有一個用於歷史歸檔的數據庫(簡稱歷史庫),經過一定時間的積累,數據文件已經達到700多GB,後來決定某些數據可以不需要保留,就把這部分數據truncate了,空余出600多GB的空間,也就是說,經過收縮後,理論上數據庫只有100多G。為此,我經過重建各個表(表數量不多,但單表數量還是有幾千萬)的聚集索引後,准備進行收縮。
但是當收縮開始時,即使把每次收縮的范圍縮小到500MB,速度也極其慢,經常幾個小時都沒反應。經過查看等待信息之後發現有一個SPID=18的會話(SPID<=50的均為系統會話)一直顯示等待狀態為“SLEEP_BPROOL_FLUSH”,並且阻塞了收縮操作。

為此,我覺得即使是小概率事件(因為這個等待類型雖然常見,但是並不總引人注意),既然出現了,就不妨來研究一下。
說明:環境為SQL Server 2008R2
本文出處:http://blog.csdn.net/dba_huangzj/article/details/50455543
既然這已經成為了問題,那麼有必要先了解一下SLEEP_BPOOL_FLUSH這個等待狀態是什麼。在微軟官方說明中:https://technet.microsoft.com/zh-cn/library/ms179984(v=sql.105).aspx ,僅有簡單的描述:當檢查點為了避免磁盤子系統泛濫而中止新 I/O 的發布時出現。明顯這種解釋是不足的。因此我翻翻國外大牛的博客和其他書籍,總結如下:
這種等待狀態與checkpoint進程有直接關系,checkpoint主要用於在內存的緩沖區(BufferPool)中,自加載到內存之後發生了數據改變(稱為髒頁),在checkpoint觸發後把髒頁從內存回寫到磁盤的數據文件中。
所以很自然地想到Checkpoint。但是從行為特性來看,又意味著可能你的磁盤子系統有性能問題。
要了解SLEEP_BPOOL_FLUSH等待類型,有必要先了解一下Checkpoint這個東西。它是SQL Server後台觸發的系統進程,也可以手動輸入checkpoint來運行。
這個進程負責把緩沖區的被修改過的頁寫入到數據文件中。常見的地方是在備份中。這個進程的重要作用之一是加快數據庫在異常情況下恢復的速度。當數據庫發生故障時,SQL Server必須把數據庫盡可能地還原到之前的正常狀態。SQL Server會使用事務日志進行重做(redo)或回滾(undo),把未寫入數據文件的修改重新附加會數據文件中。如果數據頁被修改但還未寫入數據文件,SQL Server必須把修改重做。如果之前已經有一次Checkpoint發生並把這些髒頁寫到數據文件,那麼這一步就可以跳過,從而加快數據庫的恢復速度。如圖所示:
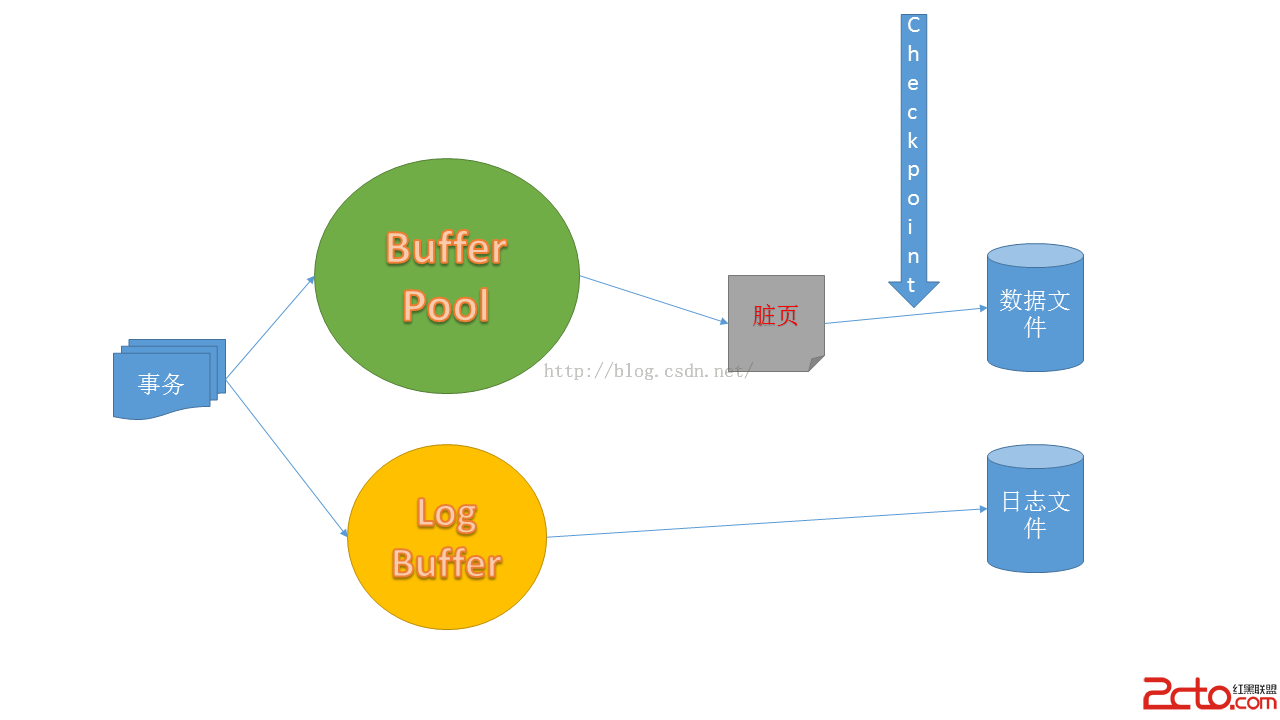
當一個數據頁被事務修改後,這個修改會先被記錄在事務日志中(實際上不寫入LDF文件而是內存中的一塊叫log buffer的區域中,然後再寫到磁盤的LDF文件中,這個過程由WRITELOG和LOGBUFFER等待類型表示)。然後在內存的buffer pool中的對應數據頁標識為髒頁。當Checkpoint進程觸發時,所有自上一次Checkpoint發生後至今的髒頁都會被物理地寫入磁盤的數據文件中,這個過程不會管引發髒頁的事務的狀態是什麼(提交、未提交、回滾)。
