思考一下這個場景:如果重做日志可以無限地增大,同時緩沖池也足夠大,那麼是不需要將緩沖池中頁的新版本刷新回磁盤。因為當發生宕機時,完全可以通過重做日志來恢復整個數據庫系統中的數據到宕機發生的時刻。
但是這需要兩個前提條件:1、緩沖池可以緩存數據庫中所有的數據;2、重做日志可以無限增大
因此Checkpoint(檢查點)技術就誕生了,目的是解決以下幾個問題:1、縮短數據庫的恢復時間;2、緩沖池不夠用時,將髒頁刷新到磁盤;3、重做日志不可用時,刷新髒頁。
當數據庫發生宕機時,數據庫不需要重做所有的日志,因為Checkpoint之前的頁都已經刷新回磁盤。數據庫只需對Checkpoint後的重做日志進行恢復,這樣就大大縮短了恢復的時間。
當緩沖池不夠用時,根據LRU算法會溢出最近最少使用的頁,若此頁為髒頁,那麼需要強制執行Checkpoint,將髒頁也就是頁的新版本刷回磁盤。
當重做日志出現不可用時,因為當前事務數據庫系統對重做日志的設計都是循環使用的,並不是讓其無限增大的,重做日志可以被重用的部分是指這些重做日志已經不再需要,當數據庫發生宕機時,數據庫恢復操作不需要這部分的重做日志,因此這部分就可以被覆蓋重用。如果重做日志還需要使用,那麼必須強制Checkpoint,將緩沖池中的頁至少刷新到當前重做日志的位置。
對於InnoDB存儲引擎而言,是通過LSN(Log Sequence Number)來標記版本的。
LSN是8字節的數字,每個頁有LSN,重做日志中也有LSN,Checkpoint也有LSN。可以通過命令SHOW ENGINE INNODB STATUS來觀察:
mysql> show engine innodb status \G --- LOG --- Log sequence number 34778380870 Log flushed up to 34778380870 Last checkpoint at 34778380870 0 pending log writes, 0 pending chkp writes 54020151 log i/o's done, 0.92 log i/o's/second
Checkpoint發生的時間、條件及髒頁的選擇等都非常復雜。而Checkpoint所做的事情無外乎是將緩沖池中的髒頁刷回到磁盤,不同之處在於每次刷新多少頁到磁盤,每次從哪裡取髒頁,以及什麼時間觸發Checkpoint。
在InnoDB存儲引擎內部,有兩種Checkpoint,分別為:Sharp Checkpoint、Fuzzy Checkpoint
Sharp Checkpoint 發生在數據庫關閉時將所有的髒頁都刷新回磁盤,這是默認的工作方式,即參數innodb_fast_shutdown=1。但是若數據庫在運行時也使用Sharp Checkpoint,那麼數據庫的可用性就會受到很大的影響。故在InnoDB存儲引擎內部使用Fuzzy Checkpoint進行頁的刷新,即只刷新一部分髒頁,而不是刷新所有的髒頁回磁盤。
Fuzzy Checkpoint:1、Master Thread Checkpoint;2、FLUSH_LRU_LIST Checkpoint;3、Async/Sync Flush Checkpoint;4、Dirty Page too much Checkpoint
1、Master Thread Checkpoint
以每秒或每十秒的速度從緩沖池的髒頁列表中刷新一定比例的頁回磁盤,這個過程是異步的,此時InnoDB存儲引擎可以進行其他的操作,用戶查詢線程不會阻塞。
2、FLUSH_LRU_LIST Checkpoint
因為InnoDB存儲引擎需要保證LRU列表中需要有差不多100個空閒頁可供使用。在InnoDB1.1.x版本之前,需要檢查LRU列表中是否有足夠的可用空間操作發生在用戶查詢線程中,顯然這會阻塞用戶的查詢操作。倘若沒有100個可用空閒頁,那麼InnoDB存儲引擎會將LRU列表尾端的頁移除。如果這些頁中有髒頁,那麼需要進行Checkpoint,而這些頁是來自LRU列表的,因此稱為FLUSH_LRU_LIST Checkpoint。
而從MySQL 5.6版本,也就是InnoDB1.2.x版本開始,這個檢查被放在了一個單獨的Page Cleaner線程中進行,並且用戶可以通過參數innodb_lru_scan_depth控制LRU列表中可用頁的數量,該值默認為1024,如:
mysql> SHOW GLOBAL VARIABLES LIKE 'innodb_lru_scan_depth'; +-----------------------+-------+ | Variable_name | Value | +-----------------------+-------+ | innodb_lru_scan_depth | 1024 | +-----------------------+-------+
3、Async/Sync Flush Checkpoint
指的是重做日志文件不可用的情況,這時需要強制將一些頁刷新回磁盤,而此時髒頁是從髒頁列表中選取的。若將已經寫入到重做日志的LSN記為redo_lsn,將已經刷新回磁盤最新頁的LSN記為checkpoint_lsn,則可定義:
checkpoint_age = redo_lsn - checkpoint_lsn
再定義以下的變量:
async_water_mark = 75% * total_redo_log_file_size
