Mysql索引及優化使用總結:
在關系數據庫中,索引的使用十分重要,而且所有的關系數據庫支持索引機制,因為有了索引之後,在大數據量檢索數據時速度很快,性能消耗很低;當然,凡事有利必有弊,增加索引也會增加數據庫系統的開銷,我們很多時候需要在性能和檢索間折中設計,而且正確使用索引及對他維護和優化是很重要的!
· 索引的類型?
· 索引的原理?
· 何時建索引?
· 索引的使用?
· 索引的優化?
一、索引的類型
在Mysql中,索引可分為普通索引、唯一索引、主鍵索引、外鍵索引及組合索引,它們在創建索引位置上都是一樣的,即在表的一個或多個字段上創建使用,具體介紹下:
1、普通索引
普通索引的唯一任務就是加快數據的檢索速度,應該在經常出現在WHERE或ORDER BY後的單一列上使用,而且該索引列可以重復,由關鍵字KEY或INDEX定義的索引。
2、唯一索引
唯一索引的主要任務除了加快數據的檢索速度之外,還有就是約束創建或使用唯一索引的單一列必須是不重復的,也就是保證了數據的唯一性,所以,它的主要作用體現在檢索速度和數據唯一方面,由關鍵字UNIQUE定義的索引。
3、主鍵索引
主鍵索引是MYSQL為數據表主鍵字段默認生成的索引,它與唯一索引的唯一不同就是它們的定義語句,這裡使用的是PRIMARY而不是UNIQUE。
4、外鍵索引
如果為某個外鍵字段定義一個外鍵,MYSQL就會為其生成一個索引,來幫助加快對外鍵約束的使用,由關鍵字KEY定義,外鍵數據可重復。
5、組合索引
組合索引與普通索引的區別是在多個列上定義,與唯一索引相同的是組合索引必須保證唯一,而且MYSQL可以選擇不同的索引字段的合適組合來組合查詢索引(適用於排列在前的數據列組合)。
6、全文索引
文本字段上的普通索引只能加快對出現在字段內容最前面的字符串(也就是字段內容開頭的字符)進行檢索操作。如果字段裡存放的是由幾個、甚至是多個單詞構成的較大段文字,普通索引就沒什麼作用了。這種檢索往往以LIKE %word%的形式出現,這對MySQL來說很復雜,如果需要處理的數據量很大,響應時間就會很長。
這類場合正是全文索引(full-text index)可以大顯身手的地方。在生成這種類型的索引時,MySQL將把在文本中出現的所有單詞創建為一份清單,查詢操作將根據這份清單去檢索有關的數據記錄。全文索引即可以隨數據表一同創建,也可以等日後有必要時再使用下面這條命令添加:
ALTER TABLE tablename ADD FULLTEXT(column1, column2)
有了全文索引,就可以用SELECT查詢命令去檢索那些包含著一個或多個給定單詞的數據記錄了。下面是這類查詢命令的基本語法:
SELECT * FROM tablename
WHERE MATCH(column1, column2) AGAINST(‘word1′, ‘word2′, ‘word3′)
上面這條命令將把column1和column2字段裡有word1、word2和word3的數據記錄全部查詢出來。
注:
有博文說全文索引在數據庫引擎InnoDB中不支持,其實不然,在MYSQL版本5.6已經引入了全文索引
二、索引的原理
索引的工作原理比較清楚明了,在創建或使用索引時,默認按照某種規則為索引字段排好順序,在用戶檢索數據時,系統首先檢索排序的索引內容,如果找到匹配的內容即刻返回,不進行全文檢索,這樣也就是大大提高了檢索的速度了,在下面索引的分析中會演示索引的工作原理,請繼續閱讀。
三、何時建索引
1、准備工作
鑒於創建索引需要額外的磁盤空間,需要後期維護清理索引碎片,以及增加表的CUD操作的性能,所以創建索引需要謹慎考慮哦。
2、何時創建
既然索引的誕生就是為了解決數據的檢索效率,那麼很明顯需要在經常查詢的表的某些字段上創建並維護索引,鑒於准備工作部分考慮的因素,對於那些經常查詢也同時經常CUD的表字段上如果必須添加索引,那麼推薦使用合適的算法使用索引,比如:二分檢索(這裡不做介紹)。
四、索引的使用
語法結構:
CREATE [NORMAL|UNIQUE|FULLTEXT] INDEX index_name
ON table_name (col_name[(length)[ASC | DESC]],[…])
NOTE:
index_name:索引名字;
table_name:建立索引的數據表;
col_name:建立索引的表字段,length為內容字符的前多少位加入索引算法;
1、普通索引
首先,我准備一張數據表t_user_info,該表中我添加了500萬條數據,下面我們來測分析下,在使用索引和未使用索引的差別,同樣條件的檢索:
SELECT account,nickname,email,address FROM t_user_infoWHERE account="cwteam4000000";
未使用索引:使用EXPLAIN分析SQL,分析的結果:

從上圖,我們看的出來,本次檢索復雜界別為select_type,即簡單查詢;檢索類型為type全表檢索;並未使用索引key(NULL);查詢條件Extra為where;檢索的條數為4889736;另外,檢索的時長在4秒左右浮動(去掉EXPLAIN執行查看)。
已使用索引:使用EXPLAIN分析SQL,分析的結果:
A、創建索引
DROP INDEX IF EXISTS idx_user_info ON t_user_info;
CREATE INDEX idx_user_info ON t_user_info(account);
B、分析檢索

