由於MySQL數據庫是基於行(Row)存儲的數據庫,而數據庫操作 IO 的時候是以 page(block)的方式,也就是說,如果我們每條記錄所占用的空間量減小,就會使每個page中可存放的數據行數增大,那麼每次 IO 可訪問的行數也就增多了。反過來說,處理相同行數的數據,需要訪問的 page 就會減少,也就是 IO 操作次數降低,直接提升性能。此外,由於我們的內存是有限的,增加每個page中存放的數據行數,就等於增加每個內存塊的緩存數據量,同時還會提升內存換中數據命中的幾率,也就是緩存命中率。
MySQL支持很多種不同的數據類型,並且選擇正確的數據類型對於獲得高性能至關重要。不管選擇何種類型,下面的簡單原則都會有助於做出更好的選擇:
1、越簡單越小越好
更小的數據類型通常更快,因為它們使用了更少的磁盤空間、內存和CPU緩存,而且需要的CPU周期也更少。越簡單的數據類型,需要的CPU周期就越少。例如:比較整數的代價小於比較字符,因為字符集和排序規則使字符比較更復雜。
2、避免空(NULL)
要盡可地把字段定義為NOT NULL ,如果計劃對列進行索引,就要盡量避免把它設置為可為空(NULL),NULL 類型比較特殊,SQL 難優化。雖然 MySQL NULL類型和 Oracle 的NULL 有差異,會進入索引中,但如果是一個組合索引,那麼這個NULL 類型的字段會極大影響整個索引的效率。此外,NULL 在索引中的處理也是特殊的,也會占用額外的存放空間。很多人覺得 NULL 會節省一些空間,所以盡量讓NULL來達到節省IO的目的,但是大部分時候這會適得其反,雖然空間上可能確實有一定節省,倒是帶來了很多其他的優化問題,不但沒有將IO量省下來,反而加大了SQL的IO量。所以盡量確保 DEFAULT 值NOT NULL,也是一個很好的表結構設計優化習慣。
3、盡可能不要直接 SELECT * 讀取全部字段,尤其是表中存在 TEXT/BLOB 大列的時候。可能本來不需要讀取這些列,但因為偷懶寫成 SELECT * 導致內存buffer pool被這些“垃圾”數據把真正需要緩沖起來的熱點數據給洗出去了
4、超過20個長度的字符串列,最好創建前綴索引而非整列索引(例如:ALTER TABLE t1 ADD INDEX(user(20))),可以有效提高索引利用率,不過它的缺點是對這個列排序時用不到前綴索引。前綴索引的長度可以基於對該字段的統計得出,一般略大於平均長度一點就可以了
5、定期用 pt-duplicate-key-checker 工具檢查並刪除重復的索引。比如 index idx1(a, b) 索引已經涵蓋了 index idx2(a),就可以刪除 idx2 索引了
6、有多字段聯合索引時,WHERE中過濾條件的字段順序無需和索引一致,但如果有排序、分組則就必須一致了
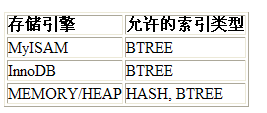
7、默認地,使用InnoDB引擎,InnoDB必須要有自增(或類似自增)屬性的主鍵
8、若無特殊需求,均可使用latin1字符集,否則用utf8\utf8mb4等大字符集保證通用性
9、基數小的不適合建立索引,復合索引比普通索引更合適
