一般而言,MySQL 的調優可以分為兩個層面,一個是在MySQL層面上進行的調優,比如SQL改寫,索引的添加,MySQL各種參數的配置;另一個層面是從操作系統的層面和硬件的層面來進行調優。操作系統的層面的調優,一般要先定位到是那種資源出現瓶頸——CPU、 內存、硬盤、網絡,然後入手調優。所以其實MySQL 的調優,其實不是那麼簡單,它要求我們對 硬件、OS、MySQL 三者都具有比較深入的理解。比如 NUMA 架構的CPU是如何分配CPU的,以及是如何分配內存的,如何避免導致SWAP的發生;Linux 系統的IO調度算法選擇哪一種——CFQ、DEADLINE、NOOP、還是 ANTICIPATORY;MySQL的redo log和undo log它們的寫哪個是順序寫,哪個是隨機寫?
所以其實,如果想要對 MySQL 進行調優,要求我們必須對 硬件和OS,以及MySQL的內部實現原理,都要有很好的掌握。本文關於MySQL調優基礎之 CPU和進程。
1. CPU 架構之 NUMA和SMP
SMP:稱為共享內存訪問CPU(Shared Memory Mulpti Processors), 也稱為對稱型CPU架構(Symmetry Multi Processors)
NUMA:非統一內存訪問 (Non Uniform Memory Access)
它們最重要的區別在於內存是否綁定在各個物理CPU上,以及CPU如何訪問內存:
SMP架構的CPU內部沒有綁定內存,所有的CPU爭用一個總線來訪問所有共享的內存,優點是資源共享,而缺點是總線爭用激烈。隨著PC服務 器上的CPU數量變多(不僅僅是CPU核數),總線爭用的弊端慢慢越來越明顯,於是Intel在Nehalem CPU上推出了NUMA架構,而AMD也推出了基於相同架構的Opteron CPU。
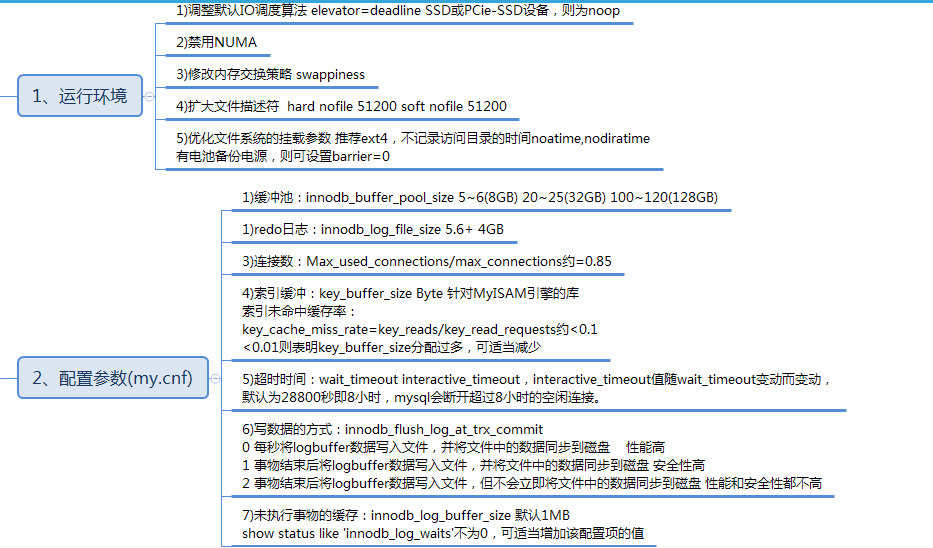
NUMA 最大的特點是引入了node和distance的概念,node內部有多個CPU,以及綁定的內存。每個node的CPU和內存一般是相等。distance這個概念是用來定義各個node之間調用資源的開銷。NUMA架構中內存和CPU的關系如下圖所示: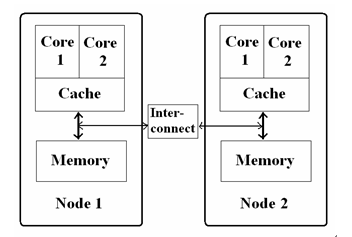
(node內部有多個CPU,node內部有內存;每兩個node之間有 inter-connect)
NUMA架構的提出是為了適應多CPU,可以看到node內部的CPU對內存的訪問分成了兩種情況:
1)對node內部的內存的訪問,一般稱為 local access,顯然訪問速度是最快的;
2)對其它node中的內存的訪問,一般稱為 remote access,因為要通過 inter-connect,所以訪問速度會慢一些;
因為CPU和內存是綁定而形成一個node,那麼就涉及到CPU如何分配,內存如何分配的問題:
1)NUMA的CPU分配策略有cpunodebind、physcpubind。cpunodebind規定進程運行在某幾個node之上,而physcpubind可以更加精細地規定運行在哪些核上。
