OR、in和union all 查詢效率到底哪個快?
網上很多的聲音都是說union all 快於 or、in,因為or、in會導致全表掃描,他們給出了很多的實例。
但真的union all真的快於or、in?
EXPLAIN SELECT * from employees where employees.first_NAME ='Georgi' UNION ALL SELECT * from employees where employees.first_NAME ='Bezalel'
這條語句執行結果481條,執行時間為0.35s
PRIMARY employees ALL 300141 Using where
UNION employees ALL 300141 Using where
UNION RESULT <union1,2> ALL
explain SELECT * FROM employees WHERE employees.first_name IN ('Georgi','Bezalel')
這條語句的執行結果時間為0.186s
SIMPLE employees ALL 300141 Using where explain SELECT * FROM employees WHERE employees.first_name ='Georgi' or employees.first_name='Bezalel'
這條語句的執行結果和in的結果差不多
難道是網上的說法有誤?難道和索引有關?在firstname上建立了一個索引
重新執行
union的執行執行計劃如下,執行時間為0.004s
PRIMARY employees ref index_firstname index_firstname 44 const 253 Using where UNION employees ref index_firstname index_firstname 44 const 228 Using where UNION RESULT <union1,2> ALL
in的執行計劃如下,執行時間也為0.004s
SIMPLE employees range index_firstname index_firstname 44 481 Using where
or的執行計劃如下,執行時間也為0.004s
SIMPLE employees range index_firstname index_firstname 44 481 Using where
感覺性能差不多啊。但是注意執行計劃中的type,ref要好於range哦(ref為非唯一性索引掃描,range為索引范圍掃描)
突然感覺好像和網上說的差不多了,但是第一個語句走了兩個ref掃描 會不會效率比走一次range的掃描低啊。
要不我再試試主鍵,這個是唯一的,會不會和網上的效果一直呢?
EXPLAIN SELECT * FROM employees WHERE employees.EMP_NO=100001 UNION ALL SELECT * FROM employees WHERE employees.EMP_NO=101100
union的執行計劃如下