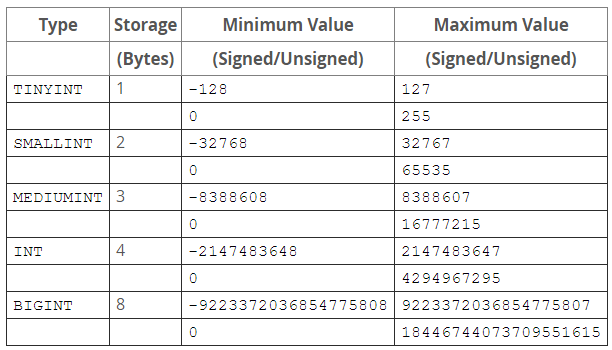
"TINYINT"=>1,
"SMALLINT"=>2,
"MEDIUMINT"=>3,
"INT"=>4,
"BIGINT"=>8,
"FLOAT"=>'if ($M <= 24) {return 4;} else {return 8;}',
"DOUBLE"=>8,
"DECIMAL"=>'if ($M < $D) {return $D + 2;} elsif ($D > 0) {return $M + 2;} else {return $M + 1;}',
"NUMERIC"=>'if ($M < $D) {return $D + 2;} elsif ($D > 0) {return $M + 2;} else {return $M + 1;}',
"DATE"=>3,
"DATETIME"=>8,
"TIMESTAMP"=>4,
"TIME"=>3,
"YEAR"=>1,
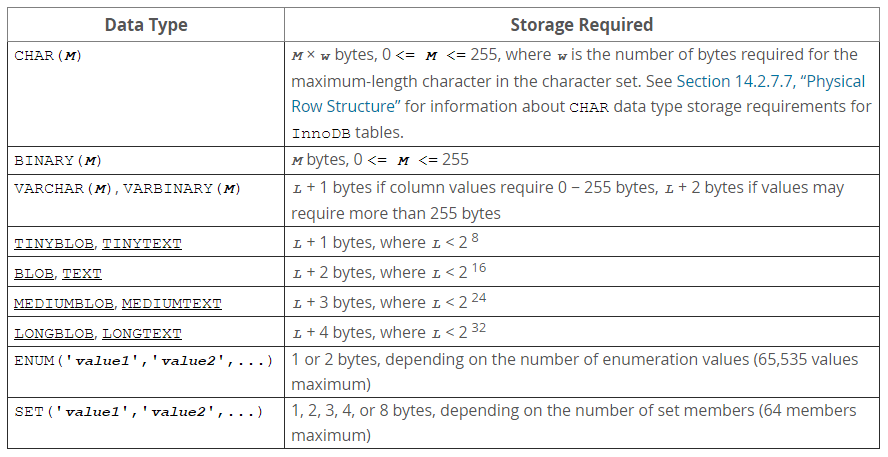
"CHAR"=>'$M',
"VARCHAR"=>'$M+1',
"TINYBLOB"=>'$M+1',
"TINYTEXT"=>'$M+1',
"BLOB"=>'$M+2',
"TEXT"=>'$M+2',
"MEDIUMBLOB"=>'$M+3',
"MEDIUMTEXT"=>'$M+3',
"LONGBLOB"=>'$M+4',
"LONGTEXT"=>'$M+4'
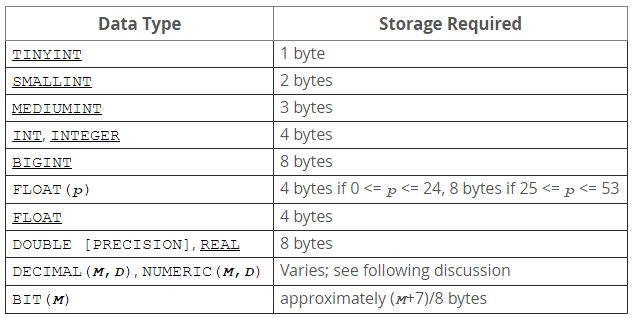
如果存儲整數,就可以使用這幾種整數類型,如下所示
還有一個,BIT(M) approximately (M+7)/8 bytes
varchar:保存了可變長度的字符串,是使用得最多的字符串類型,它能比固定類型占用更少的存儲空間,因為它只占用了自已需要的空間(也就是說較短的值占用的空間更小)。它使用額外的1-2個字節來存儲值的長度。varchar能節約空間,所以對性能有幫助。然而,由於行的長度是可變的,它們在更新的時候可能會發生變化,這會引起額外的工作。當最大長度遠大於平均長度,並且很少發生更新的時候,通常適合用varchar。這時候碎片就不會成為問題,還有你使用復雜的字符集,如utf-8時,它的每個字符都可能會占用不同的存儲空間。varchar存取值時候,MySQL不會去掉字符串末尾的空格。
char:固定長度,char存取值時候,MySQL會去掉末尾的空格。Char在存儲很短的字符串或長度近似相同的字符的時候很有用。例如,char適用於存儲密碼的MD5哈希值,它的長度總是一樣的。對於經常改變的值,char也好於varchar,因為固定長度的行不容易產生碎片,對於很短的列,char的效率也高於varchar。Char(1)字符串對於單字節字符集只會占用1個字節,而varchar(1)則會占用2個字節,因為有一個字節用來存儲其長度。
Char和varchar的兄弟類型為binary和varbinary,它們用於保存二進制的字符串,二進制字符串的傳統的字符串很類似,但是它們保存的是字節而不是字符。填充也有所不同,MySQL使用\0(0字節)填充binary值,而不是空格,並且不會在獲取數據的時候把填充的值截掉。