2)NUMA的內存分配策略有localalloc、preferred、membind、interleave。localalloc規定進程從當前
node上請求分配內存;而preferred比較寬松地指定了一個推薦的node來獲取內存,如果被推薦的node上沒有足夠內存,進程可以嘗試別的
node。membind可以指定若干個node,進程只能從這些指定的node上請求分配內存。interleave規定進程從所有node上以RR算法交織地請求分配內存,達到隨機均勻的從各個node中分配內存的目的。
NUMA 架構導致的問題——SWAP
因為NUMA架構的CPU,默認采用的是localalloc的內存分配策略,運行在本node內部CPU上的進程,會從本node內部的內存上分配內存,如果內存不足,則會導致swap的產生,嚴重影響性能!它不會向其它node申請內存。這是他最大的問題。
所以為了避免SWAP的產生,一定要將NUMA架構CPU的內存分配策略設置為:interleave; 這樣設置的話,任何進程的內存分配,都會隨機向各個node申請,雖然remote access會導致一點點的性能損失,但是他杜絕了SWAP導致的嚴重的性能損失。所以 interleave 其實是將NUMA架構的各個node中的內存,又重新虛擬成了一個共享的內存,但是和SMP不同的是,因為每兩個node之間有 inter-connect ,所以又避免了SMP架構總線爭用的缺陷。
2. CPU 和 Linux 進程
進程應該是Linux中最重要的一個概念。進程運行在CPU上,是所有硬件資源分配的對象。Linux中用一個task_struct的結構來描述進程,描述了進程的各種信息、屬性、資源。
Linux中進程的生命周期和它們涉及的調用:
1)父進程調用fork() 產生一個新的自進程;
2)子進程調用exec() 指定自己要執行的代碼;
3)子進程調用exit() 退出,進入zombie狀態;
4)父進程調用wait(),等待子進程的返回,回收其所有資源;
Thread:
是一個執行單元,同一進程中所有線程,共享進程的資源。線程一般稱為 LWP(Light Weight Process)輕量級進程。所以期限線程沒有那麼神秘,我們可以將其當做特殊的進程來看待。
進程的優先級和nice:
進程的調度,涉及到進程的優先級。優先級使用nice level來表示,其值范圍:19 ~ -20。值越小,優先級越大,默認為0.
一般如果我們想降低某個線程被調度的頻率,就可以調高它的nice值(越nice,就越不會去爭用CPU)。
進程的 context switch:
進程上下文切換,是一個極為重要的概念,因為他對性能影響極大。進程的調度,級涉及到進程上下文的切換。上下文切換,是指將進程的所有的信息,從CPU的register中flush到內存中,然後換上其它進程的上下文。頻繁的上下文切換,將極大的影響性能。
CPU中斷處理:
CPU的中斷處理是優先級最高的任務之一。中斷分為:hard interrupte 和 soft interrupt.
