relay-bin.nnnnnn host_name是slave的hostname。默認relay log文件和relay log所有文件可以自己定義。使用參數—relay-log,--relay-log-index
如果slave使用默認hostname的命名方式,修改slave host name會導致復制報錯,Failed to open the relay log and Could not find target log during relay log initialization. 可以通過指定—relay-log,--relay-log-index來避免這個問題。
如果已經發生了這個問題,有個方法可以修復,仙停止slave服務,把老的relay log index文件寫入到新的,然後重啟服務。
在以下情況下,slave服務會創建一個新的relay log文件:
1.每次IO線程啟動
2.當log被flush
3.當前relay log變的太大:
如果max_relay_log_size大於0,那麼就是超過這個值。
如果max_relay_log_size = 0,max_binlog_size決定了relay log的最大大小。
SQL Thread不在需要的relay文件會被自動刪除。
復制slave服務創建2個日志,默認日志文件命名為master.info和relay-log.info,可以通過—master-info-file,--relay-info-file修改文件名。而且這個2個文件也可以寫在表裡面通過設置—master-info-repository,寫入到mysql.slave_master_info表中。設置—relay-log-info-repository把relay info log 寫入到mysql.slave_relay_log_info。
Status log包含的信息也顯示在show slave status上。因為狀態文件是以文件保存的,他們會在slave服務關閉之後保存下來。等到下次啟動的時候,讀取這2個文件決定已經從master讀取了多少binary log,並且已經執行了多少relay logs。
Master info log或者表要被保護起來,因為裡面包含了連接到master的賬號密碼。
當備份slave數據的時候也要備份2個狀態日志和relay日志文件。當恢復slave數據的時候這些數據也要被恢復。如果都是了relay log但是任然有relay log info日志,你可以檢查來決定sql thread已經執行了多少master binary log。然後可以使用change master to來決定沖那裡讀取master的文件。當然這個master binary log文件要依然在master中。
如果master服務沒有寫入入局到binary log,語句不會被復制。如果服務記錄了語句,語句會被發送的slave,slave決定是否運行語句。
在master上,你可以控制那些數據庫記錄binary,--binlog-do-db,--binlog-ignore-db選項用來控制寫入binary log的數據庫。