使用varchar(5)和varchar(200)保存“hello”占用的空間是一樣的,但是使用較短的列有很大的優勢,較大的列會使用更多的內存,因為MySQL通常會分配固定大小的內存塊來保存值。這對排序或使用基於內存的臨時表尤其不好。同樣的事情也會發生在使用文件排序或基於磁盤的臨時表的時候。
一般不要使用 TEXT 數據類型,其處理方式決定了他的性能要低於char或者是varchar類型的處理。定長字段,建議使用 CHAR 類型,不定長字段盡量使用 VARCHAR,且僅僅設定適當的最大長度,而不是非常隨意的給一個很大的最大長度限定,因為不同的長度范圍,MySQL也會有不一樣的存儲處理
BLOB和TEXT分別用二進制和字符形式保存大量數據。
事實在,它們各有自的數據類型家族:
字符類型有TINYTEXT, SMALLTEXT, TEXT, MEDIUMTEXT和LONGTEXT,
二進制類型有TINYBLOB, SMALLBLOB, BLOB, MEDICMBLOB, LONGBLOB,BLOB 等同於SMALLBLOB, TEXT等同於SMALLTEXT
和其它類型不同,MYSQL把BLOB, TEXT當成有實體的對象來處理,存儲引擎通常會特別地保存它們。INNODB在它們較大的時候會使用單獨的“外部”存儲來進行保存,每個值在行裡面都需要1-4字節,並且還需要足夠的外部存儲空間來保存實際的值。
BLOB和TEXT唯一的區別就是BLOB保存的是二進制數據,沒有字符集和排序規則,TEXT保存的是字符數據,有字符集和排序規則。
MYSQL對BLOB、TEXT列的排序方式和其它類型不同,它不會按照字符串的長度進行排序,而只是按照MAX_SORT_LENGTH規定的前若干個字節進行排序,如果只按照開始的幾個字符排序,就可以減少MAX_SORT_LENGTH的值或使用ORDER BY SUBSTRING(COLUMN, LENGTH)。MYSQL不能索引這些數據類型的完整長度,也不能為排序而使用索引。
強烈反對在數據庫中存放 BLOB 類型數據,雖然數據庫提供了這樣的功能,但這不是他所擅長的,我們更應該讓合適的工具做他擅長的事情,才能將其發揮到極致
ENUM的內部存儲機制是采用TINYINT或SMALLINT(並非CHAR/VARCHAR),而且即使需要增加新的類型,只要增加於末尾,修改結構也不需要重建表數據,ENUM列可以存儲65535個不同的字符串,MYSQL以非常緊湊的方式保存了它們,根據列表中值的數量,MYSQL會把它們壓縮到1-2個字節中,MYSQL在內部會把每個值都保存為整數,以表示值在列表中的位置,並且還保留了一份“查找表”來表示整數和字符串在表的.FRM文件中的映射關系。
ENUM最不好的一面是字符串是固定的,如果需要添加或者刪除字符串必須使用ALTER TABLE,因此,對於一系列未知可能會改變的字符串,使用ENUM就不是一個好主意,MYSQL在內部的權限表中使用ENUM來保存Y值和N值。
