[matsunobu@host ~]$ mysqlslap --query="select user_name,.. from test.user where user_id=1" \\ --number-of-queries=10000000 --concurrency=30 --host=xxx -uroot通過如下命令,很快就得知 InnoDB 的 QPS 大概為 100,000, 幾乎只有 Memcached 的 1/4.
[matsunobu@host ~]$ mysqladmin extended-status -i 1 -r -uroot \\ | grep -e "Com_select"
... | Com_select | 107069 | | Com_select | 108873 | | Com_select | 108921 | | Com_select | 109511 | | Com_select | 108084 | | Com_select | 108483 | | Com_select | 108115 | ...看上去, 100, 000+ QPS 也不是太差,但為什麼 MySQL 比 Memcached 差這麼多呢,MySQL 到底在做什麼呢。從 vmstat 的統計信息得知, %user 和 %system 的數據都非常高.
[matsunobu@host ~]$ vmstat 1
r b swpd free buff cache in cs us sy id wa st 23 0 0 963004 224216 29937708 58242 163470 59 28 12 0 0 24 0 0 963312 224216 29937708 57725 164855 59 28 13 0 0 19 0 0 963232 224216 29937708 58127 164196 60 28 12 0 0 16 0 0 963260 224216 29937708 58021 165275 60 28 12 0 0 20 0 0 963308 224216 29937708 57865 165041 60 28 12 0 0再看 Oprofile 輸出,可知 CPU 消耗的出去:
samples % app name symbol name 259130 4.5199 mysqld MYSQLparse(void*) 196841 3.4334 mysqld my_pthread_fastmutex_lock 106439 1.8566 libc-2.5.so _int_malloc 94583 1.6498 bnx2 /bnx 284550 1.4748 ha_innodb_plugin.so.0.0.0 ut_delay 67945 1.1851 mysqld _ZL20make_join_statisticsP4JOINP10TABLE_LISTP4ItemP16st_dynamic_array 63435 1.1065 mysqld JOIN::optimize() 55825 0.9737 vmlinux wakeup_stack_begin 55054 0.9603 mysqld MYSQLlex(void*, void*) 50833 0.8867 libpthread-2.5.so pthread_mutex_trylock 49602 0.8652 ha_innodb_plugin.so.0.0.0 row_search_for_mysql 47518 0.8288 libc-2.5.so memcpy 46957 0.8190 vmlinux .text.elf_core_dump 46499 0.8111 libc-2.5.so mallocMySQL 的 SQL 解析階段,有調用 MYSQLparse() 和 MYSQLlex(); 查詢優化階段,調用 make_join_statistics() 和 JOIN::optimize()。很明顯,主要耗資源的是SQL 層,而不是 InnoDB 存儲層。與 Memcached/NoSQL 比起來,MySQL 還要額外做一些工作:
另外,MySQL 還必須要做大量的並發控制,比如在發送/接收網絡數據包的時候,fcntl() 就要被調用很多次; Global mutexes 比如 LOCK_open,LOCK_thread_count 也被頻繁地取得/釋放。所以, 在 Oprofile 的輸出中,排在第二位的是 my_pthread_fastmutex_lock()。並且 %system 占用的 CPU 相當高(28%)。
其實 MySQL 開發團隊和外圍的開發團體已意識到大量並發控制對性能的影響,MySQL5.5 中已經解決了一些問題。未來的 MySQL 版本中,應該會越來越好。
還有一個大的問題是,%user 達到了60%。互斥量的爭奪導致 %system 上增,而不是 %user,即使 MySQL 內部關於互斥量的的問題都得到修復,還是很難達到我們所期望的 300,000 QPS.也許,會有人提到使用 HANDLER ,但是因為在解析 SQL時,opening/closing table 還是必須的,所以對於提高吞吐量,它還是只能愛莫能助。