因為中斷發生,就會去運行中斷處理程序,也就導致了context switch,所以過多的中斷也會導致性能的下降。
進程的各種狀態 state:
進程的各種狀態,一定要搞清楚他們的含義,不然後面進程的 load average(top命令和uptime命令)等各種信息會看不懂。
1)TASK_RUNNING: In this state, a process is running on a CPU or waiting to run in the queue (run queue).
2)TASK_STOPPED: A process suspended by certain signals (for example SIGINT, SIGSTOP) is in this state. The process is waiting to be
resumed by a signal such as SIGCONT.
3)TASK_INTERRUPTIBLE: In this state, the process is suspended and waits for a certain condition to be satisfied. If a process is in
TASK_INTERRUPTIBLE state and it receives a signal to stop, the process state is changed and operation will be interrupted. A typical
example of a TASK_INTERRUPTIBLE process is a process waiting for keyboard interrupt.
4)TASK_UNINTERRUPTIBLE: Similar to TASK_INTERRUPTIBLE. While a process in TASK_INTERRUPTIBLE state can be interrupted,
sending a signal does nothing to the process in TASK_UNINTERRUPTIBLE state. A typical example of a TASK_UNINTERRUPTIBLE
process is a process waiting for disk I/O operation.
5)TASK_ZOMBIE: After a process exits with exit() system call, its parent should know of the termination. In TASK_ZOMBIE state, a
process is waiting for its parent to be notified to release all the data structure.
除了 TASK_RUNNING 中的進程可能在運行之外,其它狀態的進程都沒有在運行。但是其實 TASK_UNINTERRUPTIBLE 比較特殊,它其實可以看做是在運行的,因為他是在等待磁盤操作完成,所以其實從系統的角度,而不是從進程的角度而言,其實系統是在為進程運行的。這也就是為什麼 load average 中的數值,是包括了 TASK_RUNNING 和 TASK_UNINTERRUPTIBLE 兩種狀態的進程的平均值。
進程如何使用內存:
進程的運行,必須申請和使用內存,最重要的包括堆和棧:
進程使用的內存,可以用 pmap, ps 等待命令行來查看。在後面會有站麼的內存調優文章介紹。
CPU 調度:
前面介紹了CPU的調度涉及到進程的優先級和nice level. Linux中進程的調度算法是 O(1)的,所以進程數量的多少不會影響進程調度的效率。
進程的調度涉及到兩個優先級數組(優先級隊列):active, expired 。CPU按照優先級調度 active 隊列中的進程,隊列中所有進程調度完成之後,交換active隊列和expired隊列,繼續調度。
NUMA架構的CPU在調度時,一般不會垮node節點進行調度,除非一個node節點CPU超載了並且請求進行負載均衡。因為垮node節點CPU調度影響性能。
3. Linux 如何度量 CPU
1)CPU utilization:最直觀最重要的就是CPU的使用率。如果長期超過80%,則表明CPU遇到了瓶頸;
2)User time: 用戶進程使用的CPU;該數值越高越好,表明越多的CPU用在了用戶實際的工作上
3)System time: 內核使用的CPU,包括了硬中斷、軟中斷使用的CPU;該數值越低越好,太高表明在網絡和驅動層遇到瓶頸;
4)Waiting: CPU花在等待IO操作上的時間;該數值很高,表明IO子系統遇到瓶頸;
5)Idel time: CPU空閒的時間;
6)Load average: the average of the sum of TASK_RUNNING and TASK_UNINTERRUPTIBLE processes. If processes that request CPU time are blocked (which means that the CPU has no time to process them), the load average will increase. On the other hand, if each
process gets immediate access to CPU time and there are no CPU cycles lost, the load will decrease.