在slave側,通過控制--replication-*選項控制那些語句在slave上執行。在MySQL 5.7.3之後這些過來可以動態的設置,使用語句CHANGE REPLICATION FILTER語句。
數據庫級別的選項--replication-do-db,--replication-ignore-db會被先檢查。語句對於數據庫的影響要在--replication-wild-do-table前面。也就是說--replication-wild-do-table選項,只有在沒有數據庫級別的選項應用之後才會被檢查。
避免do,-ignore選項混用,避免wildcard,nowildcard混用。
當評估復制選項,slave開始檢查查看是否有任何--replication-do-db,--replication-ignore-db選項,當使用--binlog-do-db,--binlog-ignore-db和上面相似,但是處理確實在master上。
使用基於語句的復制,默認數據庫檢查是否匹配,使用基於行的復制,數據修改數據庫會被檢查,不管binary log格式,以下圖檢查圖片:
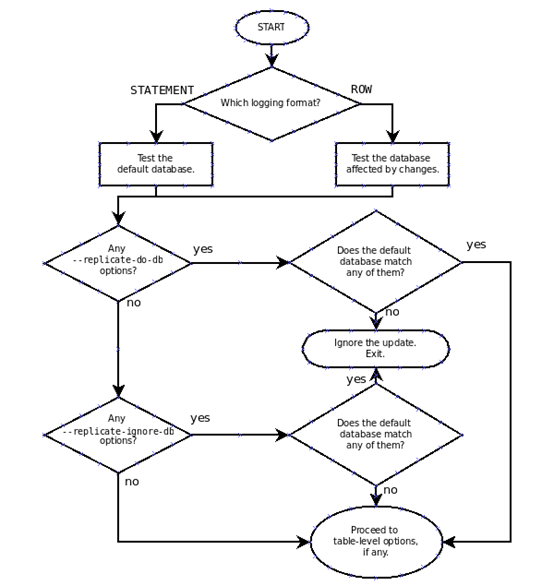
對於binary log步驟設計列表如下:
1.是否設置了--binlog-do-db會在—binlog-ignore-db選項
是,第二步
不是,記錄語句退出
2.是否有默認數據庫
是,第三步
否,ignore語句退出
3.是否在—binlog-do-db中
是,是否都匹配數據庫
是,記錄日志,並且推出
否,忽略語句並推出
否,繼續第4步
4.是否有數據庫匹配--binlog-ignore-db
是,忽略並且推出
否,記錄語句推出。
--binlog-do-db有時候也可以認為忽略其他數據庫。比如,使用了基於語句的日志,服務只有--binlog-do-db=sales就不會寫入默認數據庫不是sales的日志。當使用基於行的日志,使用了向東選項,只會記錄只在sales發生修改的日志。
只有在以下一個條件為真的情況下才會評估表選項:
1.沒有匹配數據庫被找到
2.匹配數據庫級別的過濾
首先,最為初步條件,slave檢查是否啟動了基於語句的復制。如果啟動了,並且語句發生在存儲函數中,則執行語句退出。如果是基於行的復制,slave不知道語句是否發生在存儲函數中,所以不應用。
到了這裡,如果沒有表的復制選項,那麼slave會直接執行,如果有—replicate-do-table或者—replicate-wild-do-table選項,那麼時間必須匹配這些選項的其中一個。否則會被忽略。如果沒有—replicate-ignore-table或者—replicate -wild-ignore-table選項,所有的事件不匹配的都會被執行。執行流程:
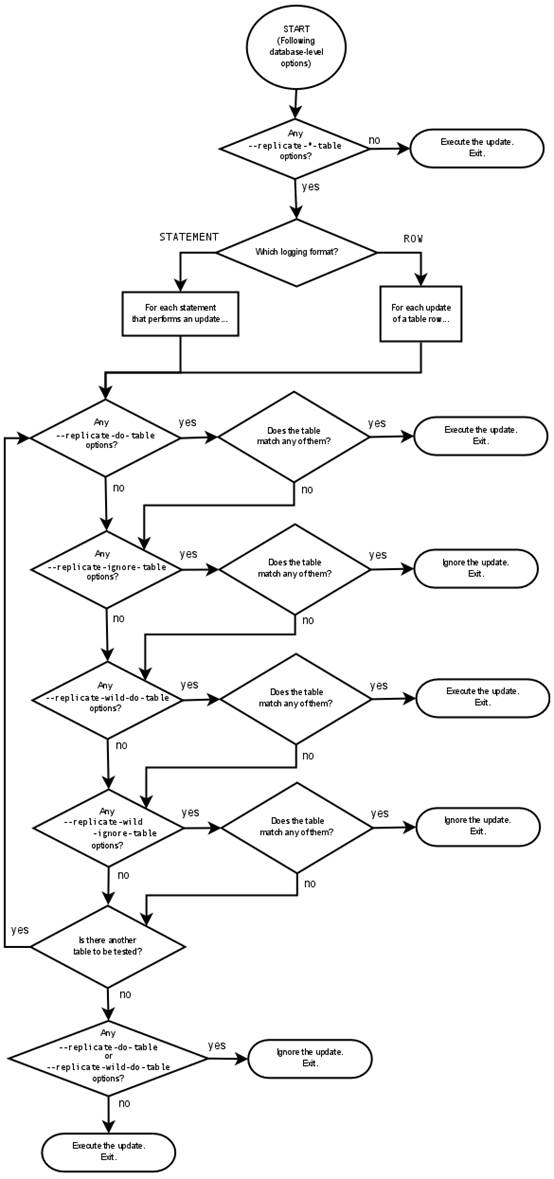
Condition (Types of Options)
Outcome
沒有 --replicate-*選項:
所有的事件都會被執行
--replicate-*-db選項,沒有其他選項
Slave接受或者忽略使用了數據庫的選項,沒有表限制,符合數據庫的都會被執行.