sync_water_mark = 90% * total_redo_log_file_size
若每個重做日志文件的大小為1GB,並且定義了兩個重做日志文件,則重做日志文件的總大小為2GB。那麼async_water_mark=1.5GB,sync_water_mark=1.8GB。則:
當checkpoint_age<async_water_mark時,不需要刷新任何髒頁到磁盤;
當async_water_mark<checkpoint_age<sync_water_mark時觸發Async Flush,從Flush列表中刷新足夠的髒頁回磁盤,使得刷新後滿足checkpoint_age<async_water_mark;
checkpoint_age>sync_water_mark這種情況一般很少發生,除非設置的重做日志文件太小,並且在進行類似LOAD DATA的BULK INSERT操作。此時觸發Sync Flush操作,從Flush列表中刷新足夠的髒頁回磁盤,使得刷新後滿足checkpoint_age<async_water_mark。
可見,Async/Sync Flush Checkpoint是為了保證重做日志的循環使用的可用性。在InnoDB 1.2.x版本之前,Async Flush Checkpoint會阻塞發現問題的用戶查詢線程,而Sync Flush Checkpoint會阻塞所有的用戶查詢線程,並且等待髒頁刷新完成。從InnoDB 1.2.x版本開始——也就是MySQL 5.6版本,這部分的刷新操作同樣放入到了單獨的Page Cleaner Thread中,故不會阻塞用戶查詢線程。
MySQL官方版本並不能查看刷新頁是從Flush列表中還是從LRU列表中進行Checkpoint的,也不知道因為重做日志而產生的Async/Sync Flush的次數。但是InnoSQL版本提供了方法,可以通過命令SHOW ENGINE INNODB STATUS來觀察,如:
mysql> show engine innodb status \G BUFFER POOL AND MEMORY ---------------------- Total memory allocated 2058485760; in additional pool allocated 0 Dictionary memory allocated 913470 Buffer pool size 122879 Free buffers 79668 Database pages 41957 Old database pages 15468 Modified db pages 0 Pending reads 0 Pending writes: LRU 0, flush list 0, single page 0 Pages made young 15032929, not young 0 0.00 youngs/s, 0.00 non-youngs/s Pages read 15075936, created 366872, written 36656423 0.00 reads/s, 0.00 creates/s, 0.90 writes/s Buffer pool hit rate 1000 / 1000, young-making rate 0 / 1000 not 0 / 1000 Pages read ahead 0.00/s, evicted without access 0.00/s, Random read ahead 0.00/s LRU len: 41957, unzip_LRU len: 0 I/O sum[39]:cur[0], unzip sum[0]:cur[0]
4、Dirty Page too much
即髒頁的數量太多,導致InnoDB存儲引擎強制進行Checkpoint。其目的總的來說還是為了保證緩沖池中有足夠可用的頁。其可由參數innodb_max_dirty_pages_pct控制:
mysql> SHOW GLOBAL VARIABLES LIKE 'innodb_max_dirty_pages_pct' ; +----------------------------+-------+ | Variable_name | Value | +----------------------------+-------+ | innodb_max_dirty_pages_pct | 75 | +----------------------------+-------+
innodb_max_dirty_pages_pct值為75表示,當緩沖池中髒頁的數量占據75%時,強制進行Checkpoint,刷新一部分的髒頁到磁盤。在InnoDB 1.0.x版本之前,該參數默認值為90,之後的版本都為75。
在Innodb事務日志中,采用了Fuzzy Checkpoint,Innodb每次取最老的modified page(last checkpoint)對應的LSN,再將此髒頁的LSN作為Checkpoint點記錄到日志文件,意思就是“此LSN之前的LSN對應的日志和數據都已經flush到redo log
當mysql crash的時候,Innodb掃描redo log,從last checkpoint開始apply redo log到buffer pool,直到last checkpoint對應的LSN等於Log flushed up to對應的LSN,則恢復完成
那麼具體是怎麼恢復的呢?