如果只有一小部分數據進入內存,那麼 SQL 帶來的消耗可以忽略不計。很簡單,因為磁盤的 I/0 操作所帶來的消耗會要大,這種情況下時,就不需要太過的去考慮 SQL 所帶來的消耗。
但是,在大多數的 hot MySQL 服務器中, 大部分的數據都是因為全部載入至內存中而變的只受 CPU 的限制。Profiling 的結果就類似上所述的那樣: SQL 層消耗了大量的資源。假設,需要做大量的 PK 查詢(i.e. SELECT x FROM t WHERE id=?)或者是做 LIMIT 的范圍查詢, 即使有 70-80% 都是在同一張表中做 PK 查詢(僅僅只是查詢條件中給定的值不同,即 value 不同而已), MySQL 還是每次需要去做 parse/open/lock/unlock/close, 這對我們來說,是非常影響效率的。
到底有沒有好的方法來減少 MySQL SQL 層的 CPU 資源/爭奪呢? 如果使用 MySQL Cluster, NDBAPI 不失為一個很好的解決辦法。 在我還是 MySQL/Sun/Oracle 的顧問時,就見到過很多客戶對SQL Node + NDB performance 感到非常不爽,但當他們用了 NDBAPI 客戶端後,發現性能調提高了 N 倍。當然,在 MySQL Cluster 中是可以同時使用 NDBAPI 和 SQL 的,但在做頻繁的訪問模式時還是推薦使用 NDBAPI,而在 ad-hoc 或者 查詢不頻繁的情況下使用 SQL + MySQL + NDB。
以快捷的速度訪問 API, 這正是我們需要的,但同時我們也想在 ad_hoc 或者復雜的查詢的情況時還是使用 SQL. 像其他的 web service, DeNA 使用的是 InnoDB, 轉為 NDB,這並不是一件容易的事情,因為內置InnoDB 即不支持 SQL 也不支持網絡層的服務。
最好的辦法可以是在 MySQL 的內部,實現一以 MySQL plugin 的形式存在的 NoSQL 的網絡服務。它偵聽在某端口來接收采用 NoSQL 協議/API 的通訊, 然後通過 MySQL 內部的存儲引擎 API 來直接訪問 InnoDB。這種方法的理念類似於 NDBAPI, 但是它可以做到與 InnoDB 通訊。
這個理念最初是去年由 Kazuho Oku 在 Cybozu Labs 上提出的,他曾寫過采用 Memcached protocols 通訊的MyCached UDF。而我的大學同學實現了另外一個插件 ― HandlerSocket,
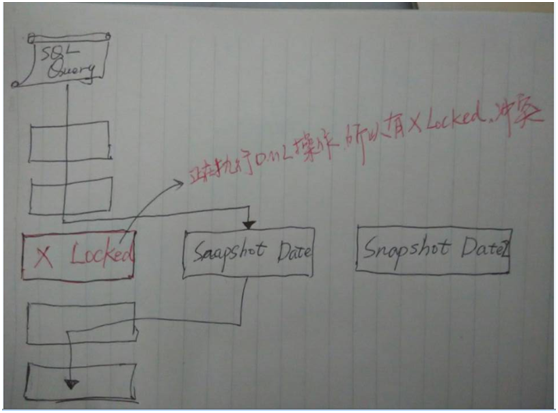
是以 MySQL daemaon plugin 形式存在,所以在應用中可把 MySQL 當 NoSQL 使用. 它最大的功能是實現了與存儲引擎交互,比如 InnoDB,而這不需要任何的 SQL 方面的開銷. 訪問 MySQL 的 table 時,當然她也是需要 open/close table 的,但是 它並不是每次都去 open/close table, 因為它會將以前訪問過的 table 保存下來以供來是使用,而 opening/closing tables 是最耗資源的,而且很容易引起互斥量的爭奪,這樣一來,對於提高性能,非常有效。在流量變小時, HandlerSocket 會 close tables, 所以,它不會阻塞 administrative commands (DDL).它與MySQL + Memcached 的區別在哪呢? 對比圖1 和圖2 ,可從中看出其不同點。圖2 展示了典型的 MySQL + Memecached 的使用. 因為 Memcached 的 get 操作比 MySQL 的內存中/磁盤上的主鍵查詢要快很多,所以 Memcached 用於緩存數據庫記錄。如果 HandlerSocket 的查詢速度能和 Memcached 媲美,我們就不需要使用 Memcached 來緩存記錄。
舉一個例子,假設有一 user 表,通過 user_id 來獲取用戶信息:
CREATE TABLE user ( user_id INT UNSIGNED PRIMARY KEY, user_name VARCHAR(50), user_email VARCHAR(255), created DATETIME ) ENGINE=InnoDB;
用 SELECT 語句獲取用戶信息
mysql> SELECT user_name, user_email, created FROM user WHERE user_id=101; +---------------+-----------------------+---------------------+ | user_name | user_email | created | +---------------+-----------------------+---------------------+ | Yukari Takeba | yukari.takeba@dena.jp | 2010-02-03 11:22:33 | +---------------+-----------------------+---------------------+ 1 row in set (0.00 sec)
下面我們來看看如何使用 HandlerSocket 完成同樣的事情.