--replicate-*-table 選項沒有其他選項:
因為沒有數據庫選項,所有符合表的選項都會被執行
數據庫選項和表選項都有
Slave接受或者忽略使用數據庫的選項,然後評估這些事件的表選項可能會有因為行模式或者語句模式有些不同
假設我們有2個表db1. mytb1,db2.mytb2。選項設置如下:
replicate-ignore-db = db1
replicate-do-table = db2.tbl2
然後執行以下語句:
USE db1;
INSERT INTO db2.tbl2 VALUES (1);
這種情況下就和binary log有關了:
基於語句復制:使用use導致db1變成默認數據庫,這樣—replicate-ignore-db選項匹配就會被忽略。
基於行復制:默認數據庫不會影響slave讀取數據庫選項。因此use語句的數據庫和—replicate-ignore-db一樣,但是insert的數據庫和選項不批匹配,然後檢查表選項,和—replicate-do-table匹配,行被插入。
如果復制是作為備份的一個解決方案,復制master的數據到slave,備份slave數據。Slave可以暫停,關閉不會影響master的運行。
如何備份數據庫和用途有關,比如只是備份數據,或者備份數據用來創建新的slave:
1.如果為了備份數據,並且數據庫大小不是很大,那麼可以使用mysqldump工具進行備份。
2.對於大數據庫,mysqldump效率很低,可以直接復制原生的數據文件。
使用mysqldunmp備份數據庫,因為備份結果是sql語句,可以很簡單的發布或者應用到其他服務,緊急使用。
1.停止slave
2.使用mysqldump導出所有數據庫
3.啟動slave
為了保證文件的一致性,備份文件只能在服務關閉的情況下進行。如果mysql服務還是運行的,後台任務依然會去修改數據庫文件,如果是innodb表那麼這些問題在crash恢復的時候會被修正。
1.關閉mysql服務
2.使用cp,tar等命令復制數據文件。
3.啟動服務
如果你想要恢復一個slave,通常要備份整個數據目錄。Slave數據,slave狀態文件,master info文件relay log info,relay log文件。這些文件在恢復復制的時候會使用到。
如果你丟失了relay日志但是依然有relay-log.info文件,你可以檢查slave已經運行到了什麼地方然後使用change master to來告訴slave需要重新讀取的binary log。
如果slave。
通過在master或者slave上,設置全局讀鎖修改到只讀模式:
1.服務設置為只讀,堵塞寫入
2.執行備份
3.修改服務為讀寫模式
以下是具體如何操作:
ž Master服務,M1
ž Slave服務,S1,M1作為master
ž C1連接到M1
ž C2連接到S1
場景1:在master上使用只讀備份
把master設置到只讀狀態:
mysql> FLUSH TABLES WITH READ LOCK;
mysql> SET GLOBAL read_only = ON;
當M1只讀狀態,一下屬性為真:
1.因為是只讀模式,所有更新都會堵塞。
2.但是可以查詢數據
3.備份M1是安全的
4.在s1上備份不安全,因為服務依然是運行的,可能在執行binary log或者執行來著C2的更新。
當備份完成有,執行以下語句:
mysql> SET GLOBAL read_only = OFF;
mysql> UNLOCK TABLES;
場景2:備份只讀Slave
執行以下腳本:
mysql> FLUSH TABLES WITH READ LOCK;
mysql> SET GLOBAL read_only = ON;
這個是比較流行的備份方式:有一個slave執行備份不會有什麼問題,因為不會影響網絡,並且系統任然能夠正常運行。
備份完成後執行:
mysql> SET GLOBAL read_only = OFF;
mysql> UNLOCK TABLES;
Master和slave存儲引擎不一樣是沒有問題的。實際上,default_storage_engine和storage_engine是不會被復制的。
使用不同的存儲引擎在不同場景有不同的好處。
使用不同的存儲引擎還決定於,復制初始化的過程:
1.如果你使用嗎,mysqldump創建數據庫快照,那麼可以使用文本編輯替換存儲引擎
2.如果使用原文件備份,就不能在初始化階段修改,要在slave配置好有alter table修改。
3.如果復制已經創建,並且master沒有表,那麼在創建表的時候不要指定存儲引擎。
如果已經有復制了,但是想要修改表的存儲引擎:
1.關閉slave
2.使用alter table修改存儲引擎
3.啟動slave。
雖然參數default_storage_engine不會被復制,但是create table和alter table的語句包含了存儲引擎還是會被復制的。
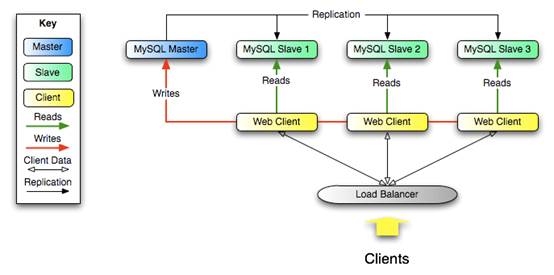
你可以把復制作為擴展解決方案,比如想要分離負荷到其他服務器。因為復制可以分布一個或者多個slave。這個最好使用在讀多寫少的情況下。
這樣的情況下讀取負荷可以分散到復制slave。當有寫入服務的時候還是寫入到master。如圖:
有一個master但是想把不同的數據庫復制到不同的slave,如圖:
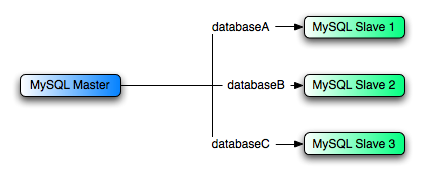
那麼可以在每個slave上使用—replication-wild-do-table來處理。比如:
1. slave1,--replicate-wild-do-table=databaseA.%
2. slave2,--replicate-wild-do-table=databaseB.%
3. slave3,--replicate-wild-do-table=databaseC.%
每個slave都會收到整個master的binary log,但是只執行在--replicate-wild-do-table內的。
如果在復制開始前有數據要挺不到slave,那麼有幾個選擇:
1.同步所有的數據到每個slave,然後刪除不要的表或者數據庫。
2.使用mysqldump為每個數據庫創建slave。
3.使用原生文件和特定的文件和數據庫。
Slave連接到master的線程盡管開銷很小,但是也會有影響。每個slave必須接受所有的binary log,網絡帶寬也會影響。
如果有大量的slave,master還需要處理用戶請求,這個時候你就想要提升復制的性能。
有個方法提高性能是創建一個配對復制結構讓master只復制到一個slave。然後其他的slave都連接到這個slave上。如圖:
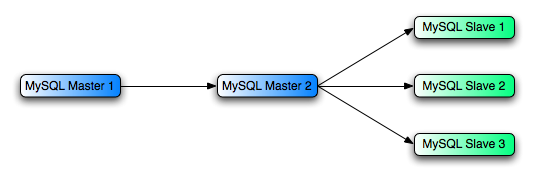
為了讓上圖工作,必須如下配置:
1.master1,是主master所有的修改都會寫入到這裡。這台要啟動binary log
2.master2,是master1的slave,master2也要啟動binary log並且—log-slave-update,這樣master1的寫入才會被記錄到master2的binary log。
3.slave1,slave2,slave3連接到master2,復制master2上的信息。
以上解決方案,減少了用戶負荷和網絡接口的負荷,可以主master的總體性能。
如果slave更上master有困難,那麼有以下幾個措施:
1.如果可以,把relay log和數據文件分開到不同的磁盤,通過配置—relay-log選項。
2.如果slave比master慢很多,你可能想要把不同的數據庫分到不同的slave。
3.如果你master使用了事務,如果你不在乎事務,那麼可以在slave上使用myisam表。
4.如果slave不作為master,並且保證在事件錯誤的時候可以跟上master,然後關掉log-slave-updates.防止了slave爆炸,也可以把他們執行的記錄到binary log。
當使用GTID的復制,你可以在錯誤的時候使用mysqlfailover在master和slave之間進行切換。如果沒有使用GTID那麼就無法使用mysqlfailover,你不許配置一個master和多個slave。然後你需要些一個腳本或者程序來監控master檢查是否正常,並且指示slave和應用程序切換到另外一個master。
你可以通過change master通知一個slave修改master。slave不會檢查master的數據庫是否和slave兼容。指示簡單的開始讀取並且執行指定master的binary log。在故障轉移時,所有的組內的服務執行相同的事件來自相同的binary log文件,所以修改事件的來源不會影響數據庫結構和數據的一致性。保證修改的安全性。
slave也要開始--log-bin選項,如果沒有使用GTID那麼要開啟--log-slave-update這樣,slave變成master不需要重啟slave的mysqld服務。假設目前你的數據庫結構如下:
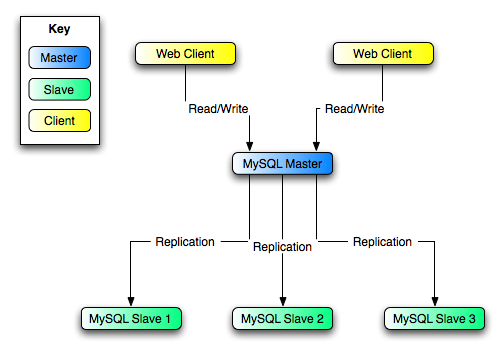
MySQL Master保存了master數據庫,MySQL Slave是復制的slave。並且web client發生數據庫讀寫。Web Client的讀取會直接走slave不再這裡顯示,不需要再錯誤發生後切換。