通常來說,Checkpoint由SQL Server自動周期性運行(默認情況下為一分鐘)。但是不代表真的是只有等待1分鐘才觸發。用戶可以設置這個運行周期不過除非你確定問題的根源在此,否則不要隨便修改。因為Checkpoint會自己分析當前IO請求、延時等情況進行觸發。從而避免不必要的高IO開銷。
在SQL Server中,有以下幾種Checkpoint類型(關於Checkpoint的詳細描述將在後續文章中專門介紹):
內部Checkpoint類型:不可配置,在特定情況下自動觸發,比如備份。自動Checkpoint類型:如果未改動SQLServer相關配置,會在1分鐘周期時觸發。這種類型可以修改時間,但是這種修改是實例級別的,並且只能修改為小於等於1分鐘。手動Checkpoint類型:通過SSMS或其他客戶端發起checkpoint命令。這種觸發可以輸入一個秒數,用於指定checkpoint必須在這個秒數內完成。這種操作是庫級別的。比如CHECKPOINT 10,代表SQL Server會在10秒內嘗試執行checkpoint。詳細內容可見:https://technet.microsoft.com/zh-cn/library/ms188748(v=sql.105).aspx間接Checkpoint類型:這是SQLServer 2012引入的庫級別選項。如果這個值大於0則會覆蓋特定數據庫上的默認自動Checkpoint配置,可以通過下面命令實現:ALTER DATABASE[數據庫名] SET TARGET_RECOVERY_TIME = [秒數或分鐘數]
前面提到過,SQL Server會分析當前系統壓力,當它認為當前沒必要進行Checkpoint時,會扼殺這個進程,從而避免磁盤子系統的雪上加霜。當Checkpoint被扼殺時,就會記錄在SLEEP_BPOOL_FLUSH等待類型的信息中。
在正常情況下,這種等待狀態應該盡可能接近0。
既然有問題,那麼就該解決,即使它可能通常沒有多大性能問題。遇到這個問題時,建議首先檢查配置,還是那句話,如無必要不要修改默認配置。可以通過下面語句查詢配置值:
select * from sys.configurations where name ='recovery interval (min)'其中“value”為0代表默認配置,這個值以分鐘為單位,值越小,Checkpoint的頻率就越高,越容易引發SLEEP_BPOOL_FLUSH等待。另外在事務中頻繁使用CHECKPOINT命令也很容易觸發這種等待。
除了這種情況之外,還有一個可能就是數據文件所在的磁盤子系統的性能問題。前面提到過,Checkpoint觸發的結果是把緩沖區的髒頁寫入磁盤,如果當前磁盤負載非常大,那麼Checkpoint操作就會被頻繁扼殺,從而引起SLEEP_BPOOL_FLUSH等待。