7)Context Switch: 上下文切換;
如何檢測CPU:
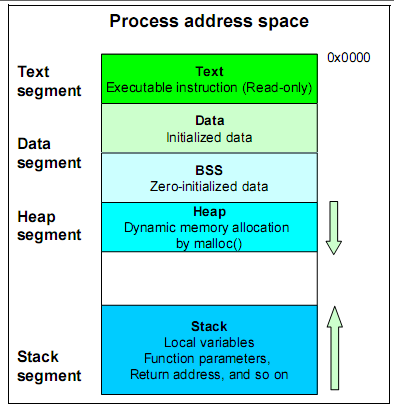
檢測CPU使用情況最好的工具是 top 命令:
3.1 top 命令 查看CPU 信息
要調優,那麼就必須讀懂 很多 命令行工具的輸出。上面的top命令包括了很多的信息:
第一行:
top - 14:35:55 up 25 min, 4 users, load average: 0.10, 0.07, 0.14
分別表示的是:當前系統時間;up 25 min表示已經系統已經運行25分鐘; 4 users:表示系統中有4個登錄用戶;
load average: 分別表示最近 1 分鐘, 5 分鐘, 15分鐘 CPU的負載的平均值。
(load average: the average of the sum of TASK_RUNNING and TASK_UNINTERRUPTIBLE processes);
這一行最重要的就是 load average
第二行:
Tasks: 92 total, 1 running, 91 sleeping , 0 stopped, 0 zombie
分別表示系統中的進程數:總共92個進程, 1個在運行,91個在sleep,0個stopped, 0個僵屍;
第三行:
Cpu(s): 0.0%us, 1.7 %sy, 0.0%ni, 97.7%id, 0.0%wa, 0.3%hi, 0.3%si, 0.0%st
這一行提供了關於CPU使用率的最重要的信息,分別表示 users time, system time, nice time, idle time, wait time, hard interrupte time, soft interrupted time, steal time; 其中最終要的是:users time, system time, wait time ,idle time 等等。nice time 表示用於調准進程nice level所花的時間。
第四行:
Mem: total, used ,free, buffers
提供的是關於內存的信息,因為Linux會盡量的來使用內存來進行緩存,所以這些信息沒有多大的價值,free數值小,並不代表存在內存瓶頸;
第五行:
Swap: total, used, free ,cached
提供的是關於swap分區的使用情況,這些信息也沒有太大的價值,因為Linux的使用內存的機制決定的。used值很大並不代表存在內存瓶頸;
剩下是關於每個進程使用的資源的情況,進程的各種信息,按照使用CPU的多少排序,每個字段的含義如下:
PID: 表示進程ID;USER: 表示運行進程的用戶;PR:表示進程優先級;NI:表示進程nice值,默認為0;
VIRT:The total amount of virtual memory used by the task. It includes all code, data and shared libraries plus pages that have been swapped out. 進程占用的虛擬內存大小,包括了swap out的內存page;
RES: Resident size (kb)。The non-swapped physical memory a task is using. 進程使用的常駐內存大小,沒有包括swap out的內存;
SHR:Shared Mem size (kb)。The amount of shared memory used by a task. It simply reflects memory that could be potentially shared
with other processes. 其實應該就是使用 shmget() 系統調用分配的共享內存,可以在多個進程之間共享訪問。
S: 表示進程處於哪種狀態:R: Running; S: sleeping; T: stoped; D: interrupted; Z:zomobie;
%CPU: 進程占用的CPU;
%MEM:進程占用的內存;
%TIME+: 進程運行時間;
COMMAND: 進程運行命令;
讀懂 top 等相關命令行的信息是進行調優的基礎。其實這些命令行的輸出的含義,在man top中都有是否詳細的說明。只要耐心看手冊就行了。
上面的 top 命令默認是以 進程為單位來顯示的,我們也可以以線程為單位來顯示: top -H
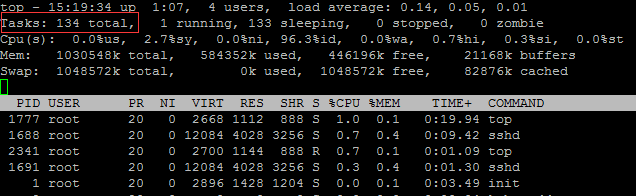
可以看到以線程為單位是,Tasks totol數量明顯增加了,有92增加到了 134,因為 mysqld 是線程架構的,後台有多個後台線程。
如果僅僅想查看 CPU 的 load average,使用uptime命令就行了:
[root@localhost ~]# uptime 15:26:59 up 1:15, 4 users, load average: 0.00, 0.02, 0.00
3.2 vmstat 查看CPU 信息
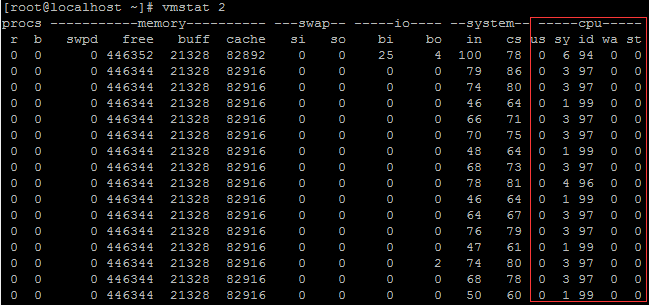