由於MYSQL把每個值保存為整數,並且須進行查找才能把它轉換成字符串形式,所以ENUM有一些開銷。這通常可以由它們較小的大小進行彌補,但不總是這樣,在特定情況下,把CHAR或VARCHAR列和ENUM列進行聯接,可能會比聯接另一個CHARA或VARCHAR列慢。
對於確定屬性的字段,可以嘗試使用SET類型,即使存在多種屬性,同樣可以游刃有余,可以結合FIND_IN_SET來使用,記住千萬別用CHAR/VARCHAR來存儲枚舉數據
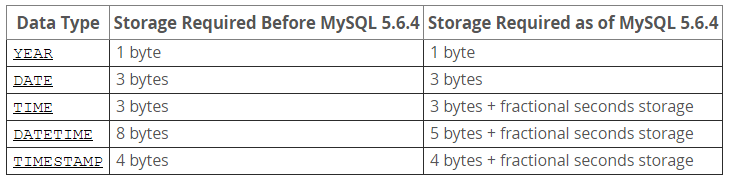
For example, TIME(0), TIME(2), TIME(4), and TIME(6) use 3, 4, 5, and 6 bytes, respectively. TIME andTIME(0) are equivalent and require the same storage
可以使用多種類型來保存各種日期和時間值,比中year和date,MySQL能存儲的最細的時間粒度是秒,然而它可以用毫秒的粒度進行暫時的運算。
有幾種相似的數據類型:DATETIME、TIMESTAMP和INT
為標識列選擇好的數據類型非常重要,你可能會更多地用它們和其他列做比較,還可能把它們用作其它表的外鍵,因為選擇標識符列選擇數據類型的時候,你也可能是在為相關的表選擇數據類型。
當為標識符列選擇數據類型的時候,不僅要考慮存儲類型,還要考慮MYSQL如何對它們進行計算和比較。例如:MYSQL會在內部把ENUM和SET類型保存為整數,但是在比較的時候把它們轉換為字符串。
一旦選擇了數據類型,要確保在相關表中使用同樣的類型。類型之前要精確匹配,包括諸如UNSIGNED這樣的屬性。混合不同的數據類型會導致性能問題,即使沒有性能問題,隱式的類型轉換也能導致難以察覺的錯誤,在你已經忘記了自己是在對不同類型做比較的時候,這些錯誤就會突然出現。
選擇最小的數據類型能表明所需值的范圍,並且為將來留出增長的空間。例如,如果用PORVINCE_ID來表示中國的省份,那麼我們知道它不會產成千上萬個值,因類就沒有必要使用INT,用TINYINT就足夠了,它比INT小3個節字,如果把一個表的主鍵是TINYINT,而另一個表以INT作為外鍵,那麼就會造成較大的性能差距。
整數通常是標識符的最佳選擇,因為它速度快,並且能使用AUTO_INCREMENT。
ENUM和SET通常不合適用作標識符,盡管它適合用來做靜態的,包含了狀態和“類型”和值的“定義表”。
ENUM和SET列適合用來性別、國家、省份這些固定不變的信息。
要盡可能的避免使用字符串來做標識符,因為它們占用了很多空間並且通常比整數類型要慢,特別注意不要在MYISAM表上使用字符串標識符。MYISAM默認情況下為字符串使用了壓縮索引,這使查找更為緩慢。
MYISAM使用前綴壓縮來減小索引大小,默認情況下會壓縮字符串,也可以壓縮整數
可以使用CREATE TABLE時用PACK_KEYS控制索引壓縮的方式。
PACK_KEYS在MYSQL手冊中如下描述:
如果您希望索引更小,則把此選項設置為1。這樣做通常使更新速度變慢,同時閱讀速度加快。把選項設置為0可以取消所有的關鍵字壓縮。把此選項設置為DEFAULT時,存儲引擎只壓縮長的CHAR或VARCHAR列(僅限於MYISAM)。