PRIMARY employees const PRIMARY PRIMARY 4 const 1 UNION employees const PRIMARY PRIMARY 4 const 1 UNION RESULT <union1,2> ALL EXPLAIN SELECT * FROM employees WHERE employees.EMP_NO IN (100001 ,101100)
in的執行計劃如下
SIMPLE employees range PRIMARY PRIMARY 4 2 Using where EXPLAIN SELECT * FROM employees WHERE employees.EMP_NO=100001 OR emp_no=101100
or的執行計劃如下
SIMPLE employees range PRIMARY PRIMARY 4 2 Using where
感覺結果和第二個實驗還是差不多。
下面本文就采用實例來探討在實際的查詢命令下它們之間的效率對比究竟如何。
1:創建表,插入數據、數據量為1千萬【要不效果不明顯】。
drop table if EXISTS BT; create table BT( ID int(10) NOT NUll, VName varchar(20) DEFAULT '' NOT NULL, PRIMARY key( ID ) )ENGINE=INNODB;
該表只有兩個字段 ID為主鍵【索引頁類似】,一個是普通的字段。(偷懶就用簡單的表結構呢)
向BT表中插入1千萬條數據
這裡我寫了一個簡單的存儲過程【所以你的mysql版本至少大於5.0,俺的版本為5.1】,代碼如下。
注意:最好
INSERT INTO BT ( ID,VNAME ) VALUES( i, CONCAT( 'M', i ) );---1
修改為
INSERT INTO BT ( ID,VNAME ) VALUES( i, CONCAT( 'M', i, 'TT' ) );---2
修改原因在
非索引列及VNAME使用了聯合進行完全掃描請使用1 。
非索引列及VNAME使用了全表掃描請使用2 。
DROP PROCEDURE IF EXISTS test_proc; CREATE PROCEDURE test_proc() BEGIN declare i int default 0; set autocommit = 0; while i<10000000 do INSERT INTO BT ( ID,VNAME ) VALUES( i, CONCAT( 'M', i ) ); set i = i+1; if i%2000 = 0 then commit; end if; end while; END;
就不寫注釋呢,挺簡單的。
存儲過程是最好設置下innob的相關參數【主要和日志、寫緩存相關這樣能加快插入】,俺沒有設置插入1千萬條數據插了6分鐘。
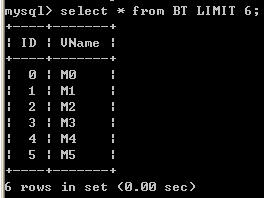
部分數據如下:1千萬數據類似
2:實戰
2.1 :分別在索引列上使用 or、in、union all
我們創建的表只有主鍵索引,所以只能用ID做查詢呢。我們查 ID 為 98,85220,9888589的三個數據各個耗時如下:

時間都為0.00,怎麼會這樣呢,呵呵所有查詢都是在毫秒級別。
我使用其他的工具--EMS SQL Manager for mysql
查詢顯示時間為
93 ms, 94ms,93 ms,時間相差了多少幾乎可以忽略。
然後我們在看看各自的執行計劃
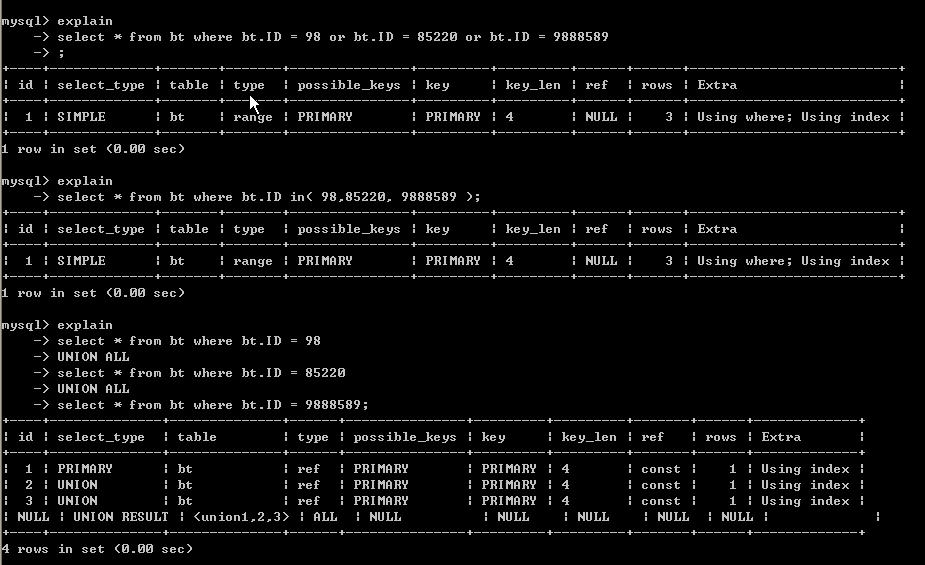
這裡要注意的字段type 與ref字段
我們發現union all 的所用的 type【type為顯示連接使用了何種類型】 為ref 而or和in為range【ref連接類型優於range,相差不了多少】,而查詢行數都一樣【看rows字段都是為3】。
從整個的過程來看,在索引列使用常數or及in和union all查詢相差不了多少。
但為什麼在有的復雜查詢中,再索引列使用or及in 比union all 速度慢很多呢,這可能是你的查詢寫的不夠合理,讓mysql放棄索引而進行全表掃描。
2.2:在非索引列中使用 or、in及union all。
我們查 VNAME 為 M98,M85220,M9888589的三個數據各個耗時如下:
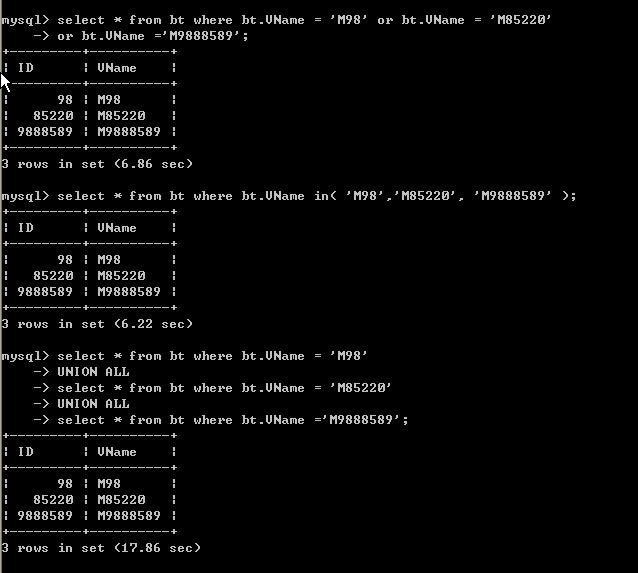
我們發現為啥union all查詢時間幾乎為 or 和in的三倍。
這是為什麼呢,我們先不說,先看看三個的查詢計劃。
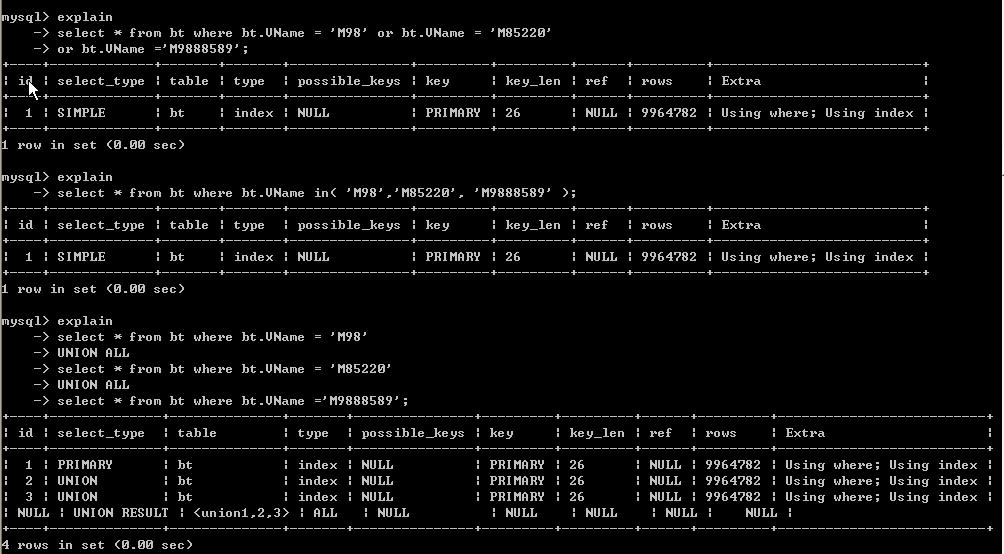
這裡我們發現計劃幾乎一樣。
但我們要注意掃描的此時對於 or及in 來說 只對表掃描一次即rows是列為9664782。
而對於union all 來說對表掃描了三次即rows的和為9664782*3。
這也是為什麼我們看到union all 為幾乎為三倍的原因。
備注: 如果使用存儲過程使用第二sql該執行計劃所有的type列 為 all,其實這個是我最想演示的,但現在已經快寫完畢了才發現問題將錯就錯呢。
3:總結
3.1:不要迷信union all 就比 or及in 快,要結合實際情況分析到底使用哪種情況。
3.2:對於索引列來最好使用union all,因復雜的查詢【包含運算等】將使or、in放棄索引而全表掃描,除非你能確定or、in會使用索引。
3.3:對於只有非索引字段來說你就老老實實的用or 或者in,因為 非索引字段本來要全表掃描而union all 只成倍增加表掃描的次數。
3.4:對於及有索引字段【索引字段有效】又包含非索引字段來時,按理你也使用or 、in或者union all 都可以,
但是我推薦使用or、in。
如以下查詢:
select * from bt where bt.VName = 'M98' or bt.id ='9888589' select * from bt where bt.VName = 'M98' UNION ALL select * from bt where bt.id = '9888589'
該兩個查詢速度相差多少 主要取決於 索引列查詢時長,如索引列查詢時間太長的話,那你也用or或者in代替吧。
3.5: 以上主要針對的是單表,而多表聯合查詢來說,考慮的地方就比較多了,比如連接方式,查詢表數據量分布、索引等,再結合單表的策略選擇合適的關鍵字。