上面各個字段的含義:
FIELD DESCRIPTION FOR VM MODE
Procs
r: The number of processes waiting for run time.
b: The number of processes in uninterruptible sleep.
Memory
swpd: the amount of virtual memory used.
free: the amount of idle memory.
buff: the amount of memory used as buffers.
cache: the amount of memory used as cache.
inact: the amount of inactive memory. (-a option)
active: the amount of active memory. (-a option)
Swap
si: Amount of memory swapped in from disk (/s).
so: Amount of memory swapped to disk (/s).
IO
bi: Blocks received from a block device (blocks/s).
bo: Blocks sent to a block device (blocks/s).
System
in: The number of interrupts per second, including the clock.
cs: The number of context switches per second.
CPU
These are percentages of total CPU time.
us: Time spent running non-kernel code. (user time, including nice time)
sy: Time spent running kernel code. (system time)
id: Time spent idle. Prior to Linux 2.5.41, this includes IO-wait time.
wa: Time spent waiting for IO. Prior to Linux 2.5.41, included in idle.
st: Time stolen from a virtual machine. Prior to Linux 2.6.11, unknown.
和CPU相關的信息有 user time, system time, idle time, wait time, steal time;
另外提供了關於中斷和上下文切換的信息。System 中的in,表示每秒的中斷數,cs表示每秒的上下文切換數;
其它的字段是關於內存和磁盤的。
3.3 iostat 命令查看 CPU 信息
[root@localhost ~]# iostat
Linux 2.6.32-504.el6.i686 (localhost.localdomain) 09/30/2015 _i686_ (1 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
0.27 0.02 4.74 0.28 0.00 94.69
Device: tps Blk_read/s Blk_wrtn/s Blk_read Blk_wrtn
scd0 0.01 0.08 0.00 536 0
sda 1.64 42.27 8.97 290966 61720
[root@localhost ~]# iostat -c
Linux 2.6.32-504.el6.i686 (localhost.localdomain) 09/30/2015 _i686_ (1 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
0.26 0.02 4.72 0.27 0.00 94.72
提供了cpu的平均使用率。
3.4 ps 命令查看某個進程和某個線程的 CPU 信息
比如我想查看 mysqld 的相關信息:
[root@localhost ~]# pidof mysqld 2412 [root@localhost ~]# ps -mp 2412 -o THREAD,pmem,rss,vsz,tid,pid USER %CPU PRI SCNT WCHAN USER SYSTEM %MEM RSS VSZ TID PID mysql 6.7 - - - - - 42.8 441212 752744 - 2412 mysql 6.5 19 - - - - - - - 2412 - mysql 0.0 19 - - - - - - - 2414 - mysql 0.0 19 - - - - - - - 2415 - mysql 0.0 19 - - - - - - - 2416 - mysql 0.0 19 - - - - - - - 2417 - mysql 0.0 19 - - - - - - - 2418 - mysql 0.0 19 - - - - - - - 2419 - mysql 0.0 19 - - - - - - - 2420 - mysql 0.0 19 - - - - - - - 2421 - mysql 0.0 19 - - - - - - - 2422 - mysql 0.0 19 - - - - - - - 2423 - mysql 0.0 19 - - - - - - - 2425 - mysql 0.0 19 - - - - - - - 2426 - mysql 0.0 19 - - - - - - - 2427 - mysql 0.0 19 - - - - - - - 2428 - mysql 0.0 19 - - - - - - - 2429 - mysql 0.0 19 - - - - - - - 2430 - mysql 0.0 19 - - - - - - - 2431 - mysql 0.0 19 - - - - - - - 2432 - mysql 0.0 19 - - - - - - - 2433 - mysql 0.0 19 - - - - - - - 2434 -
先獲得 mysqld 的基礎PID 2412,
然後查看其線程的信息:ps -mp 2412-o THREAD,pmem,rss,vsz,tid,pid ( -p 指定進程PID, -o 指定輸出格式,參見man ps)
第一列就是關於線程CPU的信息。另外我們也可以查出是占有的CPU很高的線程的tid。
關於ps我們一般使用 ps -elf , 如果想查看線程,可以 ps -elLf,其中的L表示 Leight weight process輕量級進程。
3.5 mpstat(multi processor stat) 命令查看多核CPU中每個CPU核心的信息
[root@localhost ~]# mpstat Linux 2.6.32-504.el6.i686 (localhost.localdomain) 09/30/2015 _i686_ (1 CPU) 04:11:50 PM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %idle 04:11:50 PM all 0.26 0.02 4.30 0.27 0.26 0.15 0.00 0.00 94.74
這裡因為虛擬機中的單核CPU,所以只顯示all,沒有顯示其它核心的CPU使用情況。
4. CPU 相關調優
1)使用上面介紹的工具:top, vmstat, iostat, ps -mp xxx -o, mpstat 等,可以確認是否存在 CPU 瓶頸。然後確認 user time, system time, wait time, context switch......那種占用比例高,確認是哪個進程占用CPU高。如果能確認是 mysqld 的相關進程,那麼就可以從 mysql 上入手進行調優。比如使用mysql的命令 show processlist ;查看是哪個sql導致的,找到sql之後,進行優化或者重寫等等,或者將其放到slave上去運行。
2)如果是 非必須的進程占用CPU,那麼可以殺掉,然後使用cron讓其在非高峰期去執行;或者使用 renice 命令降低其優先級;
[root@localhost ~]# renice -n -10 -p 2041 2041: old priority 10, new priority -10
將進程 2041 的優先級設置為 -10.
3)可以跟蹤進程,查找原因:strace -aef -p spid -o file
[root@localhost ~]# strace -aef -p 2041 -o mysql.txt
Process 2041 attached - interrupt to quit
^CProcess 2041 detached
[root@localhost ~]# ll mysql.txt
-rw-r--r-- 1 root root 10091 Sep 30 16:44 mysql.txt
[root@localhost ~]# head mysql.txt
read(0, "\33", 1) = 1
read(0, "[", 1) = 1
read(0, "A", 1) = 1
write(1, "select version();", 17) = 17
read(0, "\n", 1) = 1
write(1, "\n", 1) = 1
ioctl(0, SNDCTL_TMR_STOP or TCSETSW, {B38400 opost isig icanon echo ...}) = 0
rt_sigprocmask(SIG_BLOCK, [HUP INT QUIT TERM CONT TSTP WINCH], [], 8) = 0
rt_sigaction(SIGINT, {0x8053ac0, [INT], SA_RESTART}, NULL, 8) = 0
rt_sigaction(SIGTSTP, {SIG_DFL, [], 0}, NULL, 8) = 0
4)換更好的CPU。