如果您不使用PACK_KEYS,則默認操作是只壓縮字符串,但不壓縮數字。如果您使用PACK_KEYS=1,則對數字也進行壓縮。
一些數據類型沒有直接對應的內建數據類型,精度低於秒的時間戳就是一個例子,另一個例子就是IP地址,人們通常使用varchar(15)來保存IP地址。但是,IP地址實際上是無符號的32位整數,而不是字符串。使用小數點來進行分純粹是為了增加它的可讀性。在實際使用時應用用無符號整數來存儲IP地址。MySQL提供了INET_ATON()和INET_NTOA()函數在IP地址和整數之前轉換。
數據庫操作中最為耗時的操作就是 IO 處理,大部分數據庫操作 90% 以上的時間都花在了 IO 讀寫上面。所以盡可能減少 IO 讀寫量,可以在很大程度上提高數據庫操作的性能。
我們無法改變數據庫中需要存儲的數據,但是我們可以在這些數據的存儲方式方面花一些心思。下面的這些關於字段類型的優化建議主要適用於記錄條數較多,數據量較大的場景,因為精細化的數據類型設置可能帶來維護成本的提高,過度優化也可能會帶來其他的問題
字符集直接決定了數據在MySQL中的存儲編碼方式,由於同樣的內容使用不同字符集表示所占用的空間大小會有較大的差異,所以通過使用合適的字符集,可以幫助我們盡可能減少數據量,進而減少IO操作次數。
純拉丁字符能表示的內容,沒必要選擇 latin1 之外的其他字符編碼,因為這會節省大量的存儲空間
如果我們可以確定不需要存放多種語言,就沒必要非得使用UTF8或者其他UNICODE字符類型,這回造成大量的存儲空間浪費
MySQL的數據類型可以精確到字段,所以當我們需要大型數據庫中存放多字節數據的時候,可以通過對不同表不同字段使用不同的數據類型來較大程度減小數據存儲量,進而降低 IO 操作次數並提高緩存命中率
適當拆分
有些時候,我們可能會希望將一個完整的對象對應於一張數據庫表,這對於應用程序開發來說是很有好的,但是有些時候可能會在性能上帶來較大的問題。
當我們的表中存在類似於 TEXT 或者是很大的 VARCHAR類型的大字段的時候,如果我們大部分訪問這張表的時候都不需要這個字段,我們就該義無反顧的將其拆分到另外的獨立表中,以減少常用數據所占用的存儲空間。這樣做的一個明顯好處就是每個數據塊中可以存儲的數據條數可以大大增加,既減少物理 IO 次數,也能大大提高內存中的緩存命中率。
上面幾點的優化都是為了減少每條記錄的存儲空間大小,讓每個數據庫中能夠存儲更多的記錄條數,以達到減少 IO 操作次數,提高緩存命中率。下面這個優化建議可能很多開發人員都會覺得不太理解,因為這是典型的反范式設計,而且也和上面的幾點優化建議的目標相違背。
為什麼我們要冗余?這不是增加了每條數據的大小,減少了每個數據塊可存放記錄條數嗎?
確實,這樣做是會增大每條記錄的大小,降低每條記錄中可存放數據的條數,但是在有些場景下我們仍然還是不得不這樣做:
被頻繁引用且只能通過 Join 2張(或者更多)大表的方式才能得到的獨立小字段
這樣的場景由於每次Join僅僅只是為了取得某個小字段的值,Join到的記錄又大,會造成大量不必要的 IO,完全可以通過空間換取時間的方式來優化。不過,冗余的同時需要確保數據的一致性不會遭到破壞,確保更新的同時冗余字段也被更新