前面介紹了這種等待狀態的含義、原因,那麼現在來看看我的問題,因為問題還是要解決。經過檢查,默認配置沒問題,而我在執行的操作是數據文件收縮,所以問題應該是在收縮上面。
收縮數據文件有三個潛在問題:
收縮的邏輯就是把數據移動到數據文件較前的區中,因為收縮是從數據文件的最後的區開始回收,這個操作會消耗大量的時間和系統資源用於移動所有的數據。在這個過程中,SQL Server使用大量的CPU資源去決定數據可以移動到哪裡,有多少空間可以用於移動,同時要求大量的IO資源用於從數據文件中讀取數據和把數據寫入到新的物理地址中。另外,如果表沒有聚集索引,那麼非聚集索引由於葉子節點記錄了RID信息,所以移動會導致非聚集索引的信息更新開銷。注意是“每個非聚集索引的每一行”都受影響。不用多說都可以想象到,這是很高開銷的操作。日志文件的增長:不管當前使用何種恢復模式,SQL Server都會記錄每個數據移動操作,每個數據頁和區的分配或回收,還有每個索引的變更。這種記錄會加重前面第一個問題的系統資源開銷,同時會導致日志文件的快速增大。有一位MVP的博客上介紹了數據文件收縮所需的日志文件數量:http://www.karaszi.com/SQLServer/info_dont_shrink.asp增加表和索引的碎片:需要先說明,碎片不總是壞事,因為存在就有存在的理由。有很多操作並不受碎片影響。這部分可以看微軟的白皮書:https://technet.microsoft.com/en-us/library/cc966523.aspx 。裡面介紹了碎片的不通類型和需要關注的碎片情景。通過前面的分析,在查看服務器那個歷史庫所在的磁盤(普通SAS盤),可以初步確定是磁盤IO性能問題。因為在之前已經對所有表的聚集索引進行了重建(沒有堆表),應該是數據緊密度足夠高。這就是最頭痛的問題,不可能因為收縮慢就說換磁盤,即使能換,財務流程也不是一般的繁瑣。那麼我們還是來想想怎麼使得每次讀寫操作盡可能地小吧。 本文出處:http://blog.csdn.net/dba_huangzj/article/details/50455543
這個是一個歷史庫,歷史庫在月底(寫本文的時候)會有比較多的月結類、年度結算類查詢,在頻繁使用的過程中收縮文件顯然不合理,所以把這個操作放在閒時運行(閒時並不一定就是晚上,主要看系統類型和操作時間段)。另外,收縮的規模也要盡可能小,為了避免一大片的語句,可以用下面語句進行自動化收縮:
declare @sql nvarchar(1024) declare @size int=758000--當前大小,MB為單位 declare @end int =1024 --停止范圍 while @size>=@end --直到達到停止范圍前一直循環 begin set @sql='DBCC SHRINKFILE (N''數據文件名'','+cast(@size as nvarchar(20))+')' --print @sql exec (@sql) set @size=@size-500 end