HandlerSocket具體安裝步驟請參考這裡,基本步驟如下:
1 下載HandlerSocket[root@localhost handlersocket]# ./configure --with-mysql-source=mysql-source-dir --with-mysql-bindir=mysql-server-bin-dir [root@localhost handlersocket]# make [root@localhost handlersocket]# make install3 安裝 HandlerSocket
mysql> INSTALL PLUGIN \'handlersocket\' soname \'handlersocket.so\';
因為 HandlerSocket是 MySQL 插件,所以可以象使用其它插件,如 InnoDB, Q4M 和 Spider 那樣使用它,即不需要修改 MySQL 源代碼,MySQL 最好是 5.1 或更高版本,編譯 HandlerSocket 時需要 MySQL 源碼和 MySQL 庫。
目前已提供 C++ 和 perl 調用的客戶端庫,下面是使用 perl 調用的實例代碼:
#!/usr/bin/perl
use strict;
use warnings;
use Net::HandlerSocket;
#1. establishing a connection
my $args = { host => \'ip_to_remote_host\', port => 9998 };
my $hs = new Net::HandlerSocket($args);
#2. initializing an index so that we can use in main logics.
# MySQL tables will be opened here (if not opened)
my $res = $hs->open_index(0, \'test\', \'user\', \'PRIMARY\',
\'user_name,user_email,created\');
die $hs->get_error() if $res != 0;
#3. main logic
#fetching rows by id
#execute_single (index id, cond, cond value, max rows, offset)
$res = $hs->execute_single(0, \'=\', [ \'101\' ], 1, 0);
die $hs->get_error() if $res->[0] != 0;
shift(@$res);
for (my $row = 0; $row < 1; ++$row) {
my $user_name= $res->[$row + 0];
my $user_email= $res->[$row + 1];
my $created= $res->[$row + 2];
print "$user_name\\t$user_email\\t$created\\n";
}
#4. closing the connection
$hs->close()
#!/usr/bin/perl
use strict;
use warnings;
use Net::HandlerSocket;
#1. establishing a connection
my $args = { host => \'ip_to_remote_host\', port => 9998 };
my $hs = new Net::HandlerSocket($args);
#2. initializing an index so that we can use in main logics.
# MySQL tables will be opened here (if not opened)
my $res = $hs->open_index(0, \'test\', \'user\', \'PRIMARY\',
\'user_name,user_email,created\');
die $hs->get_error() if $res != 0;
#3. main logic
#fetching rows by id
#execute_single (index id, cond, cond value, max rows, offset)
$res = $hs->execute_single(0, \'=\', [ \'101\' ], 1, 0);
die $hs->get_error() if $res->[0] != 0;
shift(@$res);
for (my $row = 0; $row < 1; ++$row) {
my $user_name= $res->[$row + 0];
my $user_email= $res->[$row + 1];
my $created= $res->[$row + 2];
print "$user_name\\t$user_email\\t$created\\n";
}
#4. closing the connection
$hs->close();
上面代碼是通過 user_id=101 條件在 user 表獲取用戶 user_name, user_email和 created 信息,得到的結果應該和之前在 MySQL client 查詢出來的結果一樣。
[matsunobu@host ~]$ perl sample.pl Yukari Takeba yukari.takeba@dena.jp 2010-02-03 11:22:33
對於大多數Web應用程序而言,保持輕量級的 HandlerSocket 連接是一個很好的做法(持續連接),讓大量的請求可以集中於主要邏輯(上面代碼中的#3部分)。
HandlerSocket 協議是一個小尺寸的基於文本的協議,和 Memcached 文本協議類似,可以使用 telnet 通過 HandlerSocket 獲取數據。