每個slave都啟動了--log-bin,--log-slave-updates.因為從master收到的修改不會被寫入到binary log除非開了--log-slave-updates。這樣的話當MySQL Master不可用,叫你可以選一個slave變成master。比如slave 1,那麼所有的Web Client會重新定向到Slave 1,寫入都會被寫入binary log。Slave 2,Slave3從Slave 1上復制。
不開--log-slave-updates的理由是防止slave變成master之後防止slave會受到2次更新。如果Slave 1有--log-slave-updates開啟,那麼會把master上的修改也寫入到binary log,那麼slave 1變成master之後,slave 2會接收到master之前的修改。
保證所有的slave已經讀取了所有的relay log,執行stop slave io_thread,然後show preocesslist,然後會看到has read all realy log。當所有的slave都是這樣,就可以重新配置到新的。在slave 1上執行stop slave並且reset master。
在slave2,slave3,運行stop slave然後change master to=“salve 1”修改master。執行change master修改到slave1。change master to語句不需要指定slave 1的binary log文件名字或者log位置,因為第一個binary log位置是4.然後,在slave2,slave3啟動slave。
一旦新的復制被創建,你就需要通知每個web client連接到slave 1。所有的更新語句都發送到slave1。
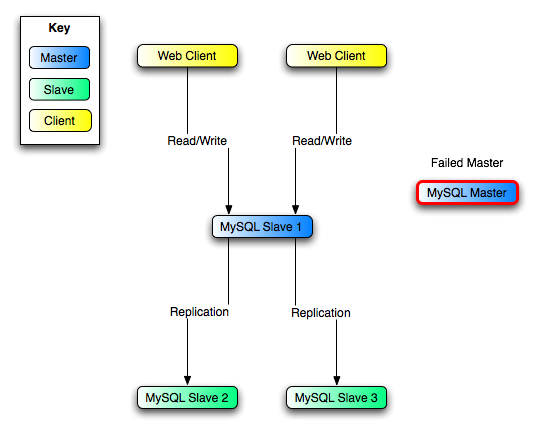
當master 變得可用,就在master上執行change master to語句。master 變成slave1的slave。
如果slave1不可用,為了master變成master,使用前面的過程讓master變成新的master。在設置master變成master之前,不要忘記執行reset master。
要注意的是slave並不是同步的,也就是說有些slave比較靠前,有些延遲比較多。可能沒有辦法像之前的預想一樣。在實際操作中,盡量讓slaves的relay log比較接近。有個方法可以讓應用程序定位到master,就是master有個動態DNS。使用bind可以使用nsupdate來動態更新dns。
使用安全連接加密binary log的傳輸,master和slave必須都支持加密連接,如果任一一個不支持就不能使用加密連接。
配置安全連接和客戶端/服務端連接差不多。你必須使用合適的安全證書來創建連接。
為了在master啟用安全連接,必須創建或者獲取證書和key文件,並且增加以下配置選項:
[mysqld]
ssl-ca=cacert.pem
ssl-cert=server-cert.pem
ssl-key=server-key.pem
文件的路徑可以是相對的也可以是絕對的。推薦使用絕對路徑。
1.ssl-ca 表明CA證書
2.ssl-cert 表示公鑰證書
3.ssl-key 表示私鑰
在slave,有2個方法設置要的信息。你可以在配置文件的[client]中配置,或者在change master中配置:
1.在配置文件[client]中配置:
[client]
ssl-ca=cacert.pem
ssl-cert=client-cert.pem
ssl-key=client-key.pem
重啟slave,使用--skip-slave-start防止連接到master,使用change master to修改設置使用ssl:
mysql> CHANGE MASTER TO
-> MASTER_HOST='master_hostname',
-> MASTER_USER='replicate',
-> MASTER_PASSWORD='password',
-> MASTER_SSL=1;
2.直接在change master to上設置:
mysql> CHANGE MASTER TO
-> MASTER_HOST='master_hostname',
-> MASTER_USER='replicate',
-> MASTER_PASSWORD='password',
-> MASTER_SSL=1,
-> MASTER_SSL_CA = 'ca_file_name',