在這裡,我們只對比不同的地方,使用了索引之後,檢索的類型是ref即索引算法檢索;使用了key索引,索引名字為idx_user_info;檢索的條數為1;查詢條件Extra為Using index condition;另外,檢索的時長在0.01秒左右浮動,基本提高了4倍速度。
得出結論:
在數據量大的檢索中,對比未使用索引,基本提高了4個級別程度,所以在經常檢索的表字段建立索引使用。
2、唯一索引
A、創建索引
ALTER TABLE t_user_info DROP INDEX idx_user_info;
ALTER TABLE t_user_info ADD UNIQUE (account);
B、分析索引

從上圖分析,為了演示准確,我們將上面建有的普通索引刪除,再新建一唯一索引。使用與普通索引同樣的檢索SQL,分析後主要的結果是一樣的;另外,得到的時長也是相同的。上面只是分析了唯一索引在速度方面,下面再來看看唯一索引在數據唯一性方面的特性,這裡我們選擇插入一條已有的數據,正常系統應該返回並提示錯誤信息:不能重復插入相同的唯一索引字段內容。
插入的語句:
INSERT INTO t_user_info(account,password,nickname,email,address) VALUES (
"cwteam11",
"e10adc3949ba59abbe56e057f20f883e",
"cwteam11",
"abc@yeah.net",
"china shss"
);
測試結果:

得出結論:
唯一索引的創建和使用,不影響它的查詢優勢,同時也保證了數據的唯一性。
3、組合索引
A、創建索引
ALTER TABLE t_user_info DROP INDEX account;
ALTER TABLE t_user_info ADD INDEX idx_user_info(account,password);
B、分析索引
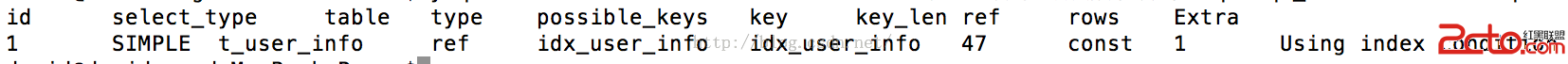
從上圖看到,組合索引的使用與普通的索引相同的,只不過索引的字段數量不同罷了;另外,在查詢時間上也是相同的。
得出結論:
組合索引與普通索引原理相同,不同的是索引的字段數量而已,同時也不影響檢索速度。
NOTE:
一般,組合索引用在保證多個列唯一的需求,也就是要結合UNIQUE索引才有實際意義,上面只是演示索引的不同。
4、全文索引
全文索引默認在引擎MyISAM支持,但在Mysql5.6版本開始,數據庫引擎InnoDB也開始支持了。由於我的MYSQL版本低於5.6,並未升級(後續升級),所以這裡暫時修改數據表的引擎為MyISAM,目的是為了介紹全文檢索。
在500萬的數據量中,我們對比LIKE和MATCH(…)AGAINST(…)在達到同樣功能時:
兩者的差別:
A、使用LIKE檢索
EXPLAIN SELECT account,nickname,email,address FROM t_user_info WHEREaccount LIKE " cwteam400000";
分析結果:

從上圖看出,在使用LIKE檢索時,采用的是全表掃描,並未使用索引掃描,時長在1.16秒左右浮動,這對於500萬條數據其實還是可以的,但隨著數據的增加這個時長也會隨之增加的,下面來看下使全文索引生效的MATCH…AGAINST的特點。
B、使用全文索引
EXPLAIN SELECT account,nickname,email,address FROM t_user_info WHEREMATCH(account,password) AGAINST(' cwteam400000');
分析結果:

從上圖明顯看出,檢索使用了全文檢索FULLTEXT,時長在0.01秒左右浮動,所以全文索引的效率還是挺高的,當然它的檢索時長也會隨著數據量增多,不斷增多哦(好像是廢話)。
得出結論:
如果建立的索引列數較多,建議使用全文檢索,而在大數據量檢索中,可使用MATCH-AGAINST使FULLTEXT生效,代替使用LIKE全表檢索。
五、索引的優化
根據上面對索引的介紹,我們可以總結一下常用的優化索引建議:
1、在經常查詢的表字段建立索引
具體創建什麼索引,可根據需求來定,如果沒有特殊要求,如:是否允許重復,那麼就可以創建一普通的索引;否則,可以創建一個唯一縮影;如果需要多個索引列唯一,那麼就創建唯一組合索引即可。
2、在大數據量檢索中,盡量使用FULL-TEXT索引代替LIKE
使用InnoDB引擎的同學,需要升級MYSQL版本到5.6,或者使用MyISAM引擎。
3、維護優化索引碎片
在建有索引的數據表中,每當刪除記錄數據時,對應記錄上的索引標記並未刪除,這會產生數據垃圾,也叫碎片,長期以往不作處理的話,會影響數據的檢索效率。
比較好的辦法:重建索引。
4、避免使用聚合函數
在建有索引的數據檢索中,盡量在檢索條件後不使用聚合函數,這可能會使索引失效,影響數據檢索速度。
NOTE:
對於索引的優化,很多時候就是保證索能發揮其正常的功能,所以很多圍繞索引的優化,其實就是避免索引被迫害,剩下的就是對檢索的SQL的優化了。