[matsunobu@host ~]$ telnet 192.168.1.2 9998 Trying 192.168.1.2... Connected to xxx.dena.jp (192.168.1.2). Escape character is \'^]\'. P 0 test user PRIMARY user_name,user_email,created 0 1 0 = 1 101 0 3 Yukari Takeba yukari.takeba@dena.jp 2010-02-03 11:22:33 (Green lines are request packets, fields must be separated by TAB)
綠色表示請求數據包,字段必須用Tab鍵分隔。
現在是時候展示基准測試結果,使用上面的 user 表,從多線程遠程客戶端測試了執行主鍵查詢操作的次數,所有用戶數據都裝入到內存中(我測試了 100 萬行),也用類似的數據測試了 Memcached(我使用 libMemcached 和 Memcached_get() 獲取用戶數據),在 MySQL SQL 測試中,我使用了的是傳統的 SELECT 語句: “SELECT user_name, user_email, created FROM user WHERE user_id=?”, Memcached 和 HandlerSocket 客戶端代碼均使用 C/C++ 編寫,所有客戶端程序都位於遠程主機上,通過 TCP/IP 連接到 MySQL/Memcached。最高的吞吐量情況如下:
approx qps server CPU util
MySQL via SQL 105,000 %us 60% %sy 28%
Memcached 420,000 %us 8% %sy 88%
MySQL via HandlerSocket 750,000 %us 45% %sy 53%
HandlerSocket的吞吐量比使用傳統 SQL 時高出 7.5, 而且 %us 也只有使用傳統 SQL 時的3/4, 這說明 MySQL 的 SQL 層是非常耗資源的,如果能跳過這一層,性能肯定會大大提升。有趣的是,MySQL 使用 HandlerSocket 時的速度比使用 Memcached 也要快 178%,並且 Memcached 消耗的 %sy 資源也更多。所以雖然 Memcached 是一個很好的產品,但仍然有優化的空間。
下面是oprofile輸出內容,是在 MySQL HandlerSocket 測試期間收集到的,在核心操作,如網絡數據包處理,獲取數據等的 CPU 資源消耗(bnx2是一個網絡設備驅動程序)。
samples % app name symbol name 984785 5.9118 bnx2 /bnx2 847486 5.0876 ha_innodb_plugin.so.0.0.0 ut_delay 545303 3.2735 ha_innodb_plugin.so.0.0.0 btr_search_guess_on_hash 317570 1.9064 ha_innodb_plugin.so.0.0.0 row_search_for_mysql 298271 1.7906 vmlinux tcp_ack 291739 1.7513 libc-2.5.so vfprintf 264704 1.5891 vmlinux .text.super_90_sync 248546 1.4921 vmlinux blk_recount_segments 244474 1.4676 libc-2.5.so _int_malloc 226738 1.3611 ha_innodb_plugin.so.0.0.0 _ZL14build_template P19row_prebuilt_structP3THDP8st_tablej 206057 1.2370 HandlerSocket.so dena::hstcpsvr_worker::run_one_ep() 183330 1.1006 ha_innodb_plugin.so.0.0.0 mutex_spin_wait 175738 1.0550 HandlerSocket.so dena::dbcontext:: cmd_find_internal(dena::dbcallback_i&, dena::prep_stmt const&, ha_rkey_function, dena::cmd_exec_args const&) 169967 1.0203 ha_innodb_plugin.so.0.0.0 buf_page_get_known_nowait 165337 0.9925 libc-2.5.so memcpy 149611 0.8981 ha_innodb_plugin.so.0.0.0 row_sel_store_mysql_rec 148967 0.8943 vmlinux generic_make_request
因為 HandlerSocket 是運行於 MySQL 內部,直接與 InnoDB 交互,所以,可以使用常見的 SQL 命令,如 SHOW GLOBAL STATUS 獲得統計信息,Innodb_rows_read 達到了 750000+ 是值得一看的。
$ mysqladmin extended-status -uroot -i 1 -r | grep "InnoDB_rows_read" ... | Innodb_rows_read | 750192 | | Innodb_rows_read | 751510 | | Innodb_rows_read | 757558 | | Innodb_rows_read | 747060 | | Innodb_rows_read | 748474 | | Innodb_rows_read | 759344 | | Innodb_rows_read | 753081 | | Innodb_rows_read | 754375 | ...
測試用機的詳細信息如下:
Memcached 和 HandlerSocket 都做了網絡 I/O 限制,當我測試單個端口時,HandlerSocket 的 QPS 為 260000,而 Memcached 為 220000。
如下所述,HandlerSocket 有其自己的特點和優勢,而其中一些對我們來說, 是真的很給力.