-> MASTER_SSL_CAPATH = 'ca_directory_name',
-> MASTER_SSL_CERT = 'cert_file_name',
-> MASTER_SSL_KEY = 'key_file_name';
設置好後start slave啟動。
你可以使用show slave status查看安全連接是否成功。
如果你想要強制使用安全連接,創建一個用戶設置REQUIRE SSL選項,並設置復制權限。
mysql> CREATE USER 'repl'@'%.mydomain.com' IDENTIFIED BY 'slavepass'
-> REQUIRE SSL;
mysql> GRANT REPLICATION SLAVE ON *.*
-> TO 'repl'@'%.mydomain.com';
如果賬號已經存在,你可以直接加REQUIRE SSL
mysql> ALTER USER 'repl'@'%.mydomain.com' REQUIRE SSL;
處理異步復制之外,MySQL 5.7支持半同步復制。復制默認是異步的。master寫事件到binary log不管slave是否獲取處理他們。使用異步復制,如果master崩潰,已經提交的事務可能無法傳輸到其他slave。
半同步復制是復制的一個替代:
1.slave表示是否可以半同步連接到master
2.如果半同步復制在master上啟動,至少有一個半同步slave,一個在master執行提交的事務堵塞並且等待直到一個半同步slave通知已經收到了事務的所有事件,或者發生超時。
3.Slave在relay log被寫入到磁盤後通知
4.如果超時發生,master被還原為異步復制。當至少一個slave跟上事務後,master恢復半同步復制。
5.半同步復制必須在master和slave都啟動。如果半同步復制在任意一端被禁用master使用異步復制。
當master被堵塞,執行的事務沒有返回。當堵塞結束,master返回到會話,就可以執行其他語句。這個時候會話提交的事務至少已經傳到了一個slave。
MySQL 5.7.3之後,通知的事務個數可以通過參數repl_semi_sync_master_wait_for_ slave_count設置默認為1.
當事務已經寫入binary log,但是回滾了,也會堵塞。當事務修改了非事務表被回滾的情況。回滾的事務也會被記錄,因為非事務表不能回滾,只能發送到slave。
對於語句不是在事務內的,如果啟動的自動提交,那麼每個語句會隱式提交。當半同步復制會堵塞所有的語句,就好像了調用了顯示事務一樣。
半同步復制被稱為半同步的原因:
1.對於異步復制無法保證每個事務發送到了任意一個slave。
2.對於同步復制,當master提交事務所有的slave必須受到之後master才能返回。
3.半同步復制在異步復制和同步復制之前,只要有一個slave收到了事務就可以返回。
比較異步復制,半同步復制提供更好的數據一致性。對於同步復制一旦有個slave太慢那麼就會拖累整個復制。
半同步復制有一些性能印象,因為提交比較慢因為要等slave返回。
Repl_semi_sync_master_wait_point系統變量控制master在什麼時候等待 slave通知才能返回會話:
AFTER_SYNC:默認,master把每個事務寫入到binary log和slave,並且同步binary log 到磁盤。Master等待slave通知。接受到通知後,master提交事務到存儲引擎並且返回到客戶端。
AFTER_COMMIT:master把事務寫入到binary log 和slave,同步binary log,提交事務到存儲引擎,master等待slave通知事務已經被slave接受。接收到通知,master返回到client然後繼續處理。
不同設置,不同特性:
1.使用AFTER_SYNC,所有客戶端可以同時看到提交的事務,接收到通知後提交到存儲引擎。所以所有的client在master都看到相同的數據。
2.使用AFTER_COMMIT,客戶端獲取事務提交到存儲引擎,並且獲取slave通知後才返回。在提交後,但是通知前,其他客戶端可以比提交事務先看到數據。
如果因為一些錯誤slave沒有處理事務,master crash,切到slave,有可能會出現一部分數據丟失。
半同步復制的管理接口有一些組件:
ž 2個插件實現半同步復制的能力。一個是master側一個是slave側、
ž 有一些系統變量可以控制插件的行為:
o
Rpl_semi_sync_master_enabled
控制半同步復制是否在master上啟動。為了啟動或者禁用插件,默認為0.
