MySQL5.6中引入了MRR,專門來優化:二級索引的范圍掃描並且需要回表的情況。它的原理是,將多個需要回表的二級索引根據主鍵進行排序,然後一起回表,將原來的回表時進行的隨機IO,轉變成順序IO。文檔地址:http://dev.mysql.com/doc/refman/5.6/en/mrr-optimization.html
Reading rows using a range scan on a secondary index can result in many random disk accesses to the base table when the table is large and not stored in the storage engine's cache. With the Disk-Sweep Multi-Range Read (MRR) optimization, MySQL tries to reduce the number of random disk access for range scans by first scanning the index only and collecting the keys for the relevant rows. Then the keys are sorted and finally the rows are retrieved from the base table using the order of the primary key. The motivation for Disk-sweep MRR is to reduce the number of random disk accesses and instead achieve a more sequential scan of the base table data.
首先對二級索引進行范圍掃描,對於符合條件的 key, 按照主鍵進行排序,然後一起根據key來讀取基表。
The Multi-Range Read optimization provides these benefits:
MRR enables data rows to be accessed sequentially rather than in random order, based on index tuples. The server obtains a set of index tuples that satisfy the query conditions, sorts them according to data row ID order, and uses the sorted tuples to retrieve data rows in order. This makes data access more efficient and less expensive.
MRR enables batch processing of requests for key access for operations that require access to data rows through index tuples, such as range index scans and equi-joins that use an index for the join attribute. MRR iterates over a sequence of index ranges to obtain qualifying index tuples. As these results accumulate, they are used to access the corresponding data rows. It is not necessary to acquire all index tuples before starting to read data rows.
MRR的主要優勢:將隨機IO轉換成順序IO;使用在 索引范圍掃描 和 使用索引進行join 時;
The following scenarios illustrate when MRR optimization can be advantageous:
Scenario A: MRR can be used for InnoDB and MyISAM tables for index range scans and equi-join operations.
A portion of the index tuples are accumulated in a buffer.
The tuples in the buffer are sorted by their data row ID.
Data rows are accessed according to the sorted index tuple sequence.
When MRR is used, the Extra column in EXPLAIN output shows Using MRR.
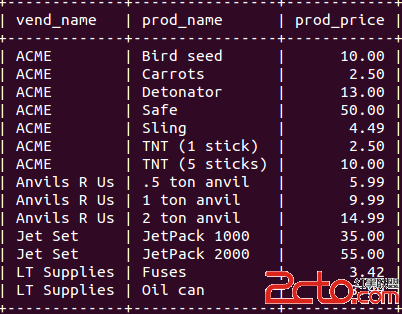
Example query for which MRR can be used, assuming that there is an index on (:key_part1, key_part2)
SELECT * FROM t WHERE key_part1 >= 1000 AND key_part1 < 2000 AND key_part2 = 10000;
The index consists of tuples of ( values, ordered first by key_part1, key_part2)key_part1 and then by key_part2.
Without MRR, an index scan covers all index tuples for the key_part1 range from 1000 up to 2000, regardless of the key_part2 value in these tuples. The scan does extra work to the extent that tuples in the range contain key_part2 values other than 10000.
With MRR, the scan is broken up into multiple ranges, each for a single value of key_part1 (1000, 1001, ... , 1999). Each of these scans need look only for tuples with key_part2 = 10000. If the index contains many tuples for which key_part2 is not 10000, MRR results in many fewer index tuples being read.
To express this using interval notation, the non-MRR scan must examine the index range [{1000, 10000}, {2000, MIN_INT}), which may include many tuples other than those for which key_part2 = 10000. The MRR scan examines multiple single-point intervals [{1000, 10000}], ..., [{1999, 10000}], which includes only tuples with key_part2 = 10000.
Two optimizer_switch system variable flags provide an interface to the use of MRR optimization. The mrr flag controls whether MRR is enabled. If mrr is enabled (on), the mrr_cost_based flag controls whether the optimizer attempts to make a cost-based choice between using and not using MRR (on) or uses MRR whenever possible (off). By default, mrr is on and mrr_cost_based is on. See Section 8.9.2, “Controlling Switchable Optimizations”.
For MRR, a storage engine uses the value of the read_rnd_buffer_size system variable as a guideline for how much memory it can allocate for its buffer. The engine uses up to read_rnd_buffer_size bytes and determines the number of ranges to process in a single pass.
MySQL的MRR一次掃描多少個二級索引,然後進行回表,其使用到的內存是參考 read_rnd_buffer_size 的值來決定的。
總結:
MRR 僅僅針對 二級索引 的范圍掃描 和 使用二級索引進行 join 的情況。
MRR 的優勢是將多個隨機IO轉換成較少數量的順序IO。所以對於 SSD 來說價值還是有的,但是相比機械磁盤來說意義小一些。