HandlerSocket 目前支持 主鍵/唯一性查詢,非唯一性索引查詢,范圍掃描,LIMIT 和 INSERT/UPDATE/DELETE,但還不支持未使用任何索引的操作。另外,multi_get()(類似於in(1,2,3), 只需一次網絡往返)還可獲取多行數據。到這裡可查詢詳細信息。
HandlerSocket 連接是輕量級的,因為 HandlerSocket 采用epoll()和 worker-thread/thread-pooling 架構,而 MySQL 內部線程的數量是有限的(可以由 my.cnf中的 handlersocket_threads參數控制),所以即使建立上千萬的網絡連接到 HandlerSocket,它的穩定性也不會受到任何影響(消耗太多的內存,會造成巨大的互斥競爭等其他問題,如bug#26590,bug#33948,bug#49169)。
HandlerSocket,如上所描述, 相對於其它 NoSQL 陣容,性能表現一點也不遜色。事實上,我還未曾見過哪個 NoSQL 產品在一台普通服務器上可達到 750000+ 次查詢。它不僅沒有調用與 SQL 相關的函數,還優化了網絡/並發相關的問題。
更小的網絡數據包和傳統 MySQL 協議相比,HandlerSocket 協議更簡短,因此整個網絡的流量更小。
運行有限的 MySQL 內部線程數參考上面的內容。
將客戶端請求分組當大量的並發請求抵達 HandlerSocket 時,每個工作線程盡可能多地聚集請求,然後同時執行聚集起來的請求和返回結果。這樣,通過犧牲一點響應時間,而大大地提高性能。例如,你可以得到以下好處,如果有人感興趣,我會在今後的文章中對它們加以深入的解釋。
減少fsync()調用的次數.
減少復制延遲.
當使用 Memcached 緩存 MySQL/InnoDB 記錄時,在 Memcached 和 InnoD B緩沖池中均緩存了這些記錄,因此效率非常低(內存仍然很貴). 而采用 HandlerSocket插件, 由於它訪問 InnoDB 存儲引擎,記錄緩存在 InnoDB 緩沖池中,這樣,其它 SQL 語句就可以重復使用它。
由於數據只存儲在一個地方(InnoDB 內),不像使用 Memcached 時,需要在 Memcached 和 MySQL 之間檢查數據一致性。
後端存儲是 InnoDB,它是事務性和崩潰安全的,即使有設置innodb-flush-log-at-trx-commit!=1,在服務器崩潰時也只會丟掉 < 1s 內的數據。
在許多情況下,人們仍然希望使用 SQL(如生產摘要報告),這就是為什麼我們不能使用嵌入式 InnoDB 的原因,大多數 NoSQL 產品都不支持 SQL 接口,HandlerSocket 僅僅是一個 MySQL 插件,可以從 MySQL 客戶端發送 SQL 語句,但當需要高吞吐量時,最好使用 HandlerSocket。
因為 HandlerSocket 運行於 MySQL 內部,因此所有 MySQL 操作,如 SQL,在線備份,復制,通過 Nagios/EnterpriseMonitor 監控等都是支持的,HandlerSocket 獲得可以通過普通的 MySQL 命令監控,如SHOW GLOBAL STAUTS,SHOW ENGINE INNODB STATUS和SHOW PROCESSLIST等.
因為 HandlerSocket 是一個插件,所以它支持 MySQL 社區版和企業服務器版,而無需對 MySQL 做出任何修改就可以使用。
雖然我們只測試了5.1和5.5 InnoDB 插件,但 HandlerSocket 可以和任何存儲引擎交互。
盡管它很容易使用,但仍然需要學習如何與 HandlerSocket 交互,我們提供了C++ API、Perl綁定。
和其它NoSQL數據庫類似,HandlerSocket不支持安全功能,HandlerSocket的工作線程以系統用戶權限運行,因此應用程序可以訪問通過 HandlerSocket 協議的所有表,當然,你可以象其它 NoSQL 產品一樣使用防火牆過濾數據包。
對於 HDD I/O 綁定工作負載,數據庫每秒無法執行數千次查詢,通常只有 1-10% 的 CPU 利用率,在這種情況下,SQL 執行層不會成為瓶頸,因此使用HandlerSocket沒有什麼優勢,我們只在數據完全裝載到內存的服務器上使用 HandlerSocket。
我們已經在生產環境中使用了 HandlerSocket 插件,效果很明顯,因為我們減少了許多 Memcached 和 MySQL 從屬服務器,而且整個網絡流量也在減少。目前還沒有發現任何性能問題(如響應時間慢,延遲等)。
我認為, NoSQL/Database 社區完全低估了 MySQL, 相對於其他產品來說,它歷史悠久,而且到目前為止,我優秀的前同事們也做了許多獨特的、偉大的改進。從 NDBAPI 可以看出 MySQL 有成為 NoSQL 的潛力,因為存儲引擎 API 和守護進程接口的完全獨立,使得 Akira 和 DeNA 開發 HandlerSocket 成為可能。作為 MySQL 一名前員工和對 MySQL 長期的了解,我想看到 MySQL 變得更好,更受歡迎,而不僅僅只作為一個 RDBMS,也應該成為 NoSQL 陣營中的一員。