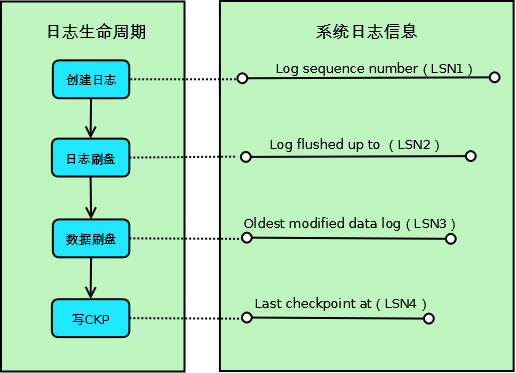
如上圖所示,Innodb的一條事務日志共經歷4個階段:
創建階段:事務創建一條日志;
日志刷盤:日志寫入到磁盤上的日志文件;
數據刷盤:日志對應的髒頁數據寫入到磁盤上的數據文件;
寫CKP:日志被當作Checkpoint寫入日志文件;
對應這4個階段,系統記錄了4個日志相關的信息,用於其它各種處理使用:
Log sequence number(LSN1):當前系統LSN最大值,新的事務日志LSN將在此基礎上生成(LSN1+新日志的大小);
Log flushed up to(LSN2):當前已經寫入日志文件的LSN;
Oldest modified data log(LSN3):當前最舊的髒頁數據對應的LSN,寫Checkpoint的時候直接將此LSN寫入到日志文件;
Last checkpoint at(LSN4):當前已經寫入Checkpoint的LSN;
對於系統來說,以上4個LSN是遞減的,即: LSN1>=LSN2>=LSN3>=LSN4.
具體的樣例如下(使用show innodb status \G命令查看,Oldest modified data log沒有顯示):
LOG --- Log sequence number 34822137537 Log flushed up to 34822137537 Last checkpoint at 34822133028 0 pending log writes, 0 pending chkp writes 54189288 log i/o's done, 3.00 log i/o's/second
mysql crash的時候,Innodb有日志刷盤機制,可以通過innodb_flush_log_at_trx_commit參數進行控制,這裡說的是如何防止日志覆蓋導致日志丟失
Innodb的checkpoint和redo log有哪些緊密關系?有幾上名詞需要解釋一下:

Ckp age(動態移動): 最老的dirty page還沒有flush到數據文件,即沒有做last checkpoint的范圍
Buf age(動態移動): modified page information沒有寫到log中,但已在log buffer
Buf async(固定點): 日志空間大小的7/8,當buf age移動到Buf async點時,強制把沒有寫到log中的modified page information開始寫入到log中,不阻塞事務
Buf sync(固定點): 日志空間大小的15/16,當寫入很大的,buf age移動非常快,一下子到buf sync的點,阻塞事務,強制把modified page information開始寫入到log中。如果不阻塞事務,未做last checkpoint的redo log存在覆蓋危險
Ckp async(固定點): 日志空間大小的31/32,當ckp age到達ckp async,強制做last checkpoint,不阻塞事務
Ckp sync(固定點):日志空間大小,當ckp age到達ckp sync,強制做last checkpoint,阻塞事務,存在redo log覆蓋的危險
接下分析4種情況
如果buf age在buf async和buf sync之間
如果buf age在buf sync之後(當然這種情況是不存在,mysql有保護機制)
如果ckp age在ckp async和ckp sync之間(這種情況是不存在)
如果ckp age在ckp sync之後(這種情況是不存在)
第一種情況:

當寫入量巨大時,buf age移動到buf async和buf sync之間,觸發寫出到log中,mysql把盡量多的log寫出,如果寫入量減慢,buf age又移回到“圖一”狀態。如果寫入量大於flush log的速度,buf age最終會和buf sync重疊,這時所有的事務都被阻塞,強制將2*(Buf age-Buf async)的髒頁刷盤,這時IO會比較繁忙。
第二種情況:

當然這種情況是不可能出現,因為如果出現,redo log存在覆蓋的可能,數據就會丟失。buf age會越過log size,buf age的大小可能就超過log size,如果要刷buf age,那麼整個log size都不夠容納所有的buf age。
第三種和第四種情況不存在分析:
ckp age始終位於buf age的後面(左邊),因為ckp age是last checkpoint點,總是追趕buf age(將盡可能多的modified page flush到磁盤),所以buf age肯定是先到達到buf sync。
ckp async及ckp sync存在意義?
mysql中page cache也存在high water及low water,當dirty page觸到low water時,os是開始flush dirty page到磁盤,到high water時,會阻塞一切動作,os會瘋狂的flush dirty page,磁盤會很忙,存在IO Storm,
本文參考:
http://blog.csdn.net/yah99_wolf/article/category/539408
http://www.cnblogs.com/bamboos/p/3532150.html
http://tech.uc.cn/?p=716
http://www.mysqlperformanceblog.com/2011/04/04/innodb-flushing-theory-and-solutions/