o
Rpl_semi_sync_master_timeout
毫秒控制master等待slave通知的超時時間。
o
Rpl_semi_sync_slave_enabled
控制slave半同步復制是否啟動。
ž 用來監控復制的狀態變量:
o
Rpl_semi_sync_master_clients
半同步的slave個數
o
Rpl_semi_sync_master_status
如果是1表示插件已經啟動並且提交通知還沒有發生,如果是0表示插件沒有啟動,或者已經退回為異步復制。
o
Rpl_semi_sync_master_no_tx
沒有被成功通知的事務
o
Rpl_semi_sync_slave_status
如果為1表示slave IO 線程已經運行,0表示沒有運行。
變量和狀態只有在安裝了插件之後才可用。
半同步復制使用插件實現,所以插件必須被撞到服務上並且啟用。啟動後可以通過系統變量來控制。系統變量在插件安裝好後啟用。
要使用半同步復制,要滿足以下幾點:
1.必須MySQL 5.5以上的版本。
2.MySQL服務要支持動態加載插件。
3.復制已經開始工作。
4.不能是多源復制。
使用下列命令來安裝半同步復制。INSTALL PLUGIN,SET GLOBAL,STOP SLAVE,START SLAVE.
MySQL發布的時候已經包含半同步復制插件。
安裝組件目錄裡面的插件:
mysql> INSTALL PLUGIN rpl_semi_sync_master SONAME 'semisync_master.so';
不同的系統要選擇不同的綴名。如果不確定插件名字,可以到插件目錄上查看。
如果在類linux系統上報錯如下,那麼就要安裝libimf
mysql> INSTALL PLUGIN rpl_semi_sync_master SONAME 'semisync_master.so';
ERROR 1126 (HY000): Can't open shared library
'/usr/local/mysql/lib/plugin/semisync_master.so' (errno: 22 libimf.so: cannot open
shared object file: No such file or directory)
可以通過show plugin查看已經安裝的插件。
半同步復制安裝好後,默認是不啟用的。插件必須在master和slave同時啟動。如果只有一邊啟動那麼是異步復制。
通過設置變量來控制插件啟動:
在master上:
mysql> SET GLOBAL rpl_semi_sync_master_enabled = {0|1};
mysql> SET GLOBAL rpl_semi_sync_master_timeout = N;
在slave上:
mysql> SET GLOBAL rpl_semi_sync_slave_enabled = {0|1};
如果slave在運行時,啟動半同步復制,然後重啟slave I/O線程。
服務啟動,要把半同步復制的參數寫入到命令行或者配置文件中。
Master:
[mysqld]
rpl_semi_sync_master_enabled=1
rpl_semi_sync_master_timeout=1000 # 1 second
Slave:
[mysqld]
rpl_semi_sync_slave_enabled=1
半同步復制會釋放出一些系統變量和狀態變量可以通過來決定配置和操作狀態。
比如使用show variables查看變量:
mysql> SHOW VARIABLES LIKE 'rpl_semi_sync%';
使用show status查看狀態:
mysql> SHOW STATUS LIKE 'Rpl_semi_sync%';
當master在異步和同步之間切換回根據提交堵塞超時時間或者slave catching up來決定,通過rpl_semi_sync_master_status查看當前同步方式是同步還是異步。
通過rpl_semi_sync_master_clients查看連接的半同步復制slave個數。
提交的事務的成功通知未成功通知可以查看rpl_semi_sync_master_ves_tx和rpl_semi_sync_master_ves_no_tx。
在slave端使用rpl_semi_sync_slave_status。
MySQL 5.7支持延遲復制,slave比master延遲指定的時間。默認延遲為0可以通過change master設置延遲N秒。
CHANGE MASTER TO MASTER_DELAY = N;
一個事務收到後不會被運行,直到比master延遲N秒之後。不會影響事件或者日志文件的回繞,值會影響SQL thread線程。
延遲事務有幾個用處:
1.保護用戶誤操作。
2.測試當有測試的時候系統如何處理。
3.用來檢查以前數據庫。
Start slave,stop slave會馬上執行忽略任何延遲。Reset slave 重置延遲。
Show slave status有3個信息和延遲相關:
1.SQL_Delay:非負整數,表示要延遲的N秒
2.SQL_Remaining_Delay:當SQL_Running_state等待直到master執行完N秒之後。表示還剩下多少秒的延遲。
3.Slave_SQL_Running_State:字符串表示SQL thread的狀態。
如果SQL thread等待延遲,show processlist會顯示 Waiting until MASTER_DELAY seconds after master executed event.
具體看:http://dev.mysql.com/doc/refman/5.7/en/replication-notes.html